Copia de datos de forma segura desde Azure Blob Storage a SQL Database mediante puntos de conexión privados
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, creará una factoría de datos mediante la interfaz de usuario (UI) de Azure Data Factory. La canalización de esta factoría de datos copia los datos de forma segura desde Azure Blob Storage a una base de datos de Azure SQL (en ambas se permite el acceso solo a las redes seleccionadas) mediante puntos de conexión privados en una red virtual administrada por Azure Data Factory. El patrón de configuración de este tutorial se aplica a la copia de un almacén de datos basado en archivos a un almacén de datos relacional. Para obtener una lista de los almacenes de datos que se admiten como orígenes y receptores, consulte la tabla Almacenes de datos y formatos que se admiten.
Nota
Si no está familiarizado con Data Factory, consulte Introducción a Azure Data Factory.
En este tutorial, realizará los siguientes pasos:
- Creación de una factoría de datos.
- Creación de una canalización con una actividad de copia.
Requisitos previos
- Suscripción de Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita de Azure antes de empezar.
- Cuenta de Azure Storage. Usará Blob Storage como almacén de datos de origen. Si no tiene una cuenta de almacenamiento, consulte Crear una cuenta de almacenamiento para crear una. Asegúrese de que la cuenta de almacenamiento solo permita el acceso desde las redes seleccionadas.
- Azure SQL Database. Usará la base de datos como un almacén de datos receptor. Si no tiene una base de datos de Azure SQL, consulte Creación de una base de datos de Azure SQL para ver los pasos para crear una. Asegúrese de que la cuenta de SQL Database solo permite el acceso desde las redes seleccionadas.
Creación de un blob y una tabla SQL
Ahora, prepare su instancia de Blob Storage y su base de datos SQL para el tutorial mediante los pasos siguientes.
Creación de un blob de origen
Abra Bloc de notas. Copie el texto siguiente y guárdelo como un archivo emp.txt en el disco:
FirstName,LastName John,Doe Jane,DoeCree un contenedor denominado adftutorial en su instancia de Blob Storage. Cree una carpeta denominada input en este contenedor. A continuación, cargue el archivo emp.txt en la carpeta input. Use Azure Portal o herramientas como Explorador de Azure Storage para realizar estas tareas.
Creación de una tabla SQL receptora
Use el siguiente script de SQL para crear la tabla dbo.emp en la base de datos SQL:
CREATE TABLE dbo.emp
(
ID int IDENTITY(1,1) NOT NULL,
FirstName varchar(50),
LastName varchar(50)
)
GO
CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Crear una factoría de datos
En este paso, creará una factoría de datos e iniciará la interfaz de usuario de Data Factory para crear una canalización en la factoría de datos.
Abra Microsoft Edge o Google Chrome. Actualmente, solo los exploradores web Microsoft Edge y Google Chrome admiten la interfaz de usuario de Data Factory.
En el menú de la izquierda, seleccione Crear un recurso>Analytics>Data Factory.
En la página Nueva factoría de datos, en Nombre, escriba ADFTutorialDataFactory.
El nombre de la instancia de Azure Data Factory debe ser único de forma global. Si recibe un mensaje de error sobre el valor de nombre, escriba un nombre diferente para la factoría de datos (por ejemplo, yournameADFTutorialDataFactory). Para conocer las reglas de nomenclatura de los artefactos de Data Factory, consulte Azure Data Factory: reglas de nomenclatura.
Seleccione la suscripción de Azure en la que quiere crear la factoría de datos.
Para Grupo de recursos, realice uno de los siguientes pasos:
- Seleccione en primer lugar Usar existentey después un grupo de recursos de la lista desplegable.
- Seleccione Crear nuevoy escriba el nombre de un grupo de recursos.
Para más información sobre los grupos de recursos, consulte Uso de grupos de recursos para administrar los recursos de Azure.
En Versión, seleccione V2.
En Ubicación, seleccione la ubicación de la factoría de datos. En la lista desplegable solo aparecen las ubicaciones que se admiten. Los almacenes de datos (por ejemplo, Azure Storage y SQL Database) y los procesos (por ejemplo, Azure HDInsight) que usa la factoría de datos pueden estar en otras regiones.
Seleccione Crear.
Una vez finalizada la creación, verá el aviso en el centro de notificaciones. Seleccione Ir al recurso para ir a la página de Data Factory.
Seleccione Abrir en el icono Abrir Azure Data Factory Studio para iniciar la interfaz de usuario de Data Factory en una pestaña independiente.
Creación de una instancia de Azure Integration Runtime en una red virtual administrada por Data Factory
En este paso se crea una instancia de Azure Integration Runtime y se habilita una red virtual administrada por Data Factory.
En el portal de Data Factory, vaya a Administrar y seleccione Nuevo para crear una instancia nueva de Azure Integration Runtime.
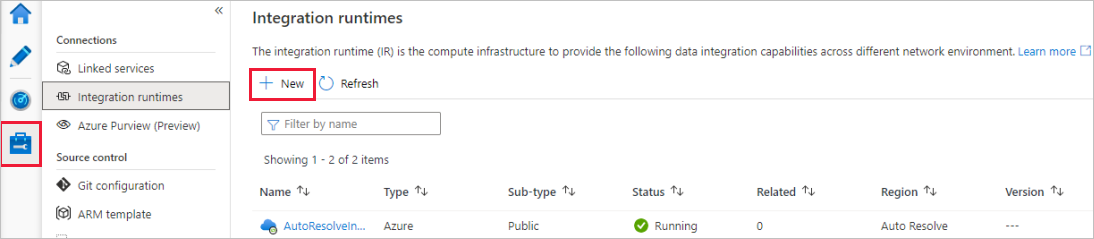
En la página Integration runtime setup (Configuración de Integration Runtime), elija qué entorno de ejecución de integración va a crear según las funcionalidades necesarias. En este tutorial, seleccione Azure, Self-Hosted (Azure, autohospedado) y, luego, haga clic en Continuar.
Seleccione Azure y, luego, haga clic en Continuar para crear un entorno de ejecución de integración de Azure.
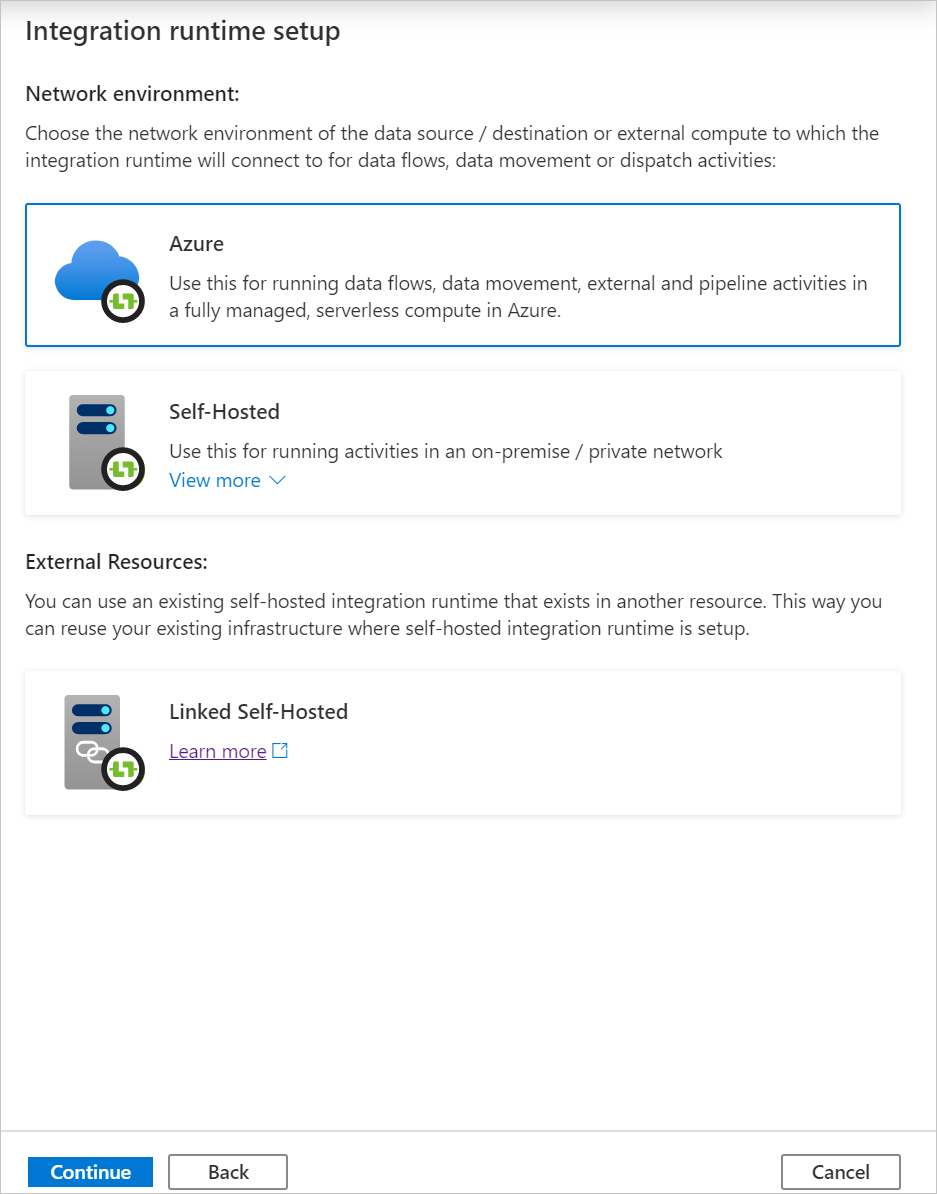
En Configuración de red virtual (versión preliminar) , seleccione Habilitar.
Seleccione Crear.
Crear una canalización
En este paso, creará una canalización con una actividad de copia en la factoría de datos. La actividad de copia realiza la copia de los datos de Blob Storage a SQL Database. En el tutorial de inicio rápido,creó una canalización mediante estos pasos:
- Creación del servicio vinculado.
- Creación del conjunto de datos de entrada y salida.
- Creación de una canalización
En este tutorial, comenzará por crear una canalización. A continuación, creará servicios vinculados y conjuntos de datos cuando los necesite para configurar la canalización.
En la página principal, seleccione Orchestrate (Organizar).
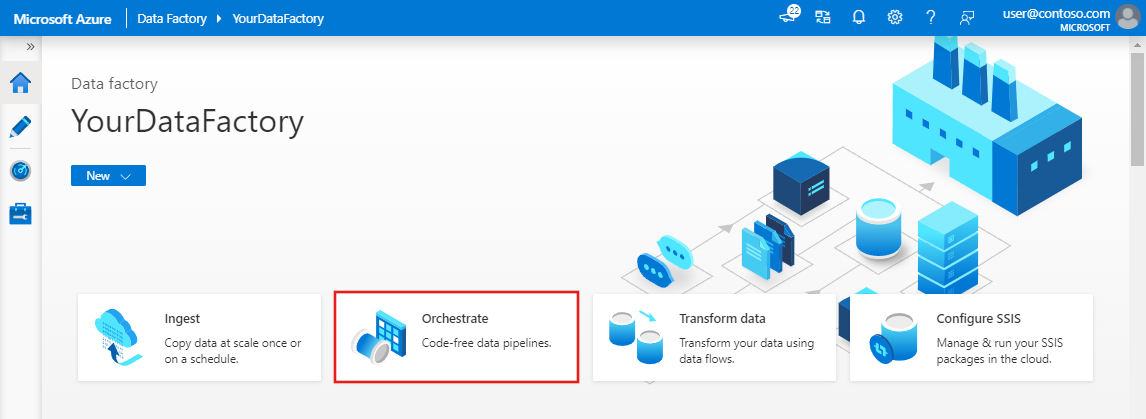
En el panel de propiedades de la canalización, escriba CopyPipeline como nombre de la canalización.
En el cuadro de herramientas Actividades, expanda la categoría Mover y transformar y arrastre la actividad Copiar datos desde el cuadro de herramientas hasta la superficie de diseño de la canalización. Especifique CopyFromBlobToSql como nombre.
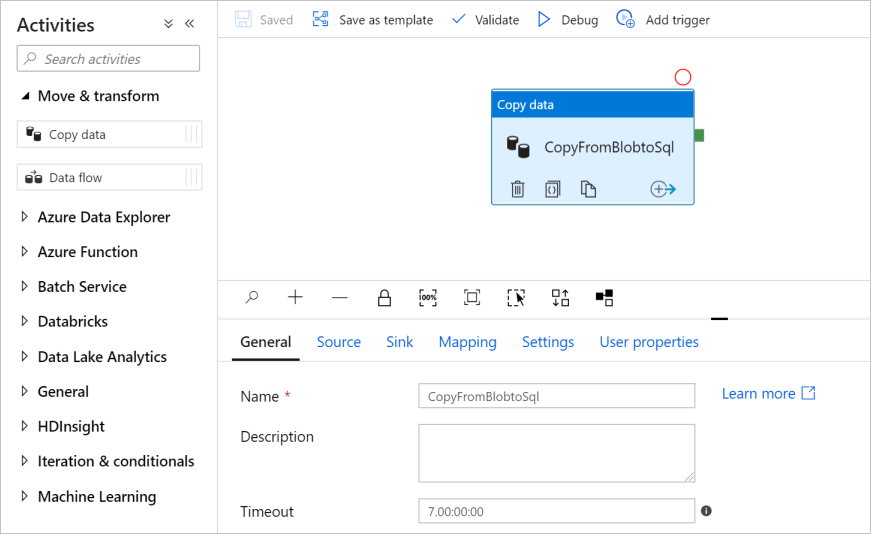
Configuración de un origen de datos
Sugerencia
En este tutorial, usará Clave de cuenta como el tipo de autenticación para el almacén de datos de origen. También puede elegir otros métodos de autenticación admitidos, como URI de SAS,Entidad de servicio e Identidad administrada, si es necesario. Para obtener más información, consulte las secciones correspondientes en Copia y transformación de datos en Azure Blob Storage mediante Azure Data Factory.
Para almacenar los secretos de los almacenes de datos de forma segura, también se recomienda usar su instancia de Azure Key Vault. Para obtener más información e ilustraciones, consulte Almacenamiento de credenciales en Azure Key Vault.
Creación de un conjunto de datos de origen y un servicio vinculado
Vaya a la pestaña Source (Origen). Haga clic en + New (+ Nuevo) para crear un conjunto de datos de origen.
En el cuadro de diálogo New Dataset (Nuevo conjunto de datos), seleccione Azure Blob Storage y, después, seleccione Continue (Continuar). Los datos de origen están en Blob Storage, así que seleccionará Azure Blob Storage como conjunto de datos de origen.
En el cuadro de diálogo Seleccionar formato, elija el tipo de formato de los datos y, después, seleccione Continuar.
En el cuadro de diálogo Establecer propiedades, escriba SourceBlobDataset como Nombre. Active la casilla First row as header (Primera fila como encabezado). En el cuadro de texto Linked service (Servicio vinculado), seleccione + New (+ Nuevo).
En el cuadro de diálogo New linked service (Azure Blob Storage) [Nuevo servicio vinculado (Azure Blob Storage)], escriba AzureStorageLinkedService como Nombre y seleccione su cuenta de almacenamiento en la lista Nombre de la cuenta de almacenamiento.
Asegúrese de habilitar Interactive Authoring (Creación interactiva). Puede tardar aproximadamente un minuto en habilitarse.
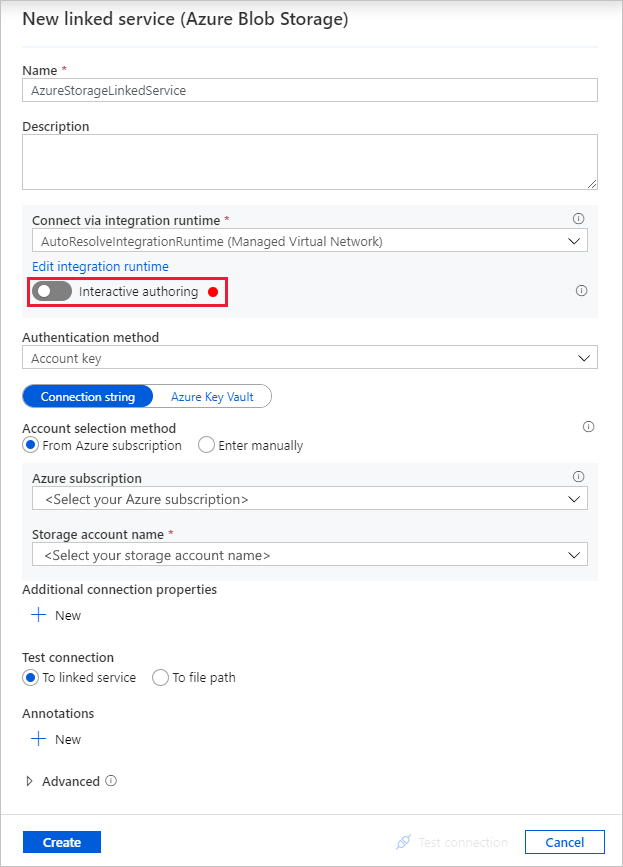
Seleccione Test connection (Probar conexión). Se debería producir un error cuando la cuenta de almacenamiento solo permite el acceso desde las Redes seleccionadas y requiere que Data Factory cree un punto de conexión privado que debe aprobarse antes de su uso. En el mensaje de error, debería ver un vínculo para crear un punto de conexión privado que puede usar para crear un punto de conexión privado administrado. Una alternativa es ir directamente a la pestaña Administrar y seguir las instrucciones de la siguiente sección para crear un punto de conexión privado administrado.
Nota
Es posible que dicha pestaña Administrar no esté disponible para todas las instancias de Data Factory. Si no se muestra, puede tener acceso a los puntos de conexión privados al seleccionarAutor>Conexiones>Punto de conexión privado.
Mantenga abierto el cuadro de diálogo y, después, vaya a la cuenta de almacenamiento.
Siga las instrucciones de esta sección para aprobar el vínculo privado.
Vuelva al cuadro de diálogo. Seleccione de nuevo Probar conexión y seleccione Crear para implementar el servicio vinculado.
Una vez creado el servicio vinculado, se dirige a la página Establecer propiedades. Junto a File path (Ruta de acceso del archivo), seleccione Browse (Examinar).
Vaya a la carpeta adftutorial/input, seleccione el archivo emp.txt y, luego, Finalizar.
Seleccione Aceptar. Se dirige automáticamente a la página de canalización. En la pestaña Origen, confirme que se selecciona SourceBlobDataset. Para obtener una vista previa de los datos de esta página, seleccione Preview data (Vista previa de los datos).
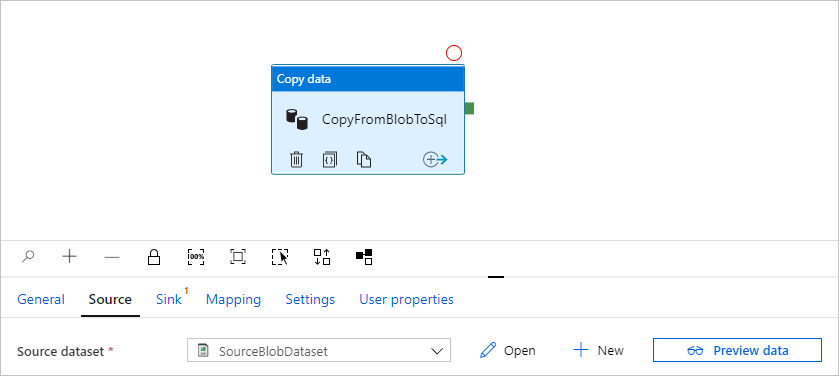
Creación de un punto de conexión privado administrado
Si no seleccionó el hipervínculo al probar la conexión, siga la ruta de acceso. Ahora debe crear un punto de conexión privado administrado que conectará al servicio vinculado que creó anteriormente.
Vaya a la pestaña Administrar.
Nota
Es posible que la pestaña Administrar no esté disponible para todas las instancias de Data Factory. Si no se muestra, puede tener acceso a los puntos de conexión privados al seleccionar Autor>Conexiones>Punto de conexión privado.
Vaya a la sección Puntos de conexión privados administrados.
Seleccione + Nuevo debajo de Puntos de conexión privados administrados.
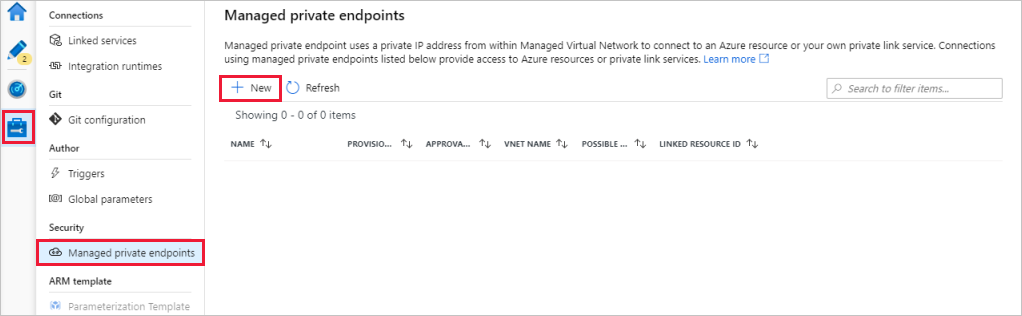
Seleccione el icono de Azure Blob Storage de la lista y seleccione Continuar.
Escriba el nombre de la cuenta de almacenamiento que ha creado.
Seleccione Crear.
Después de unos segundos, debería ver que el vínculo privado creado necesita aprobación.
Seleccione el punto de conexión privado que creó. Puede ver un hipervínculo que le llevará a la página para aprobar el punto de conexión privado en el nivel de cuenta de almacenamiento.
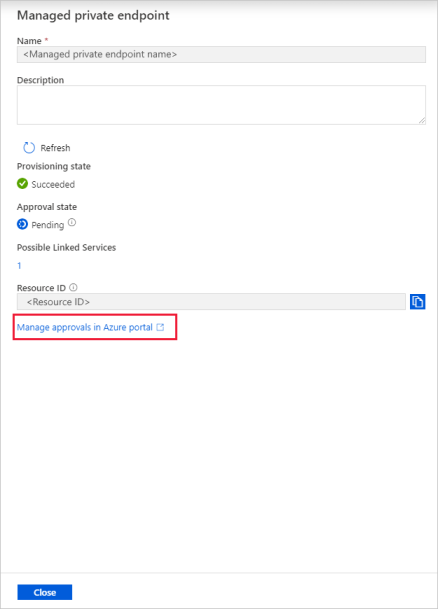
Aprobación de un vínculo privado en una cuenta de almacenamiento
En la cuenta de almacenamiento, vaya a Conexiones de punto de conexión privado en la sección Configuración.
Seleccione la casilla del punto de conexión privado que creó y seleccione Aprobar.
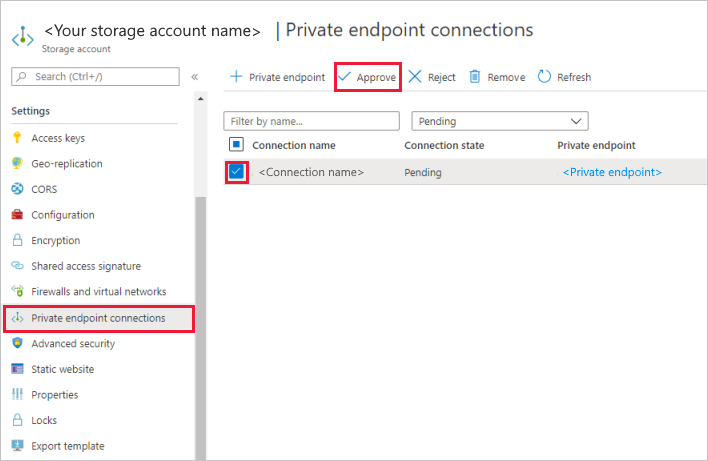
Agregue una descripción y seleccione Sí.
Vuelva a la sección Puntos de conexión privados administrados de la pestaña Administrar de Data Factory.
Tras aproximadamente uno o dos minutos, debería asegurarse de que la aprobación del punto de conexión privado aparezca en la interfaz de usuario de Data Factory.
Configuración de un receptor
Sugerencia
En este tutorial, usará Autenticación de SQL como el tipo de autenticación para el almacén de datos del receptor. También puede elegir otros métodos de autenticación admitidos, como Entidad de servicio e Identidad administrada, si es necesario. Para obtener más información, consulte las secciones correspondientes en Copia y transformación de datos en Azure SQL Database mediante Azure Data Factory.
Para almacenar los secretos de los almacenes de datos de forma segura, también se recomienda usar su instancia de Azure Key Vault. Para obtener más información e ilustraciones, consulte Almacenamiento de credenciales en Azure Key Vault.
Creación de un conjunto de datos receptor y un servicio vinculado
Vaya a la pestaña Sink (Receptor) y seleccione + New (+Nuevo) para crear un conjunto de datos del receptor.
En el cuadro de diálogo Nuevo conjunto de datos, escriba SQL en el cuadro de búsqueda para filtrar los conectores. Seleccione Azure SQL Database y luego Continuar. En este tutorial, copiará los datos en una base de datos SQL.
En el cuadro de diálogo Establecer propiedades, escriba OutputSqlDataset como Nombre. En la lista desplegable Servicio vinculado, seleccione + Nuevo. Un conjunto de datos debe estar asociado con un servicio vinculado. El servicio vinculado tiene la cadena de conexión que usa Data Factory para conectarse a la base de datos SQL en tiempo de ejecución. El conjunto de datos especifica el contenedor, la carpeta y el archivo (opcional) donde se copian los datos.
En el cuadro de diálogo New linked service (Azure SQL Database) [Nuevo servicio vinculado (Azure SQL Database)], realice los siguientes pasos:
- En Name (Nombre), escriba AzureSqlDatabaseLinkedService.
- En Server name (Nombre del servidor), seleccione su instancia de SQL Server.
- Asegúrese de habilitar Interactive Authoring (Creación interactiva).
- En Database name (Nombre de la base de datos), seleccione la base de datos SQL.
- En User name (Nombre de usuario), escriba el nombre del usuario.
- En Password (Contraseña), escriba la contraseña del usuario.
- Seleccione Test connection (Probar conexión). Debería producirse un error porque SQL Server solo permite el acceso desde las Redes seleccionadas y requiere que Azure Data Factory cree un punto de conexión privado, que debe aprobarse antes de su uso. En el mensaje de error, debería ver un vínculo para crear un punto de conexión privado que puede usar para crear un punto de conexión privado administrado. Una alternativa es ir directamente a la pestaña Administrar y seguir las instrucciones de la siguiente sección para crear un punto de conexión privado administrado.
- Mantenga abierto el cuadro de diálogo y, a continuación, vaya a la instancia de SQL Server seleccionada.
- Siga las instrucciones de esta sección para aprobar el vínculo privado.
- Vuelva al cuadro de diálogo. Seleccione de nuevo Probar conexión y seleccione Crear para implementar el servicio vinculado.
Se dirigirá automáticamente al cuadro de diálogo Establecer propiedades. En Table (Tabla), seleccione [dbo].[emp] . Después, seleccione Aceptar.
Vaya a la pestaña con la canalización y, en Sink dataset (Conjunto de datos del receptor), confirme que se ha seleccionado OutputSqlDataset.
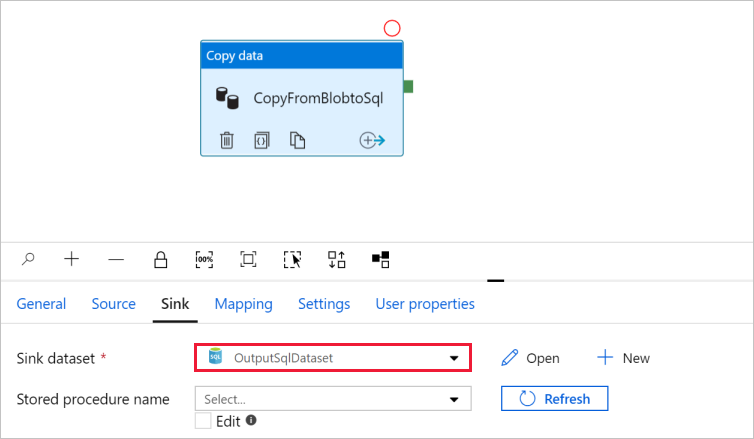
Opcionalmente, puede asignar el esquema del origen al esquema de destino correspondiente. Para ello, siga las instrucciones de Asignación de esquemas en la actividad de copia.
Creación de un punto de conexión privado administrado
Si no seleccionó el hipervínculo al probar la conexión, siga la ruta de acceso. Ahora debe crear un punto de conexión privado administrado que conectará al servicio vinculado que creó anteriormente.
Vaya a la pestaña Administrar.
Vaya a la sección Puntos de conexión privados administrados.
Seleccione + Nuevo debajo de Puntos de conexión privados administrados.
Seleccione el icono de Azure SQL Database de la lista y seleccione Continuar.
Escriba el nombre de la instancia de SQL Server que seleccionó.
Seleccione Crear.
Después de unos segundos, debería ver que el vínculo privado creado necesita aprobación.
Seleccione el punto de conexión privado que creó. Puede ver un hipervínculo que le llevará a la página para aprobar el punto de conexión privado en el nivel de instancia de SQL Server.
Aprobación de un vínculo privado en SQL Server
- En la instancia de SQL Server, vaya a Conexiones de punto de conexión privado en la sección Configuración.
- Seleccione la casilla del punto de conexión privado que creó y seleccione Aprobar.
- Agregue una descripción y seleccione Sí.
- Vuelva a la sección Puntos de conexión privados administrados de la pestaña Administrar de Data Factory.
- La aprobación para el punto de conexión privado debe tardar uno o dos minutos en aparecer.
Depuración y publicación de la canalización
Puede depurar una canalización antes de publicar artefactos (servicios vinculados, conjuntos de datos y canalizaciones) en Data Factory o en su propio repositorio Git de Azure Repos.
- Para depurar la canalización, seleccione Depurar en la barra de herramientas. Verá el estado de ejecución de la canalización en la pestaña Output (Salida) en la parte inferior de la ventana.
- Después de que la canalización se puede ejecutar correctamente, en la barra de herramientas superior, seleccione Publicar todo. Esta acción publica las entidades (conjuntos de datos y canalizaciones) que creó para Data Factory.
- Espere a que aparezca el mensaje Successfully published (Publicado correctamente). Para ver los mensajes de notificación, seleccione Mostrar notificaciones en la esquina superior derecha (botón de campana).
Resumen
La canalización de este ejemplo copia datos de Blob Storage a SQL Database mediante puntos de conexión privados en una red virtual administrada por Data Factory. Ha aprendido a:
- Creación de una factoría de datos.
- Creación de una canalización con una actividad de copia.