Octubre de 2019
Estas características y mejoras de plataforma Azure Databricks se publicaron en octubre de 2019.
Nota:
Las versiones se publican por fases. Su cuenta de Azure Databricks puede no actualizarse hasta una semana después de la fecha de lanzamiento inicial.
Las métricas de compatibilidad se movieron a Azure Event Hubs
22-29 de octubre de 2019
Las métricas de compatibilidad que permiten a Azure Databricks supervisar el estado del clúster se han migrado de Azure Blob Storage a los puntos de conexión del centro de eventos. Esto permite a Azure Databricks proporcionar respuestas de menor latencia para resolver incidentes de clientes. En las áreas de trabajo de inserción de VNet, hemos agregado una regla adicional al grupo de seguridad de red para el EventHub punto de conexión de servicio. Los detalles están disponibles en la tabla de reglas del grupo de seguridad de red. No es necesario realizar ninguna acción para la disponibilidad continua de los servicios.
Para obtener una lista de las métricas de compatibilidad de Azure Databricks con los puntos de conexión Event Hubs por región, consulte Metastore, almacenamiento de artefactos de Blob, almacenamiento de tablas del sistema, almacenamiento de registro de Blob y direcciones IP de punto de conexión de Event Hubs.
El acceso directo a credenciales de Azure Data Lake Storage en clústeres estándar y Scala está en disponibilidad general
22-29 de octubre de 2019: versión 3.5
El acceso directo a credenciales para Python, SQL y Scala en clústeres estándar que ejecutan Databricks Runtime 5.5 y posteriores, así como SparkR en Databricks Runtime 6.0 y posteriores, está disponible con carácter general. Vea Habilitación del acceso directo a credenciales de Azure Data Lake Storage para un clúster estándar.
Disponibilidad general de Databricks Runtime 6.1 para Genomics
22 de octubre de 2019
Databricks Runtime 6.1 para Genomics está disponible con carácter general.
Disponibilidad general de Databricks Runtime 6.1 para Machine Learning
22 de octubre de 2019
Databricks Runtime 6.1 ML está disponible con carácter general. Incluye soporte con clústeres de GPU y actualizaciones a las siguientes bibliotecas de aprendizaje automático:
- TensorFlow a 1.14.0
- PyTorch a 1.2.0
- Torchvision a 0.4.0
- MLflow a 1.3.0
Para obtener más información, consulte las notas de la versión completa Databricks Runtime 6.1 para ML (no admitido).
Las llamadas API de MLflow ahora tienen velocidad limitada
22-29 de octubre de 2019: versión 3.5
Para garantizar una servicio de alta calidad cuando hay mucha carga, Azure Databricks hace cumplir los límites de velocidad de API en todas las llamadas de MLflow API. Los límites se establecen por cuenta para garantizar un uso justo y una alta disponibilidad para todas las organizaciones que comparten un área de trabajo.
Los clientes de MLflow con reintentos automáticos están disponibles en MLflow 1.3.0 y están en Databricks Runtime 6.1 para ML (no admitido). Recomendamos a todos los clientes que cambien a la versión de cliente más reciente de MLflow.
Para obtener más información, consulta API de experimentos.
Disponibilidad general de los grupos de instancias para el inicio rápido de clústeres
22-29 de octubre de 2019: versión 3.5
La característica de Azure Databricks que admite la asociación de un clúster a un grupo predefinido de instancias inactivas ahora está disponible con carácter general.
Azure Databricks no cobra DBU por hora mientras las instancias están inactivas en el grupo. Tiene validez la facturación del proveedor de instancias. Consulte Precios.
Para obtener más información, consulte Referencia de configuración del grupo.
Disponibilidad general de Databricks Runtime 6.1
16 de octubre de 2019
Databricks Runtime 6.1 aporta varias mejoras a Delta Lake:
- Conversión sencilla de tablas al formato de Delta Lake
- API de Python para tablas delta (Versión preliminar pública)
- La limpieza dinámica de archivos (DFP) está habilitada de forma predeterminada
Databricks Runtime 6.1 también elimina varias limitaciones en el acceso directo a credenciales.
Nota:
A partir de la versión 6.1, Databricks Runtime solo admite clústeres de CPU. Si desea usar clústeres de GPU, debe usar Databricks Runtime ML.
Para más información, consulte las notas de la versión completa deDatabricks Runtime 6.1 (no admitido).
Disponibilidad general de Databricks Runtime 6.0 para Genomics
16 de octubre de 2019
Databricks Runtime para Genomics es una variante de Databricks Runtime optimizada para trabajar con datos genómicos y biomédicos. A partir de la versión 6.0, Databricks Runtime para Genomics está disponible con carácter general.
La funcionalidad para implementar un área de trabajo de Azure Databricks en su propia red virtual, también conocida como inserción en red virtual, ahora está disponible con carácter general
9 de octubre de 2019
Nos complace anunciar la disponibilidad general de la capacidad de implementar un área de trabajo de Azure Databricks en su propia red virtual, también conocida como inserción de red virtual. Esta opción está pensada para aquellos usuarios que requieren personalización de red y, por tanto, no quieren usar la red virtual predeterminada que se crea al implementar un área de trabajo de Azure Databricks de la manera estándar. Con la inserción de red virtual, puede:
- Conectar Azure Databricks con otros servicios de Azure (por ejemplo, Azure Storage) de forma más segura mediante puntos de conexión de servicio.
- Conectarse a orígenes de datos en el entorno local para su uso con Azure Databricks, aprovechando las rutas definidas por el usuario.
- Conectar Azure Databricks a una aplicación virtual de red para inspeccionar todo el tráfico saliente y tomar medidas en función de reglas que permitan o denieguen el acceso.
- Configurar Azure Databricks para usar DNS personalizado.
- Configurar reglas de grupo de seguridad de red para especificar las restricciones del tráfico de salida.
- Implementar clústeres de Azure Databricks en la red virtual existente.
Implementar Azure Databricks en su propia red virtual también le permite sacar provecho de rangos de enrutamiento de interdominios sin clases (CIDR) flexibles (entre /16-/24 para la red virtual y hasta /26 para las subredes).
La configuración mediante la interfaz de usuario de Azure Portal es rápida y sencilla: al crear un área de trabajo, solo tiene que seleccionar Implementar un área de trabajo Azure Databricks en Virtual Network, seleccionar la red virtual y proporcionar rangos CIDR para dos subredes. Azure Databricks actualiza la red virtual con las dos nuevas subredes y grupos de seguridad de red, permite acceso al tráfico de subred entrante y saliente, e implementa el área de trabajo en la red virtual actualizada.
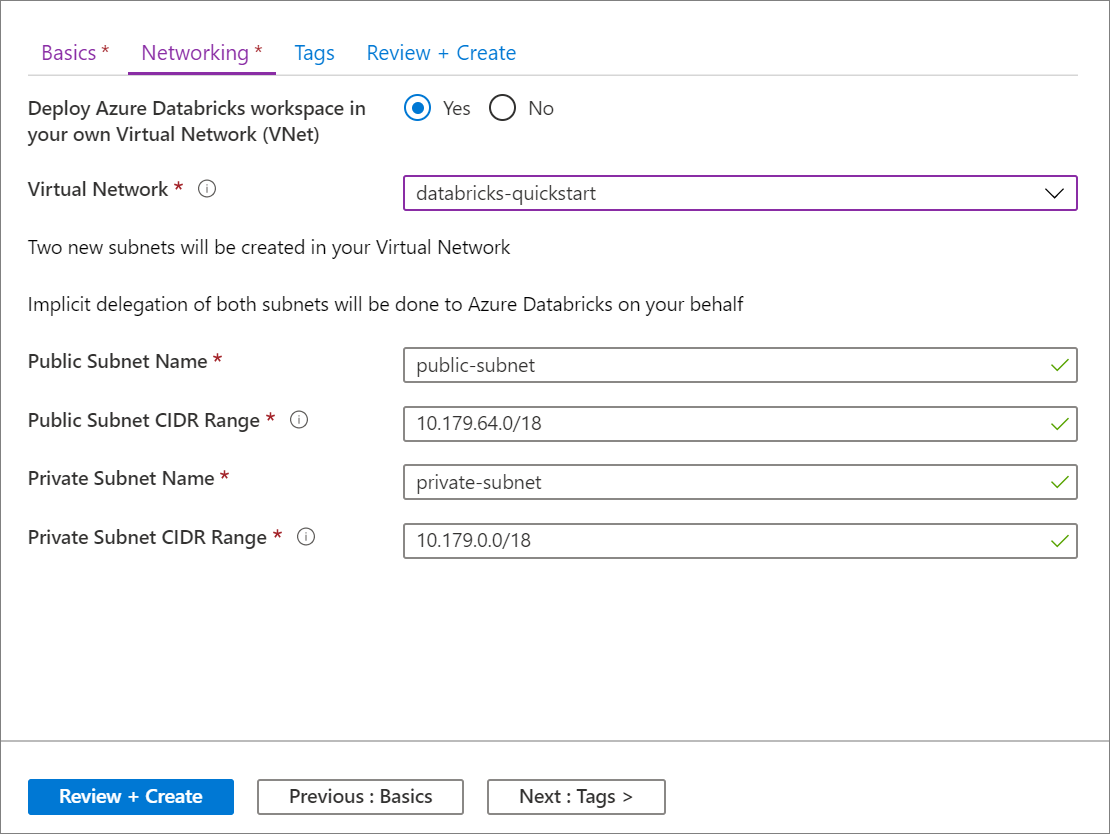
Si prefiere configurar la red virtual para la inserción de red virtual usted mismo (por ejemplo, quiere usar subredes existentes, usar grupos de seguridad de red existentes o crear sus propias reglas de seguridad), puede usar plantillas de ARM proporcionadas por Azure Databricks en lugar de la interfaz de usuario del portal.
Nota:
Si ha participado en la versión preliminar de inserción de red virtual, debe actualizar el área de trabajo de versión preliminar a la versión de disponibilidad general antes del 31 de enero de 2020 para seguir recibiendo soporte técnico.
Para más información, consulte Implementación de Azure Databricks en la red virtual de Azure (inserción de red virtual) y Conectar área de trabajo Azure Databricks en la red local.
Los usuarios que no son administradores de Azure Databricks pueden leer los nombres e identificadores de usuarios y grupos mediante la API de SCIM
8-15 de octubre de 2019: versión 3.4
Los usuarios que no son administradores ahora pueden invocar los extremos Obtener usuarios y Obtener grupos de la API de grupos para leer solo los ID y los nombres para mostrar de usuarios y grupos. Todas las demás operaciones de API de SCIM siguen necesitando acceso de administrador.
La API del área de trabajo devuelve los identificadores de objeto de los cuadernos y carpetas
8-15 de octubre de 2019: versión 3.4
Los puntos de conexión get-status y list de la API del área de trabajo ahora devuelven los nombres de objeto de cuaderno y carpeta, lo que te ofrece la capacidad de hacer referencia a esos objetos en otras llamadas API.
Disponibilidad general de Databricks Runtime 6.0 ML
4 de octubre de 2019
Databricks Runtime 6.0 ML incluye las siguientes actualizaciones:
- MLflow
- Un nuevo origen de datos de Spark para experimentos de MLflow ahora proporciona una API estándar para cargar datos de ejecución de experimentos de MLflow.
- Se ha agregado el cliente Java de MLflow.
- MLflow ahora se promueve como una biblioteca de nivel superior
- Hyperopt disponibilidad general: entre las mejoras importantes desde la versión preliminar pública se incluyen el servicio de asistencia para iniciar sesión MLflow en el rol de trabajo de Spark, el control correcto de las variables de difusión de PySpark, así como una nueva guía sobre la selección de modelos mediante Hyperopt.
- Se han actualizado las bibliotecas Horovod y MLflow y la distribución de Anaconda.
Nota:
En esta versión solo se admiten clústeres de CPU.
Para más información, consulte las notas de la versión completa deDatabricks Runtime 6.0 para Machine Learning (no admitido).
Regiones nuevas: Sur de Brasil y Centro de Francia
1 de octubre de 2019
Azure Databricks está disponible en el sur de Brasil (estado de São Paulo) y centro de Francia (París).
Disponibilidad general de Databricks Runtime 6.0
1 de octubre de 2019
Databricks Runtime 6.0 ofrece muchas actualizaciones de biblioteca y características nuevas, entre las que se incluyen:
- Nuevas API de Scala y Java para comandos DML de Delta Lake, así como los comandos de utilidad de vacío e historial.
- Cliente FUSE de DBFS mejorado para lecturas y escrituras más rápidas y confiables durante el entrenamiento del modelo.
- Soporte técnico con varios trazados matplotlib por celda de cuaderno.
- Actualización a Python 3.7, así como bibliotecas numpy, pandas, matplotlib y otras, actualizadas.
- Soporte técnico de puesta del sol en Python 2.
Nota:
En esta versión solo se admiten clústeres de CPU.
Para más información, consulte las notas de la versión completa de Databricks Runtime 6.0 (no admitido).