Introducción: Consulta y visualización de datos desde un cuaderno
Este artículo de introducción le guía por el uso de un cuaderno de Azure Databricks para consultar datos de ejemplo almacenados en Unity Catalog mediante SQL, Python, Scala y R y, a continuación, visualizar los resultados de la consulta en el cuaderno.
Requisitos
Para completar las tareas de este artículo, debe cumplir los siguientes requisitos:
- El área de trabajo debe tener habilitado para Unity Catalog. Para obtener información sobre cómo empezar a trabajar con Unity Catalog, vea Configuración y administración del Unity Catalog.
- Debe tener permiso para usar un recurso de proceso existente o crear un nuevo recurso de proceso. Vea Introducción: Configuración de cuenta y área de trabajo o vea el administrador de Databricks.
Paso 1: Crear un nuevo cuaderno
Para crear un cuaderno en el área de trabajo:
- Haga clic en
 Nuevo en la barra lateral y, luego, en Cuaderno.
Nuevo en la barra lateral y, luego, en Cuaderno. - En la página Crear cuaderno:
- Especifique un nombre único para el cuaderno.
- Establezca el idioma predeterminado del cuaderno y haga clic en Confirmar si se le solicita.
- Use el menú desplegable Conectar para seleccionar un recurso de proceso. Para crear un nuevo recurso de proceso, vea Use compute.
Para obtener más información sobre cómo crear y administrar cuadernos, consulte Administración de cuadernos.
Paso 2: Consultar una tabla
Consulte la tabla samples.nyctaxi.trips en Unity Catalog con el idioma que prefiera.
SQL
- Copie y pegue el código siguiente en la nueva celda del cuaderno vacío. Este código muestra los resultados de consultar la tabla
samples.nyctaxi.tripsen Unity Catalog.
SELECT * FROM samples.nyctaxi.trips
Python
- Copie y pegue el código siguiente en la nueva celda del cuaderno vacío. Este código muestra los resultados de consultar la tabla
samples.nyctaxi.tripsen Unity Catalog.
display(spark.read.table("samples.nyctaxi.trips"))
Scala
- Copie y pegue el código siguiente en la nueva celda del cuaderno vacío. Este código muestra los resultados de consultar la tabla
samples.nyctaxi.tripsen Unity Catalog.
display(spark.read.table("samples.nyctaxi.trips"))
R
- Copie y pegue el código siguiente en la nueva celda del cuaderno vacío. Este código muestra los resultados de consultar la tabla
samples.nyctaxi.tripsen Unity Catalog.
library(SparkR)
display(sql("SELECT * FROM samples.nyctaxi.trips"))
Presione
Shift+Enterpara ejecutar la celda y, a continuación, vaya a la celda siguiente.Los resultados de la consulta aparecen en el cuaderno.
Paso 3: Mostrar los datos
Muestra la cantidad promedio de tarifas por distancia de viaje, agrupada por el código postal de recogida.
Junto a la pestaña Tabla, haga clic + y, a continuación, haga clic en Visualización.
Se muestra el editor de visualización.
En la lista desplegable Tipo de visualización, compruebe que la Barra está seleccionada.
Seleccione
fare_amountpara la columna X.Seleccione
trip_distancepara la columna Y.Seleccione
Averagecomo tipo de agregación.Seleccione
pickup_zipcomo columna Agrupar por.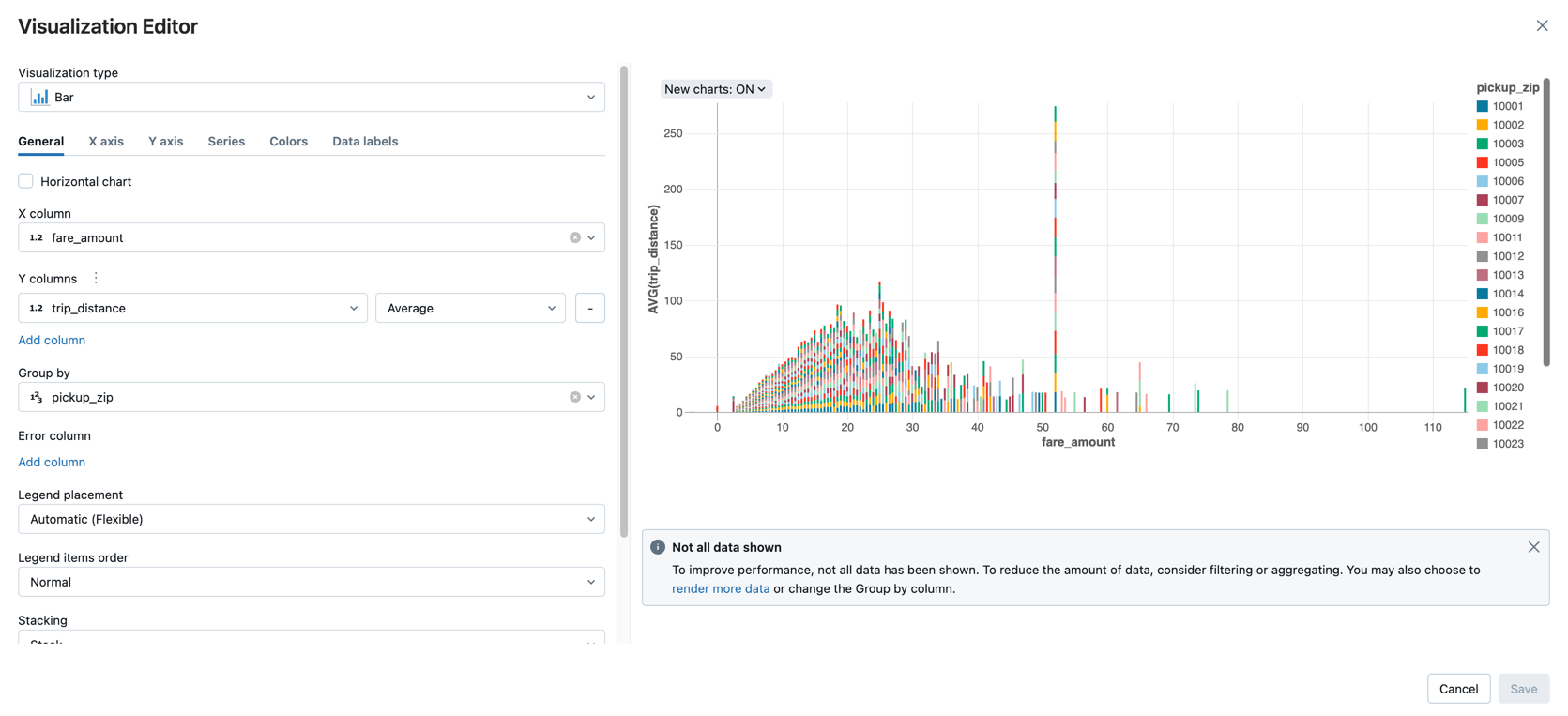
Haga clic en Save(Guardar).
Pasos siguientes
- Para obtener información sobre cómo cargar datos en Databricks mediante Apache Spark, vea Tutorial: Carga y transformación de datos mediante DataFrames de Apache Spark.
- Para más información sobre la ingesta de datos en Databricks, vea Ingesta de datos en una instancia de Databricks lakehouse.
- Para más información sobre cómo consultar datos con Databricks, vea Consulta de datos.
- Para más información sobre las visualizaciones, vea Visualizaciones en cuadernos de Databricks.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de