Configuración de Delta Lake para controlar el tamaño del archivo de datos
Delta Lake proporciona opciones para configurar manualmente o automáticamente el tamaño del archivo de destino para las escrituras y para las operaciones OPTIMIZE. Azure Databricks ajusta automáticamente muchas de estas opciones de configuración y habilita características que mejoran automáticamente el rendimiento de las tablas mediante la búsqueda de archivos de tamaño correcto.
Nota:
Tanto en Databricks Runtime 13.3 como en las versiones posteriores, Databricks recomienda usar la agrupación en clústeres para el diseño de tabla Delta. Consulte Uso de clústeres líquidos para tablas Delta.
Databricks recomienda usar la optimización predictiva para ejecutar automáticamente OPTIMIZE y VACUUM para las tablas Delta. Consulte Optimización predictiva de para Delta Lake.
En Databricks Runtime 10.4 LTS y versiones posteriores, la compactación automática y las escrituras optimizadas siempre están habilitadas para las operaciones MERGE, UPDATE y DELETE. No puede deshabilitar esta funcionalidad.
A menos que se especifique lo contrario, todas las recomendaciones de este artículo no se aplican a las tablas administradas de Unity Catalog que ejecutan los entornos de ejecución más recientes.
En el caso de las tablas administradas por Unity Catalog, Databricks ajusta la mayoría de estas opciones de configuración automáticamente si usa un almacén de SQL o Databricks Runtime 11.3 LTS o superior.
Si va a actualizar una carga de trabajo desde Databricks Runtime 10.4 LTS o a continuación, consulte Actualización a la compactación automática en segundo plano.
Cuándo se debe ejecutar OPTIMIZE
La compactación automática y las escrituras optimizadas reducen los problemas de archivos pequeños, pero no son un reemplazo completo de OPTIMIZE. Especialmente para las tablas de más de 1 TB, Databricks recomienda ejecutar OPTIMIZE según una programación para consolidar aún más los archivos. Azure Databricks no ejecuta automáticamente ZORDER en las tablas, por lo que debe ejecutarse OPTIMIZE con ZORDER para habilitar la omisión de datos mejorada. Consulte Omisión de datos para Delta Lake.
¿Qué es la optimización automática en Azure Databricks?
El término optimización automática se usa a veces para describir la funcionalidad controlada por la configuración delta.autoOptimize.autoCompact y delta.autoOptimize.optimizeWrite. Este término se ha retirado en favor de describir cada configuración individualmente. Consulte Compactación automática para Delta Lake en Azure Databricks y Escrituras optimizadas para Delta Lake en Azure Databricks.
Compactación automática de Delta Lake en Azure Databricks
La compactación automática combina archivos pequeños dentro de las particiones de tabla Delta para reducir automáticamente los problemas de archivos pequeños. La compactación automática se produce después de que una escritura en una tabla se haya realizado correctamente y se ejecute sincrónicamente en el clúster que ha realizado la escritura. La compactación automática solo compacta los archivos que no se han compactado anteriormente.
Puede controlar el tamaño del archivo de salida estableciendo la configuración de Sparkspark.databricks.delta.autoCompact.maxFileSize. Databricks recomienda usar el ajuste automático en función de la carga de trabajo o el tamaño de la tabla. Consulte Ajuste automático del tamaño de archivo en función de la carga de trabajo y Ajuste automático del tamaño del archivo en función del tamaño de la tabla.
La compactación automática solo se desencadena para particiones o tablas que tienen al menos un número determinado de archivos pequeños. De manera opcional, puede cambiar el número mínimo de archivos necesarios para desencadenar la compactación automática estableciendo spark.databricks.delta.autoCompact.minNumFiles.
La compactación automática se puede habilitar en el nivel de tabla o de sesión mediante la siguiente configuración:
- Propiedad de tabla:
delta.autoOptimize.autoCompact - Configuración de SparkSession:
spark.databricks.delta.autoCompact.enabled
Esta configuración acepta las siguientes opciones:
| Opciones | Comportamiento |
|---|---|
auto (recomendado) |
Ajusta el tamaño del archivo de destino al tiempo que respeta otras funcionalidades de ajuste automático. Requiere Databricks Runtime 10.4 LTS o superior. |
legacy |
Alias para true. Requiere Databricks Runtime 10.4 LTS o superior. |
true |
Use 128 MB como tamaño de archivo de destino. Sin dimensionamiento dinámico. |
false |
Desactiva la compactación automática. Se puede establecer en el nivel de sesión para invalidar la compactación automática de todas las tablas Delta modificadas en la carga de trabajo. |
Importante
En Databricks Runtime 9.1 LTS, cuando otros escritores realizan operaciones como DELETE, MERGE, UPDATE, o OPTIMIZE simultáneamente, la compactación automática puede hacer que esos otros trabajos produzcan un error en un conflicto de transacciones. Esto no es un problema en Databricks Runtime 10.4 LTS y versiones posteriores.
Escrituras optimizadas para Delta Lake en Azure Databricks
Las escrituras optimizadas mejoran el tamaño de archivo a medida que se escriben los datos y benefician las lecturas posteriores en la tabla.
Las escrituras optimizadas son más eficaces para las tablas con particiones, ya que reducen el número de archivos pequeños escritos en cada partición. Escribir menos archivos grandes es más eficaz que escribir muchos archivos pequeños, pero es posible que todavía vea un aumento en la latencia de escritura porque los datos se ordenan aleatoriamente antes de escribirse.
En la imagen siguiente se muestra cómo funcionan las escrituras optimizadas:
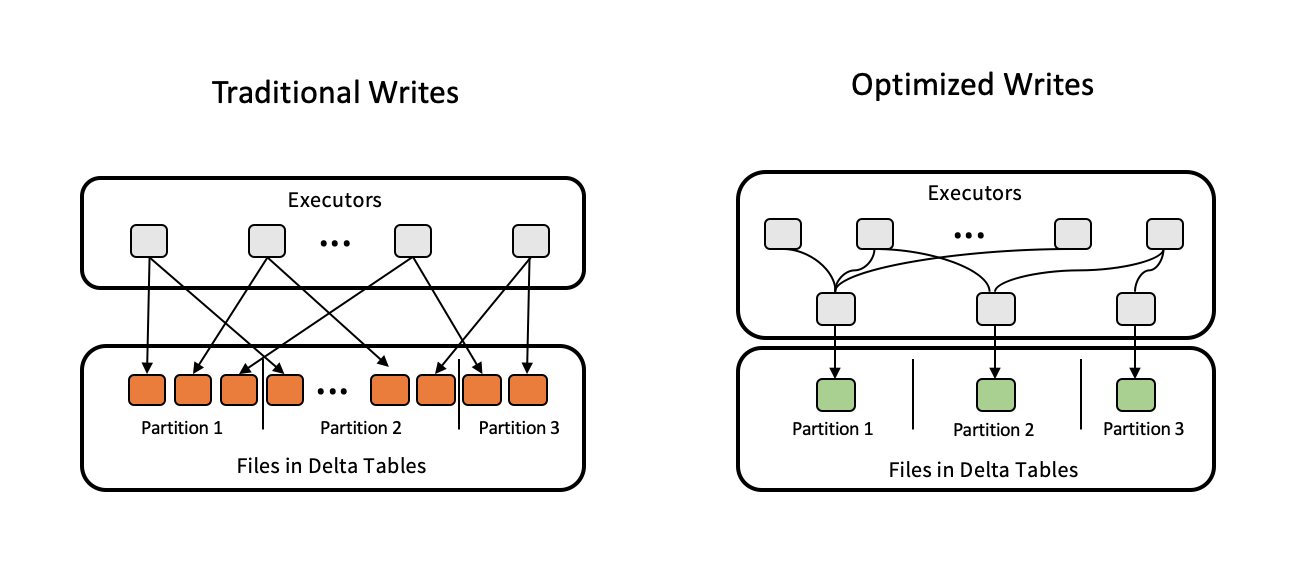
Nota:
Es posible que tenga código que ejecute coalesce(n) o repartition(n) justo antes de escribir los datos para controlar el número de archivos escritos. Las escrituras optimizadas eliminan la necesidad de usar este patrón.
Las escrituras optimizadas están habilitadas de forma predeterminada para las siguientes operaciones en Databricks Runtime 9.1 LTS y versiones posteriores:
MERGEUPDATEcon subconsultasDELETEcon subconsultas
Las escrituras optimizadas también se habilitan para las sentencias CTAS y las operaciones INSERT cuando se utilizan almacenes SQL. En Databricks Runtime 13.3 LTS y versiones posteriores, todas las tablas Delta registradas en Unity Catalog tienen habilitadas escrituras optimizadas para instrucciones CTAS y operaciones INSERT para tablas con particiones.
Las escrituras optimizadas se pueden habilitar en el nivel de tabla o de sesión mediante la siguiente configuración:
- Configuración de tabla:
delta.autoOptimize.optimizeWrite - Configuración de SparkSession:
spark.databricks.delta.optimizeWrite.enabled
Esta configuración acepta las siguientes opciones:
| Opciones | Comportamiento |
|---|---|
true |
Use 128 MB como tamaño de archivo de destino. |
false |
Desactiva las escrituras optimizadas. Se puede establecer en el nivel de sesión para invalidar la compactación automática de todas las tablas Delta modificadas en la carga de trabajo. |
Establecer un tamaño de archivo de destino
Si quiere ajustar el tamaño de los archivos de una tabla de Delta, establezca la propiedad de tabladelta.targetFileSize en el tamaño deseado. Si se establece esta propiedad, todas las operaciones de optimización del diseño de datos harán todo lo posible por generar archivos del tamaño especificado. Algunos ejemplos incluyen optimización u orden Z, compactación automática y escrituras optimizadas.
Nota:
Al usar tablas administradas por Unity Catalog y almacenes de SQL o Databricks Runtime 11.3 LTS y versiones posteriores, solo los comandos OPTIMIZE respetan la configuración targetFileSize.
| Propiedad de tabla |
|---|
| delta.targetFileSize Tipo: Tamaño en bytes o unidades superiores. Tamaño del archivo de destino. Por ejemplo, 104857600 (bytes) o 100mb.Valor predeterminado: ninguno |
En el caso de las tablas existentes, puede establecer y anular la configuración de propiedades mediante el comando SQL ALTER TABLE SET TBL PROPERTIES. Además, puede establecer estas propiedades automáticamente al crear nuevas tablas mediante configuraciones de sesión de Spark. Consulte Referencia de las propiedades de la tabla Delta para más información.
Ajuste automático del tamaño del archivo en función de la carga de trabajo
Databricks recomienda establecer la propiedad de tabla delta.tuneFileSizesForRewrites en true para todas las tablas que son destino de muchas operaciones DML o MERGE, independientemente de Databricks Runtime, Unity Catalog u otras optimizaciones. Cuando se establece en true, el tamaño del archivo de destino de la tabla se establece en un umbral mucho menor, lo que acelera las operaciones de escritura intensiva.
Si no se establece explícitamente, Azure Databricks detecta automáticamente si 9 de las últimas 10 operaciones anteriores en una tabla Delta eran operaciones MERGE y establece esta propiedad de tabla en true. Debe establecer explícitamente esta propiedad en false para evitar este comportamiento.
| Propiedad de tabla |
|---|
| delta.tuneFileSizesForRewrites Escriba: BooleanSi se deben ajustar los tamaños de archivo para la optimización del diseño de los datos. Valor predeterminado: ninguno |
En el caso de las tablas existentes, puede establecer y anular la configuración de propiedades mediante el comando SQL ALTER TABLE SET TBL PROPERTIES. Además, puede establecer estas propiedades automáticamente al crear nuevas tablas mediante configuraciones de sesión de Spark. Consulte Referencia de las propiedades de la tabla Delta para más información.
Ajuste automático del tamaño del archivo en función del tamaño de tabla
Para minimizar la necesidad de ajustes manuales, Azure Databricks ajusta automáticamente el tamaño de archivo de las tablas de Delta en función del tamaño de la tabla. Azure Databricks usará tamaños de archivo más pequeños para tablas más pequeñas, y tamaños de archivo más grandes para tablas más grandes, de modo que el número de archivos de la tabla no crezca demasiado. Azure Databricks no ajusta automáticamente las tablas que ha ajustado con un tamaño de destino específico ni en función de una carga de trabajo con reescrituras frecuentes.
El tamaño del archivo de destino se basa en el tamaño actual de la tabla de Delta. En el caso de las tablas de menos de 2,56 TB, el tamaño del archivo de destino con ajuste automático es de 256 MB. En el caso de las tablas con un tamaño entre 2,56 TB y 10 TB, el tamaño objetivo crecerá linealmente de 256 MB a 1 GB. Para las tablas de más de 10 TB, el tamaño del archivo de destino es de 1 GB.
Nota:
Cuando aumenta el tamaño del archivo de destino para una tabla, el comando OPTIMIZE no vuelve a optimizar los archivos existentes en archivos más grandes. Por lo tanto, una tabla grande siempre puede tener algunos archivos que sean menores que el tamaño de destino. Si también es necesario optimizar esos archivos más pequeños en archivos más grandes, puede configurar un tamaño fijo para el archivo de destino para la tabla mediante la propiedad de tabla delta.targetFileSize.
Cuando una tabla se escribe de forma incremental, los tamaños de los archivos de destino y los recuentos de archivos se acercarán a los siguientes números, según el tamaño de la tabla. Los recuentos de archivos de esta tabla son solo un ejemplo. Los resultados reales serán diferentes en función de muchos factores.
| Tamaño de la tabla | Tamaño del archivo de destino | Número aproximado de archivos en la tabla |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 TB | 256 MB | 4096 |
| 2,56 TB* | 256 MB | 10240 |
| 3 TB | 307 MB | 12108 |
| 5 TB | 512 MB | 17339 |
| 7 TB | 716 MB | 20784 |
| 10 TB | 1 GB | 24437 |
| 20 TB | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 TB | 1 GB | 114437 |
Limitar las filas escritas en un fichero de datos
Ocasionalmente, se puede encontrar un error en las tablas con datos reducidos que indica que el número de filas de un archivo de datos determinado supera los límites de compatibilidad del formato Parquet. Para evitar este error, puede usar la configuración spark.sql.files.maxRecordsPerFile de la sesión de SQL para especificar el número máximo de registros que se van a escribir en un único archivo para una tabla de Delta Lake. Especificar un valor de cero o un valor negativo no representa ningún límite.
En Databricks Runtime 11.3 LTS y versiones posteriores, también puede usar la opción DataFrameWriter maxRecordsPerFile al usar las API de DataFrame para escribir en una tabla de Delta Lake. Cuando se especifica maxRecordsPerFile, se omite el valor de la configuración spark.sql.files.maxRecordsPerFile de la sesión de SQL.
Nota:
Databricks no recomienda usar esta opción a menos que sea necesario evitar el error mencionado anteriormente. Esta configuración puede seguir siendo necesaria para algunas tablas administradas de Unity Catalog con datos muy reducidos.
Actualización a la compactación automática en segundo plano
La compactación automática en segundo plano está disponible para las tablas administradas de Unity Catalog en Databricks Runtime 11.3 LTS y versiones posteriores. Al migrar una carga de trabajo o tabla heredadas, haga lo siguiente:
- Quite la configuración de Spark
spark.databricks.delta.autoCompact.enabledde los valores de configuración del clúster o del cuaderno. - Para cada tabla, ejecute
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)para quitar cualquier configuración de compactación automática heredada.
Después de quitar estas configuraciones heredadas, debería ver que la compactación automática en segundo plano se desencadenó automáticamente para todas las tablas administradas por Unity Catalog.