Julio de 2019
Estas características y las mejoras de la plataforma Azure Databricks se publicaron en julio de 2019.
Nota:
Las versiones se publican por fases. Es posible que su cuenta de Azure Databricks no se actualice hasta una semana después de la fecha de lanzamiento inicial.
Próximamente: Databricks 6.0 no será compatible con Python 2
En previsión del próximo fin de la vida útil de Python 2, anunciado para 2020, Python 2 no se admitirá en Databricks Runtime 6.0. Las versiones anteriores Databricks Runtime seguirán siendo compatibles con Python 2. Esperamos publicar Databricks Runtime 6.0 más adelante en 2019.
Carga previa de la versión de Databricks Runtime en las instancias inactivas del grupo
Del 30 de julio al 6 de agosto de 2019: versión 2.103
Ahora, puede acelerar el inicio de un clúster con respaldo de grupo, seleccionando una versión de Databricks Runtime para cargarla en las instancias inactivas del grupo. El campo de la interfaz de usuario del grupo se denomina Versión de Spark precargada.

Las etiquetas de clúster y las etiquetas de grupo personalizadas funcionan mejor juntas
Del 30 de julio al 6 de agosto de 2019: versión 2.103
A principios de este mes, Azure Databricks presentó los grupos, un conjunto de instancias inactivas que le ayudan a poner en marcha los clústeres rápidamente. En la versión original, los clústeres con respaldo de grupo heredaban etiquetas predeterminadas y personalizadas de la configuración del grupo, y esas etiquetas no se podían modificar al nivel de clúster. Ahora puede configurar etiquetas personalizadas específicas de un clúster con respaldo de grupo y ese clúster aplicará todas las etiquetas personalizadas, ya sean heredadas del grupo o asignadas específicamente a ese clúster. No se puede agregar una etiqueta personalizada específica del clúster con el mismo nombre de clave que una etiqueta personalizada heredada de un grupo (es decir, no se puede invalidar una etiqueta personalizada heredada del grupo). Para más información, consulte Etiquetas de grupos.
MLflow 1.1 incluye varias mejoras en la interfaz de usuario y la API
Del 30 de julio al 6 de agosto de 2019: versión 2.103
MLflow 1.1 presenta varias características nuevas para mejorar la facilidad de uso de la interfaz de usuario y la API:
La interfaz de usuario de información de ejecuciones ahora le permite examinar varias páginas de ejecuciones si el número de ejecuciones es superior a 100. Después de la ejecución 100, haga clic en el botón Cargar más para cargar las siguientes 100 ejecuciones.
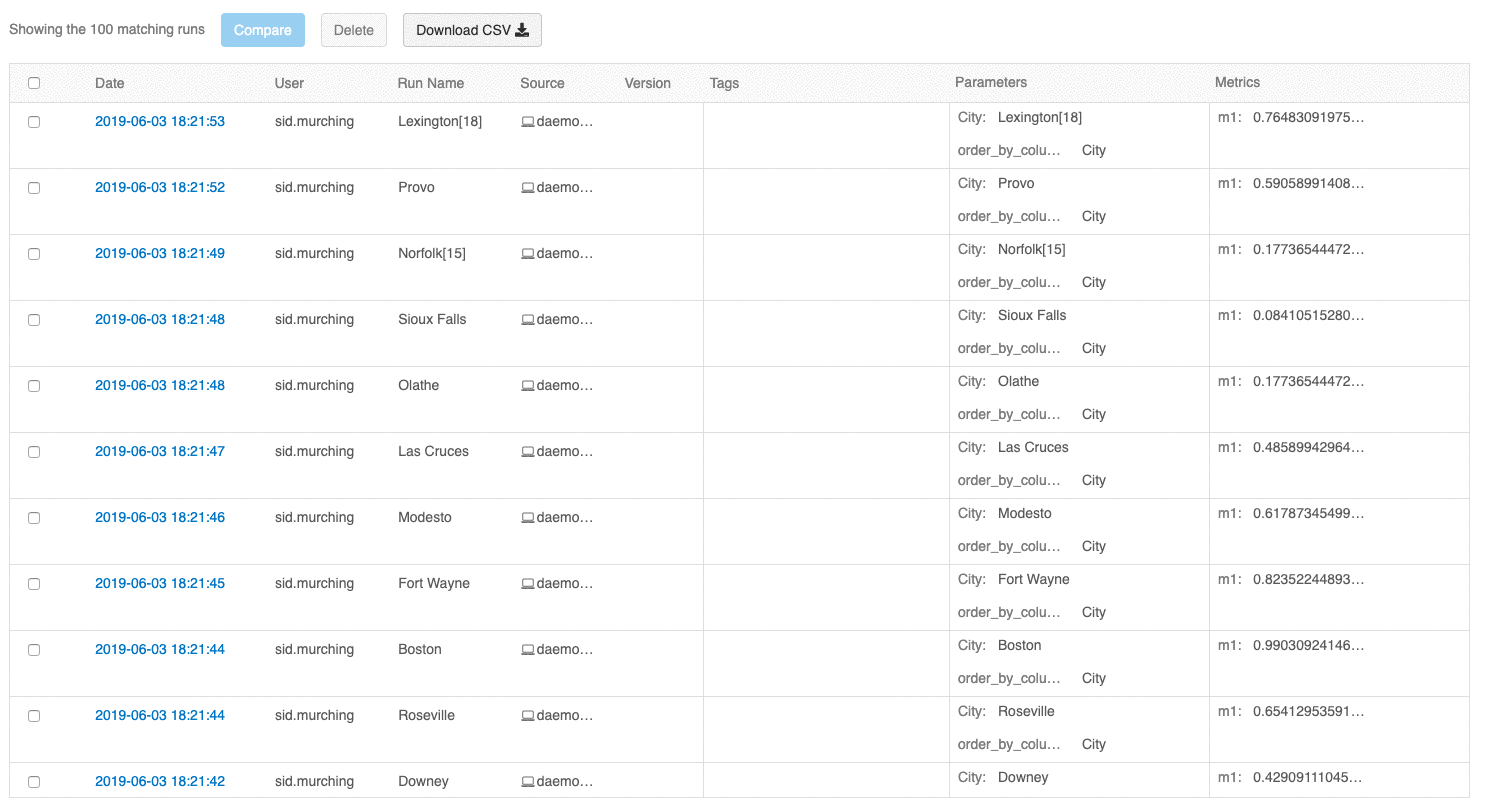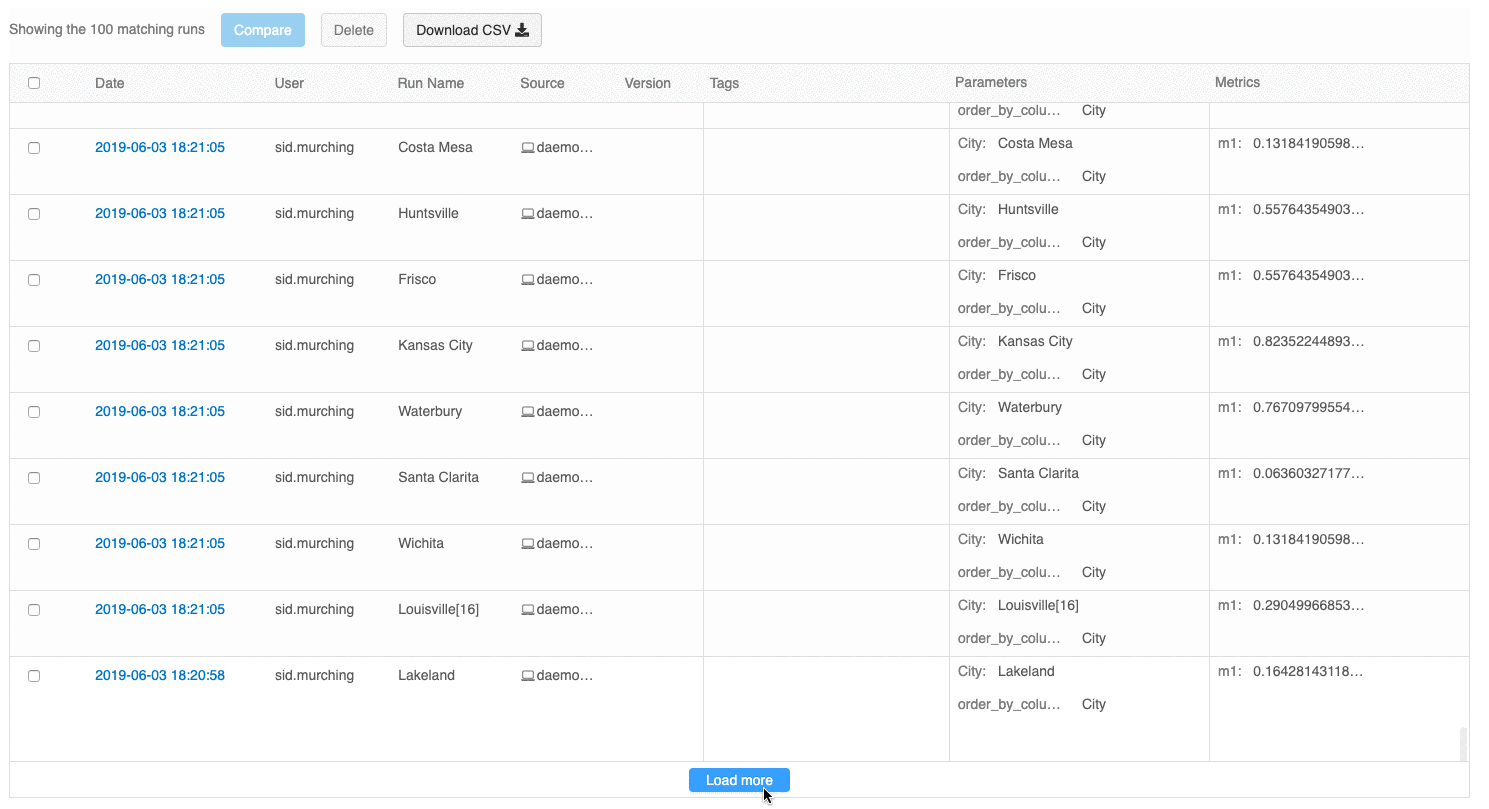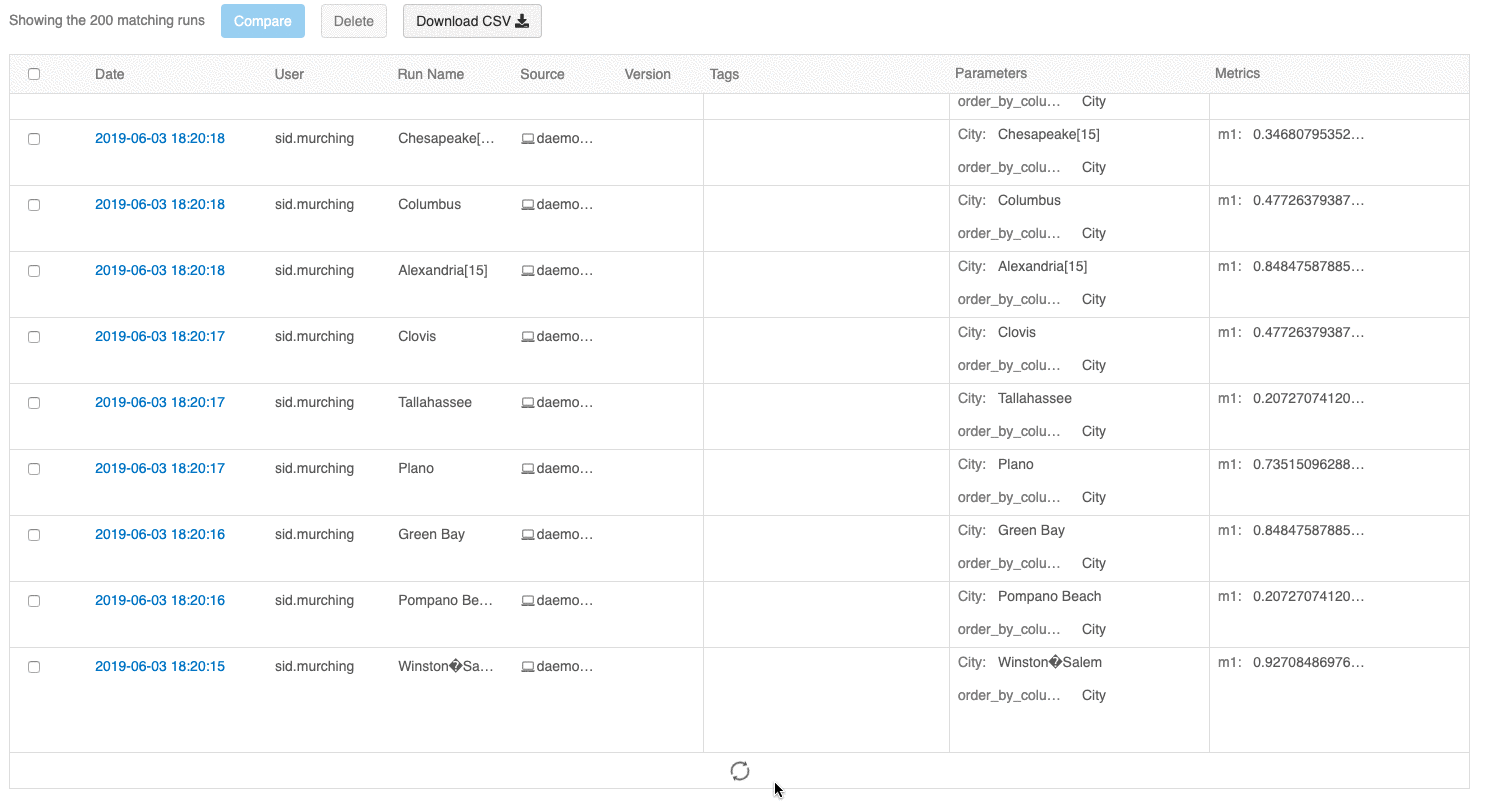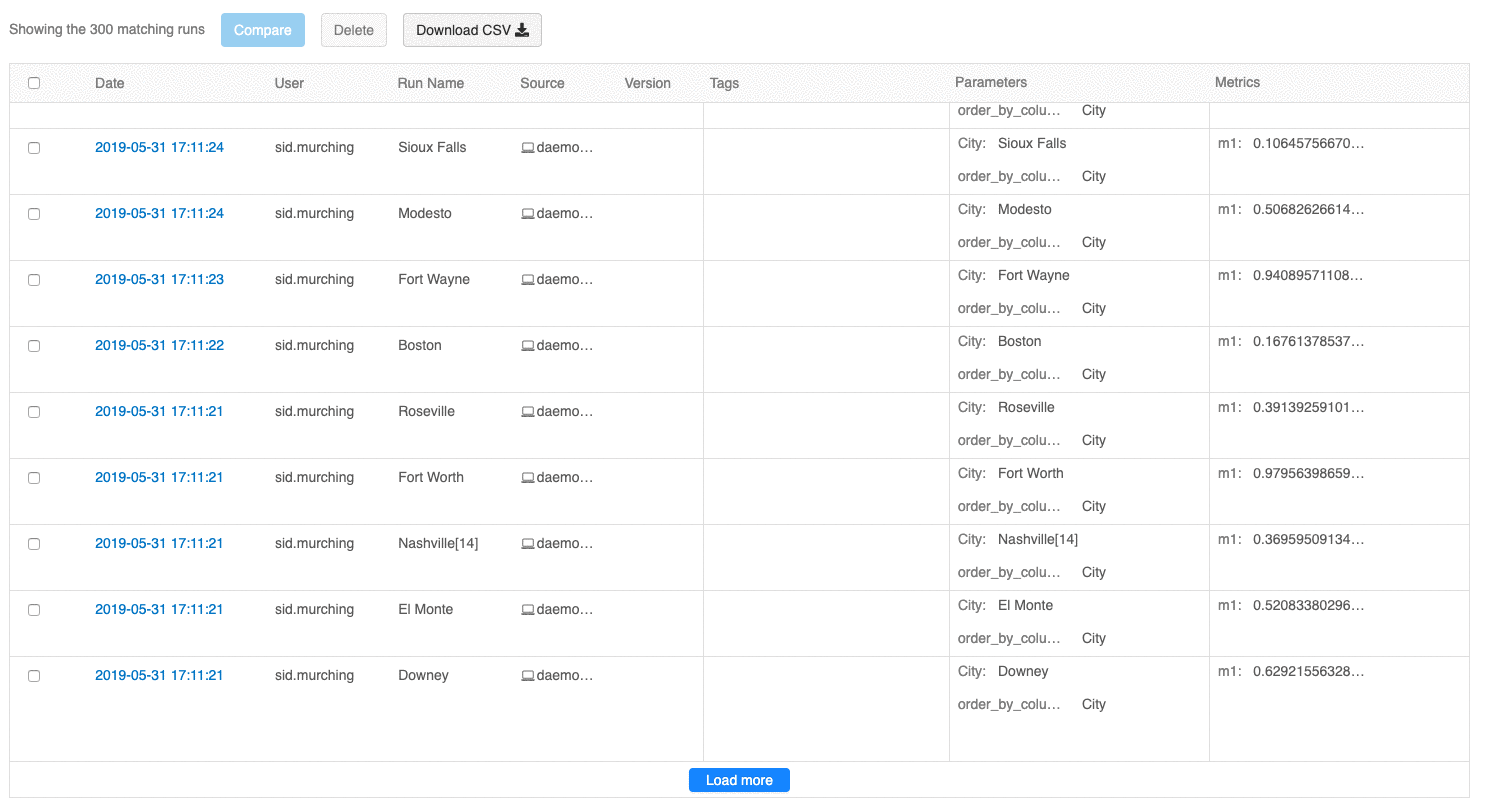
Ahora, la interfaz de usuario de ejecuciones de comparación proporciona un trazado de coordenadas paralelas. El trazado permite observar las relaciones entre un conjunto de parámetros y métricas de n dimensiones. Visualiza todas las ejecuciones como líneas codificadas por colores en función del valor de una métrica (por ejemplo, precisión) y muestra los valores de parámetro que tomó cada ejecución.

Ahora puede agregar y editar etiquetas desde la interfaz de usuario de información de ejecución y ver etiquetas en la vista de búsqueda de experimentos.
La nueva API MLflowContext permite crear y registrar ejecuciones de una manera similar a la API de Python. Esta API contrasta con la API de bajo nivel
MlflowClientexistente, que simplemente encapsula las API REST.Ahora puede eliminar etiquetas de ejecuciones de MLflow mediante la API deleteTag.
Para más información, consulte la entrada de blog MLflow 1.1. Para obtener la lista completa de características y correcciones, consulte el registro de cambios de MLflow.
Los dataframes de Pandas se representan como en Jupyter
Del 30 de julio al 6 de agosto de 2019: versión 2.103
Ahora, cuando llame a un DataFrame de Pandas, se representará de la misma manera que en Jupyter.
Regiones nuevas
30 de julio de 2019
Azure Databricks ahora está disponible en las siguientes regiones adicionales:
- Centro de Corea del Sur
- Norte de Sudáfrica
Databricks Runtime 5.5 con Conda (versión beta)
23 de julio de 2019
Importante
Databricks Runtime con Conda se encuentra en versión Beta. El contenido de los entornos admitidos puede cambiar en las próximas versiones beta. Los cambios pueden incluir la lista de paquetes o versiones de los paquetes instalados. Databricks Runtime 5.5 con Conda se basa en Databricks Runtime 5.5 LTS (sin soporte técnico).
La versión Databricks Runtime 5.5 con Conda agrega una nueva API de biblioteca de ámbito de cuaderno para dar soporte a la actualización del entorno de Conda del cuaderno con una especificación YAML (consulte la documentación de Conda).
Consulte las notas de la versión completas en Databricks Runtime 5.5 con Conda (no compatible).
Se actualizó el límite de conexiones de MetaStore
Del 16 al 23 de julio de 2019: Version 2.102
Las nuevas áreas de trabajo de Azure Databricks de trabajo en eastus, eastus2, centralus, westus, westus2, westeurope, northeurope tendrán un límite de conexión de metastore superior de 250. Las áreas de trabajo existentes seguirán usando el metastore actual sin interrupciones y seguirán teniendo un límite de 100 conexiones.
Establecimiento de permisos en grupos (versión preliminar pública)
Del 16 al 23 de julio de 2019: Version 2.102
La interfaz de usuario del grupo ahora admite la configuración de permisos sobre quién puede administrar grupos y quién puede asociar clústeres a grupos.
Para obtener más información, consulte Permisos de grupo.
Databricks Runtime 5.5 para Machine Learning
15 de julio de 2019
Databricks Runtime 5.5 ML se basa en Databricks Runtime 5.5 LTS (no admitido). Contiene muchas bibliotecas populares de aprendizaje automático, como TensorFlow, PyTorch, Keras y XGBoost, y proporciona entrenamiento distribuido de TensorFlow mediante Horovod.
Esta versión incluye las siguientes características y mejoras nuevas:
- Se ha agregado el paquete de Python para MLflow 1.0
- Bibliotecas de aprendizaje automático actualizadas
- TensorFlow se actualizó de la versión 1.12.0 a la 1.13.1
- PyTorch se actualizó de la versión 0.4.1 a la 1.1.0
- scikit-learn se actualizó de la versión 0.19.1 a la 0.20.3
- Operación de nodo único para HorovodRunner
Para más información, consulte Databricks Runtime 5.5 LTS para ML (sin soporte técnico).
Databricks Runtime 5.5
15 de julio de 2019
Databricks Runtime 5.5 ya está disponible. Databricks Runtime 5.5 incluye Apache Spark 2.4.3, bibliotecas actualizadas de Python, R, Java y Scala, y las siguientes características nuevas:
- Optimización automática GA con Delta Lake en Azure Databricks
- Delta Lake en Azure Databricks mejoró el rendimiento de las consultas de agregación min, max y count
- Canalizaciones de inferencia de modelos más rápidas con mejor origen de datos de archivo binario y una UDF de pandas de iterador escalar (versión preliminar pública)
- API de secretos en cuadernos de R
Para obtener más información, consulte Databricks Runtime 5.5 LTS (no admitido).
Los grupos de instancias se mantienen en espera para un inicio de clúster rápido (versión preliminar pública)
Del 9 al 11 de julio de 2019: Version 2.101
Para reducir el tiempo de inicio del clúster, Azure Databricks ahora admite la asociación de un clúster a un grupo predefinido de instancias inactivas. Cuando se asocia a un grupo, un clúster asigna sus nodos de controlador y de trabajo desde el grupo. Si el grupo no tiene suficientes recursos inactivos para dar cabida a la solicitud del clúster, el grupo se expande asignando nuevas instancias del proveedor de nube. Cuando finaliza un clúster asociado, las instancias que ha usado se devuelven al grupo y otro clúster puede reutilizarlas.
Azure Databricks no cobra DBU por hora mientras las instancias están inactivas en el grupo. Tiene validez la facturación del proveedor de instancias. Consulte Precios.
Para obtener más información, consulte Referencia de configuración del grupo.
Métricas de Ganglia
Del 9 al 11 de julio de 2019: Version 2.101
Ganglia es un sistema de supervisión distribuida escalable que ahora está disponible en los clústeres de Azure Databricks. Las métricas de Ganglia le ayudan a supervisar el rendimiento y el estado del clúster. Puede acceder a las métricas de Ganglia desde la página de detalles del clúster:
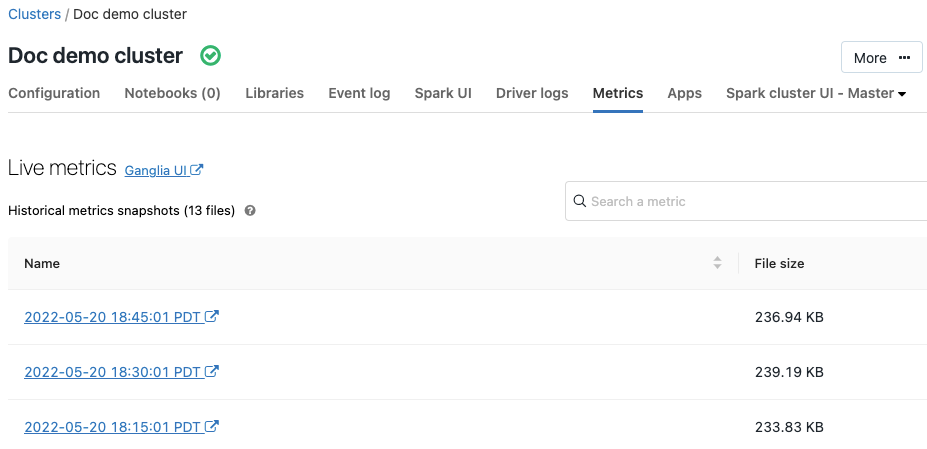
Para obtener más información sobre el uso y la configuración de métricas, consulte Métricas de Ganglia.
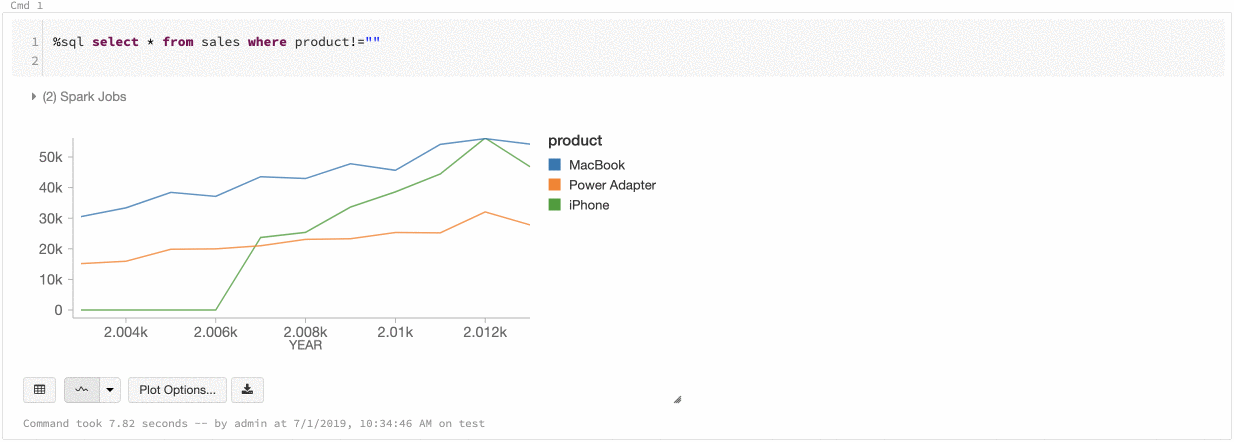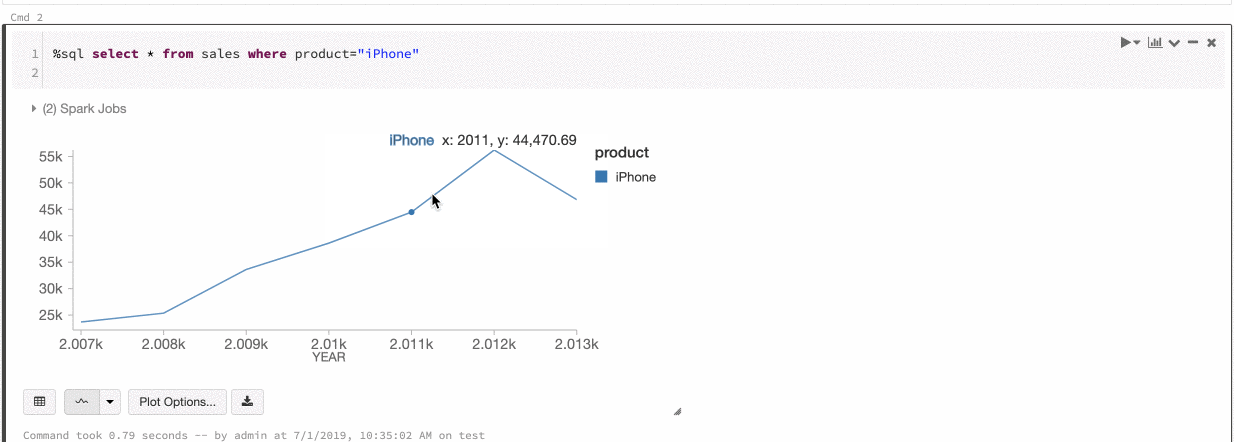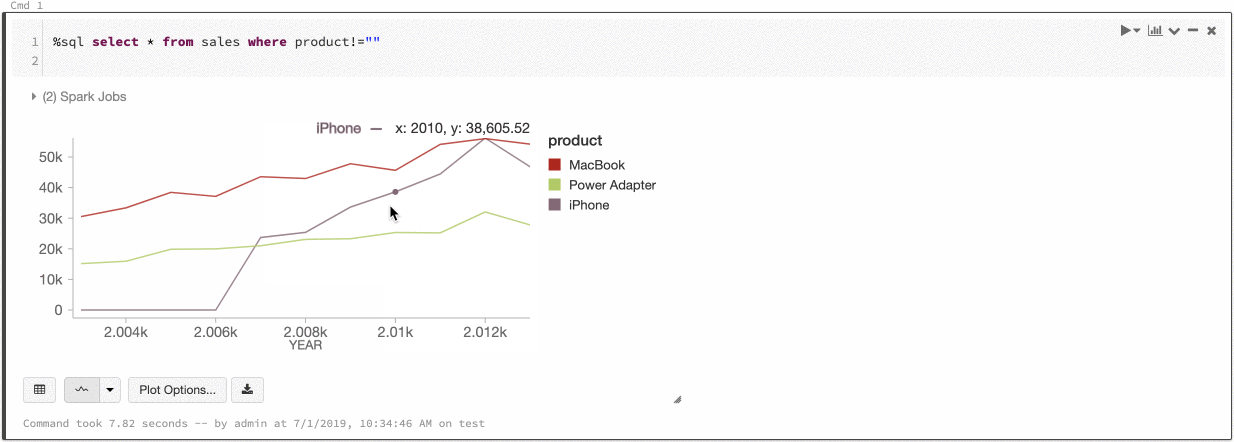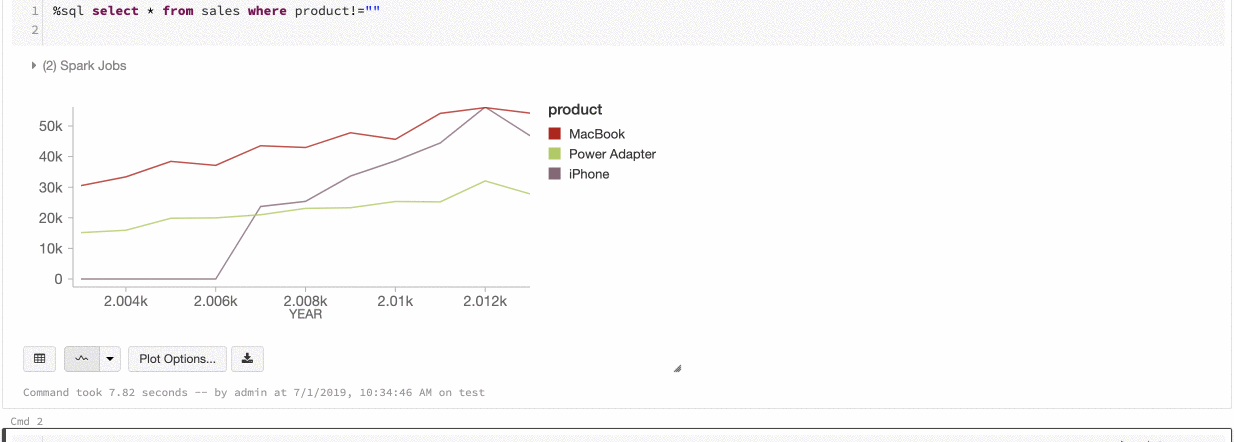
Color global de las series
Del 9 al 11 de julio de 2019: Version 2.101
Ahora puede especificar que los colores de una serie sean coherentes en todos los gráficos del cuaderno. Consulte Coherencia de colores entre gráficos.