Captura y visualización del linaje de datos mediante Unity Catalog
Puede usar el catálogo de Unity para capturar el linaje de datos en tiempo de ejecución entre las consultas que se ejecutan en Azure Databricks. El linaje es compatible con todos los idiomas y se captura hasta el nivel de columna. Los datos del linaje incluyen cuadernos, flujos de trabajo y paneles relacionados con la consulta. El linaje se puede visualizar en el Explorador de catálogos casi en tiempo real y recuperarse con la API REST de Databricks.
Nota:
También puede ver y consultar datos de linaje mediante las tablas del sistema de linaje (versión preliminar pública). Para obtener más información, consulte Referencian de tablas del sistema de linaje.
El linaje se agrega en todas las áreas de trabajo asociadas a un metastore del catálogo de Unity. Esto significa que el linaje capturado en un área de trabajo es visible en cualquier otra área de trabajo que comparta ese metastore. Los usuarios deben tener los permisos correctos para ver los datos del linaje. Los datos del linaje se conservan durante 1 año.
En este artículo se describe cómo visualizar el linaje mediante el Catalog Explorer y la API de REST. Para obtener información sobre el seguimiento del linaje de un modelo de Machine Learning, vea Seguimiento del linaje de datos de un modelo en Unity Catalog.
Requisitos
Los siguientes son necesarios para capturar el linaje de datos mediante el catálogo de Unity:
El área de trabajo debe estar habilitada para Unity Catalog.
Las tablas deben registrarse en un metastore de catálogo de Unity.
Las consultas deben usar el elemento DataFrame de Spark (por ejemplo, las funciones de Spark SQL que devuelven una trama de datos) o las interfaces SQL de Databricks. Para obtener ejemplos de consultas de SQL y PySpark de Databricks, consulte la sección Ejemplos.
Para ver el linaje de una tabla o vista, los usuarios deben tener al menos el privilegio
BROWSEen el catálogo primario de la tabla o vista.Para ver la información de linaje de cuadernos, flujos de trabajo o paneles, los usuarios deben tener permisos en estos objetos según lo definido por la configuración de control de acceso en el área de trabajo. Consulte Permisos de linaje.
Para ver el linaje de una canalización habilitada para el catálogo de Unity, debe tener los permisos
CAN_VIEWen la canalización.Es posible que tenga que actualizar las reglas de firewall de salida para permitir la conectividad con el punto de conexión del centro de eventos en el plano de control de Azure Databricks. Normalmente, esto se aplica si el área de trabajo de Azure Databricks se implementa en su propia red virtual (también conocida como inyección de red virtual). Para obtener el punto de conexión del centro de eventos para la región del área de trabajo, consulte Metastore, artefacto de Blob Storage, almacenamiento de tablas del sistema, registro de Blob Storage y direcciones IP del punto de conexión del centro de eventos. Para obtener información acerca de cómo configurar rutas definidas por el usuario (UDR) para Azure Databricks, consulte Configuración de rutas definida por el usuario para Azure Databricks.
Limitaciones
El streaming entre tablas Delta solo se admite en Databricks Runtime 11.3 LTS o superior.
Dado que el linaje se calcula en una ventana gradual de 1 año, no se muestra el linaje recopilado hace más de 1 año. Por ejemplo, si un trabajo o consulta lee datos de la tabla A y escribe en la tabla B, el vínculo entre la dichas tablas se muestra solo durante 1 año.
Puede filtrar los datos de linaje por período de tiempo. Cuando se selecciona "Todo el linaje", se muestran los datos de linaje recopilados a partir de junio de 2023.
Los flujos de trabajo que usan la solicitud
runs submitde API de trabajos no están disponibles al acceder al linaje. El linaje de nivel de tabla y columna se sigue capturando al usar la solicitudruns submit, pero el vínculo de la ejecución no se captura.El catálogo de Unity captura el linaje en el nivel de columna todo lo posible. Pero hay algunos casos en los que no se puede capturar el linaje de nivel de columna.
El linaje de columnas solo se admite cuando se hace referencia tanto al origen como al destino por el nombre de la tabla (ejemplo:
select * from <catalog>.<schema>.<table>). El linaje de columnas no se puede capturar si el origen o el destino se abordan mediante la ruta de acceso (ejemplo:select * from delta."s3://<bucket>/<path>").Si se cambia el nombre de una tabla, su linaje no se captura.
Si usa puntos de comprobación del conjunto de datos de Spark SQL, el linaje no se captura. Consulte pyspark.sql.DataFrame.checkpoint en la documentación de Apache Spark.
Unity Catalog captura el linaje de las canalizaciones de Delta Live Tables en la mayoría de los casos. Sin embargo, en algunos casos, no se puede garantizar la cobertura de linaje completa, como cuando las canalizaciones usan la API APPLY CHANGES o las tablasTEMPORALES.
Ejemplos
Nota:
En los ejemplos siguientes se usa el nombre de catálogo
lineage_datay el nombre de esquemalineagedemo. Para usar un catálogo y un esquema diferentes, cambie los nombres que se hayan usado en los ejemplos.Para completar este ejemplo, debe tener los privilegios
CREATEyUSE SCHEMAen un esquema. Un administrador de metastore, el propietario del catálogo o el del esquema puede concederle todos estos privilegios. Por ejemplo, para conceder permiso a todos los usuarios del grupo "data_engineers" para crear tablas en el esquemalineagedemodel catálogolineage_data, un usuario con uno de los permisos o roles anteriores puede ejecutar las siguientes consultas:CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
Captura y exploración del linaje
Para capturar los datos del linaje, siga estos pasos:
Vaya a la página de aterrizaje de Azure Databricks, haga clic en
 Nuevo en la barra lateral y seleccione Cuaderno en el menú.
Nuevo en la barra lateral y seleccione Cuaderno en el menú.Escriba un nombre para el cuaderno y seleccione SQL en Idioma predeterminado.
En Clúster, seleccione un clúster con acceso al catálogo de Unity.
Haga clic en Crear.
En la primera celda del cuaderno, escriba las siguientes consultas:
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menuPara ejecutar las consultas, haga clic en la celda y presione mayús+entrar o haga clic en
 y seleccione Ejecutar celda.
y seleccione Ejecutar celda.
Para usar el Explorador de catálogos para ver el linaje que han generado las consultas, siga estos pasos:
En el cuadro Buscar de la barra superior del área de trabajo de Azure Databricks, escriba
lineage_data.lineagedemo.dinnery haga clic en Search lineage_data.lineagedemo.dinner in Databricks (Buscar lineage_data.lineagedemo.dinner en Databricks).En Tablas, haga clic en la tabla
dinner.Seleccione la pestaña Linaje. Verá el panel de linaje y muestra las tablas relacionadas (en este ejemplo se trata de la tabla
menu).Para ver un gráfico interactivo del linaje de datos, haga clic en Ver gráfico de linaje. De forma predeterminada, se muestra un nivel en el gráfico. Puede hacer clic en el
 de un nodo para mostrar más conexiones si están disponibles.
de un nodo para mostrar más conexiones si están disponibles.Haga clic en una flecha que conecte los nodos en el gráfico de linaje para abrir el panel Conexión de linaje. En el panel Conexión de linaje se muestran detalles sobre la conexión, incluidas las tablas de origen y destino, los cuadernos y los flujos de trabajo.
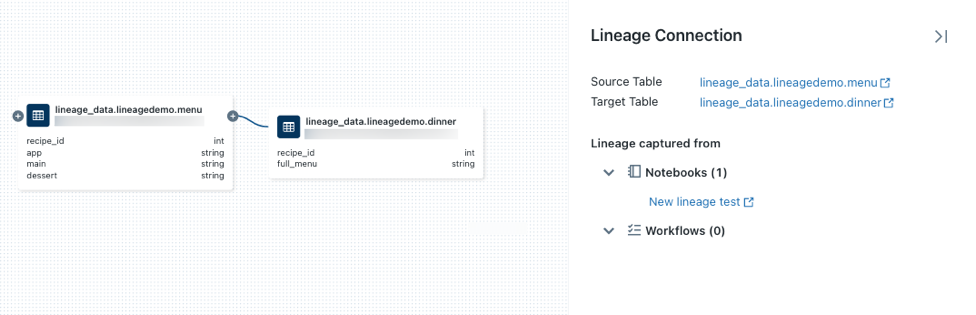
Para mostrar el cuaderno asociado a la tabla
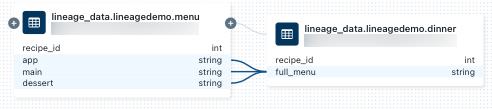
dinner, selecciónelo en el panel Conexión de linaje o cierre el gráfico de linaje y haga clic en Cuadernos. Para abrir el cuaderno en una nueva pestaña, haga clic en el nombre del cuaderno.Para ver el linaje de nivel de columna, haga clic en una columna del gráfico para mostrar vínculos a columnas relacionadas. Por ejemplo, al hacer clic en la columna "full_menu" se muestran las columnas ascendentes de las que se deriva la columna:
Para demostrar la creación y visualización del linaje con un lenguaje diferente, por ejemplo, Python, siga estos pasos:
Abra el cuaderno que creó anteriormente, cree una nueva celda y escriba el siguiente código de Python:
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")Ejecute la celda haciendo clic en ella y presionando mayús+entrar o haciendo clic en
y seleccionando Ejecutar celda.En el cuadro Buscar de la barra superior del área de trabajo de Azure Databricks, escriba
lineage_data.lineagedemo.pricey haga clic en Search lineage_data.lineagedemo.dinner in Databricks (Buscar lineage_data.lineagedemo.price en Databricks).En Tablas, haga clic en la tabla
price.Seleccione la pestaña Linaje y haga clic en Ver gráfico de linaje. Haga clic en los iconos
para explorar el linaje de datos que han generado las consultas SQL y Python.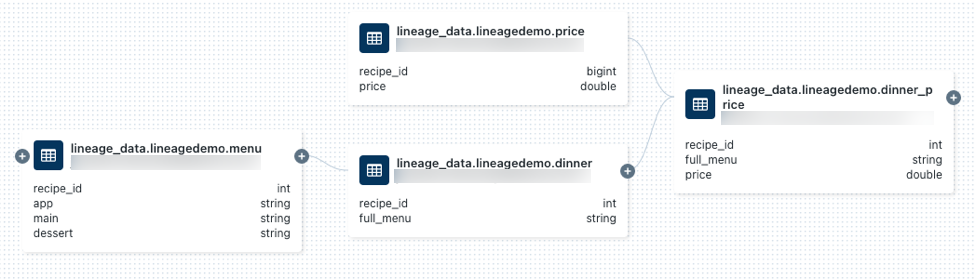
Haga clic en una flecha que conecte los nodos en el gráfico de linaje para abrir el panel Conexión de linaje. En el panel Conexión de linaje se muestran detalles sobre la conexión, incluidas las tablas de origen y destino, los cuadernos y los flujos de trabajo.
Captura y visualización del linaje del flujo de trabajo
El linaje también se captura para cualquier flujo de trabajo que lea o escriba en el catálogo de Unity. Para demostrar cómo ver el linaje de un flujo de trabajo de Azure Databricks, siga estos pasos:
Haga clic en
Nuevo en la barra lateral y seleccione Cuaderno en el menú.Escriba un nombre para el cuaderno y seleccione SQL en Idioma predeterminado.
Haga clic en Crear.
En la primera celda del cuaderno, escriba la siguiente consulta:
SELECT * FROM lineage_data.lineagedemo.menuHaga clic en Programar en la barra superior. En el cuadro de diálogo programación, seleccione Manual, seleccione un clúster con acceso al catálogo de Unity y haga clic en Crear.
Haga clic en Ejecutar ahora.
En el cuadro Buscar de la barra superior del área de trabajo de Azure Databricks, escriba
lineage_data.lineagedemo.menuy haga clic en Search lineage_data.lineagedemo.dinner in Databricks (Buscar lineage_data.lineagedemo.menu en Databricks).En Tables View all tables (Tablas Ver todas las tablas), haga clic en la tabla
menu.Seleccione la pestaña Linaje, haga clic en Flujos de trabajo y seleccione la pestaña Bajada. El nombre del trabajo aparece en Nombre del trabajo como consumidor de la tabla
menu.
Captura y visualización del linaje de panel
Para saber cómo ver el linaje de un panel de SQL, siga estos pasos:
- Vaya a la página de aterrizaje de Azure Databricks y abra el Explorador de catálogos; para ello, haga clic en Catálogo en la barra lateral.
- Haga clic en el nombre del catálogo, seleccione linajedemo y haga clic en la tabla
menu. También puede usar el cuadro de texto Buscar tablas en la barra superior para buscar la tablamenu. - Haga clic en Acciones > Crear un panel rápido.
- Seleccione las columnas que quiera agregar al panel y haga clic en Crear.
- En el cuadro Buscar de la barra superior del área de trabajo de Azure Databricks, escriba
lineage_data.lineagedemo.menuy haga clic en Search lineage_data.lineagedemo.dinner in Databricks (Buscar lineage_data.lineagedemo.menu en Databricks). - En Tables View all tables (Tablas Ver todas las tablas), haga clic en la tabla
menu. - Seleccione la pestaña Linaje y haga clic en Paneles. El nombre del panel aparece en la opción Nombre del panel como consumidor de la tabla de menús.
Permisos de linaje
Los gráficos de linaje comparten el mismo modelo de permisos que el catálogo de Unity. Si un usuario no tiene privilegios BROWSE o SELECT en una tabla, no podrá explorar el linaje. Además, los usuarios solo pueden ver cuadernos, flujos de trabajo y paneles que tengan permiso para ver. Por ejemplo, si ejecuta los siguientes comandos para un usuario que no es administrador userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Cuando userA vea el gráfico de linaje de la tabla lineage_data.lineagedemo.menu, verá la tabla menu. No podrán ver información sobre las tablas asociadas, como la tablalineage_data.lineagedemo.dinner descendente. La tabla dinner se muestra como un nodo masked en la presentación de userA, y userA no puede expandir el gráfico para mostrar las tablas de bajada de las tablas a las que no puede acceder.
Si ejecuta el siguiente comando para conceder el permiso BROWSE a un usuario que no sea administrador userB:
GRANT BROWSE on lineage_data to `userA@company.com`;
userB ahora puede ver el gráfico de linaje de cualquier tabla del esquema lineage_data.
Para obtener más información sobre cómo administrar el acceso a objetos protegibles en Unity Catalog, consulte Administración de privilegios en Unity Catalog. Para obtener más información sobre cómo administrar el acceso a objetos del área de trabajo, como cuadernos, flujos de trabajo y paneles, vea Listas de control de acceso.
Eliminación de datos de linaje
Advertencia
Las instrucciones siguientes indican cómo eliminar todos los objetos almacenados en el catálogo de Unity. Use estas instrucciones solo si es necesario. Por ejemplo, para satisfacer los requisitos de cumplimiento.
Para eliminar los datos de linaje, debe eliminar el metastore que administra los objetos del catálogo de Unity. Para más información sobre cómo eliminar el metastore, consulte Eliminación de un metastore. Los datos se eliminarán en un plazo de 90 días.
API de linaje de los datos
La API de linaje de datos permite recuperar el linaje de tablas y columnas.
Importante
Para acceder a las API REST de Databricks, es preciso autenticarse.
Recuperación del linaje de tablas
En este ejemplo se recuperan los datos de linaje de la tabla dinner.
Solicitar
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
Reemplace <workspace-instance>.
En este ejemplo, se usa un archivo .netrc.
Response
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
Recuperación del linaje de tablas
En este ejemplo se recuperan los datos de columna de la tabla dinner.
Solicitar
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
Reemplace <workspace-instance>.
En este ejemplo, se usa un archivo .netrc.
Response
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de