Proceso
El proceso de Azure Databricks hace referencia a la selección de recursos informáticos disponibles en el área de trabajo de Azure Databricks. Los usuarios necesitan acceso a un proceso para ejecutar cargas de trabajo de ingeniería de datos, ciencia de datos y análisis de datos, como canalizaciones de ETL de producción, análisis de streaming, análisis ad hoc y aprendizaje automático.
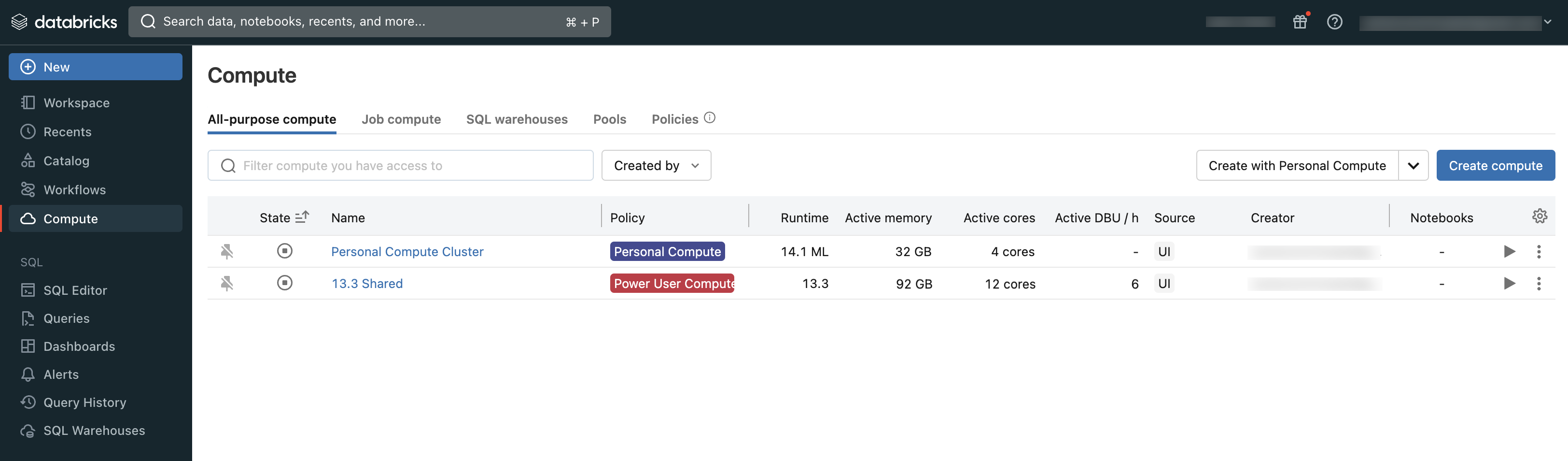
Los usuarios pueden conectarse al proceso existente o crear uno nuevo si tienen los permisos adecuados.
Consulte el proceso al que tiene acceso mediante la sección Proceso del área de trabajo:
Tipos de proceso
Estos son los tipos de procesos disponibles en Azure Databricks:
Proceso sin servidor para cuadernos (versión preliminar pública): Proceso escalable y a petición que se usa para ejecutar código SQL y Python en cuadernos.
Proceso sin servidor para flujos de trabajo (versión preliminar pública): Proceso escalable a petición que se usa para ejecutar los trabajos de Databricks sin configurar e implementar la infraestructura.
Proceso de uso completo: Proceso aprovisionado que se usa para analizar datos en cuadernos. Puede crear, finalizar y reiniciar este proceso mediante la interfaz de usuario, la CLI o la API de REST.
Proceso de trabajo: Proceso aprovisionado que se usa para ejecutar trabajos automatizados. El programador de trabajos de Azure Databricks crea automáticamente un proceso de trabajo cada vez que se configura un trabajo para ejecutarse en un nuevo proceso. El proceso finaliza cuando se completa el trabajo. No puede reiniciar un proceso de trabajo. Consulte Uso del proceso de Azure Databricks con los trabajos.
Grupos de instancias: Proceso con instancias inactivas y listas para usar que se usan para reducir los tiempos de inicio y escalado automático. Puede crear este proceso mediante la interfaz de usuario, la CLI o la API de REST.
Almacenes de SQL sin servidor: proceso elástico a petición que se usa para ejecutar comandos SQL en objetos de datos en el editor de SQL o cuadernos interactivos. Puede crear almacenes de SQL mediante la interfaz de usuario, la CLI o la API de REST.
Almacenes de SQL clásicos: se usan para ejecutar comandos SQL en objetos de datos en el editor de SQL o cuadernos interactivos. Puede crear almacenes de SQL mediante la interfaz de usuario, la CLI o la API de REST.
En los artículos de esta sección se describe cómo trabajar con recursos de proceso mediante la interfaz de usuario de Azure Databricks. Para ver otros métodos, consulte Uso de la línea de comandos y la referencia de laDatabricks API de REST.
Databricks Runtime
Databricks Runtime es el conjunto de componentes principales que se ejecutan en el proceso. Databricks Runtime es un parámetro configurable universal para todos los procesos de trabajos, pero se selecciona automáticamente en los almacenes de SQL.
Cada versión de Databricks Runtime incluye actualizaciones que mejoran la usabilidad, el rendimiento y la seguridad de los análisis de big data. Databricks Runtime en el proceso agrega muchas características, entre las que se incluyen:
- Delta Lake, una capa de almacenamiento de próxima generación creada sobre Apache Spark que proporciona transacciones ACID, diseños e índices optimizados y mejoras del motor de ejecución para crear canalizaciones de datos. Consulte ¿Qué es Delta Lake?
- Bibliotecas de Java, Scala, Python y R instaladas.
- Ubuntu y sus bibliotecas del sistema.
- Bibliotecas de GPU para clústeres habilitados para GPU.
- Servicios de Azure Databricks que se integran con otros componentes de la plataforma, como, por ejemplo, cuadernos, trabajos y administración de clústeres.
Para obtener información sobre el contenido de cada versión del entorno de ejecución, consulte las notas de la versión.
Control de versiones en tiempo de ejecución
Las versiones de Databricks Runtime se publican de forma periódica:
- Las versiones de soporte técnico a largo plazo se representan mediante un calificador LTS (por ejemplo, 3,5 LTS). Para cada versión principal, declaramos una versión de característica "canónica", para la que proporcionamos tres años completos de soporte técnico. Consulte Ciclos de vida de soporte técnico del entorno de ejecución de Databricks para más información.
- Las versiones principales se representan mediante un incremento en el número de versión que precede al separador decimal (el salto de 3.5 a 4.0, por ejemplo). Se publican cuando hay cambios importantes, algunos de los cuales pueden no ser compatibles con versiones anteriores.
- Las versiones de características se representan mediante un incremento en el número de versión que precede al separador decimal (el salto de 3.4 a 3.5, por ejemplo). Cada versión principal incluye varias versiones de características. Las versiones de características siempre son compatibles con versiones anteriores de su versión principal.