Trabajo con archivos en Azure Databricks
Azure Databricks proporciona varias utilidades y API para interactuar con archivos en las siguientes ubicaciones:
- Volúmenes de Unity Catalog
- Archivos del área de trabajo
- Almacenamiento de objetos en la nube
- Montajes de DBFS y raíz de DBFS
- Almacenamiento efímero conectado al nodo del controlador del clúster
En este artículo se proporcionan ejemplos para interactuar con archivos en estas ubicaciones para las siguientes herramientas:
- Apache Spark
- Spark SQL y Databricks SQL
- Utilidades del sistema de archivos Databricks (
dbutils.fso%fs) - CLI de Databricks
- API REST de Databricks
- Comandos de shell de Bash (
%sh) - Instalaciones en la biblioteca con ámbito de cuaderno mediante
%pip - Pandas
- Utilidades de procesamiento y administración de archivos de Python de OSS
Importante
Las operaciones de archivo que requieren acceso FUSE a los datos no pueden acceder directamente al almacenamiento de objetos en la nube mediante URI. Databricks recomienda usar volúmenes de Unity Catalog para configurar el acceso a estas ubicaciones para FUSE.
Scala no admite FUSE para volúmenes de Unity Catalog o archivos de área de trabajo en el proceso configurado con el modo de acceso de usuario único o clústeres sin Unity Catalog. Scala admite FUSE para volúmenes de Unity Catalog y archivos de área de trabajo en el proceso configurado con Unity Catalog y el modo de acceso compartido.
¿Es necesario proporcionar un esquema de URI para acceder a los datos?
Las rutas de acceso a datos de Azure Databricks siguen uno de los siguientes estándares:
Las rutas de acceso de estilo URI incluyen un esquema URI. En el caso de las soluciones de acceso a datos nativos de Databricks, los esquemas de URI son opcionales para la mayoría de los casos de uso. Al acceder directamente a los datos en el almacenamiento de objetos en la nube, debe proporcionar el esquema de URI correcto para el tipo de almacenamiento.
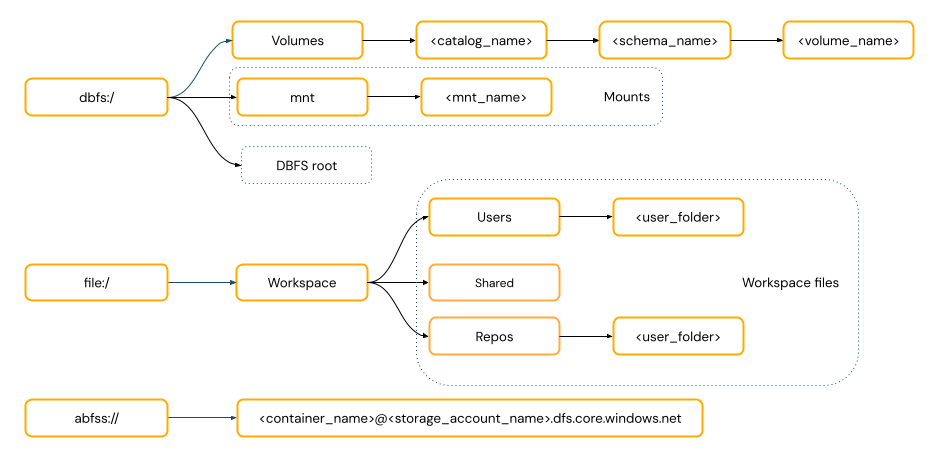
Las rutas de estilo POSIX proporcionan acceso a datos relativos a la raíz del controlador (
/). Las rutas de estilo POSIX nunca requieren un esquema. Puede usar volúmenes de Unity Catalog o montajes DBFS para proporcionar acceso de estilo POSIX a los datos en el almacenamiento de objetos en la nube. Muchos marcos de ML y otros módulos de Python de OSS requieren FUSE y solo pueden usar rutas de estilo POSIX.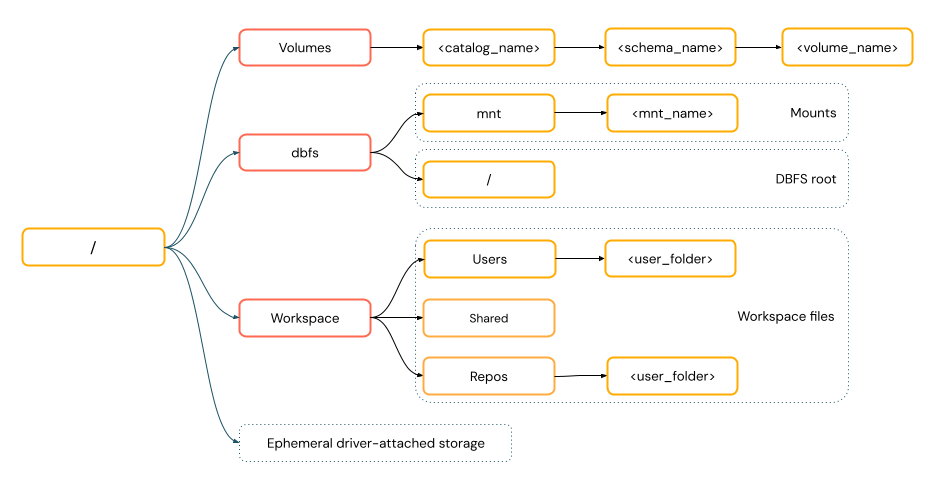
Trabajo con archivos en volúmenes de Unity Catalog
Databricks recomienda utilizar volúmenes de Unity Catalog para configurar el acceso a archivos de datos no tabulares en el almacenamiento de objetos en la nube. Consulte Crear y trabajar con volúmenes.
| Herramienta | Ejemplo |
|---|---|
| Spark de Apache | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL y Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`; LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Utilidades del sistema de archivos de Databricks | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/") %fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| CLI de Databricks | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| API REST de Databricks | POST https://<databricks-instance>/api/2.1/jobs/create {"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Comandos de shell de Bash | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| Instalaciones de biblioteca | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandas | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| OSS Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
Nota:
El esquema dbfs:/ es necesario cuando se trabaja con la CLI de Databricks.
Limitaciones de volúmenes
Los volúmenes tienen las siguientes limitaciones:
No se admiten escrituras de anexión directa o no secuenciales (aleatorias), como escribir archivos Zip y Excel. En el caso de las cargas de trabajo de anexión directa o escritura aleatoria, realice primero las operaciones en un disco local y luego copie los resultados en volúmenes de Catálogo de Unity. Por ejemplo:
# python import xlsxwriter from shutil import copyfile workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx') worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") workbook.close() copyfile('/local_disk0/tmp/excel.xlsx', '/Volumes/my_catalog/my_schema/my_volume/excel.xlsx')No se admiten archivos dispersos. Para copiar archivos dispersos, use
cp --sparse=never:$ cp sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file error writing '/dbfs/sparse.file': Operation not supported $ cp --sparse=never sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file
Trabajo con archivos del área de trabajo
Los archivos del área de trabajo de Databricks son el conjunto de archivos de un área de trabajo que no son cuadernos. Puede usar archivos de área de trabajo para almacenar datos y otros archivos guardados junto con cuadernos y otros recursos del área de trabajo y acceder a ellos. Dado que los archivos de área de trabajo tienen restricciones de tamaño, Databricks solo recomienda almacenar archivos de datos pequeños aquí principalmente para desarrollo y pruebas.
| Herramienta | Ejemplo |
|---|---|
| Spark de Apache | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL y Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Utilidades del sistema de archivos de Databricks | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/") %fs ls file:/Workspace/Users/<user-folder>/ |
| CLI de Databricks | databricks workspace list |
| API REST de Databricks | POST https://<databricks-instance>/api/2.0/workspace/delete {"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Comandos de shell de Bash | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| Instalaciones de biblioteca | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandas | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| OSS Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
Nota:
El esquema file:/ es necesario cuando se trabaja con utilidades de Databricks, Apache Spark o SQL.
Limitaciones de los archivos del área de trabajo
Los archivos del área de trabajo tienen las siguientes limitaciones:
El tamaño del archivo del área de trabajo está limitado a 500 MB desde la interfaz de usuario. El tamaño máximo de archivo permitido al escribir desde un clúster es de 256 MB.
Si su flujo de trabajo utiliza código fuente ubicado en un repositorio Git remoto, no puede escribir en el directorio actual o escribir utilizando una ruta relativa. Escribir datos en otras opciones de ubicación.
No se pueden usar comandos
gital guardar en archivos en el área de trabajo. No se permite la creación de directorios.giten archivos del área de trabajo.Hay compatibilidad limitada con las operaciones de archivos del área de trabajo desde el proceso sin servidor.
Los ejecutores no pueden escribir en archivos del área de trabajo.
no se admiten vínculos simbólicos.
No se puede acceder a los archivos del área de trabajo desde funciones definidas por el usuario (UDF) en clústeres con modo de acceso compartido.
¿Dónde van los archivos del área de trabajo eliminados?
Al borrar un archivo de área de trabajo, se envía a la papelera. Puede recuperar o eliminar permanentemente archivos de la papelera mediante la interfaz de usuario.
Trabajo con archivos en el almacenamiento de objetos en la nube
Databricks recomienda usar volúmenes de Unity Catalog para configurar el acceso seguro a los archivos en el almacenamiento de objetos en la nube. Si decide acceder directamente a los datos en el almacenamiento de objetos en la nube mediante URI, debe configurar los permisos. Consulte Administración de ubicaciones externas, tablas externas y volúmenes externos.
En los ejemplos siguientes se usan URI para acceder a los datos en el almacenamiento de objetos en la nube:
| Herramienta | Ejemplo |
|---|---|
| Spark de Apache | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL y Databricks SQL | SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`; LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path'; |
| Utilidades del sistema de archivos de Databricks | dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/") %fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/ |
| CLI de Databricks | No compatible |
| API REST de Databricks | No compatible |
| Comandos de shell de Bash | No compatible |
| Instalaciones de biblioteca | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Pandas | No compatible |
| OSS Python | No compatible |
Nota:
El almacenamiento de objetos en la nube no admite el paso directo de credenciales.
Trabajo con archivos en montajes de DBFS y raíz de DBFS
Los montajes DBFS no se pueden proteger mediante Unity Catalog y Databricks ya no los recomienda. Todos los usuarios del área de trabajo pueden acceder a los datos almacenados en la raíz de DBFS. Databricks recomienda que no se almacenen datos de producción o información confidencial en la raíz de DBFS. Consulte ¿Qué es el sistema de archivos de Databricks (DBFS)?.
| Herramienta | Ejemplo |
|---|---|
| Spark de Apache | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL y Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Utilidades del sistema de archivos de Databricks | dbutils.fs.ls("/mnt/path") %fs ls /mnt/path |
| CLI de Databricks | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| API REST de Databricks | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Comandos de shell de Bash | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| Instalaciones de biblioteca | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandas | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| OSS Python | os.listdir('/dbfs/mnt/path/to/directory') |
Nota:
El esquema dbfs:/ es necesario cuando se trabaja con la CLI de Databricks.
Trabajo con archivos en almacenamiento efímero conectado al nodo del controlador
El almacenamiento efímero conectado al nodo del controlador es un almacenamiento de bloques con acceso nativo a rutas basadas en POSIX. Los datos almacenados en esta ubicación desaparecen cuando un clúster finaliza o se reinicia.
| Herramienta | Ejemplo |
|---|---|
| Spark de Apache | No compatible |
| Spark SQL y Databricks SQL | No compatible |
| Utilidades del sistema de archivos de Databricks | dbutils.fs.ls("file:/path") %fs ls file:/path |
| CLI de Databricks | No compatible |
| API REST de Databricks | No compatible |
| Comandos de shell de Bash | %sh curl http://<address>/text.zip > /tmp/text.zip |
| Instalaciones de biblioteca | No compatible |
| Pandas | df = pd.read_csv('/path/to/data.csv') |
| OSS Python | os.listdir('/path/to/directory') |
Nota:
El esquema file:/ es necesario cuando se trabaja con las utilidades de Databricks.
Traslado de datos del almacenamiento efímero a volúmenes
Es posible que quiera acceder a los datos descargados o guardados en el almacenamiento efímero mediante Apache Spark. Debido a que el almacenamiento efímero está conectado con el controlador y Spark es un motor de procesamiento distribuido, no todas las operaciones pueden acceder directamente a los datos aquí. Si necesita mover datos del sistema de archivos del controlador a volúmenes de Unity Catalog, puede copiar archivos utilizando comandos mágicos o las utilidades Databricks, como en los siguientes ejemplos:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>