Enero de 2019
Estas características y mejoras de la plataforma de Azure Databricks se publicaron en enero de 2019.
Nota:
Las versiones se publican por fases. Es posible que su cuenta de Azure Databricks no se actualice hasta una semana después de la fecha de lanzamiento inicial.
Próximo cambio: Python 3 será la versión predeterminada cuando se crean clústeres
29 de enero de 2019
Cuando la versión 2.91 de la plataforma de Databricks se publica a mediados de febrero, la versión predeterminada de Python para los nuevos clústeres pasará de Python 2 a Python 3. Los clústeres existentes no cambiarán sus versiones de Python, por supuesto. Pero si ha tenido el hábito de usar el valor predeterminado de Python 2 al crear nuevos clústeres, deberá empezar a prestar atención a la selección de la versión de Python.
Lanzamiento de Databricks Runtime 5.2 para Machine Learning (versión beta)
24 de enero de 2019
Databricks Runtime 5.2 ML se basa en Databricks Runtime 5.2 (sin soporte técnico). Contiene muchas bibliotecas populares de aprendizaje automático, como TensorFlow, PyTorch, Keras y XGBoost, y proporciona entrenamiento distribuido de TensorFlow mediante Horovod. Además de las actualizaciones de biblioteca desde Databricks Runtime ML 5.1, Databricks Runtime 5.2 ML incluye las siguientes características nuevas:
- GraphFrames ahora admite la API de Pregel (Python) con las optimizaciones de rendimiento de Databricks.
- HorovodRunner agrega:
- En un clúster de GPU, los procesos de entrenamiento se asignan a GPU en lugar de a nodos de trabajo para simplificar el soporte de tipos de instancia de varias GPU. Esta compatibilidad integrada permite distribuir a todas las GPU en una máquina con varias GPU sin código personalizado.
HorovodRunner.run()ahora devuelve el valor devuelto del primer proceso de entrenamiento.
Consulte las notas de la versión completas para Databricks Runtime 5.2 ML
Lanzamiento de Databricks Runtime 5.2
24 de enero de 2019
Databricks Runtime 5.2 ya está disponible. Databricks Runtime 5.2 incluye Apache Spark 2.4.0, nuevas características y actualizaciones de Delta Lake y Structured Streaming, y bibliotecas actualizadas de Python, R, Java y Scala. Para más información, consulte Databricks Runtime 5.2 (sin soporte técnico).
Vista JSON de la configuración de clúster
15-22 de enero de 2019
La página de configuración del clúster ahora admite una vista JSON:
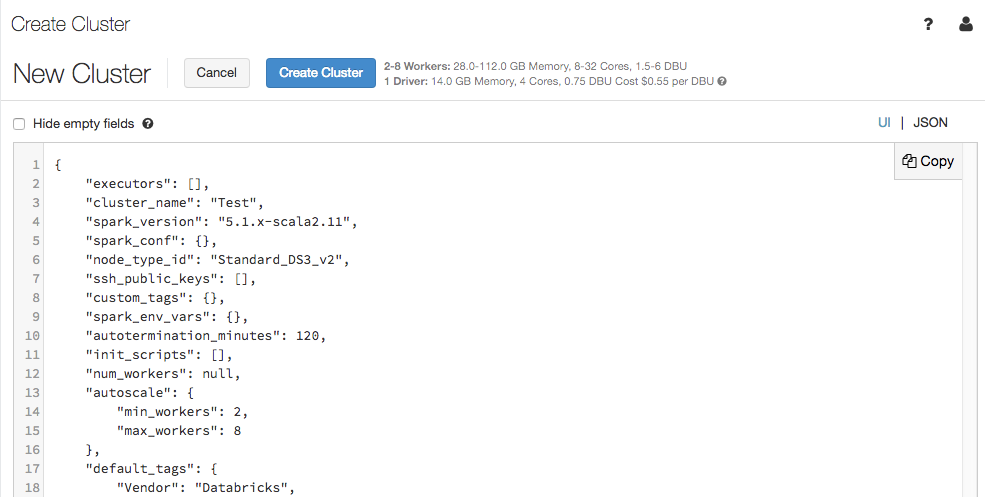
La vista JSON es de solo lectura. Sin embargo, puede copiar el JSON y usarlo para crear y actualizar clústeres con Clusters API.
Interfaz de usuario del clúster
15-22 de enero de 2019: versión 2.89
La página de creación del clúster se ha limpiado y reorganizado para facilitar su uso, incluido una nueva alternancia de Opciones avanzadas.
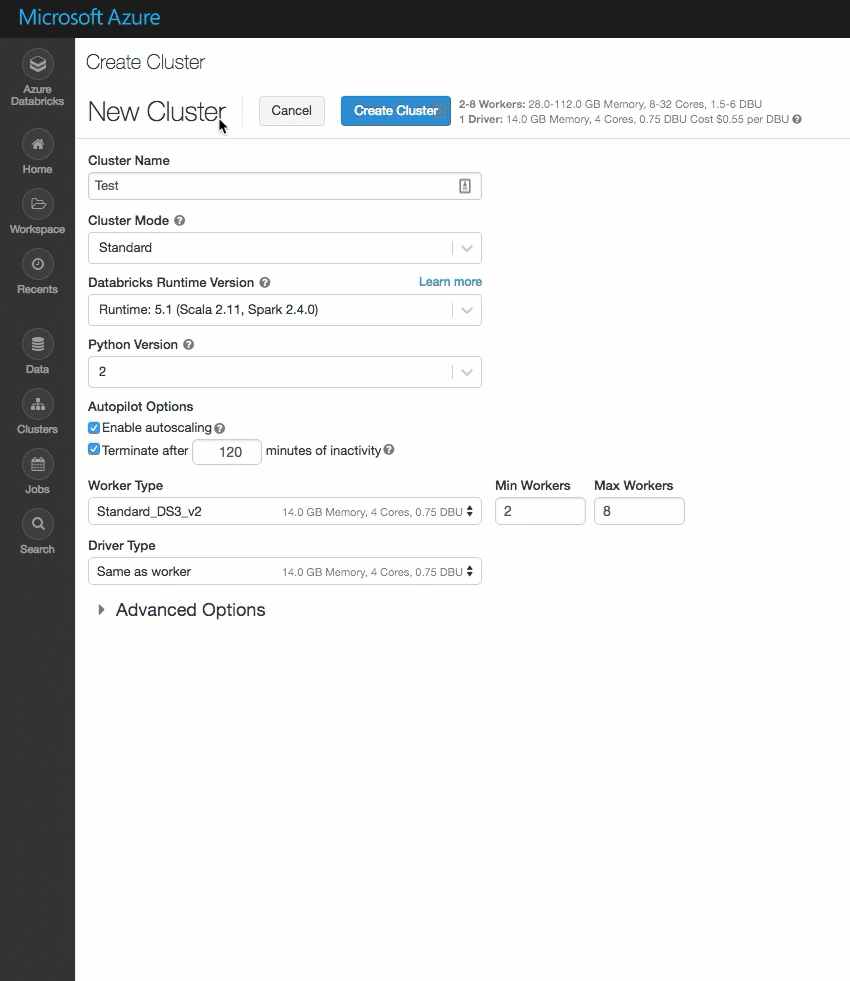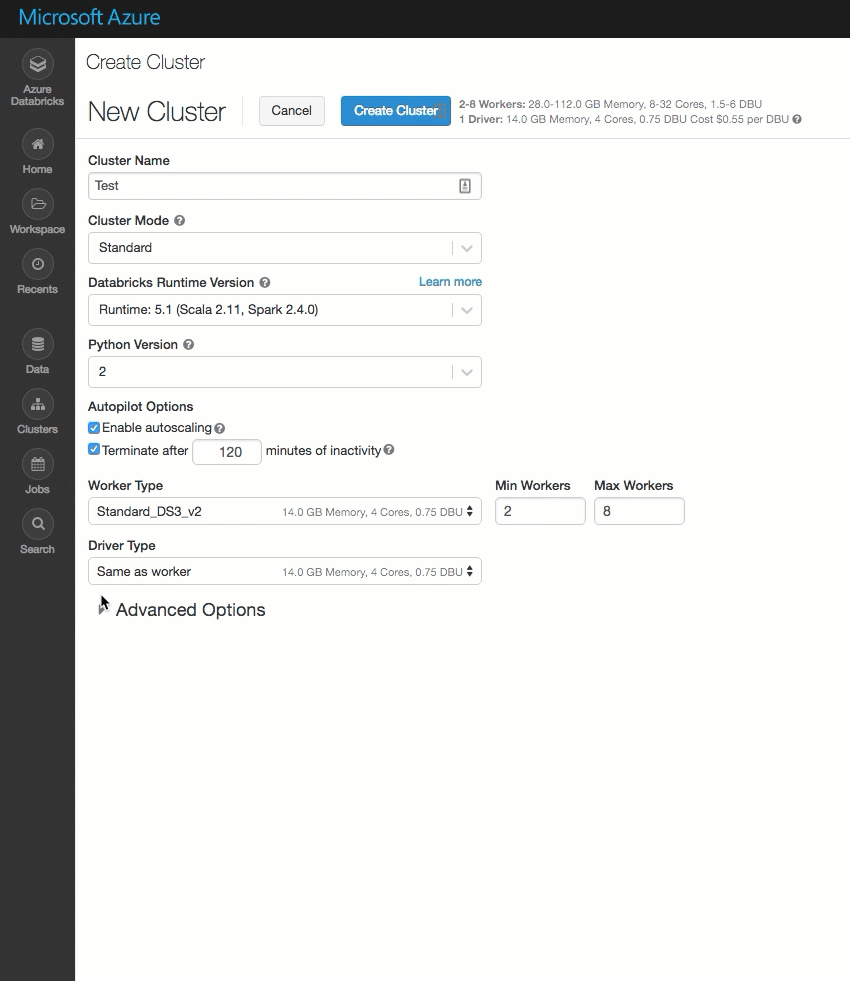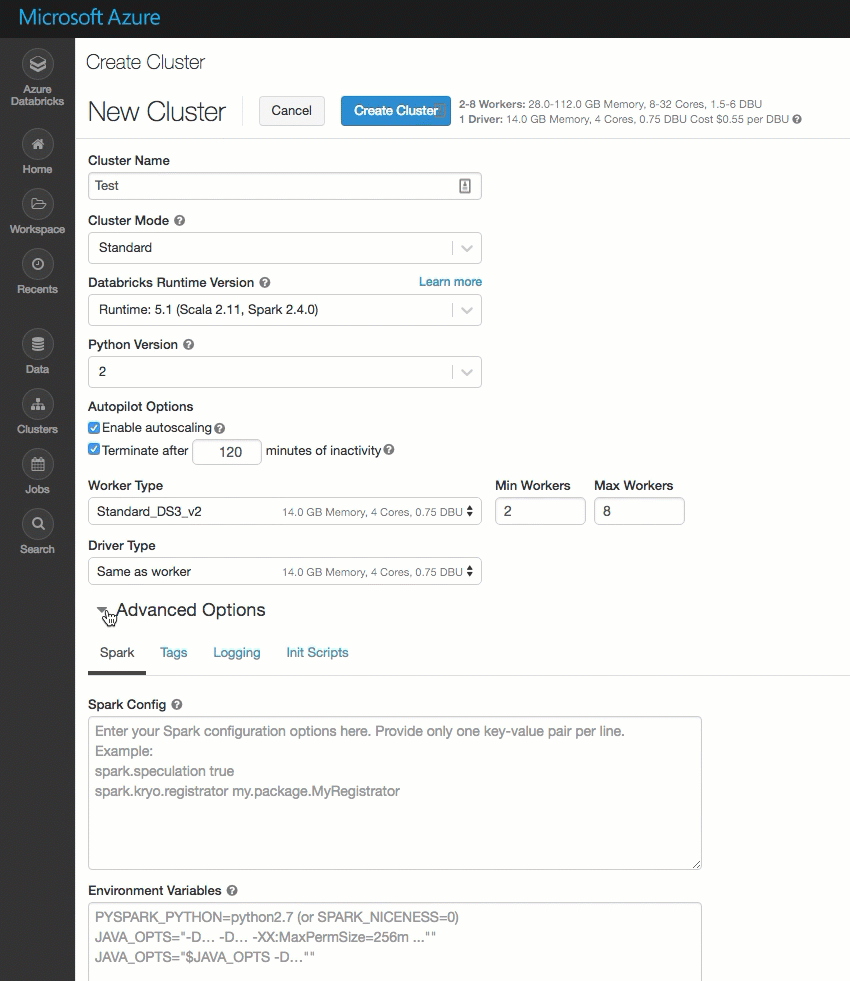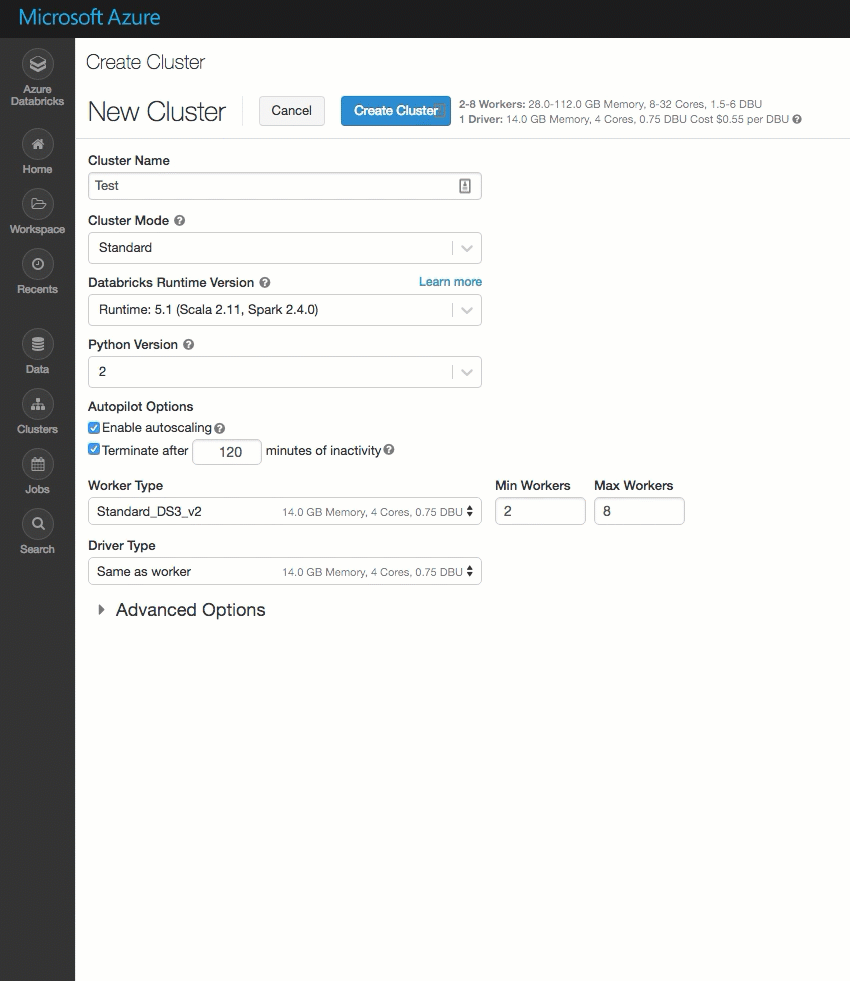
Implementación de Azure Databricks en su propia red virtual de Azure Virtual Network (inserción en red virtual)
10 de enero de 2019
Importante
Esta característica está en versión preliminar pública.
La implementación predeterminada de Azure Databricks es un servicio totalmente administrado en Azure: todos los recursos del plano de proceso, incluida una red virtual (VNet) con la que están asociados todos los clústeres, se implementan en un grupo de recursos bloqueado. Sin embargo, si necesita personalizar la red, puede implementar Azure Databricks en su propia red virtual (proceso también llamado inserción en red virtual) lo que le permitirá:
- Conectar Azure Databricks con otros servicios de Azure (por ejemplo, Azure Storage) de forma más segura mediante puntos de conexión de servicio.
- Conectarse a orígenes de datos en el entorno local para su uso con Azure Databricks, aprovechando las rutas definidas por el usuario.
- Conectar Azure Databricks a una aplicación virtual de red para inspeccionar todo el tráfico saliente y tomar medidas en función de reglas que permitan o denieguen el acceso.
- Configurar Azure Databricks para usar DNS personalizado.
- Configurar reglas de grupo de seguridad de red para especificar las restricciones del tráfico de salida.
- Implementar clústeres de Azure Databricks en la red virtual existente.
Implementar Azure Databricks en su propia red virtual también le permite sacar provecho de rangos CIDR flexibles (entre /16-/24 para la red virtual y entre /18-/26 para las subredes).
La configuración mediante la interfaz de usuario de Azure Portal es rápida y sencilla: al crear un área de trabajo, solo tiene que seleccionar Implementar un área de trabajo Azure Databricks en Virtual Network, seleccionar la red virtual y proporcionar rangos CIDR para dos subredes. Azure Databricks actualiza la red virtual con dos subredes y grupos de seguridad de red nuevos mediante rangos CIDR proporcionados por el usuario, permite el acceso al tráfico de subred entrante y saliente, e implementa el área de trabajo en la red virtual actualizada.
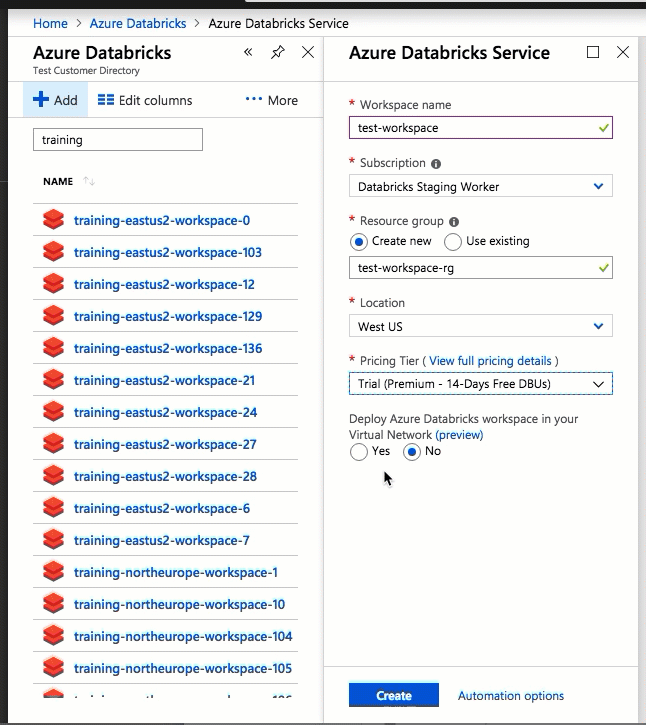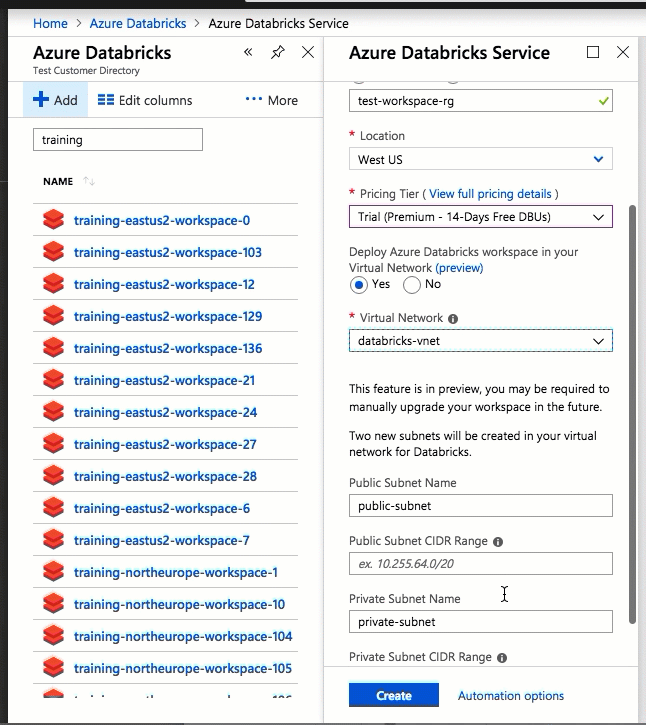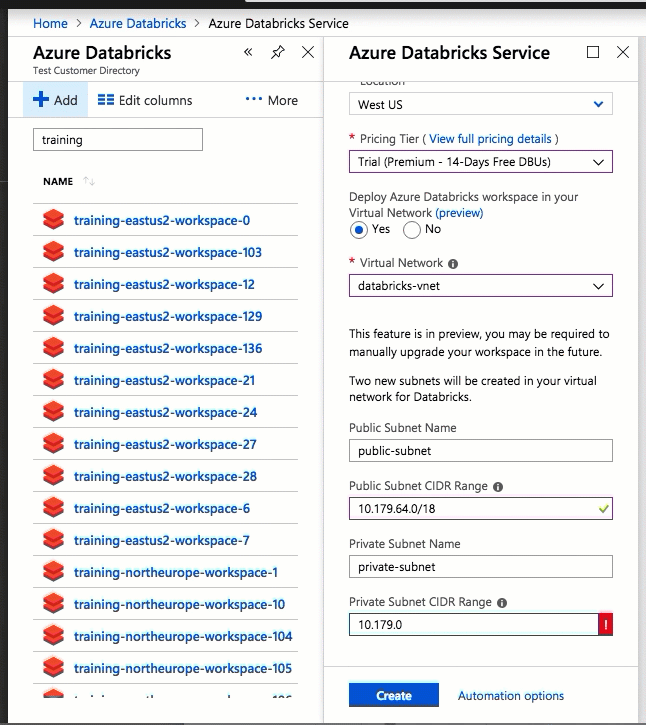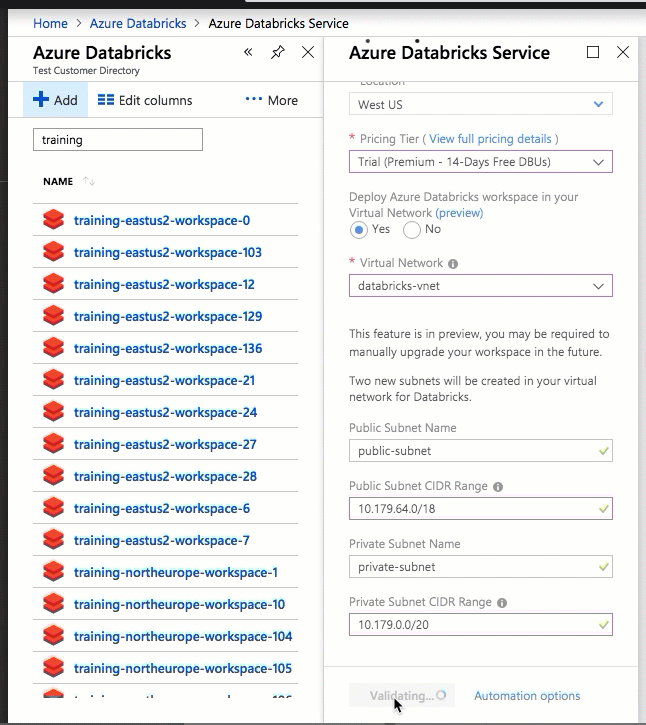
Si prefiere configurar la red virtual para la inserción de red virtual usted mismo (por ejemplo, quiere usar subredes existentes, usar grupos de seguridad de red existentes o crear sus propias reglas de seguridad), puede usar plantillas de ARM proporcionadas por Azure Databricks en lugar de la interfaz de usuario del portal.
Nota:
Esta característica solo estaba disponible anteriormente mediante inscripción. Permanece en Versión preliminar, pero ahora es totalmente de autoservicio.
Para más información, consulte Implementación de Azure Databricks en la red virtual de Azure (inserción de red virtual) y Conectar área de trabajo Azure Databricks en la red local.
UI de la biblioteca
2-9 de enero de 2019: versión 2.88
Las mejoras de la interfaz de usuario de la biblioteca que se publicaron originalmente en noviembre de 2018 y se revirtieron poco después se han vuelto a publicar. Estas actualizaciones facilitan la carga, instalación y administración de bibliotecas para los clústeres de Azure Databricks.
El interfaz de usuario de Azure Databricks ahora admite bibliotecas de área de trabajo y bibliotecas instaladas en clúster. Existe una biblioteca de áreas de trabajo en Workspace y se puede instalar en uno o varios clústeres. Una biblioteca instalada en clúster es una biblioteca que solo existe en el contexto del clúster en el que está instalada. Además:
- Ahora puede crear una biblioteca a partir de un archivo cargado en el almacenamiento de objetos.
- Ahora puede instalar y desinstalar bibliotecas desde la página de detalles de la biblioteca y la pestaña Bibliotecas de un clúster.
- Las bibliotecas instaladas mediante la API ahora se muestran en la pestaña Bibliotecas de un clúster.
Para más información, consulte Bibliotecas.
Eventos de clúster
2-9 de enero de 2019: versión 2.88
Se agregaron nuevos eventos de clúster para reflejar el estado del controlador de Spark. Para más información, consulte Clusters API.
Control de versiones de cuadernos mediante Azure DevOps Services
2-9 de enero de 2019: versión 2.88
Azure Databricks ahora facilita el uso de Azure DevOps Services (anteriormente VSTS) para controlar la versión de los cuadernos. La autenticación es automática, la configuración es sencilla y se administran las revisiones del cuaderno igual que con nuestra integración GitHub.
Para obtener información, consulte Control de versiones de Git para cuadernos (heredado).
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de