Lecturas y escrituras en streaming de tablas delta
Delta Lake está integrado en gran medida con Spark Structured Streaming a través de readStream y writeStream. Delta Lake supera muchas de las limitaciones asociadas normalmente a los sistemas y archivos de streaming, entre las que se incluyen:
- Uso de archivos pequeños generados por la ingesta de baja latencia.
- Mantener el procesamiento "exactamente una vez" con más de un flujo (o trabajos por lotes simultáneos).
- Detectar de forma eficaz qué archivos son nuevos cuando se usan archivos como origen de una secuencia.
Nota:
En este artículo se describe el uso de tablas de Delta Lake como orígenes de streaming y receptores. Para obtener información sobre cómo cargar datos mediante tablas de streaming en Databricks SQL, consulte Carga de datos mediante tablas de streaming en Databricks SQL.
Tabla Delta como origen
Structured Streaming lee incrementalmente tablas Delta. Mientras una consulta de streaming está activa en una tabla Delta, los nuevos registros se procesan de forma idempotente a medida que las nuevas versiones de la tabla hacen "commit" en la tabla de origen.
Los siguientes ejemplos de código muestran la configuración de una lectura de streaming usando el nombre de la tabla o la ruta de acceso al archivo.
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Importante
Si el esquema de una tabla Delta cambia después de que se inicie una lectura de streaming en la tabla, se produce un error en la consulta. Para la mayoría de los cambios de esquema, puede reiniciar la secuencia para resolver el error de coincidencia del esquema y continuar con el procesamiento.
En Databricks Runtime 12.2 LTS y versiones inferiores, no puede transmitir desde una tabla Delta con la asignación de columnas habilitada que haya experimentado una evolución del esquema no aditivo, como un cambio de nombre o una eliminación de columnas. Para más detalles, consulte Streaming con asignación de columnas y cambios de esquema.
Limitación de la velocidad de entrada
Las siguientes opciones están disponibles para controlar los micro lotes:
maxFilesPerTrigger: cuántos archivos nuevos se deben tener en cuenta en cada micro lote. El valor predeterminado es 1000.maxBytesPerTrigger: cantidad de datos que se procesan en cada micro lote. Esta opción establece un "máximo flexible", lo que significa que un lote procesa aproximadamente esta cantidad de datos y puede procesar más que el límite para que la consulta de flujo avance en los casos en que la unidad de entrada más pequeña sea mayor que este límite. Esto no se establece de forma predeterminada.
Si usa maxBytesPerTrigger junto con maxFilesPerTrigger, el micro lote procesa los datos hasta que se alcanza el límite maxFilesPerTrigger o el maxBytesPerTrigger.
Nota:
En los casos en los que las transacciones de la tabla de origen se limpian debido a la logRetentionDurationconfiguración y la consulta de streaming intenta procesar esas versiones, de forma predeterminada, la consulta no puede evitar la pérdida de datos. Puede establecer la opción failOnDataLoss en false para omitir los datos perdidos y continuar el procesamiento.
Transmisión de una fuente de captura de distribución de datos modificados (CDC) de Delta Lake
La fuente de distribución de datos modificados de Delta Lake registra los cambios en una tabla Delta, incluidas las actualizaciones y eliminaciones. Cuando está habilitada, puede transmitir desde una fuente de distribución de datos modificados y escribir lógica para procesar inserciones, actualizaciones y eliminaciones en tablas de bajada. Aunque la salida de datos de la fuente de distribución de datos modificados difiere ligeramente de la tabla Delta que describe, esto proporciona una solución para propagar los cambios incrementales a las tablas descendentes en una arquitectura de medallion.
Importante
En Databricks Runtime 12.2 LTS y versiones inferiores, no puede transmitir desde la fuente de datos de cambios para una tabla Delta con la asignación de columnas activada que haya sufrido una evolución del esquema no aditiva, como el cambio de nombre o la eliminación de columnas. Consulte Streaming con asignación de columnas y cambios de esquema.
Omisión de actualizaciones y eliminaciones
Structured Streaming no controla la entrada que no es un anexo y produce una excepción si se producen modificaciones en la tabla que se usa como origen. Hay dos estrategias principales para tratar los cambios que no se pueden propagar automáticamente de bajada:
- Puede eliminar la salida y el punto de control y reiniciar el flujo desde el principio.
- Se puede configurar cualquiera de estas dos opciones:
ignoreDeletes: omisión de las transacciones que eliminan datos en los límites de partición.skipChangeCommits: omisión de las transacciones que eliminan o modifican los registros existentes.skipChangeCommitssubsumesignoreDeletes.
Nota:
En Databricks Runtime 12.2 LTS y versiones posteriores, skipChangeCommits deja de usar el valor ignoreChanges anterior. En Databricks Runtime 11.3 LTS y versiones anteriores, ignoreChanges es la única opción admitida.
La semántica de ignoreChanges difiere en gran medida de skipChangeCommits. Con ignoreChanges habilitado, los archivos de datos reescritos en la tabla de origen se vuelven a emitir después de una operación de cambio de datos, como UPDATE, MERGE INTO, DELETE (dentro de las particiones) o OVERWRITE. Las filas sin cambios a menudo se emiten junto con las nuevas filas, por lo que los consumidores descendentes deben poder controlar los duplicados. Las eliminaciones no se propagan de bajada. ignoreChanges subsumes ignoreDeletes.
skipChangeCommits omite completamente las operaciones de cambio de archivo. Los archivos de datos que se reescriben en la tabla de origen debido a la operación de cambio de datos, como UPDATE, MERGE INTO, DELETE y OVERWRITE, se omiten por completo. Para reflejar los cambios en las tablas de origen ascendentes, debe implementar una lógica independiente para propagar estos cambios.
Las cargas de trabajo configuradas con ignoreChanges siguen funcionando mediante la semántica conocida, pero Databricks recomienda usar skipChangeCommits para todas las cargas de trabajo nuevas. La migración de cargas de trabajo que usan ignoreChanges a skipChangeCommits requiere una lógica de refactorización.
Ejemplo
Por ejemplo, suponga que tiene la tabla user_events que está particionada con datedate, user_email y action columnas. Se transmite fuera de la tabla user_events y es necesario eliminar datos de ella debido al RGPD.
Cuando se elimina en los límites de la partición (es decir, WHERE se encuentra en una columna de partición), los archivos ya están segmentados por valor, por lo que la eliminación simplemente quita esos archivos de los metadatos. Al eliminar una partición completa de datos, puede usar lo siguiente:
spark.readStream.format("delta")
.option("ignoreDeletes", "true")
.load("/tmp/delta/user_events")
Si elimina datos en varias particiones (en este ejemplo, filtrar por user_email), use la sintaxis siguiente:
spark.readStream.format("delta")
.option("skipChangeCommits", "true")
.load("/tmp/delta/user_events")
Si actualiza un user_email con la instrucción UPDATE, se reescribe el archivo que contiene user_email en cuestión. Use skipChangeCommits para omitir los archivos de datos modificados.
Especificación de la posición inicial
Puede usar las siguientes opciones para especificar el punto inicial del origen de streaming de Delta Lake sin procesar toda la tabla.
startingVersion: la versión de Delta Lake desde la que comenzar. Databricks recomienda omitir esta opción para la mayoría de las cargas de trabajo. Cuando no se establece, la secuencia comienza desde la versión disponible más reciente, incluida una instantánea completa de la tabla en ese momento.Si se especifica, la secuencia lee todos los cambios en la tabla Delta a partir de la versión especificada (inclusive). Si la versión especificada ya no está disponible, la secuencia no se inicia. Puede obtener las versiones de confirmación de la columna
versionde la salida del comando DESCRIBE HISTORY.Para devolver solo los cambios más recientes, especifique
latest.startingTimestamp: marca de tiempo desde la que empezar. El lector de streaming lee todos los cambios de tabla confirmados en la marca de tiempo o después (inclusive). Si la marca de tiempo proporcionada precede a todas las confirmaciones de tabla, la lectura de streaming comienza con la marca de tiempo más antigua disponible. Uno de los valores siguientes:- Una cadena de marca de tiempo. Por ejemplo,
"2019-01-01T00:00:00.000Z". - Una cadena de fecha. Por ejemplo,
"2019-01-01".
- Una cadena de marca de tiempo. Por ejemplo,
No puede establecer ambas opciones al mismo tiempo. Solo tienen efecto al iniciar una nueva consulta de streaming. Si se ha iniciado una consulta de streaming y el progreso se ha registrado en su punto de control, estas opciones se omiten.
Importante
Aunque puede iniciar el origen de streaming desde una versión o marca de tiempo especificadas, el esquema del origen de streaming siempre es el esquema más reciente de la tabla Delta. Debe asegurarse de que no hay ningún cambio de esquema incompatible en la tabla Delta después de la versión o marca de tiempo especificada. De lo contrario, el origen de streaming puede devolver resultados incorrectos al leer los datos con un esquema incorrecto.
Ejemplo
Por ejemplo, supongamos que tiene una tabla user_events. Si desea leer los cambios desde la versión 5, use:
spark.readStream.format("delta")
.option("startingVersion", "5")
.load("/tmp/delta/user_events")
Si desea leer los cambios desde la versión 2018-10-18, use:
spark.readStream.format("delta")
.option("startingTimestamp", "2018-10-18")
.load("/tmp/delta/user_events")
Procesamiento de la instantánea inicial sin quitar datos
Nota:
Esta característica está disponible en Databricks Runtime 11.3 LTS y versiones posteriores. Esta característica está en versión preliminar pública.
Cuando se usa una tabla Delta como origen de streaming, la consulta procesa primero todos los datos presentes en la tabla. La tabla Delta de esta versión se denomina "instantánea inicial". De manera predeterminada, los archivos de datos de la tabla Delta se procesan en función del archivo que se modificó por última vez. Sin embargo, la hora de la última modificación no representa necesariamente el orden de la hora de los eventos en el registro.
En una consulta de streaming con estado con una marca de agua definida, el procesamiento de archivos por la hora de modificación puede dar lugar a que los registros se procesen en el orden incorrecto. Esto podría provocar la anulación de registros como eventos retrasados por la marca de agua.
Para evitar el problema de anulación de datos, habilite la siguiente opción:
- withEventTimeOrder: indica si la instantánea inicial debe procesarse con el orden de la hora de los eventos.
Con el orden de la hora de los eventos habilitado, el intervalo de tiempo de los eventos de los datos de la instantánea inicial se divide en cubos de tiempo. Cada microlote procesa un cubo filtrando los datos dentro del intervalo de tiempo. Las opciones de configuración maxFilesPerTrigger y maxBytesPerTrigger siguen estando en vigor para controlar el tamaño del microlote, pero solo de forma aproximada debido a la naturaleza del procesamiento.
En el gráfico siguiente se muestra este proceso:
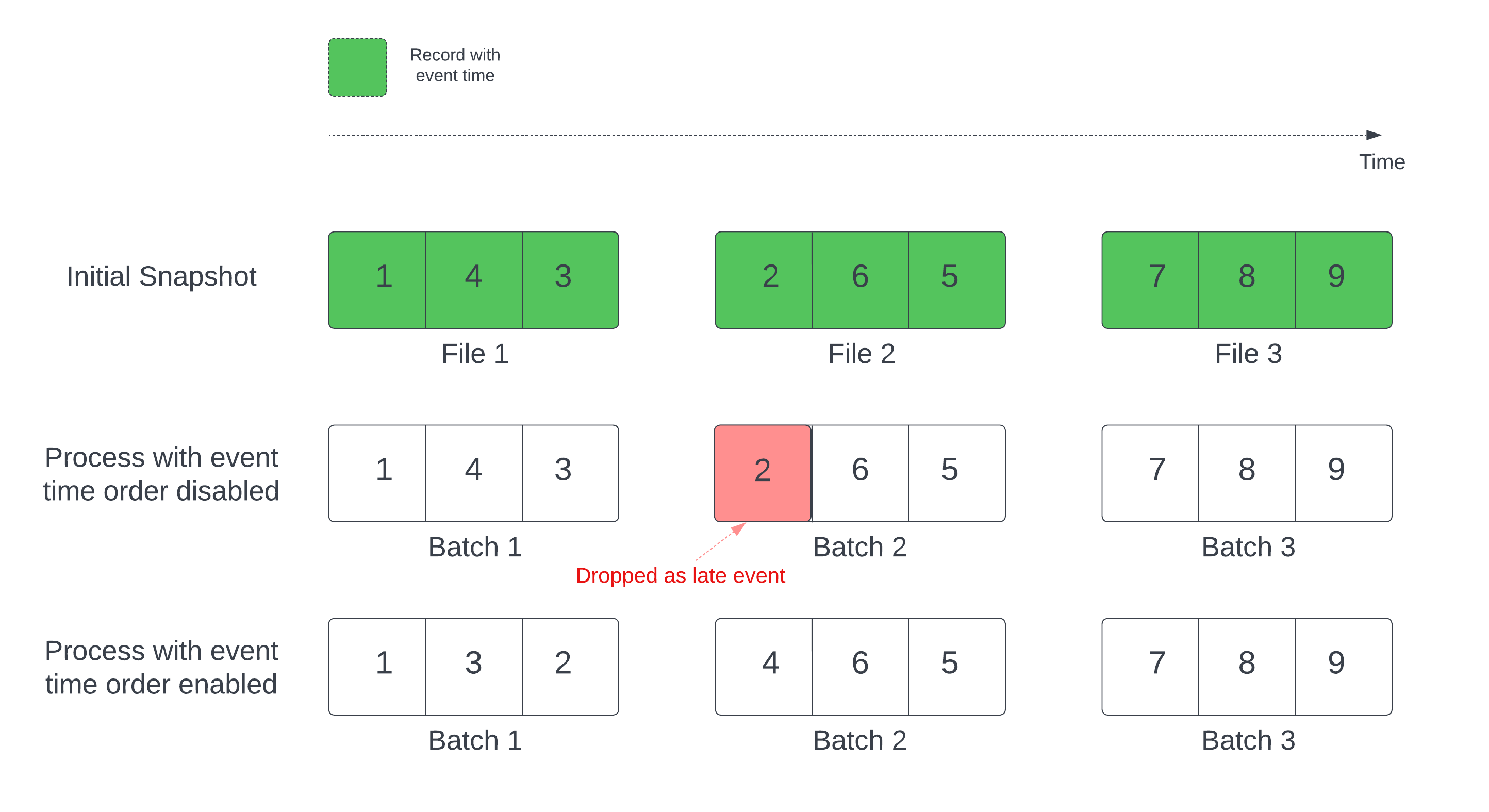
Información destacada sobre esta característica:
- El problema de anulación de datos solo se produce cuando la instantánea de Delta inicial de una consulta de streaming con estado se procesa en el orden predeterminado.
- No se puede cambiar
withEventTimeOrderuna vez que se ha iniciado la consulta de streaming mientras se sigue procesando la instantánea inicial. Para reiniciar conwithEventTimeOrdermodificado, tiene que eliminar el punto de control. - Si está ejecutando una consulta de streaming con conEventTimeOrder habilitado, no puede cambiarla a una versión anterior de DBR que no admita esta característica hasta que se complete el procesamiento de la instantánea inicial. Si tiene que cambiar a una versión anterior, puede esperar a que finalice la instantánea inicial, o bien eliminar el punto de control y reiniciar la consulta.
- Esta característica no se admite en los siguientes escenarios poco frecuentes:
- La columna de hora del evento es una columna generada y hay transformaciones que no son de proyección entre el origen de Delta y la marca de agua.
- Hay una marca de agua que tiene más de un origen de Delta en la consulta de streaming.
- Con el orden de la hora de los eventos habilitado, el rendimiento del procesamiento de la instantánea inicial de Delta podría ser más lento.
- Cada microlote examina la instantánea inicial para filtrar los datos dentro del intervalo de tiempo del evento correspondiente. Para una acción de filtrado más rápida, se recomienda usar una columna de origen de Delta como hora del evento para que se puedan aplicar la omisión de datos (compruebe Omisión de datos para Delta Lake para saber cuándo debe aplicarse). Además, la creación de particiones de tabla, junto con la columna de hora de evento, puede acelerar aún más el procesamiento. Puede comprobar la interfaz de usuario de Spark para ver cuántos archivos delta se examinan para un microlote específico.
Ejemplo
Supongamos que tiene una tabla user_events con una columna event_time. La consulta de streaming es una consulta de agregación. Si quiere asegurarse de que no se anulen datos durante el procesamiento de la instantánea inicial, puede usar:
spark.readStream.format("delta")
.option("withEventTimeOrder", "true")
.load("/tmp/delta/user_events")
.withWatermark("event_time", "10 seconds")
Nota:
También puede habilitar esto con la configuración de Spark en el clúster, que se aplicará a todas las consultas de streaming: spark.databricks.delta.withEventTimeOrder.enabled true.
Tabla Delta como receptor
También puede escribir datos en una tabla Delta mediante Structured Streaming de Spark. El registro de transacciones de Delta Lake garantiza un procesamiento exactamente una vez, incluso cuando haya otras secuencias o consultas por lotes que se ejecutan simultáneamente en la tabla.
Nota:
La función VACUUMde Delta Lake quita todos los archivos no administrados por Delta Lake, pero omite los directorios que comienzan por _. Puede almacenar de forma segura puntos de control junto con otros datos y metadatos de una tabla Delta mediante una estructura de directorios como <table-name>/_checkpoints.
Métricas
Puede averiguar el número de bytes y el número de archivos que aún deben procesarse en un proceso de consulta de streaming como las métricas numBytesOutstandingy numFilesOutstanding. Entre las métricas adicionales se incluyen:
numNewListedFiles: número de archivos de Delta Lake enumerados para calcular el trabajo pendiente de este lote.backlogEndOffset: la versión de la tabla utilizada para calcular el trabajo pendiente.
Si ejecuta el flujo en un cuaderno, puede ver estas métricas en la pestaña Datos sin procesar en el panel de progreso de la consulta de transmisión:
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
Modo de anexión
De forma predeterminada, las secuencias se ejecutan en modo Anexar, que agrega nuevos registros a la tabla.
Puede usar el método de ruta:
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/_checkpoints/")
.start("/delta/events")
)
Scala
events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.start("/tmp/delta/events")
o el método toTable, como se indica a continuación:
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Modo completo
También puede usar Structured Streaming para reemplazar toda la tabla por cada lote. Un ejemplo de caso de uso es calcular un resumen mediante agregación:
Python
(spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
)
Scala
spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
En el ejemplo anterior se actualiza continuamente una tabla que contiene el número agregado de eventos por cliente.
En el caso de las aplicaciones con requisitos de latencia más sensibles, puede ahorrar recursos informáticos con desencadenadores de un solo uso. Use estos para actualizar las tablas de agregación de resumen según una programación determinada, procesando solo los datos nuevos que han llegado desde la última actualización.
Realización de combinaciones de secuencia estática
Puede confiar en las garantías transaccionales y el protocolo de control de versiones de Delta Lake para realizar combinaciones de secuencia estática. Una combinación de secuencia estática combina la versión válida más reciente de una tabla Delta (los datos estáticos) a una secuencia de datos mediante una combinación sin estado.
Cuando Azure Databricks procesa un microlote de datos en una combinación de secuencia estática, la versión válida más reciente de los datos de la tabla delta estática se une con los registros presentes en el microproceso actual. Dado que la combinación no tiene estado, no es necesario configurar la marca de agua y puede procesar los resultados con baja latencia. Los datos de la tabla delta estática usada en la combinación deben cambiar lentamente.
streamingDF = spark.readStream.table("orders")
staticDF = spark.read.table("customers")
query = (streamingDF
.join(staticDF, streamingDF.customer_id==staticDF.id, "inner")
.writeStream
.option("checkpointLocation", checkpoint_path)
.table("orders_with_customer_info")
)
Actualización de consultas de streaming mediante foreachBatch
Puede usar una combinación de merge y foreachBatch para escribir operaciones upsert complejas de una consulta de streaming en una tabla Delta. Consulte Uso de foreachBatch para escribir en receptores de datos arbitrarios.
Este patrón tiene muchas aplicaciones, como las siguientes:
- Escritura de agregados de streaming en modo de actualización: es mucho más eficaz que el modo completo.
- Escritura de un flujo de cambios de la base de datos en una tabla Delta: la consulta de fusión mediante combinación para escribir datos modificados se puede usar en
foreachBatchpara aplicar continuamente un flujo de cambios a una tabla Delta. - Escritura de datos de flujo en una tabla Delta con desduplicación: la consulta de fusión mediante combinación de solo inserción para la desduplicación se puede usar en
foreachBatchpara escribir continuamente datos (con duplicados) en una tabla Delta con desduplicación automática.
Nota:
- Asegúrese de que la instrucción
mergedentro deforeachBatches idempotente, ya que los reinicios de la consulta de streaming pueden aplicar la operación en el mismo lote de datos varias veces. - Cuando
mergese usa enforeachBatch, puede que la velocidad de datos de entrada de la consulta de streaming (notificada medianteStreamingQueryProgressy visible en el gráfico de velocidad del cuaderno) se notifique como un múltiplo de la velocidad real a la que se generan los datos en origen. Esto se debe a quemergelee los datos de entrada varias veces, lo que hace que se multipliquen las métricas de entrada. Si se trata de un cuello de botella, puede almacenar en caché el dataframe por lotes antes demergey, después, sacarlo de la caché después demerge.
En el ejemplo siguiente se muestra cómo puede usar SQL dentro de foreachBatch para realizar esta tarea:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
También puede optar por usar las API de Delta Lake para realizar la transmisión de upserts, como en el ejemplo siguiente:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Escrituras de tabla idempotente en foreachBatch
Nota:
Databricks recomienda configurar una escritura de streaming independiente para cada receptor que quiera actualizar. El uso de foreachBatch para escribir en varias tablas serializa las escrituras, lo que reduce la paralelización y aumenta la latencia global.
Las tablas Delta son compatibles con las siguientes opciones de DataFrameWriter para hacer que las escrituras en varias tablas dentro de foreachBatch sean idempotentes:
txnAppId: cadena única que puede pasarse en cada escritura de DataFrame. Por ejemplo, puede usar el identificador de StreamingQuery comotxnAppId.txnVersion: número que aumenta de forma monótona y que actúa como versión de transacción.
Delta Lake usa la combinación de txnAppId y txnVersion para identificar escrituras duplicadas y omitirlas.
Si la escritura de un lote se interrumpe con un fallo, la reejecución del lote usa la misma aplicación e id. de lote para ayudar al runtime a identificar correctamente las escrituras duplicadas e ignorarlas. El identificador de aplicación (txnAppId) puede ser cualquier cadena única generada por el usuario y no tiene que estar relacionado con el identificador de flujo. Consulte Uso de foreachBatch para escribir en receptores de datos arbitrarios.
Advertencia
Si elimina el punto de control de streaming y reinicia la consulta con un nuevo punto de control, debe proporcionar otro txnAppId. Los nuevos puntos de control comienzan con un identificador de lote de 0. Delta Lake usa el identificador de lote y txnAppId como una clave única y omite los lotes con valores ya vistos.
En el ejemplo de código siguiente se muestra este patrón:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}