Introducción a la evaluación de respuestas en una aplicación de chat en JavaScript
En este artículo se muestra cómo evaluar las respuestas de una aplicación de chat con un conjunto de respuestas correctas o ideales (conocidas como verdad básica). Siempre que cambie la aplicación de chat de una manera que afecte a las respuestas, ejecute una evaluación para comparar los cambios. Esta aplicación de demostración ofrece herramientas que puede usar hoy para facilitar la ejecución de evaluaciones.
Siguiendo las instrucciones de este artículo, podrá:
- Use las indicaciones de ejemplo proporcionadas adaptadas al dominio del firmante. Ya están en el repositorio.
- Genere preguntas de usuario de ejemplo y respuestas de verdad básica a partir de sus propios documentos.
- Ejecute evaluaciones mediante un mensaje de ejemplo con las preguntas del usuario generadas.
- Revise el análisis de respuestas.
Introducción a la arquitectura
Entre los componentes clave de la arquitectura se incluyen:
- Aplicación de chat hospedada en Azure: la aplicación de chat se ejecuta en App de Azure Service. La aplicación de chat se ajusta al protocolo de chat, lo que permite que la aplicación de evaluaciones se ejecute en cualquier aplicación de chat que se ajuste al protocolo.
- Azure AI Search: la aplicación de chat usa Azure AI Search para almacenar los datos de sus propios documentos.
- Generador de preguntas de ejemplo: puede generar una serie de preguntas para cada documento junto con la respuesta de verdad básica. Cuantos más preguntas, más larga será la evaluación.
- El evaluador ejecuta preguntas y preguntas de ejemplo en la aplicación de chat y devuelve los resultados.
- La herramienta de revisión permite revisar los resultados de las evaluaciones.
- La herramienta Diff permite comparar las respuestas entre evaluaciones.
Requisitos previos
Suscripción de Azure. Crear una cuenta gratuita
Acceso concedido a Azure OpenAI en la suscripción de Azure que quiera.
Actualmente, solo la aplicación concede acceso a este servicio. Para solicitar acceso a Azure OpenAI, rellene el formulario en https://aka.ms/oai/access.
Complete el procedimiento de aplicación de chat anterior para implementar la aplicación de chat en Azure. Este procedimiento carga los datos en el recurso de Azure AI Search. Este recurso es necesario para que funcione la aplicación de evaluaciones. No complete la sección Limpieza de recursos del procedimiento anterior.
Necesitará la siguiente información de recursos de Azure de esa implementación, lo que se conoce como la aplicación de chat de este artículo:
- URI de API web: el URI de la API de aplicación de chat implementada.
- Búsqueda de Azure AI. Se requieren los siguientes valores:
- Nombre del recurso: nombre del recurso de Azure AI Search.
- Nombre del índice: el nombre del índice de Azure AI Search donde se almacenan los documentos.
- Clave de consulta: clave para consultar el índice de búsqueda.
- Si experimentó con la autenticación de la aplicación de chat, debe deshabilitar la autenticación de usuario para que la aplicación de evaluación pueda acceder a la aplicación de chat.
Una vez recopilada esta información, no debe volver a usar el entorno de desarrollo de aplicaciones de chat . Se hace referencia más adelante en este artículo varias veces para indicar cómo usa la aplicación de chat la aplicación Evaluations. No elimine los recursos de la aplicación de chat hasta que complete todo el procedimiento de este artículo.
Hay disponible un entorno contenedor de desarrollo con todas las dependencias necesarias para completar este artículo. Puede ejecutar el contenedor de desarrollo en GitHub Codespaces (en un navegador) o localmente utilizando Visual Studio Code.
- Cuenta de GitHub
Entorno de desarrollo abierto
Comience ahora con un entorno de desarrollo que tenga todas las dependencias instaladas para completar este artículo. Debe organizar el área de trabajo de supervisión para que pueda ver tanto esta documentación como el entorno de desarrollo al mismo tiempo.
GitHub Codespaces ejecuta un contenedor de desarrollo administrado por GitHub con Visual Studio Code para la web como interfaz de usuario. Para obtener el entorno de desarrollo más sencillo, utilice Codespaces de GitHub de modo que tenga las herramientas y dependencias de desarrollador correctas preinstaladas para completar este artículo.
Importante
Todas las cuentas de GitHub pueden usar Codespaces durante un máximo de 60 horas gratis cada mes con 2 instancias principales. Para obtener más información, consulte Almacenamiento y horas de núcleo incluidas mensualmente en GitHub Codespaces.
Inicie el proceso para crear una nueva instancia de GitHub Codespace en la rama
maindel repositorio de GitHubAzure-Samples/ai-rag-chat-evaluator.Haga clic con el botón derecho en el botón siguiente y seleccione Abrir vínculo en una nueva ventana para tener el entorno de desarrollo y la documentación disponible al mismo tiempo.
En la página Crear codespace, revise las opciones de configuración de codespace y, después, seleccione Crear nuevo codespace
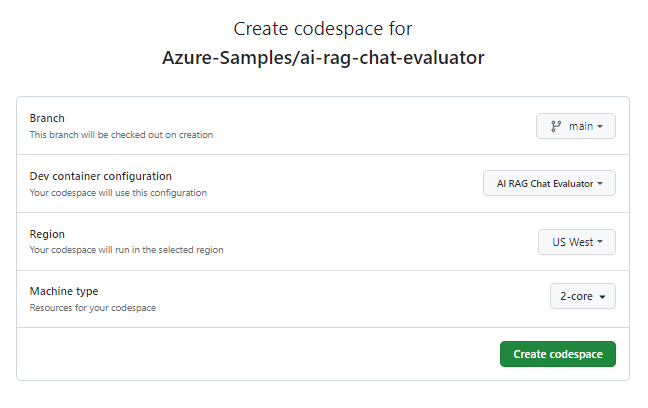
Espere a que se inicie Codespace. Este proceso de startup puede tardar unos minutos.
En el terminal de la parte inferior de la pantalla, inicie sesión en Azure con Azure Developer CLI.
azd auth login --use-device-codeCopie el código del terminal y péguelo en un navegador. Siga las instrucciones para autenticarse con su cuenta Azure.
Aprovisione el recurso de Azure necesario, Azure OpenAI, para la aplicación de evaluaciones.
azd upEsto no implementa la aplicación de evaluaciones, pero crea el recurso de Azure OpenAI con una implementación gpT-4 necesaria para ejecutar las evaluaciones localmente en el entorno de desarrollo.
Las tareas restantes de este artículo tienen lugar en el contexto de este contenedor de desarrollo.
El nombre del repositorio de GitHub se muestra en la barra de búsqueda. Esto le ayuda a distinguir entre esta aplicación de evaluaciones de la aplicación de chat. Este
ai-rag-chat-evaluatorrepositorio se conoce como la aplicación Evaluaciones de este artículo.
Preparación de los valores de entorno e información de configuración
Actualice los valores de entorno y la información de configuración con la información recopilada durante los requisitos previos de la aplicación de evaluaciones.
Use el siguiente comando para obtener la información de recursos de la aplicación Evaluations en un
.envarchivo:azd env get-values > .envAgregue los siguientes valores de la aplicación de chat para su instancia de Azure AI Search a ,
.envque ha recopilado en la sección de requisitos previos :AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>" AZURE_SEARCH_KEY="<query-key>"El
AZURE_SEARCH_KEYvalor es la clave de consulta de la instancia de Azure AI Search.Copie el
example_config.jsonarchivo en la raíz de la carpeta de la aplicación Evaluations en un nuevo archivomy_config.json.Reemplace el contenido existente de
my_config.jsonpor el siguiente contenido:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt" } } }Cambie al
target_urlvalor de URI de la aplicación de chat, que ha recopilado en la sección de requisitos previos. La aplicación de chat debe cumplir el protocolo de chat. El URI tiene el formatohttps://CHAT-APP-URL/chatsiguiente. Asegúrese de que el protocolo y lachatruta forman parte del URI.
Generación de datos de ejemplo
Para evaluar las nuevas respuestas, deben compararse con una respuesta "verdad en el terreno", que es la respuesta ideal para una pregunta determinada. Genere preguntas y respuestas a partir de documentos almacenados en Azure AI Search para la aplicación de chat.
Copie la
example_inputcarpeta en una nueva carpeta denominadamy_input.En un terminal, ejecute el siguiente comando para generar los datos de ejemplo:
python3 -m scripts generate --output=my_input/qa.jsonl --numquestions=14 --persource=2
Los pares de preguntas y respuestas se generan y almacenan en (en my_input/qa.jsonlformato JSONL) como entrada para el evaluador usado en el paso siguiente. Para una evaluación de producción, generaría más pares de control de calidad, quizás más de 200 para este conjunto de datos.
Nota:
El número de preguntas y respuestas por origen está pensado para permitirle completar rápidamente este procedimiento. No está pensado para ser una evaluación de producción que debe tener más preguntas y respuestas por origen.
Ejecución de la primera evaluación con un mensaje refinado
Edite las propiedades del archivo de
my_config.jsonconfiguración:- Cambie
results_dirpara incluir el nombre del símbolo del sistema:my_results/experiment_refined. - Cambie
prompt_templatea:<READFILE>my_input/experiment_refined.txtpara usar la plantilla de solicitud refinada en la evaluación.
El mensaje refinado es muy específico sobre el dominio del sujeto.
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by colon and the actual information, always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].- Cambie
En un terminal, ejecute el siguiente comando para ejecutar la evaluación:
python3 -m scripts evaluate --config=my_config.json --numquestions=14Esto creó una nueva carpeta de experimentos en
my_resultscon la evaluación. La carpeta contiene los resultados de la evaluación, entre los que se incluyen:eval_results.jsonl: cada pregunta y respuesta, junto con las métricas de GPT para cada par de control de calidad.summary.json: los resultados generales, como las métricas de GPT medias.
Ejecución de la segunda evaluación con un mensaje débil
Edite las propiedades del archivo de
my_config.jsonconfiguración:- Cambie
results_dira:my_results/experiment_weak - Cambie
prompt_templatea:<READFILE>my_input/prompt_weak.txtpara usar la plantilla de aviso débil en la siguiente evaluación.
Ese mensaje débil no tiene contexto sobre el dominio del sujeto:
You are a helpful assistant.- Cambie
En un terminal, ejecute el siguiente comando para ejecutar la evaluación:
python3 -m scripts evaluate --config=my_config.json --numquestions=14
Ejecución de la tercera evaluación con una temperatura específica
Use un aviso que permita más creatividad.
Edite las propiedades del archivo de
my_config.jsonconfiguración:- Cambie
results_dira:my_results/experiment_ignoresources_temp09 - Cambie
prompt_templatea:<READFILE>my_input/prompt_ignoresources.txt - Agregue una nueva invalidación:
"temperature": 0.9la temperatura predeterminada es 0,7. Cuanto mayor sea la temperatura, más creativas son las respuestas.
El mensaje de omisión es corto:
Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!- Cambie
El objeto config debe ser similar al siguiente, excepto use su propio
results_dir:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }En un terminal, ejecute el siguiente comando para ejecutar la evaluación:
python3 -m scripts evaluate --config=my_config.json --numquestions=14
Revisión de los resultados de la evaluación
Ha realizado tres evaluaciones en función de diferentes avisos y configuraciones de la aplicación. Los resultados se almacenan en la my_results carpeta . Revise cómo difieren los resultados en función de la configuración.
Use la herramienta de revisión para ver los resultados de las evaluaciones:
python3 -m review_tools summary my_resultsLos resultados tienen el siguiente aspecto:

Cada valor se devuelve como un número y un porcentaje.
Use la tabla siguiente para comprender el significado de los valores.
Valor Descripción Base Esto hace referencia a la forma en que las respuestas del modelo se basan en información fáctica y verificable. Una respuesta se considera fundamentada si es ciertamente precisa y refleja la realidad. Relevancia Esto mide la estrecha alineación de las respuestas del modelo con el contexto o el mensaje. Una respuesta pertinente aborda directamente la consulta o instrucción del usuario. Coherencia Esto hace referencia a la coherencia lógica de las respuestas del modelo. Una respuesta coherente mantiene un flujo lógico y no se contradiga. Referencia bibliográfica Esto indica si la respuesta se devolvió en el formato solicitado en el símbolo del sistema. Length Esto mide la longitud de la respuesta. Los resultados deberían indicar que las 3 evaluaciones tenían gran relevancia, mientras
experiment_ignoresources_temp09que tenían la menor relevancia.Seleccione la carpeta para ver la configuración de la evaluación.
Escriba Ctrl + C salga de la aplicación y vuelva al terminal.
Comparación de las respuestas
Compare las respuestas devueltas de las evaluaciones.
Seleccione dos de las evaluaciones que se van a comparar y, a continuación, use la misma herramienta de revisión para comparar las respuestas:
python3 -m review_tools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09Consulte los resultados.

Escriba Ctrl + C salga de la aplicación y vuelva al terminal.
Sugerencias para evaluaciones adicionales
- Edite las indicaciones en
my_inputpara adaptar las respuestas, como el dominio del sujeto, la longitud y otros factores. - Edite el
my_config.jsonarchivo para cambiar los parámetros, comotemperature, ysemantic_rankery vuelva a ejecutar experimentos. - Compare diferentes respuestas para comprender cómo afecta la pregunta y la solicitud a la calidad de la respuesta.
- Genere un conjunto independiente de preguntas y respuestas de verdad básicas para cada documento del índice de Azure AI Search. A continuación, vuelva a ejecutar las evaluaciones para ver cómo difieren las respuestas.
- Modifique las indicaciones para indicar respuestas más cortas o más largas agregando el requisito al final del mensaje. Por ejemplo:
Please answer in about 3 sentences.
Limpieza de recursos
Limpieza de los recursos de Azure
Los recursos Azure creados en este artículo se facturan a su suscripción Azure. Si no espera necesitar estos recursos en el futuro, elimínelos para evitar incurrir en más gastos.
Ejecute el siguiente comando de la Azure Developer CLI para eliminar los recursos de Azure y eliminar el código de origen:
azd down --purge
Limpiar GitHub Codespaces
La eliminación del entorno de GitHub Codespaces garantiza que pueda maximizar la cantidad de derechos de horas gratuitas por núcleo que obtiene para su cuenta.
Importante
Para obtener más información sobre los derechos de la cuenta de GitHub, consulte Almacenamiento y horas de núcleo incluidas mensualmente en GitHub Codespaces.
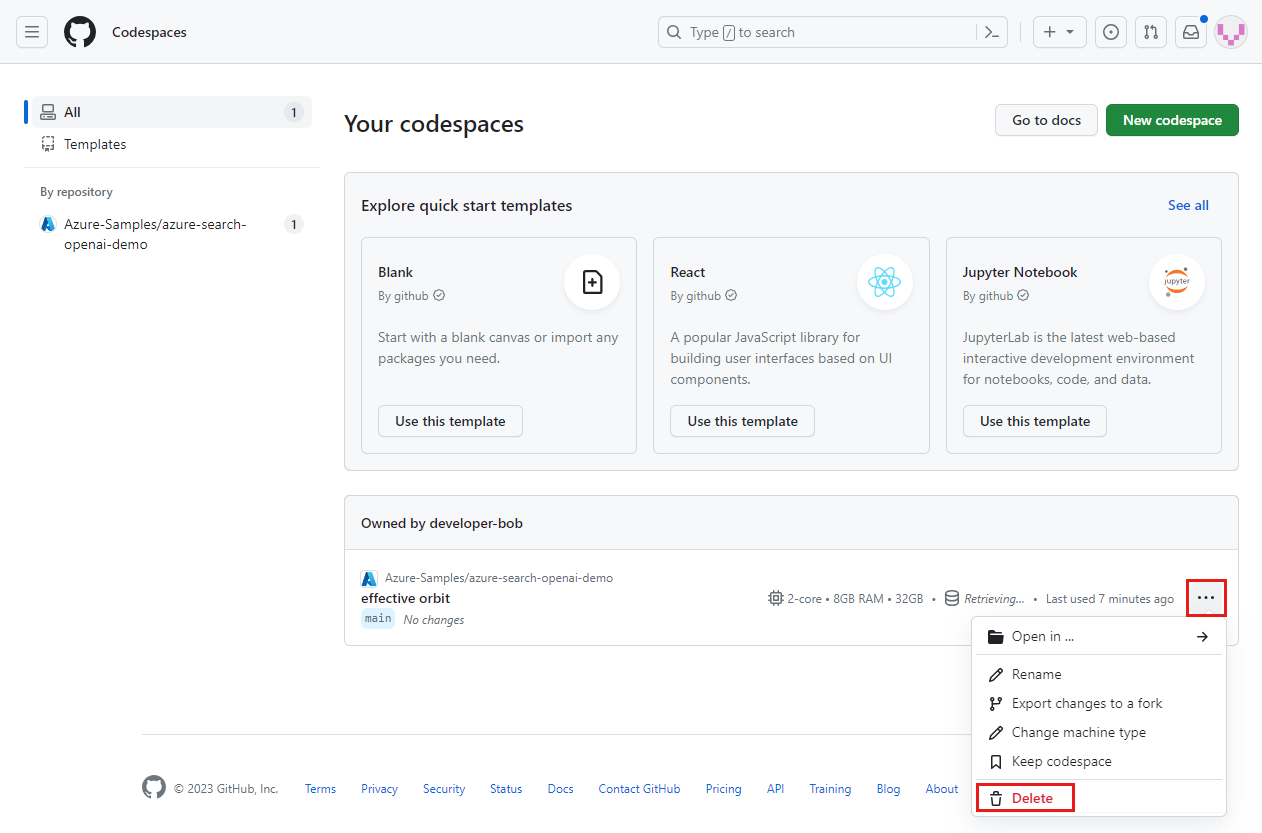
Inicie sesión en el panel de GitHub Codespaces (https://github.com/codespaces).
Busque los espacios de código que se ejecutan actualmente procedentes del repositorio de GitHub
Azure-Samples/ai-rag-chat-evaluator.
Abra el menú contextual del codespace y, a continuación, seleccione Eliminar.

Vuelva al artículo de la aplicación de chat para limpiar esos recursos.
Pasos siguientes
- Repositorio de evaluaciones
- Aplicación de chat para empresas Repositorio GitHub
- Crear una aplicación de chat con la arquitectura de soluciones de mejores prácticas de Azure OpenAI
- Control de acceso en aplicaciones de IA generativa con Búsqueda de Azure AI
- Cree una solución OpenAI preparada para la empresa con Azure API Management
- Superar el vector de búsqueda con capacidades híbridas de recuperación y clasificación
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de