Habilitar la configuración del acceso a datos
En este artículo se describen las configuraciones de acceso a datos que los administradores de Azure Databricks realizan para todos los almacenes de SQL mediante la interfaz de usuario.
Nota:
Si el área de trabajo está habilitada para Unity Catalog, no es necesario realizar los pasos descritos en este artículo. Unity Catalog admite almacenes de SQL de forma predeterminada.
Databricks recomienda usar volúmenes de Catálogo de Unity o ubicaciones externas para conectarse al almacenamiento de objetos en la nube en lugar de perfiles de instancia. Unity Catalog simplifica la seguridad y gobernanza de los datos proporcionando un lugar central para administrar y auditar el acceso a datos en varias áreas de trabajo de la cuenta. Consulte ¿Qué es Unity Catalog? Recomendaciones y para usar ubicaciones externas.
Para configurar todos los almacenes de SQL con la API de REST, consulte SQL Warehouses API.
Importante
Al cambiar esta configuración, se reinician todos los almacenes de SQL en ejecución.
Para obtener información general sobre cómo habilitar el acceso a los datos, consulte Listas de control de acceso.
Requisitos
- Es necesario ser administrador del área de trabajo de Azure Databricks para configurar los valores de todos los almacenes de SQL.
Configuración de una entidad de servicio
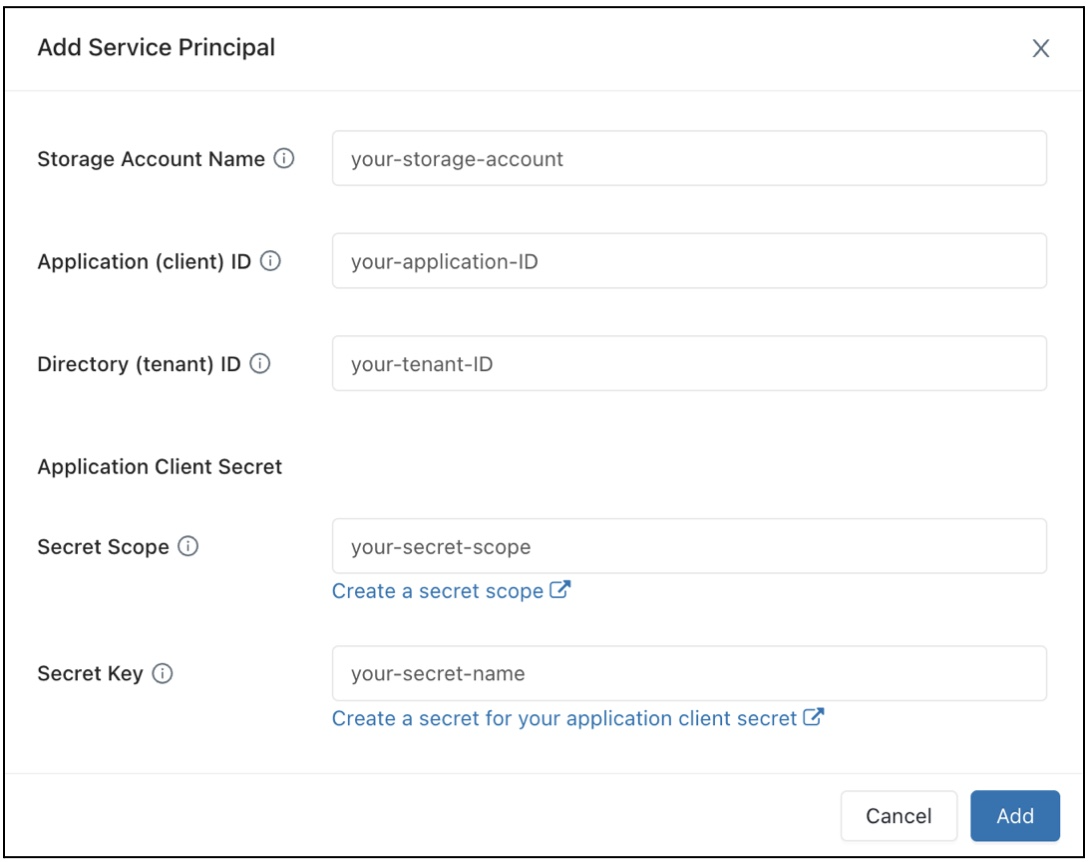
Para configurar el acceso de los almacenes de SQL a una cuenta de almacenamiento de Azure Data Lake Storage Gen2 mediante entidades de servicio, siga estos pasos:
Registre una aplicación Microsoft Entra ID (anteriormente Azure Active Directory) y registre las siguientes propiedades:
- Id. de aplicación (cliente): Un Id. que identifica de forma única la aplicación Microsoft Entra ID (anteriormente Azure Active Directory).
- Id. de directorio (inquilino): id. único de la instancia de Microsoft Entra ID (denominada id. de directorio [inquilino] en Azure Databricks).
- Secreto de cliente: el valor de un secreto de cliente que se ha creado para este registro de aplicación. La aplicación usará esta cadena secreta para probar su identidad.
En la cuenta de almacenamiento, agregue una asignación de roles para la aplicación que se ha registrado en el paso anterior a fin de concederle acceso a la cuenta de almacenamiento.
Cree un ámbito de secreto con el respaldo de Azure Key Vault o un ámbito secreto con el respaldo de Databricks y registre el valor de la propiedad de nombre de ámbito:
- Nombre del ámbito: nombre del ámbito de secreto que se ha creado.
Si usa Azure Key Vault, vaya a la sección Secretos y vea Creación de un secreto en un ámbito respaldado por Azure Key Vault. A continuación, use el secreto” de cliente que obtuvo en el “paso 1 para rellenar el “campo de valor” de este secreto. Mantenga un registro del nombre del secreto que acaba de elegir.
- Nombre del secreto: el nombre del secreto de Azure Key Vault que se ha creado.
Si usa un ámbito con el respaldo de Databricks, cree un nuevo secreto mediante la CLI de Databricks y úselo para almacenar el secreto de cliente que obtuvo en el paso 1. Mantenga un registro de la clave del secreto que ha introducido en este paso.
- Clave secreta: clave del secreto que se ha creado con respaldo de Databricks.
Nota:
Opcionalmente, puede crear un secreto adicional para almacenar el identificador de cliente obtenido en el paso 1.
Haga clic en el nombre de usuario en la barra superior del área de trabajo y seleccione Configuración en la lista desplegable.
Haga clic en la pestaña Proceso.
Haga clic en Administrar junto a almacenes de SQL.
En el campo "Configuración de acceso a datos", haga clic en el botón Agregar entidad de servicio.
Configure las propiedades de la cuenta de almacenamiento de Azure Data Lake Storage Gen2.
Haga clic en Agregar.
Verá que se han agregado nuevas entradas al cuadro de texto Configuración de acceso a datos.
Haga clic en Save(Guardar).
También puede editar las entradas del cuadro de texto Configuración de acceso a datos directamente.
Configuración de las propiedades de acceso a datos para almacenes de SQL
Para configurar todos los almacenes con propiedades de acceso a datos, haga lo siguiente:
Haga clic en el nombre de usuario en la barra superior del área de trabajo y seleccione Configuración en la lista desplegable.
Haga clic en la pestaña Proceso.
Haga clic en Administrar junto a Almacenes de SQL.
En el cuadro de texto Configuración de acceso a datos, especifique pares clave-valor que contengan propiedades de metastore.
Importante
Para establecer una propiedad de configuración de Spark en el valor de un secreto sin mostrar el valor en Spark, establezca el valor en
{{secrets/<secret-scope>/<secret-name>}}. Reemplace<secret-scope>por el ámbito de secreto y<secret-name>por el nombre de secreto. El valor debe comenzar por{{secrets/y terminar por}}. Para obtener más información sobre esta sintaxis, consulte Sintaxis para hacer referencia a secretos en una propiedad de configuración de Spark o en una variable de entorno.Haga clic en Save(Guardar).
También puede configurar las propiedades de acceso a datos con el proveedor de Databricks Terraform y databricks_sql_global_config.
Propiedades admitidas
En el caso de una entrada que termine por
*, se admiten todas las propiedades dentro de dicho prefijo.Por ejemplo,
spark.sql.hive.metastore.*indica que se admitenspark.sql.hive.metastore.jarsyspark.sql.hive.metastore.version, así como cualquier otra propiedad que comience porspark.sql.hive.metastore.En el caso de las propiedades cuyos valores contienen información confidencial, puede almacenar dicha información en un secreto y establecer el valor de la propiedad en el nombre del secreto mediante la siguiente sintaxis:
secrets/<secret-scope>/<secret-name>.
Se admiten las siguientes propiedades para los almacenes de SQL:
spark.sql.hive.metastore.*spark.sql.warehouse.dirspark.hadoop.datanucleus.*spark.hadoop.fs.*spark.hadoop.hive.*spark.hadoop.javax.jdo.option.*spark.hive.*
Para más información sobre cómo establecer estas propiedades, consulte Metastore de Hive externo.