Servicio de modelos heredados MLflow en Azure Databricks
Importante
Esta característica está en versión preliminar pública.
Importante
- Esta documentación se ha retirado y es posible que no se actualice. Los productos, servicios o tecnologías mencionados en este contenido ya no se admiten.
- Las guía de este artículo es para el servicio de modelos de MLflow heredado. Databricks recomienda migrar los flujos de trabajo del servicio del modelo al servicio de modelos para la implementación y escalabilidad del punto de conexión del modelo mejorado. Para obtener más información, consulte servicio de modelos con Azure Databricks.
El servicio de modelos de MLflow heredado permite hospedar modelos de Machine Learning del registro de modelos como puntos de conexión REST que se actualizan automáticamente en función de la disponibilidad de las versiones del modelo y de sus fases. Usa un clúster de nodo único que se ejecuta en su propia cuenta dentro de lo que ahora se denomina plano de proceso clásico. Este plano de proceso incluye la red virtual y los recursos de proceso asociados, como clústeres para cuadernos y trabajos, almacenes de SQL clásicos y pro, y puntos de conexión de servicio de modelos heredado.
Al habilitar el servicio de modelos para un modelo registrado determinado, Azure Databricks crea automáticamente un clúster único para el modelo e implementa todas las versiones no archivadas del modelo en ese clúster. Azure Databricks reinicia el clúster si se produce un error y finaliza el clúster al deshabilitar el servicio de modelos para el modelo. El servicio de modelos se sincroniza automáticamente con el registro de modelos e implementa las nuevas versiones de modelos registradas. Las versiones del modelo implementadas se pueden consultar con una solicitud de API REST estándar. Azure Databricks autentica las solicitudes al modelo mediante su autenticación estándar.
Aunque este servicio está en versión preliminar, Databricks recomienda su uso para aplicaciones de bajo rendimiento y no críticas. El rendimiento de destino es de 200 qps y la disponibilidad de destino es del 99,5 %, aunque tampoco se garantiza. Además, hay un límite de tamaño de carga de 16 MB por solicitud.
Cada versión del modelo se implementa mediante la implementación de modelo de MLflow y se ejecuta en un entorno de Conda especificado por sus dependencias.
Nota:
- El clúster se mantiene siempre que el servicio esté habilitado, incluso si no existe ninguna versión de modelo activa. Para finalizar el clúster de servicio, deshabilite el servicio de modelos para el modelo registrado.
- El clúster se considera un clúster de uso general, sujeto a los precios de cargas de trabajo de uso general.
- Los scripts de inicialización globales no se ejecutan en clústeres de modelos de servicio.
Importante
Anaconda Inc. actualizó sus términos del servicio para los canales de anaconda.org. Según los nuevos términos del servicio, puede necesitar una licencia comercial si depende del empaquetado y la distribución de Anaconda. Consulte las preguntas más frecuentes sobre Anaconda Commercial Edition para obtener más información. El uso de cualquier canal de Anaconda se rige por sus términos del servicio.
Los modelos de MLflow registrados antes de la versión 1.18 (Databricks Runtime 8.3 ML o versiones anteriores) se registraron de forma predeterminada con el canal de Conda defaults (https://repo.anaconda.com/pkgs/) como dependencia. Debido a este cambio de licencia, Databricks ha detenido el uso del canal defaults para los modelos registrados mediante MLflow v1.18 y versiones posteriores. El canal predeterminado registrado es ahora conda-forge, que apunta a la comunidad administrada https://conda-forge.org/.
Si registró un modelo antes de MLflow v1.18 sin excluir el canal defaults del entorno de Conda para el modelo, es posible que ese modelo tenga una dependencia en el defaults canal que no haya previsto.
Para confirmar manualmente si un modelo tiene esta dependencia, puede examinar el valor channel en el archivo conda.yaml que se empaqueta con el modelo registrado. Por ejemplo, un modelo conda.yaml con una dependencia de canal defaults puede tener este aspecto:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Dado que Databricks no puede determinar si el uso del repositorio de Anaconda para interactuar con los modelos está permitido en su relación con Anaconda, Databricks no obliga a sus clientes a realizar ningún cambio. Si el uso del repositorio de Anaconda.com mediante el uso de Databricks está permitido en los términos de Anaconda, no es necesario realizar ninguna acción.
Si desea cambiar el canal usado en el entorno de un modelo, puede volver a registrar el modelo en el registro de modelos con un nuevo conda.yaml. Para ello, especifique el canal en el parámetro conda_env de log_model().
Para más información sobre la log_model() API, consulte la documentación de MLflow para el tipo de modelo con el que está trabajando, por ejemplo, log_model para scikit-learn.
Para más información sobre los archivos conda.yaml, consulte la documentación de MLflow.
Requisitos
- El Servicio de modelos de MLflow heredado está disponible para los modelos MLflow de Python. Debe declarar todas las dependencias del modelo en el entorno de Conda. Consulte Dependencias del modelo de registro.
- Para habilitar el servicio de modelos, debe tener permiso de creación de clústeres.
Servicio de modelos desde el registro de modelos
El servicio de modelos está disponible en Azure Databricks desde el registro de modelos.
Habilitación y deshabilitación del servicio de modelos
Puede habilitar un modelo al que servir desde su página de modelo registrado.
Haga clic en la pestaña Serving (Servicio). Si el modelo aún no está habilitado para servir, aparece el botón Enable Serving (Habilitar servicio).
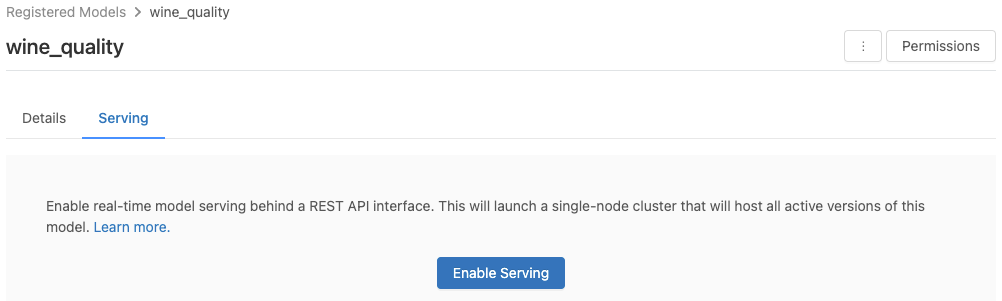
Haga clic en Enable Serving (Habilitar servicio). La pestaña Serving (Servicio) aparece con el Estado como Pendiente. Después de unos minutos, el Estado cambia a Listo.
Para deshabilitar un modelo del servicio, haga clic en Detener.
Validación del servicio de modelos
En la pestaña Serving (Servicio), puede enviar una solicitud al modelo de servicio y ver la respuesta.
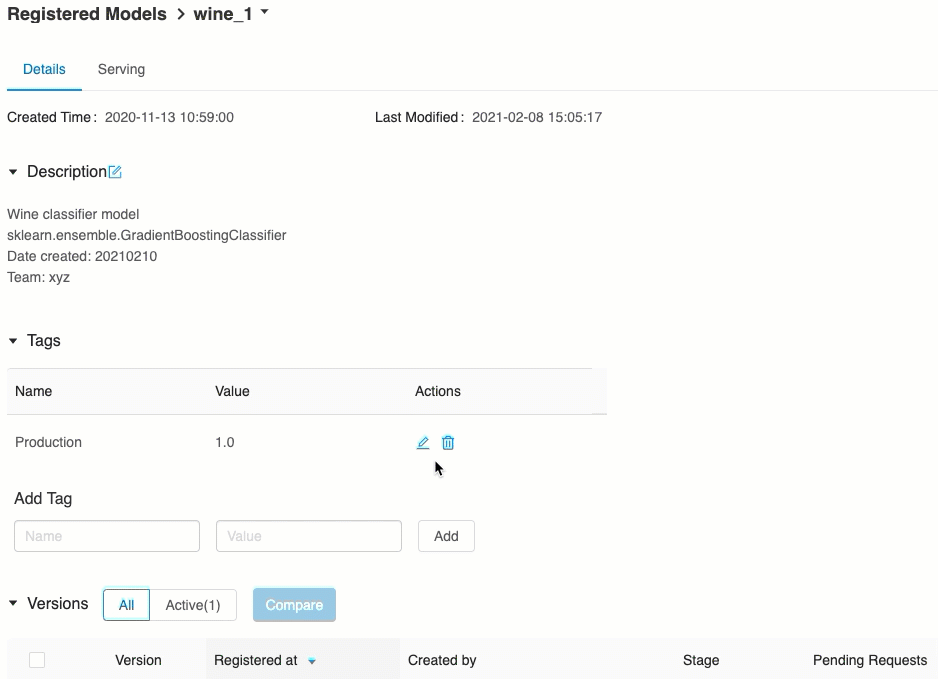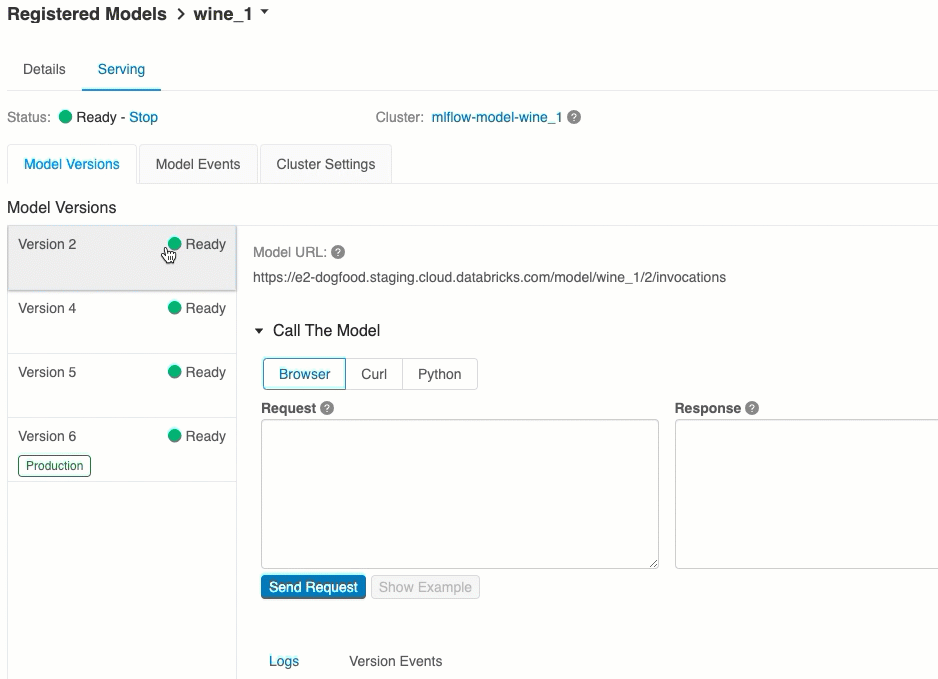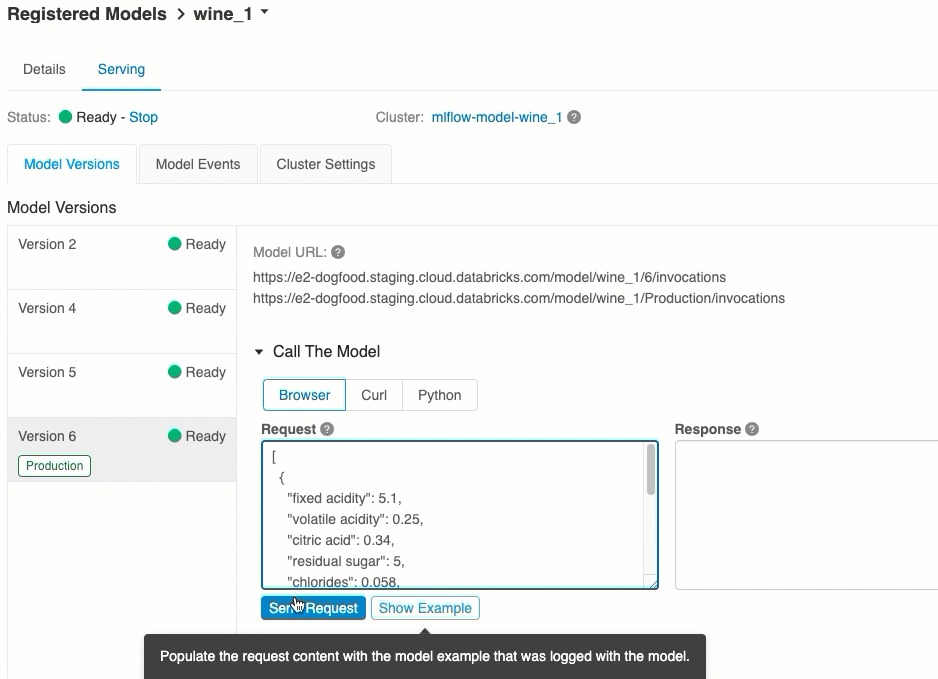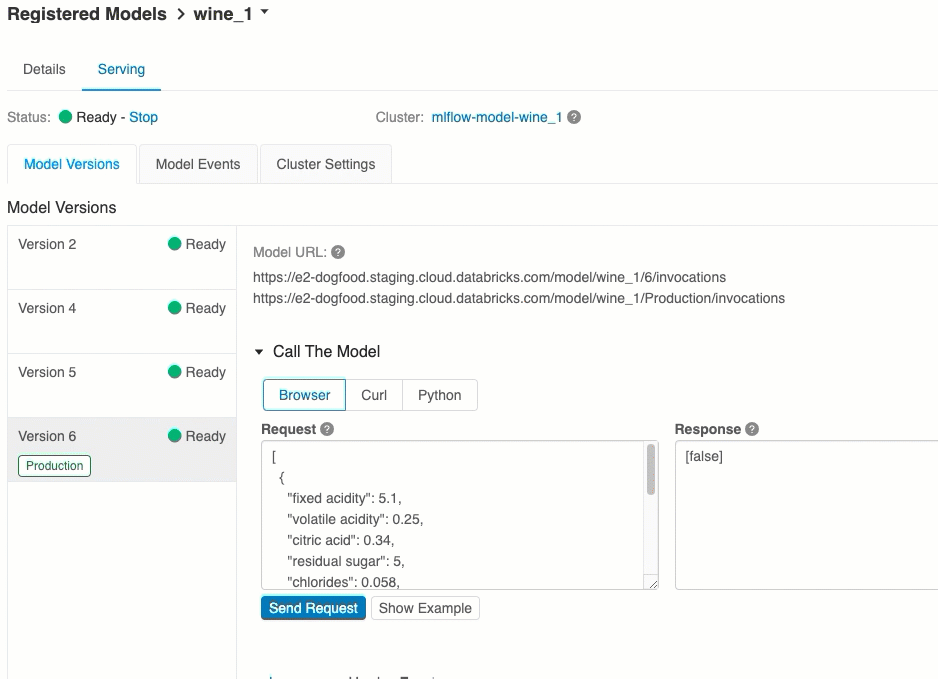
URI de versión de modelo
A cada versión del modelo implementado se le asignan uno o varios URI únicos. Como mínimo, a cada versión del modelo se le asigna un URI construido de la siguiente manera:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Por ejemplo, para llamar a la versión 1 de un modelo registrado como iris-classifier, use este URI:
https://<databricks-instance>/model/iris-classifier/1/invocations
También puede llamar a una versión del modelo por su fase. Por ejemplo, si la versión 1 está en la fase de producción, también se puede puntuar con este URI:
https://<databricks-instance>/model/iris-classifier/Production/invocations
La lista de URI de modelo disponibles aparece en la parte superior de la pestaña Versiones de modelos de la página de servicio.
Administración de versiones de servicio
Se implementan todas las versiones de modelo activas (no archivadas), y puede consultarlas mediante los URI. Azure Databricks implementa automáticamente nuevas versiones de modelo cuando se registran, y quita automáticamente las versiones anteriores cuando se archivan.
Nota:
Todas las versiones implementadas de un modelo registrado comparten el mismo clúster.
Administración de los derechos de acceso del modelo
Los derechos de acceso del modelo se heredan del registro de modelos. La habilitación o deshabilitación de la característica de servicio requiere el permiso "administrar" en el modelo registrado. Cualquier persona con derechos de lectura puede puntuar cualquiera de las versiones implementadas.
Puntuación de versiones de modelo implementadas
Para puntuar un modelo implementado, puede usar la interfaz de usuario o enviar una solicitud de API REST al URI del modelo.
Puntuación a través de la interfaz de usuario
Esta es la manera más fácil y rápida de probar el modelo. Puede insertar los datos de entrada del modelo en formato JSON y hacer clic en Enviar solicitud. Si el modelo se ha registrado con un ejemplo de entrada (como se muestra en el gráfico anterior), haga clic en Cargar ejemplo para cargar el ejemplo de entrada.
Puntuación a través de la solicitud de API REST
Puede enviar una solicitud de puntuación a través de la API REST mediante la autenticación estándar de Databricks. En los ejemplos siguientes, se muestra la autenticación mediante un token de acceso personal con MLflow 1.x.
Nota:
Como procedimiento recomendado de seguridad, cuando se autentique con herramientas, sistemas, scripts y aplicaciones automatizados, Databricks recomienda usar los tokens de acceso personal pertenecientes a las entidades de servicio en lugar de a los usuarios del área de trabajo. Para crear tókenes para entidades de servicio, consulte Administración de tokens de acceso para una entidad de servicio.
En los ejemplos siguientes se muestra cómo consultar un modelo servido dado un elemento MODEL_VERSION_URI como https://<databricks-instance>/model/iris-classifier/Production/invocations (donde <databricks-instance> es el nombre de la instancia de Databricks) y un token de la API REST de Databricks que se denomine DATABRICKS_API_TOKEN:
Los ejemplos siguientes reflejan el formato de puntuación de los modelos creados con MLflow 1.x. Si prefiere usar MLflow 2.0, debe actualizar el formato de la carga de la solicitud.
Bash
Fragmento de código para consultar un modelo que acepta entradas de trama de datos.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
Fragmento de código para consultar un modelo que acepta entradas de tensor. Las entradas de tensor deben tener el formato descrito en la documentación de la API de TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Powerbi
Puede puntuar un conjunto de datos en Power BI Desktop con los pasos siguientes:
Abra el conjunto de datos que desea puntuar.
Vaya a Transformar datos.
Haga clic con el botón derecho en el panel izquierdo y seleccione Crear nueva consulta.
Vaya a Ver > Editor avanzado.
Reemplace el cuerpo de la consulta por el fragmento de código siguiente, después de rellenar un
DATABRICKS_API_TOKENyMODEL_VERSION_URIadecuados.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionAsigne a la consulta el nombre del modelo deseado.
Abra el editor de consultas avanzada para el conjunto de datos y aplique la función de modelo.
Supervisión de modelos de servicio
La página de servicio muestra indicadores de estado para el clúster de servicio, así como versiones de modelo individuales.
- Para inspeccionar el estado del clúster de servicio, use la pestaña Model Events (Eventos de modelo), que muestra una lista de todos los eventos de servicio para este modelo.
- Para inspeccionar el estado de una sola versión del modelo, haga clic en la pestaña Versiones de modelos y desplácese para ver las pestañas Registros o Version Events (Eventos de versiones).
Personalización del clúster de servicio
Para personalizar el clúster de servicio, use la pestaña Configuración del clúster de la pestaña Serving (Servicio).
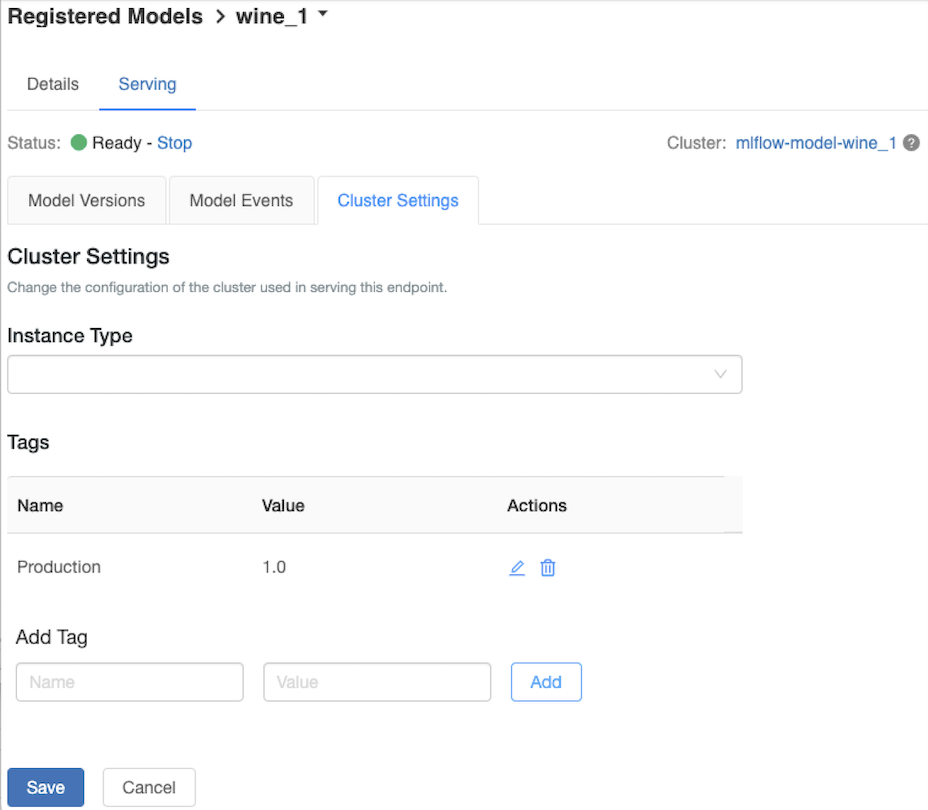
- Para modificar el tamaño de memoria y el número de núcleos de un clúster de servicio, use el menú desplegable Tipo de instancia para seleccionar la configuración de clúster deseada. Al hacer clic en Guardar, el clúster existente finaliza y se crea un nuevo clúster con la configuración especificada.
- Para agregar una etiqueta, escriba el nombre y el valor en los campos Agregar etiqueta y haga clic en Agregar.
- Para editar o eliminar una etiqueta existente, haga clic en uno de los iconos de la columna Acciones de la tabla Etiquetas.
Integración del Almacén de características
El servicio de modelos heredado puede buscar de forma automática los valores de las características en los almacenes en línea publicados.
.. aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
Errores conocidos
ResolvePackageNotFound: pyspark=3.1.0
Este error puede producirse si un modelo depende de pyspark y se registra mediante Databricks Runtime 8.x.
Si ve este error, especifique la versión pyspark explícitamente al registrar el modelo mediante el parámetro conda_env.
Unrecognized content type parameters: format
Este error puede producirse como resultado del nuevo formato de protocolo de puntuación MLflow 2.0. Si el error aparece, es probable que esté usando un formato de solicitud de puntuación obsoleto. Para resolver el error, puede hacer lo siguiente:
Actualice el formato de la solicitud de puntuación al protocolo más reciente.
Nota:
Los ejemplos siguientes reflejan el formato de puntuación introducido en MLflow 2.0. Si prefiere usar MLflow 1.x, puede modificar las llamadas API a
log_model()para incluir la dependencia de versión de MLflow que quiera en el parámetroextra_pip_requirements. Al hacerlo, se garantiza el uso del formato de puntuación adecuado.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
Consulta de un modelo que acepta entradas de dataframe de Pandas.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Consulta de un modelo que acepta entradas de tensor. Las entradas de tensor deben tener el formato descrito en la documentación de la API de TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)Powerbi
Puede puntuar un conjunto de datos en Power BI Desktop con los pasos siguientes:
Abra el conjunto de datos que desea puntuar.
Vaya a Transformar datos.
Haga clic con el botón derecho en el panel izquierdo y seleccione Crear nueva consulta.
Vaya a Ver > Editor avanzado.
Reemplace el cuerpo de la consulta por el fragmento de código siguiente, después de rellenar un
DATABRICKS_API_TOKENyMODEL_VERSION_URIadecuados.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionAsigne a la consulta el nombre del modelo deseado.
Abra el editor de consultas avanzada para el conjunto de datos y aplique la función de modelo.
Si la solicitud de puntuación usa el cliente de MLflow, como
mlflow.pyfunc.spark_udf(), actualice el cliente de MLflow a la versión 2.0 o posterior para usar el formato más reciente. Obtenga más información sobre el protocolo de puntuación del modelo de MLflow en MLflow 2.0 actualizado.
Para obtener más información sobre los formatos de datos de entrada aceptados por el servidor (por ejemplo, el formato con orientación split de Pandas), consulte la documentación de MLflow.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de