¿Qué es una instancia de Data LakeHouse?
Data Lakehouse es un sistema de administración de datos que combina las ventajas de los lagos de datos y los almacenes de datos. En este artículo se describe el patrón arquitectónico del almacén de lago y lo que puede hacer con él en Azure Databricks.
¿Para qué se usa un almacén de lago de datos?
Un almacén de lago de datos proporciona funcionalidades de almacenamiento y procesamiento escalables para las organizaciones modernas que quieren evitar un sistema aislado para procesar diferentes cargas de trabajo, como el aprendizaje automático (ML) y la inteligencia empresarial (BI). Un almacén de lago de datos puede ayudar a establecer una única fuente de verdad, eliminar los costes redundantes y garantizar la actualización de los datos.
Los almacenes de lago de datos suelen usar un patrón de diseño de datos que mejora, enriquece y refina los datos de forma incremental a medida que se mueve a través de capas de almacenamiento provisional y transformación. Cada capa del almacén de lago puede incluir una o varias capas. Este patrón se conoce con frecuencia como arquitectura de Medallion. Para obtener más información, consulte ¿Qué es la arquitectura de Medallion de almacén de lago?
¿Cómo funciona el almacén de lago de datos de Databricks?
Databricks se basa en Apache Spark. Apache Spark habilita un motor escalable de forma masiva que se ejecuta en recursos de proceso desacoplados del almacenamiento. Para más información, consulte Apache Spark en Azure Databricks
Databricks Lakehouse usa dos tecnologías clave adicionales:
- Delta Lake: una capa de almacenamiento optimizada que admite transacciones ACID y aplicación de esquemas.
- Catálogo de Unity: una solución de gobernanza unificada y específica para los datos y la inteligencia artificial.
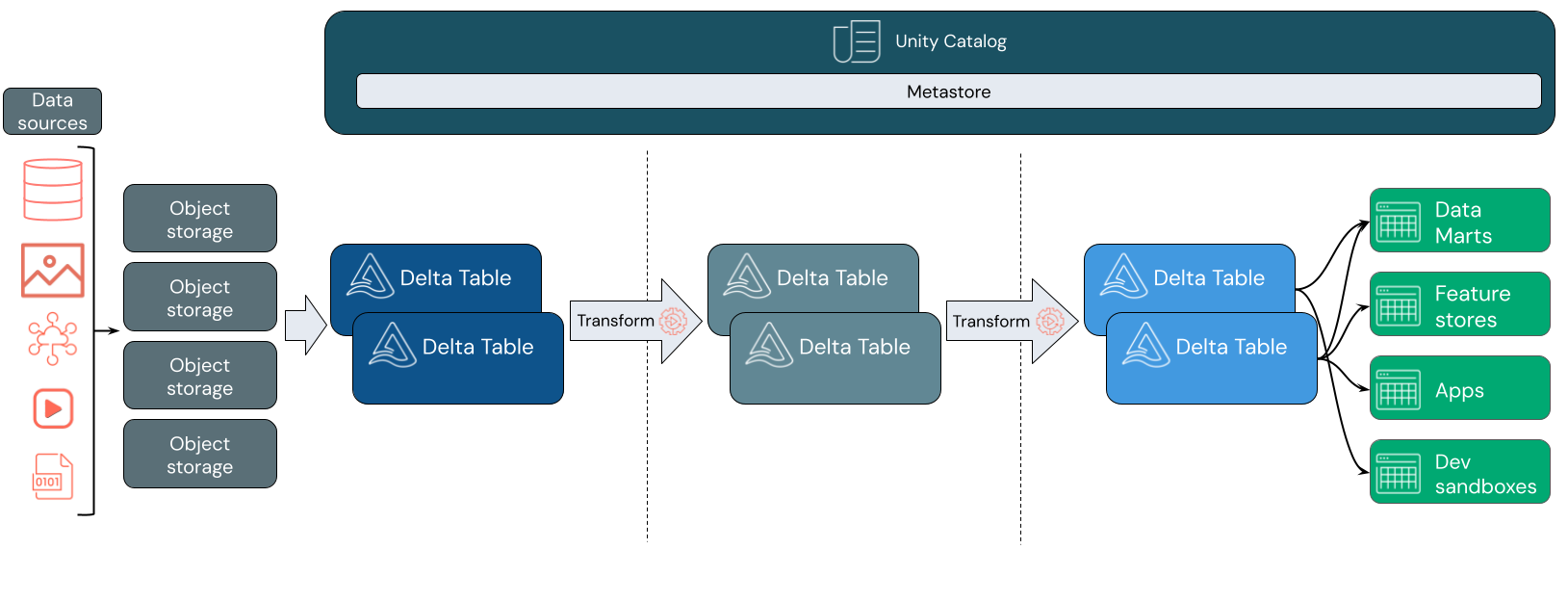
Ingesta de datos
En la capa de ingesta, los datos por lotes o de streaming llegan desde una variedad de orígenes y en una variedad de formatos. Esta primera capa lógica proporciona un lugar para que los datos se coloquen en su formato sin procesar. A medida que convierte esos archivos en tablas Delta, puede usar las funcionalidades de cumplimiento de esquemas de Delta Lake para comprobar si faltan datos o hay datos inesperados. Puede usar el catálogo de Unity para registrar tablas según el modelo de gobernanza de datos y los límites de aislamiento de datos necesarios. Unity Catalog permite realizar un seguimiento del linaje de los datos a medida que se transforman y refinan, así como aplicar un modelo de gobernanza unificado para mantener los datos confidenciales privados y seguros.
Procesamiento, curación e integración de datos
Una vez comprobado, puede empezar a seleccionar y refinar los datos. Los científicos de datos y los profesionales del aprendizaje automático suelen trabajar con datos en esta fase para empezar a combinar o crear nuevas características y completar la limpieza de datos. Una vez que los datos se han limpiado exhaustivamente, se pueden integrar y reorganizar en tablas diseñadas para satisfacer sus necesidades empresariales concretas.
Un enfoque de esquema en escritura, combinado con las funcionalidades de evolución del esquema Delta, significa que puede realizar cambios en esta capa sin tener que reescribir necesariamente la lógica de bajada que sirve datos a sus usuarios finales.
Servicio de datos
La capa final sirve datos limpios y enriquecidos a los usuarios finales. Las tablas finales deben diseñarse para proporcionar datos para todos los casos de uso. Un modelo de gobernanza unificado significa que puede realizar un seguimiento del linaje de datos de nuevo a su único origen de verdad. Los diseños de datos, optimizados para diferentes tareas, permiten a los usuarios finales acceder a datos para aplicaciones de aprendizaje automático, ingeniería de datos e inteligencia empresarial e informes.
Para más información sobre Delta Lake, consulte ¿Qué es Delta Lake? Para obtener más información sobre el catálogo de Unity, consulte ¿Qué es el catálogo de Unity?
Funcionalidades de un almacén de lago de datos de Databricks
Una lago de datos basado en Databricks reemplaza la dependencia actual de los lagos de datos y los almacenes de datos para las empresas de datos modernas. Algunas tareas clave que puede realizar incluyen:
- Procesamiento de datos en tiempo real: procesar datos de streaming en tiempo real para realizar análisis y acciones inmediatos.
- Integración de datos: unificar todos sus datos en un único sistema para permitir la colaboración y establecer una única fuente de verdad para su organización.
- Evolución del esquema: modificar esquema de datos a lo largo del tiempo para adaptarse a las necesidades empresariales cambiantes sin interrumpir las canalizaciones de datos existentes.
- Transformaciones de datos: uso de Apache Spark y Delta Lake aporta velocidad, escalabilidad y confiabilidad a los datos.
- Análisis e informes de datos: ejecutar consultas analíticas complejas con un motor optimizado para cargas de trabajo de almacenamiento de datos.
- Aprendizaje automático e inteligencia artificial: aplicar técnicas de análisis avanzadas a todos los datos. Use ML para enriquecer los datos y admitir otras cargas de trabajo.
- Control de versiones y linaje de datos: mantener el historial de versiones de los conjuntos de datos y realizar un seguimiento del linaje para garantizar la procedencia y el seguimiento de los datos.
- Gobernanza de datos: use un único sistema unificado para controlar el acceso a los datos y realizar auditorías.
- Uso compartido de datos: facilitar la colaboración al permitir el uso compartido de conjuntos de datos, informes e información mantenidos en todos los equipos.
- Análisis operativo: supervisar métricas de calidad de datos, métricas de calidad del modelo y desfase aplicando el aprendizaje automático a los datos de supervisión del almacén de lago.
Lakehouse frente a Data Lake frente a Data Warehouse
Los almacenes de datos han impulsado las decisiones de inteligencia empresarial (BI) durante unos 30 años, habiendo evolucionado como un conjunto de directrices de diseño para sistemas que controlan el flujo de datos. Los almacenamientos de datos de empresa optimizan las consultas de informes de BI, pero pueden tardar minutos o incluso horas en generar resultados. Los almacenamientos de datos, diseñados para los datos que no es probable que cambien con gran frecuencia, buscan evitar conflictos entre consultas que se ejecutan simultáneamente. Muchos almacenes de datos se basan en formatos propietarios, que a menudo limitan la compatibilidad con el aprendizaje automático. El almacenamiento de datos en Azure Databricks saca provecho de las funcionalidades de un almacén de lago de datos de Databricks y Databricks SQL. Para más información, consulte ¿Qué es el almacenamiento de datos en Azure Databricks?.
El uso de los lagos de datos se ha generalizado en la última década gracias a los avances tecnológicos en el almacenamiento de datos y debido al aumento exponencial de los tipos y el volumen de datos. Los lagos de datos almacenan y procesan los datos de forma económica y eficaz. Los lagos de datos suelen definirse en oposición a los almacenes de datos: un almacenamiento de datos ofrece datos limpios y estructurados para el análisis de BI, mientras que un lago de datos almacena de forma permanente y barata los datos de cualquier naturaleza en cualquier formato. Muchas organizaciones usan lagos de datos para la ciencia de datos y el aprendizaje automático, pero no para los informes de BI debido a su naturaleza no validada.
Data Lakehouse combina las ventajas de los lagos de datos y los almacenes de datos y proporciona:
- Acceso directo y abierto a los datos almacenados en formatos de datos estándar.
- Protocolos de indexación optimizados para el aprendizaje automático y la ciencia de datos.
- Baja latencia de consulta y alta confiabilidad para BI y el análisis avanzado.
Al combinar una capa de metadatos optimizada con datos validados almacenados en formatos estándar en el almacenamiento de objetos en la nube, Data Lakehouse permite a los científicos de datos e ingenieros de ML crear modelos a partir de los mismos datos que generan informes de BI.
Paso siguiente
Para obtener más información sobre los principios y las mejores prácticas para implantar y gestionar un almacén de lago de datos con Databricks, consulte Introducción a la buena arquitectura del almacén de lago de datos