Tipos de visualización
En este artículo se describen los tipos de visualizaciones disponibles para su uso en cuadernos de Azure Databricks y en Databricks SQL, y se muestra cómo crear un ejemplo de cada tipo de visualización.
Gráfico de barras
Las visualizaciones de gráfico de barras representan el cambio en las métricas a lo largo del tiempo o muestran proporciones, de forma similar a un gráfico circular.
Nota:
Los gráficos de barras admiten agregaciones de back-end, lo que proporciona compatibilidad con consultas que devuelven más de 64 000 filas de datos sin truncar el conjunto de resultados.
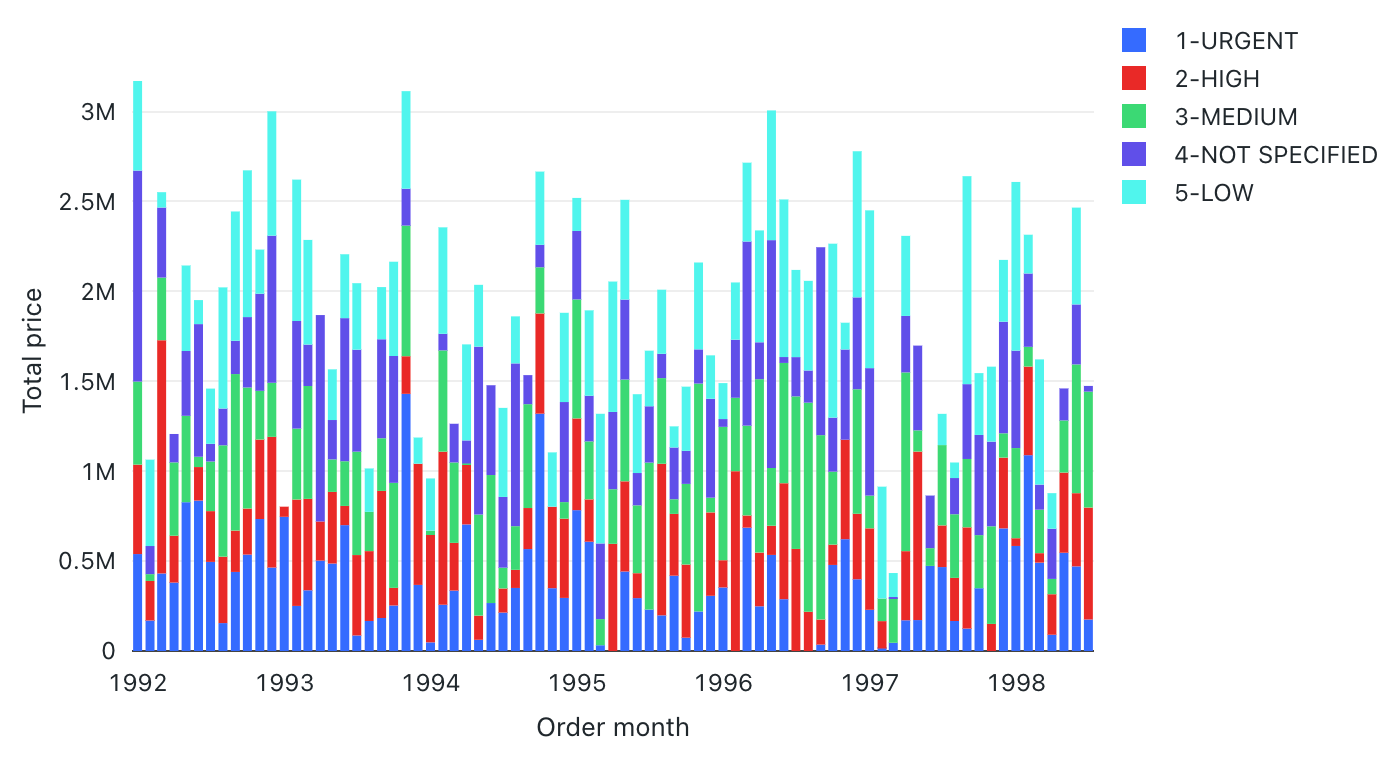
Valores de configuración: para esta visualización del gráfico de barras, se establecieron los siguientes valores:
- Columna X:
- Columna del conjunto de datos:
o_orderdate - Nivel de fecha:
Months
- Columna del conjunto de datos:
- Columnas Y:
- Columna del conjunto de datos:
o_totalprice - Tipo de agregación:
Sum
- Columna del conjunto de datos:
- Agrupar por (columna del conjunto de datos):
o_orderpriority - Apilamiento:
Stack - Nombre del eje X (invalidar el valor predeterminado):
Order month - Nombre del eje Y (invalidar el valor predeterminado):
Total price
Opciones de configuración: para ver las opciones de configuración del gráfico de barras, consulte opciones de configuración de gráficos.
Consulta SQL: para esta visualización de gráfico de barras, se generó el conjunto de datos con la siguiente consulta SQL.
select * from samples.tpch.orders
Gráfico de líneas
Los gráficos de líneas presentan el cambio en una o varias métricas a lo largo del tiempo.
Nota:
Los gráficos de líneas admiten agregaciones de back-end, lo que proporciona compatibilidad con consultas que devuelven más de 64 000 filas de datos sin truncar el conjunto de resultados.
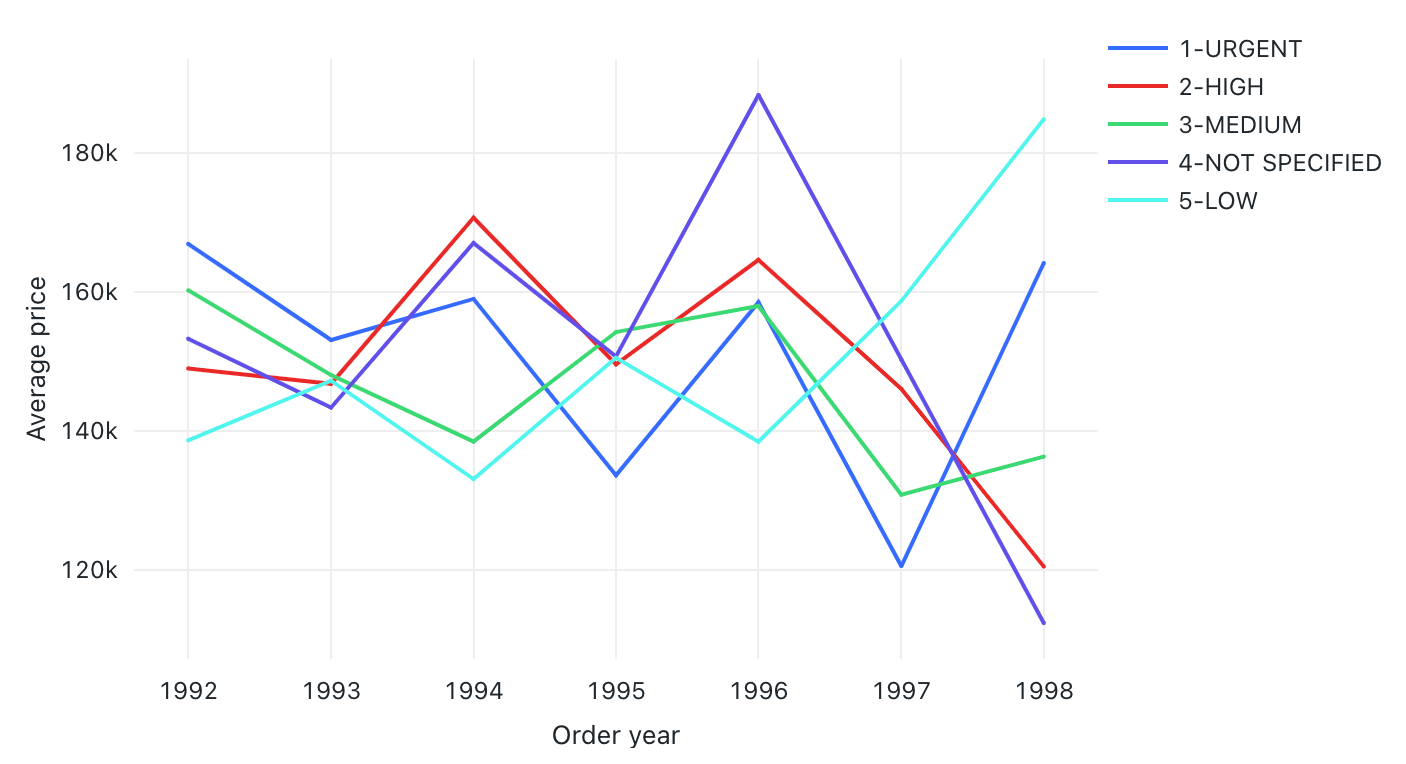
Valores de configuración: para esta visualización del gráfico de líneas, se establecieron los siguientes valores:
- Columna X:
- Columna del conjunto de datos:
o_orderdate - Nivel de fecha:
Years
- Columna del conjunto de datos:
- Columnas Y:
- Columna del conjunto de datos:
o_totalprice - Tipo de agregación:
Average
- Columna del conjunto de datos:
- Agrupar por (columna del conjunto de datos):
o_orderpriority - Nombre del eje X (invalidar el valor predeterminado):
Order year - Nombre del eje Y (invalidar el valor predeterminado):
Average price
Opciones de configuración: para ver las opciones de configuración del gráfico de líneas, consulte opciones de configuración de gráficos.
Consulta SQL: para esta visualización de gráfico de líneas, se generó el conjunto de datos con la siguiente consulta SQL.
select * from samples.tpch.orders
Gráfico de áreas
El gráfico de áreas combina el gráfico de líneas y barras para mostrar cómo cambian los valores numéricos de uno o varios grupos con respecto a la progresión de una segunda variable, normalmente la del tiempo. A menudo se usan para mostrar los cambios de embudo de ventas a lo largo del tiempo.
Nota:
Los gráficos de áreas admiten agregaciones de back-end, lo que proporciona compatibilidad con consultas que devuelven más de 64 000 filas de datos sin truncar el conjunto de resultados.
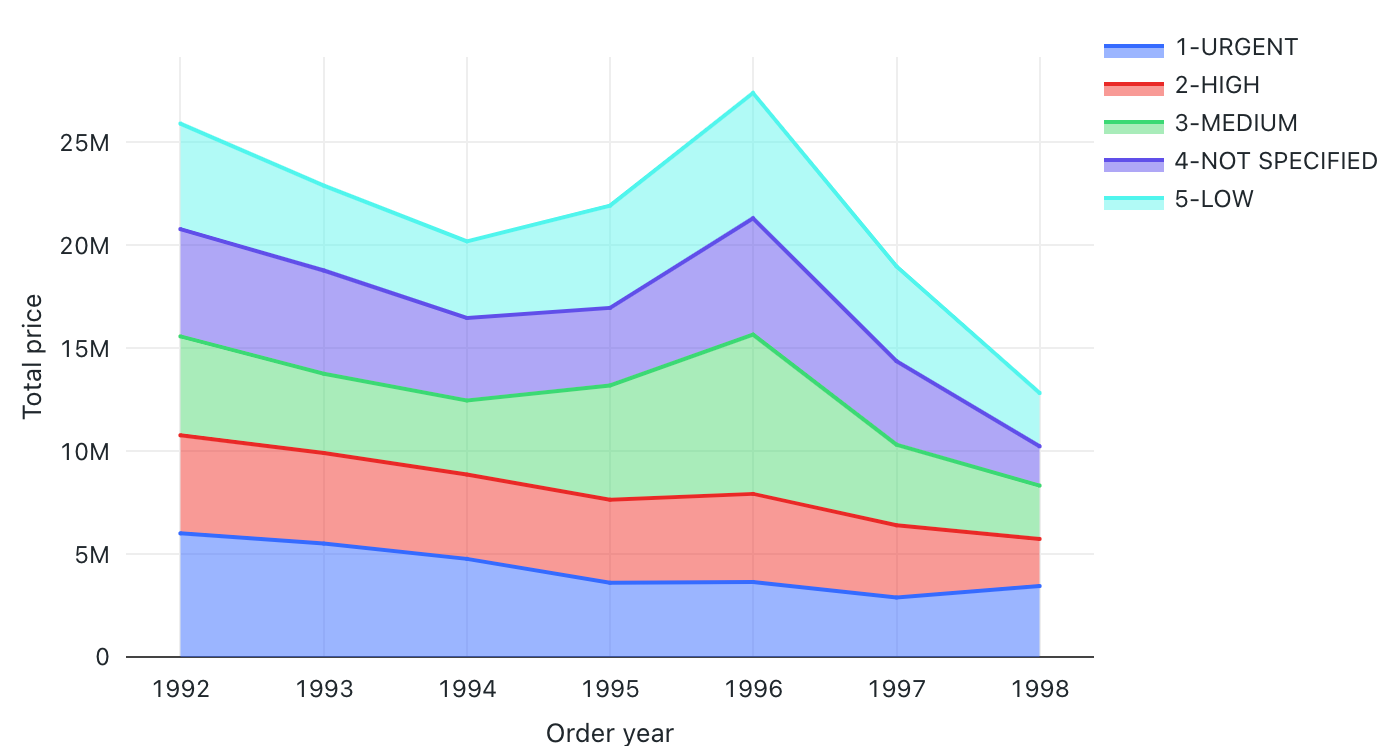
Valores de configuración: para esta visualización del gráfico de áreas, se establecieron los siguientes valores:
- Columna X:
- Columna del conjunto de datos:
o_orderdate - Nivel de fecha:
Years
- Columna del conjunto de datos:
- Columnas Y:
- Columna del conjunto de datos:
o_totalprice - Tipo de agregación:
Sum
- Columna del conjunto de datos:
- Agrupar por (columna del conjunto de datos):
o_orderpriority - Apilamiento:
Stack - Nombre del eje X (invalidar el valor predeterminado):
Order year - Nombre del eje Y (invalidar el valor predeterminado):
Total price
Opciones de configuración: para ver las opciones de configuración del gráfico de áreas, consulte opciones de configuración de gráficos.
Consulta SQL: para esta visualización del gráfico de áreas, se generó el conjunto de datos con la siguiente consulta SQL.
select * from samples.tpch.orders
Gráficos circulares
El gráfico circular muestra proporcionalidad entre métricas. No están diseñados para transmitir datos de serie temporal.
Nota:
Los gráficos circulares admiten agregaciones de back-end, lo que proporciona compatibilidad con consultas que devuelven más de 64 000 filas de datos sin truncar el conjunto de resultados.
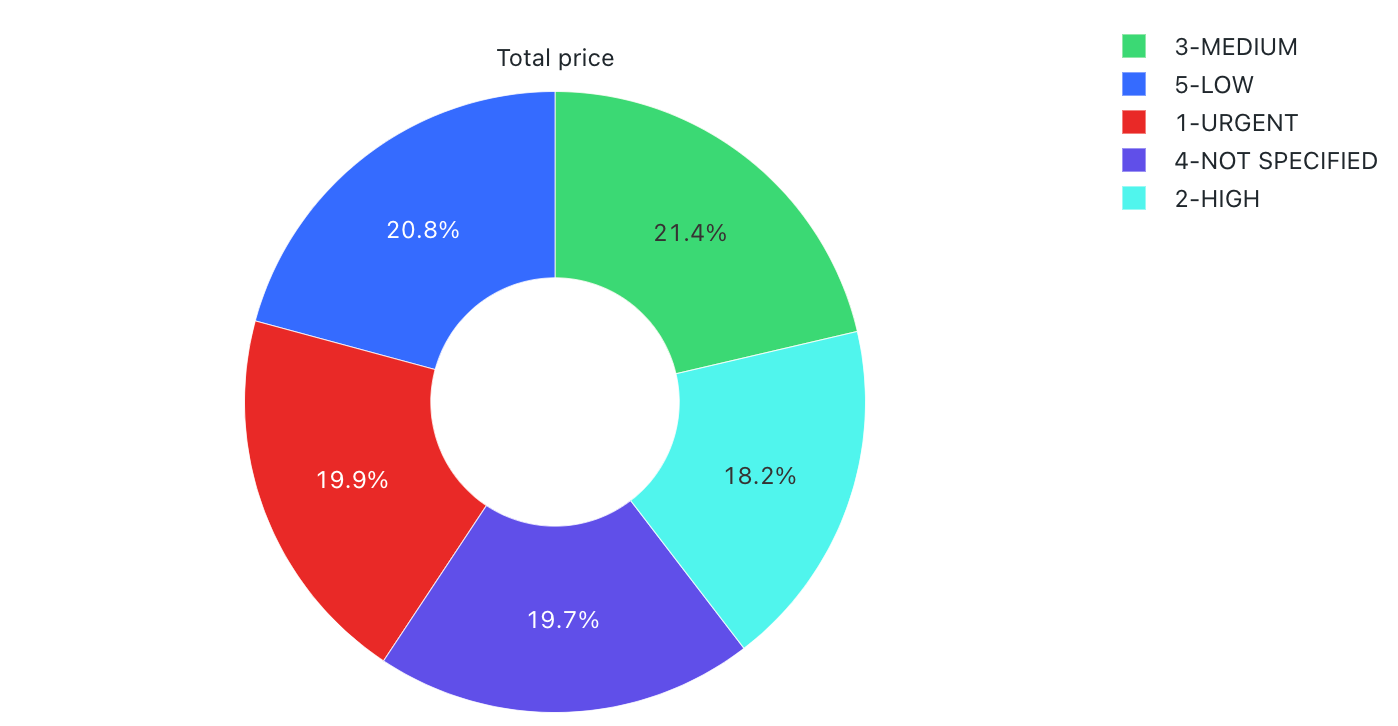
Valores de configuración: para esta visualización del gráfico circular, se establecieron los siguientes valores:
- Columna X (columna del conjunto de datos):
o_orderpriority - Columnas Y:
- Columna del conjunto de datos:
o_totalprice - Tipo de agregación:
Sum
- Columna del conjunto de datos:
- Etiqueta (invalidar el valor predeterminado):
Total price
Opciones de configuración: para ver las opciones de configuración del gráfico circular, consulte opciones de configuración de gráficos.
Consulta SQL: para esta visualización de gráfico circular, se generó el conjunto de datos con la siguiente consulta SQL.
select * from samples.tpch.orders
Histogramas
Un histograma traza la frecuencia con la que se produce un valor determinado en un conjunto de datos. Un histograma le ayuda a comprender si un conjunto de datos tiene valores que se agrupan en torno a un pequeño número de intervalos o están más distribuidos. Un histograma se muestra como un gráfico de barras en el que se controla el número de barras distintas (también denominadas rangos).
Nota:
Los histogramas admiten agregaciones de back-end, lo que proporciona compatibilidad con consultas que devuelven más de 64 000 filas de datos sin truncar el conjunto de resultados.
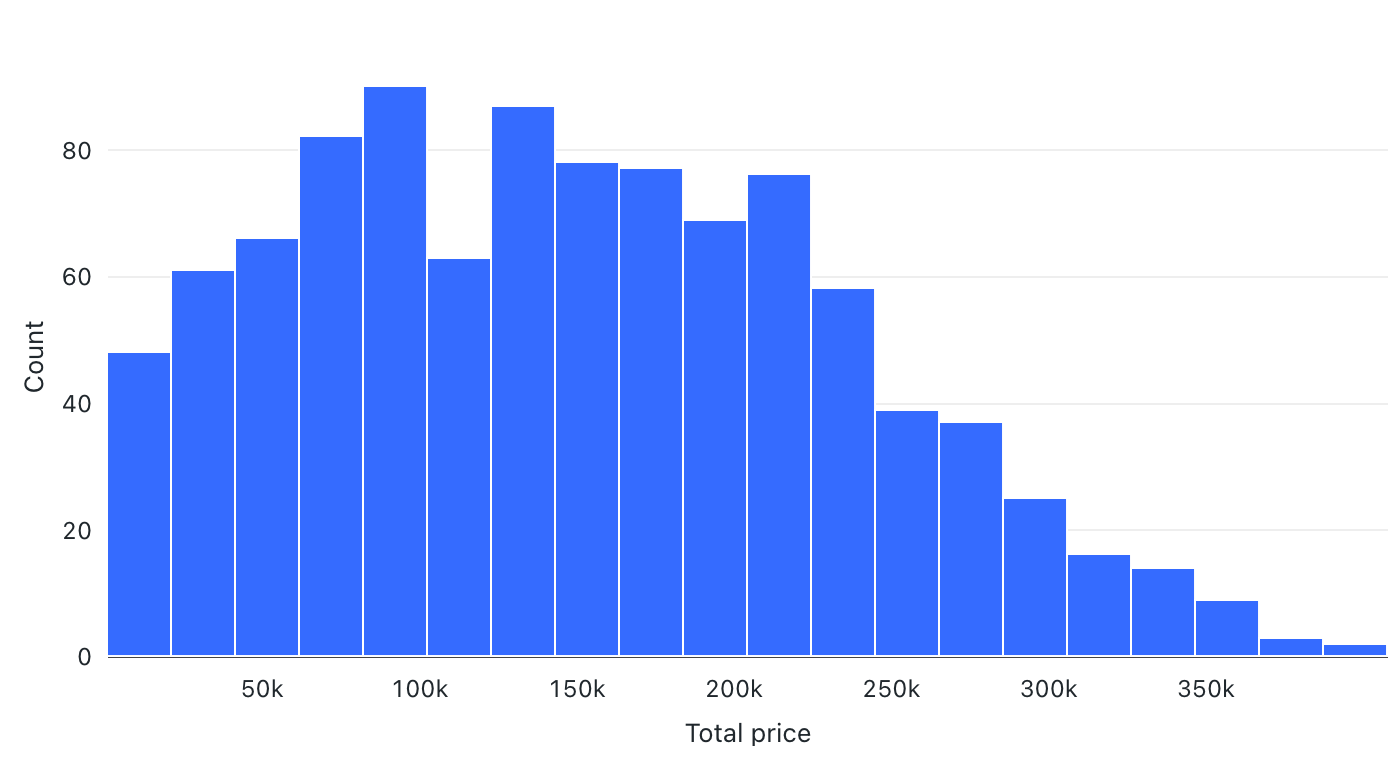
Valores de configuración: para esta visualización del histograma, se establecieron los siguientes valores:
- Columna X (columna del conjunto de datos):
o_totalprice - Número de cubos: 20
- Nombre del eje X (invalidar el valor predeterminado):
Total price
Opciones de configuración: para ver las opciones de configuración del histograma, consulte opciones de configuración de gráficos.
Consulta SQL: para esta visualización de histograma, se generó el conjunto de datos con la siguiente consulta SQL.
select * from samples.tpch.orders
Mapas térmicos
Los mapas térmicos combinan características de gráficos de barras, apilamiento y gráficos de burbujas, lo que le permite visualizar datos numéricos mediante colores. Una paleta de colores común para un mapa térmico muestra los valores más altos mediante colores cálidos, como naranja o rojo, y los valores más bajos con colores fríos, como azul o púrpura.
Por ejemplo, considere el siguiente mapa térmico que visualiza las distancias de carreras de taxi que se producen con más frecuencia a diario y agrupa los resultados por el día de la semana, la distancia y la tarifa total.
Nota:
Los mapas térmicos admiten agregaciones de back-end, lo que proporciona compatibilidad con consultas que devuelven más de 64 000 filas de datos sin truncar el conjunto de resultados.
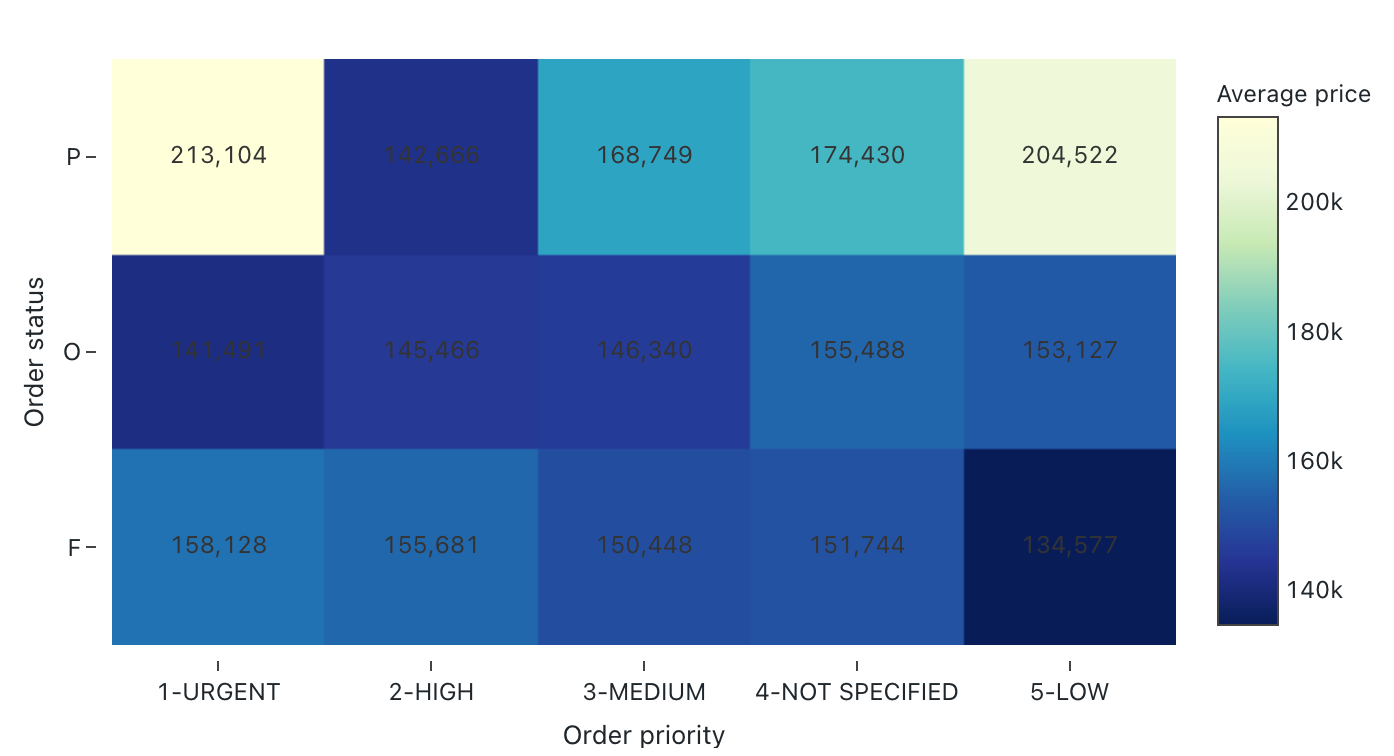
Valores de configuración: para esta visualización de los mapas térmicos, se establecieron los siguientes valores:
- Columna X (columna del conjunto de datos):
o_orderpriority - Columnas Y (columna del conjunto de datos):
o_orderstatus - Columna de color:
- Columna del conjunto de datos:
o_totalprice - Tipo de agregación:
Average
- Columna del conjunto de datos:
- Nombre del eje X (invalidar el valor predeterminado):
Order priority - Nombre del eje Y (invalidar el valor predeterminado):
Order status - Combinación de colores (invalidar el valor predeterminado):
YIGnBu
Opciones de configuración: para ver las opciones de configuración del mapa térmico, consulte opciones de configuración de mapas térmicos.
Consulta SQL: para esta visualización de mapa térmico, se generó el conjunto de datos con la siguiente consulta SQL.
select * from samples.tpch.orders
Gráfico de dispersión
Las visualizaciones de dispersión se usan normalmente para mostrar la relación entre dos variables numéricas. Además, se puede codificar una tercera dimensión con colores para mostrar cómo las variables numéricas son diferentes entre grupos.
Nota:
Los gráficos de dispersión admiten agregaciones de back-end, lo que proporciona compatibilidad con consultas que devuelven más de 64 000 filas de datos sin truncar el conjunto de resultados.
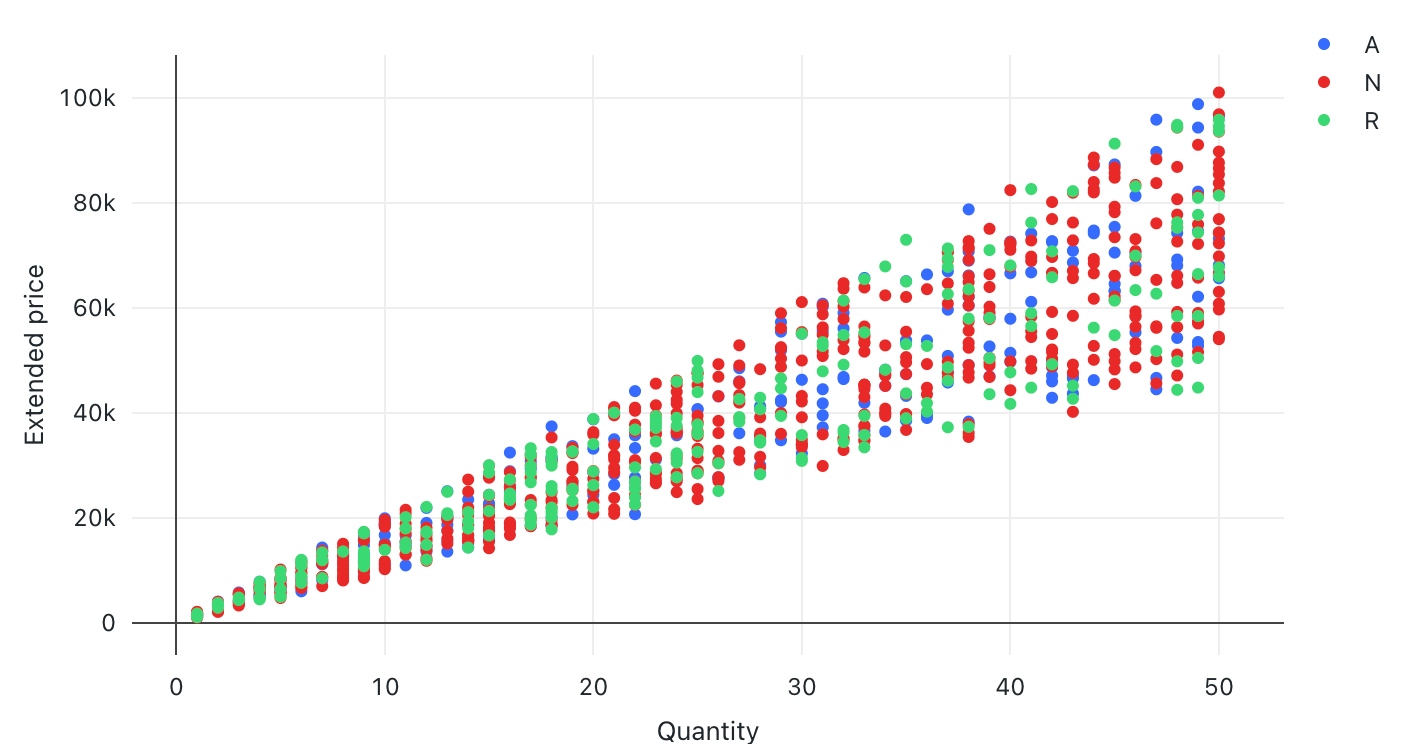
Valores de configuración: para esta visualización del gráfico de dispersión, se establecieron los siguientes valores:
- Columna X (columna del conjunto de datos):
l_quantity - Columna Y (columna del conjunto de datos):
l_extendedprice - Agrupar por (columna del conjunto de datos):
l_returnflag - Nombre del eje X (invalidar el valor predeterminado):
Quantity - Nombre del eje Y (invalidar el valor predeterminado):
Extended price
Opciones de configuración: para ver las opciones de configuración del gráfico de dispersión, consulte opciones de configuración de gráficos.
Consulta SQL: para esta visualización de dispersión, se generó el conjunto de datos con la siguiente consulta SQL.
select * from samples.tpch.lineitem
Gráfico de burbujas
Los gráficos de burbujas son gráficos de dispersión donde el tamaño de cada marcador de punto refleja una métrica pertinente.
Nota:
Los gráficos de burbujas admiten agregaciones de back-end, lo que proporciona compatibilidad con consultas que devuelven más de 64 000 filas de datos sin truncar el conjunto de resultados.
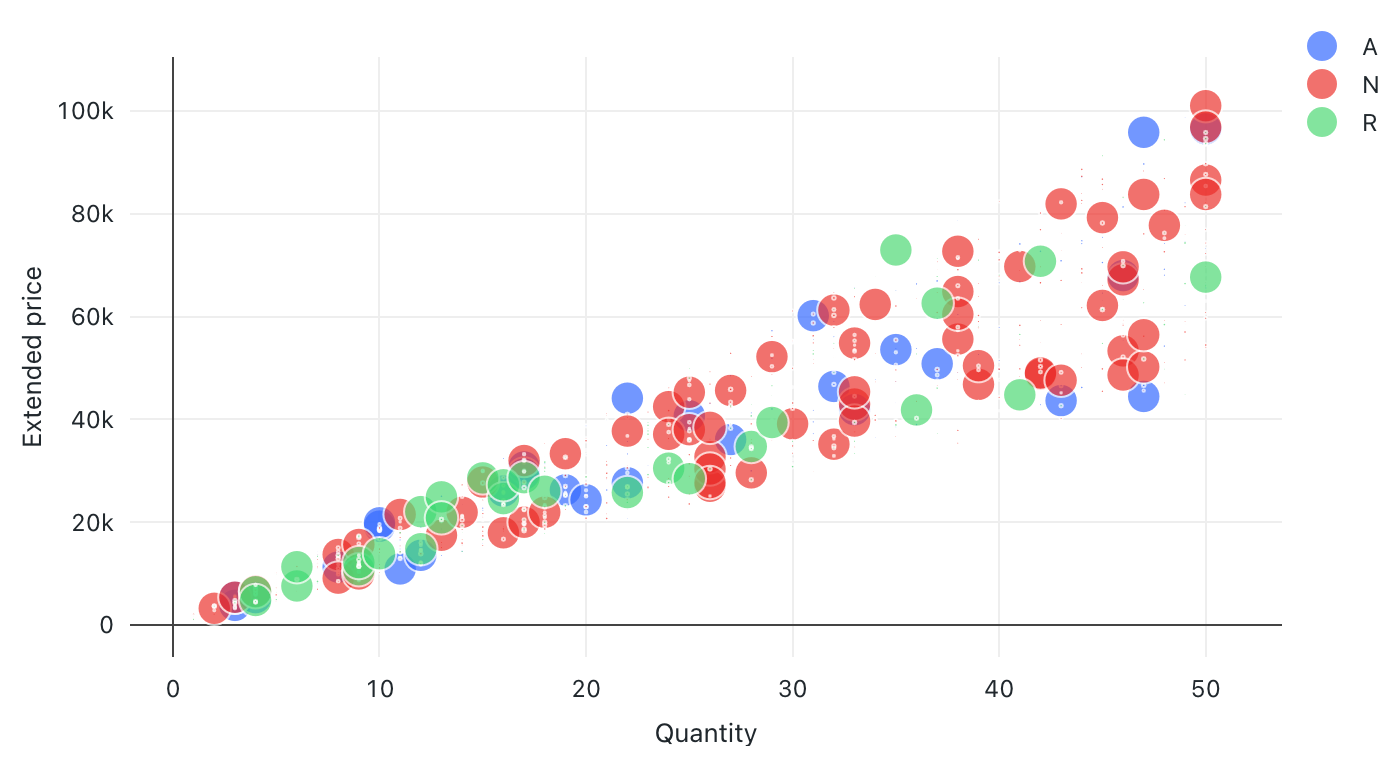
Valores de configuración: para esta visualización del gráfico de burbujas, se establecieron los siguientes valores:
- X (columna del conjunto de datos):
l_quantity - Columnas Y (columna del conjunto de datos):
l_extendedprice - Agrupar por (columna del conjunto de datos):
l-returnflag - Columna tamaño de la burbuja (columna del conjunto de datos):
l_tax - Coeficiente del tamaño de la burbuja: 20
- Nombre del eje X (invalidar el valor predeterminado):
Quantity - Nombre del eje Y (invalidar el valor predeterminado):
Extended price
Opciones de configuración: para ver las opciones de configuración del gráfico de burbujas, consulte opciones de configuración de gráficos.
Consulta SQL: para esta visualización de gráfico de burbujas, se generó el conjunto de datos con la siguiente consulta SQL.
select * from samples.tpch.lineitem
Diagrama de cajas
En la visualización de diagrama de cajas se muestra el resumen de distribución de datos numéricos, agrupados opcionalmente por categoría. Con una visualización de diagrama de cajas, puede comparar rápidamente los intervalos de valores entre categorías y visualizar los grupos de localidad, dispersión y asimetría de los valores a través de sus cuartiles. En cada caja, la línea más oscura muestra el intervalo intercuartil. Para obtener más información sobre cómo interpretar visualizaciones de diagrama de cajas, consulte el artículo Diagrama de cajas en Wikipedia.
Nota:
Los diagramas de cajas solo admiten la agregación de hasta 64 000 filas. Si un conjunto de datos es mayor que 64 000 filas, los datos se truncarán.
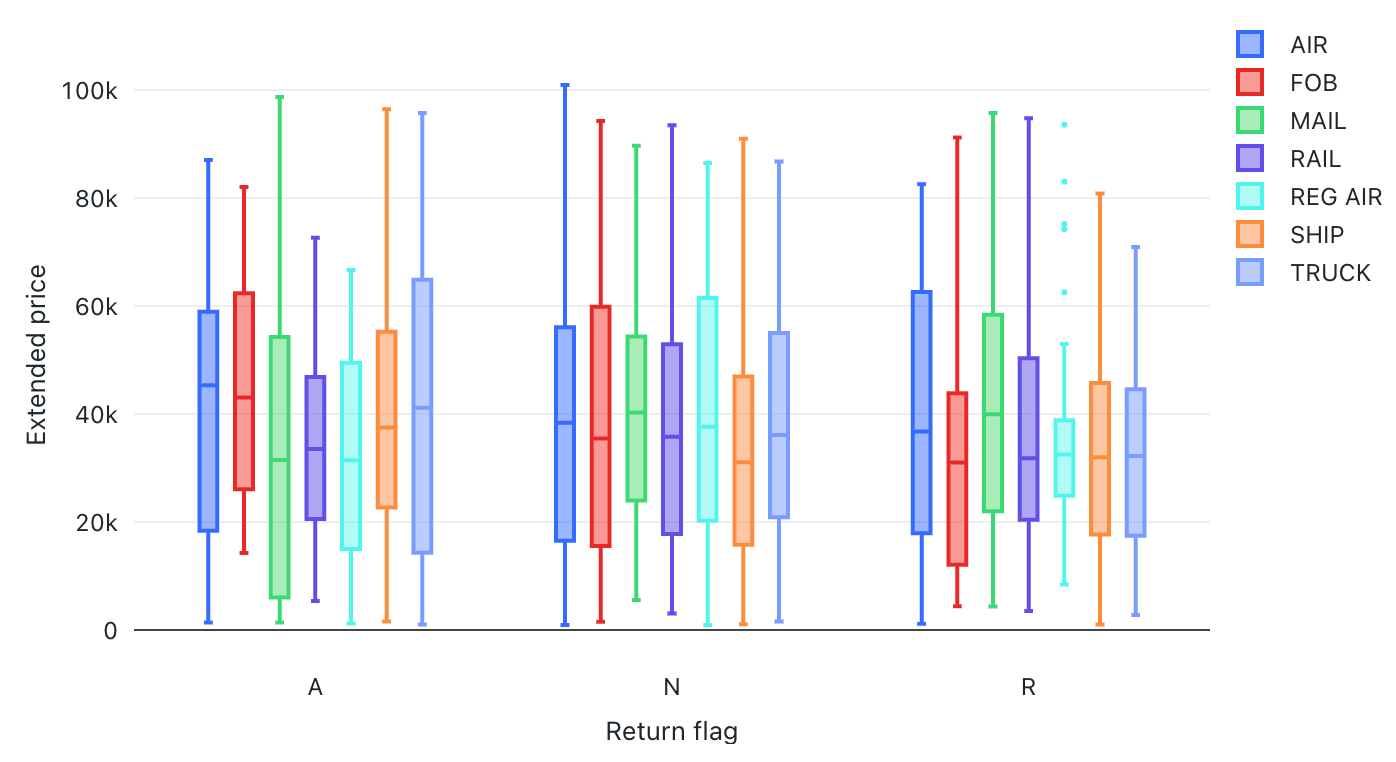
Valores de configuración: para esta visualización del diagrama de cajas, se establecieron los siguientes valores:
- Columna X (columna del conjunto de datos):
l-returnflag - Columnas Y (columna del conjunto de datos):
l_extendedprice - Agrupar por (columna del conjunto de datos):
l_shipmode - Nombre del eje X (invalidar el valor predeterminado):
Return flag1 - Nombre del eje Y (invalidar el valor predeterminado):
Extended price
Opciones de configuración: para ver las opciones de configuración del diagrama de cajas, consulte Opciones de configuración de diagrama de cajas.
Consulta SQL: para esta visualización de diagrama de cajas, se generó el conjunto de datos con la siguiente consulta SQL.
select * from samples.tpch.lineitem
Gráfico combinado
El gráfico combinado usa al mismo tiempo gráficos de líneas y barras para presentar cambios a lo largo del tiempo con proporcionalidad.
Nota:
Los gráficos combinados admiten agregaciones de back-end, lo que proporciona compatibilidad con consultas que devuelven más de 64 000 filas de datos sin truncar el conjunto de resultados.

Valores de configuración: para esta visualización de gráfico combinado, se establecieron los siguientes valores:
- Columna X (columna del conjunto de datos):
l_shipdate - Columnas Y:
- Primera columna del conjunto de datos:
l_extendedprice - Tipo de agregación: promedio
- Segunda columna de conjunto de datos:
l_quantity - Tipo de agregación: promedio
- Primera columna del conjunto de datos:
- Nombre del eje X (invalidar el valor predeterminado):
Ship date - Nombre del eje Y izquierdo (invalidar el valor predeterminado):
Quantity - Nombre del eje Y derecho (invalidar el valor predeterminado):
Average price - Series:
- Order1 (columna de conjunto de datos):
AVG(l_extendedprice) - Eje Y: derecho
- Tipo: Línea
- Order2 (columna del conjunto de datos):
AVG(l_quantity) - Eje Y: izquierdo
- Tipo: barra
- Order1 (columna de conjunto de datos):
Opciones de configuración: para ver las opciones de configuración del gráfico combinado, consulte opciones de configuración de gráficos.
Consulta SQL: para esta visualización de gráfico combinado, se generó el conjunto de datos con la siguiente consulta SQL.
select * from samples.tpch.lineitem
Análisis de cohortes
En un análisis de cohortes se examinan los resultados de los grupos predeterminados, denominados cohortes, a medida que progresan por un conjunto de fases. La visualización de cohortes solo realiza agregaciones en base a las fechas (permite agregaciones mensuales). No realiza ninguna otra agregación de datos dentro del conjunto de resultados. Todas las demás agregaciones se realizan dentro de la propia consulta.
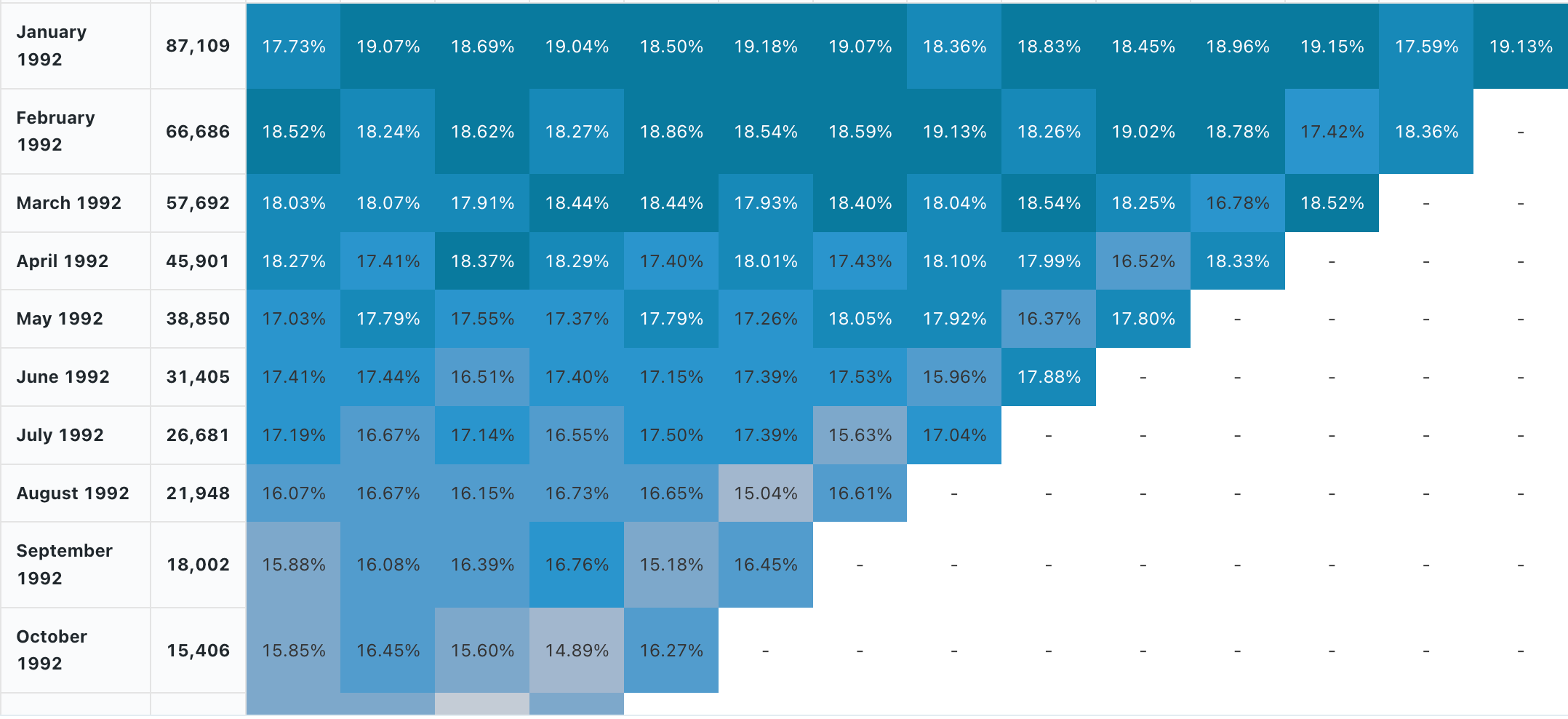
Valores de configuración: para esta visualización de gráfico de cohortes, se establecieron los siguientes valores:
- Fecha (cubo) (columna de base de datos):
cohort_month - Fase (columna de base de datos):
months - Tamaño de rellenado de cubos (columna de base de datos):
size - Valor de fase (columna de base de datos):
active - Intervalo de tiempo:
monthly
Opciones de configuración: para ver las opciones de configuración del gráfico de cohortes, consulte Opciones de configuración de gráfico de cohortes.
Consulta SQL: para esta visualización de gráfico de cohortes, se generó el conjunto de datos con la siguiente consulta SQL.
-- match each customer with its cohort by month
with cohort_dates as (
SELECT o_custkey, min(date_trunc('month', o_orderdate)) as cohort_month
FROM samples.tpch.orders
GROUP BY 1
),
-- find the size of each cohort
cohort_size as (
SELECT cohort_month, count(distinct o_custkey) as size
FROM cohort_dates
GROUP BY 1
)
-- for each cohort and month thereafter, find the number of active customers
SELECT
cohort_dates.cohort_month,
ceil(months_between(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month)) as months,
count(distinct samples.tpch.orders.o_custkey) as active,
first(size) as size
FROM samples.tpch.orders
left join cohort_dates on samples.tpch.orders.o_custkey = cohort_dates.o_custkey
left join cohort_size on cohort_dates.cohort_month = cohort_size.cohort_month
WHERE datediff(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month) != 0
GROUP BY 1, 2
ORDER BY 1, 2
Visualización de contador
Los contadores muestran un único valor destacado, con una opción para compararlo con un valor de referencia. Para usar contadores, especifique la fila de datos que se va a mostrar en la visualización del contador para la columna de valor y la columna de destino.
Nota:
Los contadores solo admiten la agregación de hasta 64 000 filas. Si un conjunto de datos es mayor que 64 000 filas, los datos se truncarán.
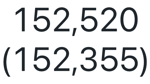
Valores de configuración: para este ejemplo de visualización de contador, se establecieron los siguientes valores:
- Columna de valor
- Columna del conjunto de datos:
avg(o_totalprice) - Fila 1:
- Columna del conjunto de datos:
- Columna de destino:
- Columna del conjunto de datos:
avg(o_totalprice) - Fila 2:
- Columna del conjunto de datos:
- Formato del valor de destino: Habilitar
Consulta SQL: para esta visualización de gráfico de contador, se generó el conjunto de datos con la siguiente consulta SQL.
select o_orderdate, avg(o_totalprice)
from samples.tpch.orders
GROUP BY 1
ORDER BY 1 DESC
Visualización de embudo
La visualización de embudo ayuda a analizar el cambio en una métrica en distintas fases. Para usar el gráfico de embudo, especifique columnas de step y value.
Nota:
Los gráficos de embudos solo admiten la agregación de hasta 64 000 filas. Si un conjunto de datos es mayor que 64 000 filas, los datos se truncarán.
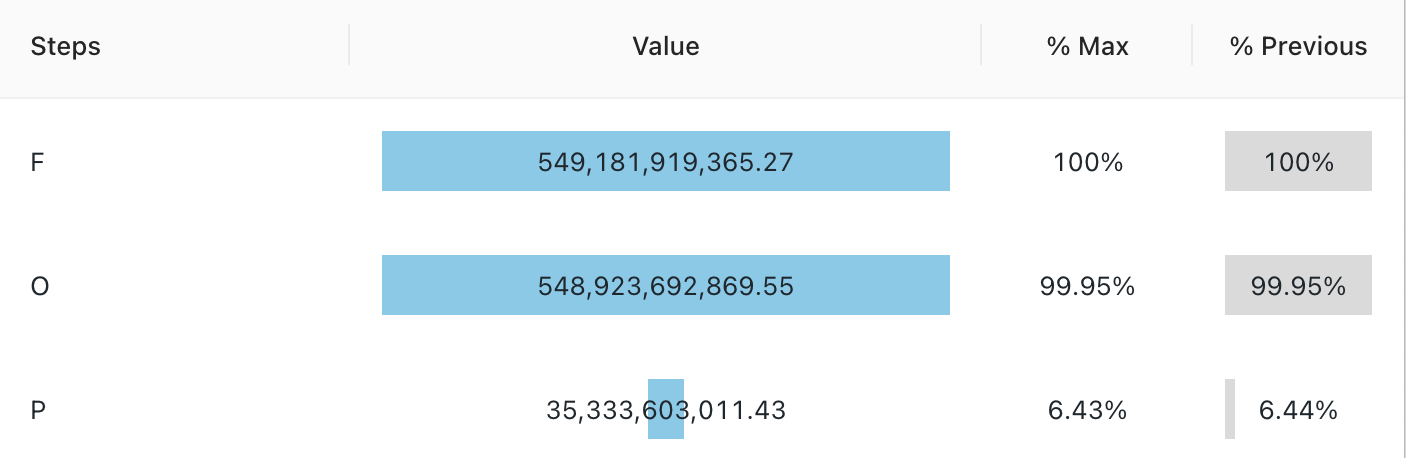
Valores de configuración: para esta visualización de gráfico de embudo, se establecieron los siguientes valores:
- Columna X (columna del conjunto de datos):
o_orderstatus - Columna de valor (columna del conjunto de datos):
Revenue
Consulta SQL: para esta visualización de gráfico de embudo, se generó el conjunto de datos con la siguiente consulta SQL.
SELECT o_orderstatus, sum(o_totalprice) as Revenue
FROM samples.tpch.orders
GROUP BY 1
Visualización de mapa coroplético
En las visualizaciones coropléticas, las localidades geográficas, como países o estados, se colorean según los valores agregados de cada columna de clave. La consulta debe devolver ubicaciones geográficas por nombre.
Nota:
Las visualizaciones coropléticas no realizan agregaciones de datos dentro del conjunto de resultados. Todas las agregaciones deben calcularse dentro de la propia consulta.
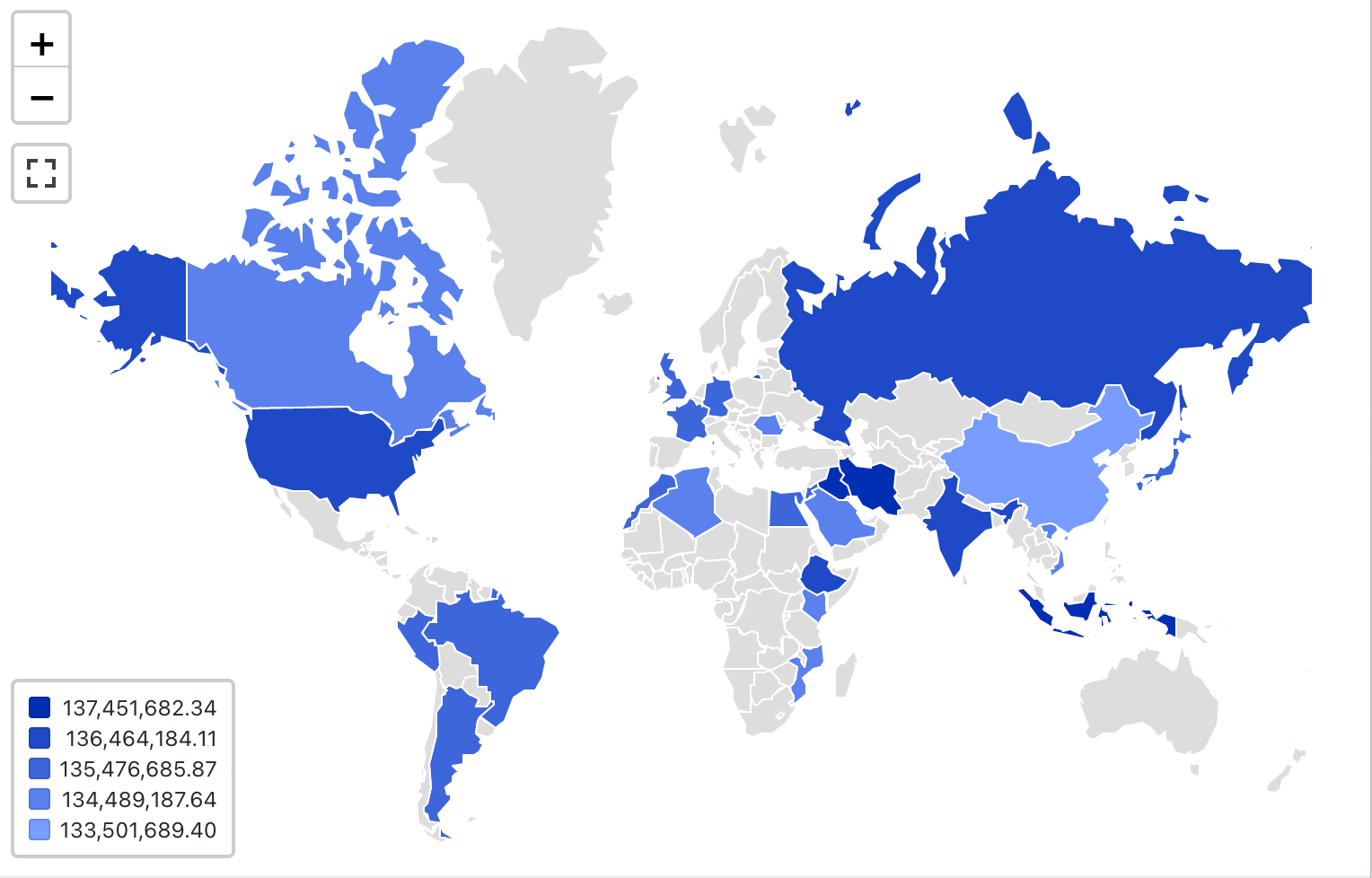
Valores de configuración: para este ejemplo de visualizaciones coropléticas, se establecieron los siguientes valores:
- Asignación (columna del conjunto de datos):
Countries - Columna geográfica (columna del conjunto de datos):
Nation - Tipo geográfico: nombre corto
- Columna de valor (columna del conjunto de datos):
revenue - Modo de agrupación en clústeres: equidistante
Opciones de configuración: para las opciones de configuración coropléticas, consulte opciones de configuración coropléticas.
Consulta SQL: para esta visualización coroplética, se usó la siguiente consulta SQL para generar el conjunto de datos.
SELECT
initcap(n_name) as Country,
sum(c_acctbal)
FROM samples.tpch.customer
join samples.tpch.nation where n_nationkey = c_nationkey
GROUP BY 1
Visualización de mapa de marcadores
En visualizaciones de marcadores se coloca un marcador en un conjunto de coordenadas del mapa. El resultado de la consulta debe devolver pares de latitud y longitud.
Nota:
El marcador no realiza ninguna otra agregación de datos dentro del conjunto de resultados. Todas las agregaciones deben calcularse dentro de la propia consulta.
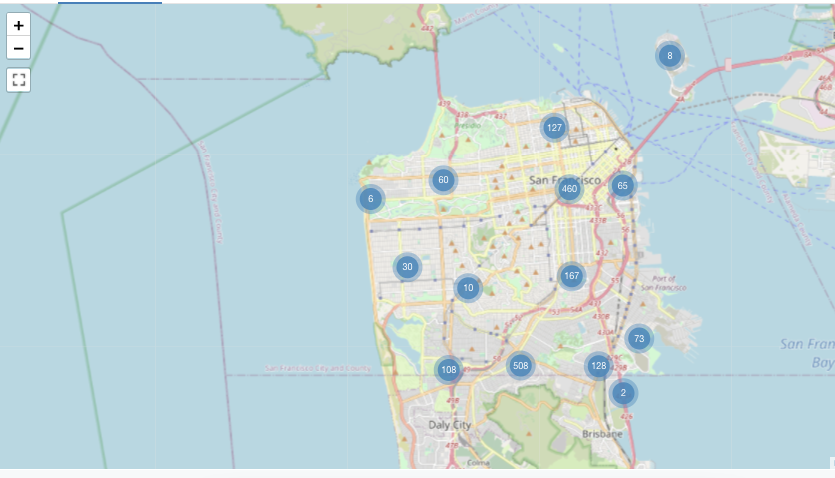
Este ejemplo de marcador se genera a partir de un conjunto de datos que incluye los valores de latitud y longitud, que no están disponibles en los conjuntos de datos de ejemplo de Databricks. Para conocer las opciones de configuración de marcadores, consulte opciones de configuración de marcadores.
Visualización de tabla dinámica
La visualización de tabla dinámica agrega registros de un resultado de consulta en una nueva presentación tabular. Es similar a las instrucciones PIVOT o GROUP BY de SQL. La visualización de tabla dinámica se configura con campos de arrastrar y colocar.
Nota:
Las tablas dinámicas admiten agregaciones de back-end, lo que proporciona compatibilidad con consultas que devuelven más de 64 000 filas de datos sin truncar el conjunto de resultados. Sin embargo, la tabla dinámica (heredada) solo admite la agregación para 64 000 filas como máximo. Si un conjunto de datos es mayor que 64 000 filas, los datos se truncarán.
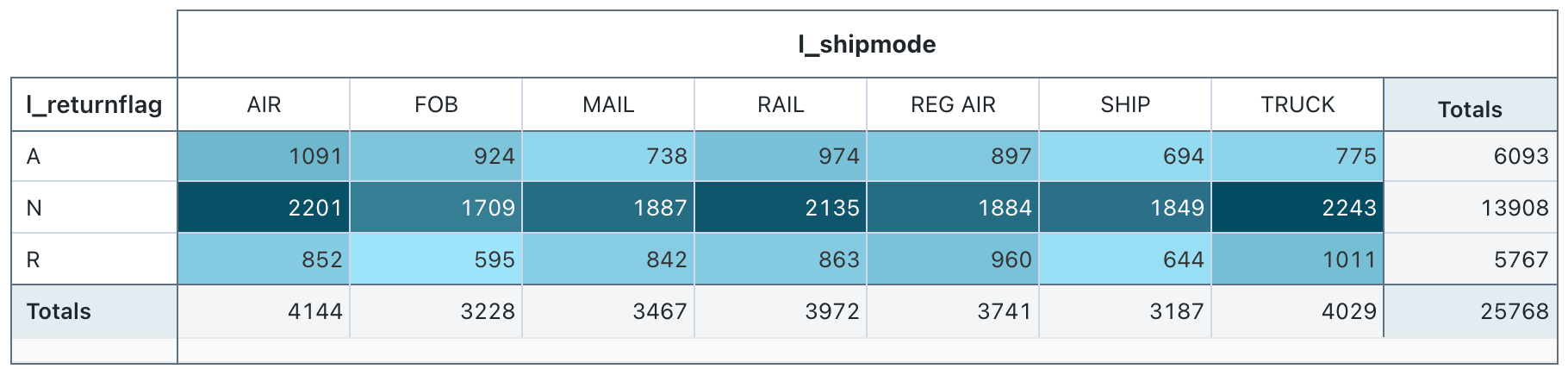{kind=link}
Valores de configuración: para este ejemplo de visualización de tabla, se establecieron los siguientes valores:
- Selección de filas (columna de conjunto de datos):
l_retkurnflag - Selección de columnas (columna de conjunto de datos):
l_shipmode - Cell
- Columna del conjunto de datos:
l_quantity - Tipo de agregación: Sum
- Columna del conjunto de datos:
Consulta SQL: para esta visualización de tabla dinámica, se usó la siguiente consulta SQL para generar el conjunto de datos.
select * from samples.tpch.lineitem
Sankey
Un diagrama sankey visualiza el flujo de un conjunto de valores a otro.
Nota:
Las visualizaciones sankey no realizan agregaciones de datos dentro del conjunto de resultados. Todas las agregaciones deben calcularse dentro de la propia consulta.

Consulta SQL: para esta visualización de gráfico sankey, se generó el conjunto de datos con la siguiente consulta SQL.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Secuencia de proyección solar
Un diagrama de proyección solar ayuda a visualizar datos jerárquicos mediante círculos concéntricos.
Nota:
La proyección solar no realiza ninguna otra agregación de datos dentro del conjunto de resultados. Todas las agregaciones deben calcularse dentro de la propia consulta.
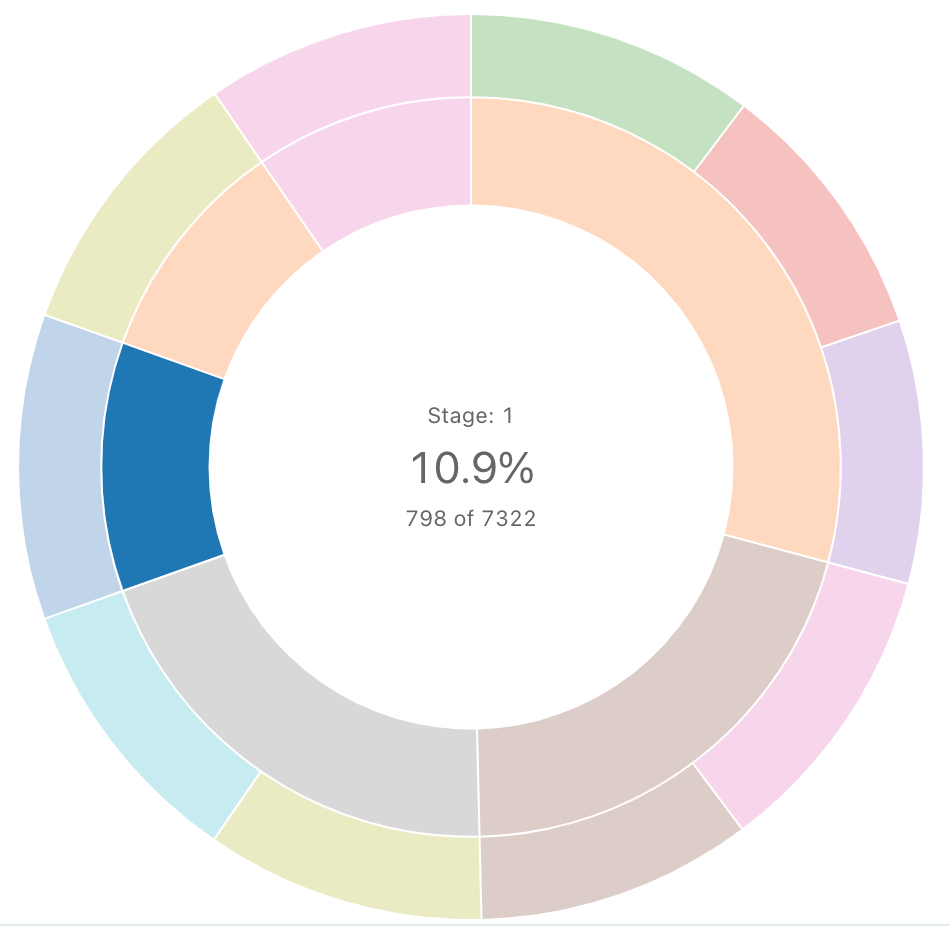
Consulta SQL: para esta visualización de proyección solar, se usó la siguiente consulta SQL para generar el conjunto de datos.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Tabla
La visualización de la tabla muestra los datos de una tabla estándar, pero con la capacidad de reordenar, ocultar y dar formato a los datos manualmente. Ver opciones de la tabla.
Nota:
Las visualizaciones de tabla no realizan agregaciones de datos dentro del conjunto de resultados. Todas las agregaciones deben calcularse dentro de la propia consulta.
Para conocer las opciones de configuración tabla, consulte opciones de configuración de tabla.
Nube de palabras
Una nube de palabras representa visualmente la frecuencia con la que se produce una palabra en los datos.
Nota:
Las nubes de palabras solo admiten la agregación de hasta 64 000 filas. Si un conjunto de datos es mayor que 64 000 filas, los datos se truncarán.
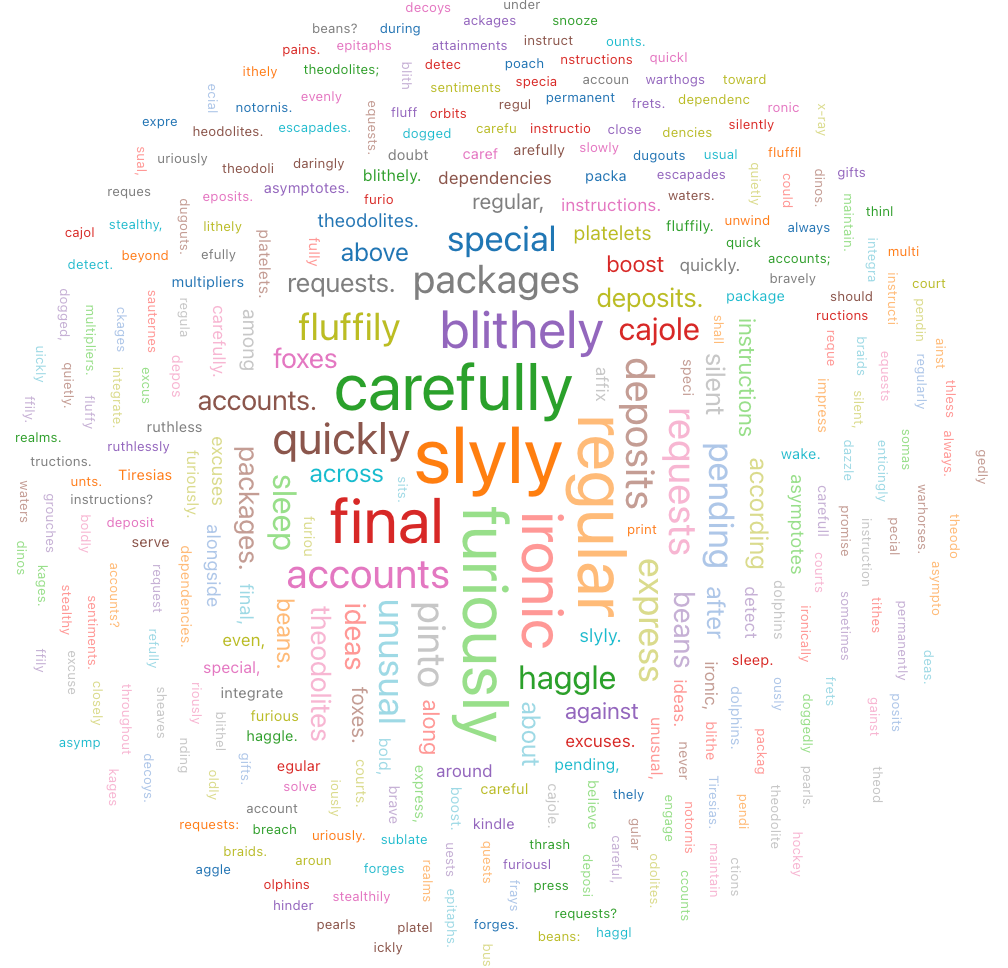
Valores de configuración: para este ejemplo de visualización de nube de palabras, se establecieron los siguientes valores: test
- Columna de palabras (columna del conjunto de datos):
o_comment - Límite de longitud de palabras: 5
- Límite de frecuencias: 2
Consulta SQL: para esta visualización de nube de palabras, se usó la siguiente consulta SQL para generar el conjunto de datos.
select * from samples.tpch.orders