Proceso sin servidor para cuadernos
Importante
Esta característica está en versión preliminar pública. Para obtener información sobre la idoneidad y la habilitación, consulte Habilitación de la versión preliminar pública de proceso sin servidor.
En este artículo se explica cómo usar el proceso sin servidor para cuadernos. Para obtener información sobre el uso del proceso sin servidor para flujos de trabajo, consulte Ejecución del trabajo de Azure Databricks con proceso sin servidor para flujos de trabajo.
Para obtener información sobre precios, consulte Precios de Databricks.
Requisitos
- Su área de trabajo debe estar en una región admitida. Consultar Regiones de Azure Databricks.
- Su área de trabajo debe estar habilitada para Unity Catalog.
- El área de trabajo debe estar habilitada para la versión preliminar pública.
Uso del proceso sin servidor para cuadernos
Si el área de trabajo está habilitada para el proceso interactivo sin servidor, todos los usuarios del área de trabajo tienen acceso al proceso sin servidor para cuadernos. No se requieren permisos adicionales.
Para conectarse al proceso sin servidor, haga clic en el menú desplegable Conectar del cuaderno y seleccione Sin servidor. En el caso de los cuadernos nuevos, el proceso adjunto pasa automáticamente al modo sin servidor cuando se ejecuta el código si no se ha seleccionado ningún otro recurso.
Visualización de información de consulta
El proceso sin servidor para cuadernos y flujos de trabajo usa información de consulta para evaluar el rendimiento de la ejecución de Spark. Después de ejecutar una celda en un cuaderno, puede ver las conclusiones relacionadas con las consultas SQL y Python haciendo clic en el vínculo Ver rendimiento.
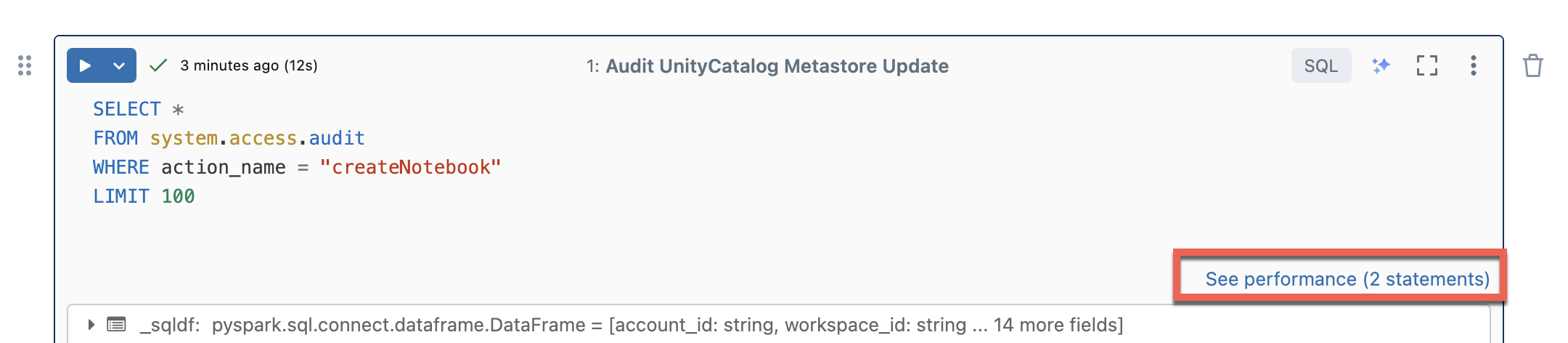
Puede hacer clic en cualquiera de las instrucciones de Spark para ver las métricas de consulta. Desde allí puede hacer clic en Ver perfil de consulta para ver una visualización de la ejecución de la consulta. Para más información sobre los perfiles de consulta, consulte Perfil de consulta.
Historial de consulta
Todas las consultas que se ejecutan en el proceso sin servidor también se registrarán en la página del historial de consultas del área de trabajo. Para obtener información sobre el historial de consultas, consulte Historial de consultas.
Limitaciones de información de consultas
- El perfil de consulta solo está disponible una vez finalizada la ejecución de la consulta.
- Las métricas se actualizan en directo aunque el perfil de consulta no se muestra durante la ejecución.
- Solo se cubren los siguientes estados de consulta: EN EJECUCIÓN, CANCELADA, FALLIDA, FINALIZADA.
- No se pueden cancelar las consultas en ejecución desde la página del historial de consultas. Se pueden cancelar en cuadernos o trabajos.
- Las métricas detalladas no están disponibles.
- La descarga del perfil de consulta no está disponible.
- El acceso a la interfaz de usuario de Spark no está disponible.
- El texto de la instrucción solo contiene la última línea que se ejecutó. Sin embargo, puede haber varias líneas anteriores a esta línea que se ejecutaron como parte de la misma instrucción.
Limitaciones
Para ver una lista de limitaciones, consulte Limitaciones de los procesos sin servidor.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de