Transformación de datos mediante la ejecución de una actividad de Jar en Azure Databricks
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
La actividad de Jar de Azure Databricks en una canalización ejecuta un archivo Jar de Spark en el clúster de Azure Databricks. Este artículo se basa en el artículo sobre actividades de transformación de datos , que presenta información general de la transformación de datos y las actividades de transformación admitidas. Azure Databricks es una plataforma administrada para ejecutar Apache Spark.
Si desea una introducción y demostración de once minutos de esta característica, vea el siguiente vídeo:
Agregar una actividad Jar para Azure Databricks a una canalización con interfaz de usuario
Para usar una actividad Jar para Azure Databricks en una canalización, complete los pasos siguientes:
Busque Jar en el panel Actividades de canalización y arrastre una actividad Jar al lienzo de canalización.
Seleccione la nueva actividad de Jar en el lienzo si aún no está seleccionada.
Seleccione la pestaña Azure Databricks para seleccionar o crear un nuevo servicio vinculado de Azure Databricks que ejecutará la actividad Jar.
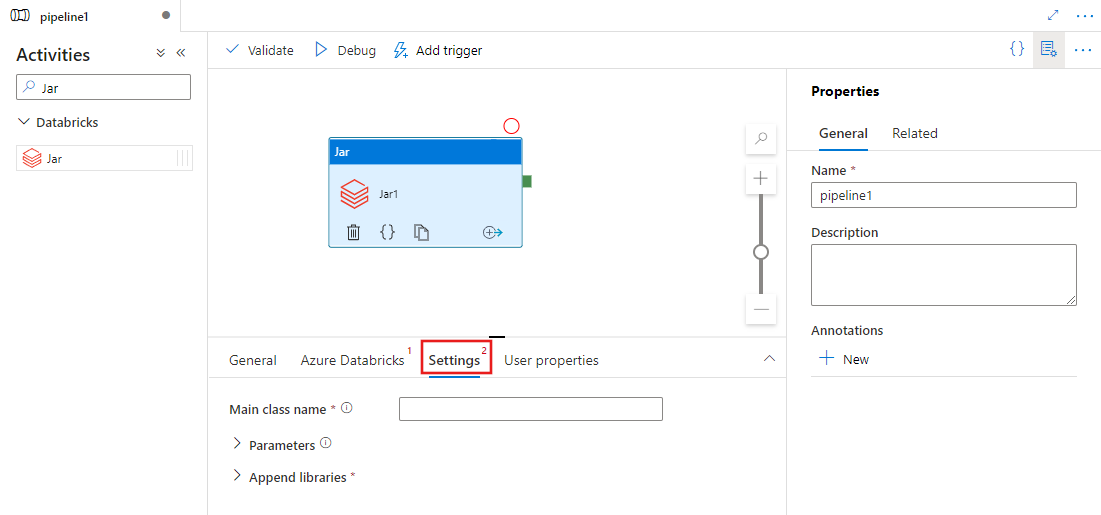
Seleccione la pestaña Configuración y especifique el nombre de clase que se va a ejecutar en Azure Databricks, los parámetros opcionales que se pasarán al archivo Jar y las bibliotecas que se instalarán en el clúster para ejecutar el trabajo.
Definición de la actividad de Jar en Databricks
Esta es la definición de JSON de ejemplo de una actividad de Jar en Databricks:
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Propiedades de la actividad de Jar en Databricks
En la siguiente tabla se describen las propiedades JSON que se usan en la definición de JSON:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| name | Nombre de la actividad en la canalización. | Sí |
| description | Texto que describe para qué se usa la actividad. | No |
| type | En el caso de la actividad de Jar en Databricks, el tipo de actividad es DatabricksSparkJar. | Sí |
| linkedServiceName | Nombre del servicio vinculado de Databricks en el que se ejecuta la actividad de Jar. Para obtener más información sobre este servicio vinculado, vea el artículo Compute linked services (Servicios vinculados de procesos). | Sí |
| mainClassName | Nombre completo de la clase que incluye el método principal que se va a ejecutar. Esta clase debe estar contenida en un archivo JAR que se proporciona como una biblioteca. Un archivo JAR puede contener varias clases. Cada una de las clases puede contener un método main. | Sí |
| parámetros | Parámetros que se pasarán al método principal. Esta propiedad es una matriz de cadenas. | No |
| libraries | Lista de bibliotecas para instalar en el clúster que ejecutará el trabajo. Puede ser una matriz de <cadena, objeto> | Sí (al menos una con el método mainClassName) |
Nota
Problema conocido: cuando se usa el mismo clúster interactivo para ejecutar actividades simultáneas de Jar en Databricks (sin reiniciar el clúster), se produce un problema conocido en Databricks por el que los parámetros "in" de la primera actividad se utilizarán también en las siguientes actividades. El resultado son parámetros incorrectos que se pasan a los trabajos posteriores. Para mitigar esto, use un clúster de trabajo en su lugar.
Bibliotecas compatibles con las actividades de Databricks
En la definición de la actividad de Databricks anterior, especificó estos tipos de biblioteca: jar, egg, maven, pypi y cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Para más información, consulte la documentación de Databricks sobre los tipos de bibliotecas.
Carga de una biblioteca en Databricks
Puede usar la interfaz de usuario del área de trabajo:
Uso de la interfaz de usuario del área de trabajo de Databricks
Para obtener la ruta de acceso de dbfs de la biblioteca que se agregó mediante la interfaz de usuario, puede usar la CLI de Databricks.
Habitualmente, las bibliotecas de Jar se almacenan en dbfs:/FileStore/jars mientras se usa la interfaz de usuario. Puede enumerar todo mediante la CLI: databricks fs ls dbfs:/FileStore/job-jars
O bien, puede usar la CLI de Databricks:
Uso de la CLI de Databricks (pasos de instalación)
Por ejemplo, para copiar un archivo JAR en dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
Contenido relacionado
Si desea una introducción y demostración de once minutos de esta característica, vea el vídeo.