Uso del flujo estructurado de Apache Spark con Apache Kafka y Azure Cosmos DB
Aprenda a usar Apache Spark y su flujo estructurado para leer datos de Apache Kafka en Azure HDInsight y, después, almacenarlos en Azure Cosmos DB.
Azure Cosmos DB es una base de datos de varios modelos distribuida globalmente. En este ejemplo se usa un modelo de base de datos de Azure Cosmos DB for NoSQL. Para obtener más información, consulte el documento Bienvenido a Azure Cosmos DB.
El flujo estructurado de Spark es un motor de procesamiento de flujo basado en Spark SQL. Permite expresar los cálculos de streaming de la misma forma que el cálculo por lotes de los datos estáticos. Para obtener más información sobre el flujo estructurado, consulte el artículo Structured Streaming Programming Guide (Guía de programación de flujo estructurado) en Apache.org.
Importante
En este ejemplo se utiliza Spark 2.4 en HDInsight 4.0.
Los pasos que se describen en este documento crean un grupo de recursos de Azure que contiene un clúster Spark de HDInsight y un clúster Kafka de HDInsight. Estos dos clústeres se encuentran en una instancia de Azure Virtual Network, lo que permite al clúster Spark comunicarse directamente con el clúster Kafka.
Cuando haya terminado los pasos indicados en este documento, no olvide eliminar los clústeres para evitar gastos innecesarios.
Creación de los clústeres
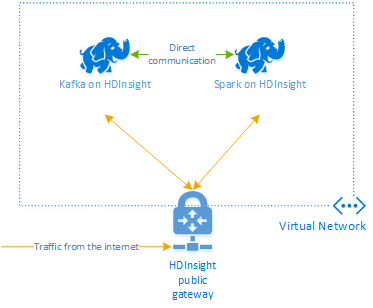
Apache Kafka en HDInsight no proporciona acceso a los agentes de Kafka a través de Internet. Cualquier comunicación con Kafka debe realizarse en la misma red virtual de Azure que utilizan los nodos del clúster Kafka. En este ejemplo, los clústeres Kafka y Spark se encuentran en una red virtual de Azure. En el diagrama siguiente, se muestra cómo fluye la comunicación entre los clústeres:
Nota:
El servicio Kafka se limita a la comunicación dentro de la red virtual. Se puede acceder a otros servicios del clúster, como SSH y Ambari, a través de Internet. Para más información sobre los puertos públicos disponibles en HDInsight, consulte Puertos e identificadores URI usados en HDInsight.
Aunque puede crear manualmente la red virtual de Azure y los clústeres Kafka y Spark, resulta más sencillo utilizar una plantilla de Azure Resource Manager. Siga los pasos que se indican a continuación para implementar una red virtual de Azure y los clústeres Kafka y Spark en la suscripción de Azure.
Utilice el siguiente botón para iniciar sesión en Azure y abrir la plantilla en Azure Portal.

La plantilla de Azure Resource Manager se encuentra en el repositorio de GitHub para este proyecto (https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb).
Esta plantilla crea los siguientes recursos:
Un clúster de Kafka en HDInsight 4.0.
Un clúster de Spark en HDInsight 4.0.
Una instancia de Azure Virtual Network, que contiene los clústeres de HDInsight. La red virtual creada por la plantilla utiliza el espacio de direcciones 10.0.0.0/16.
Una base de datos de Azure Cosmos DB for NoSQL.
Importante
El cuaderno de flujo estructurado que se utiliza en este ejemplo requiere Spark en HDInsight 4.0. Si usa una versión anterior de Spark en HDInsight, recibirá errores al usar dicho cuaderno.
Utilice los datos siguientes para rellenar las entradas de la sección Implementación personalizada:
Propiedad Valor Subscription Seleccione su suscripción a Azure. Resource group cree un grupo o seleccione uno existente. Este grupo contiene el clúster de HDInsight. Nombre de la cuenta de Azure Cosmos DB Este valor se utiliza como nombre para la cuenta de Azure Cosmos DB. El nombre solo puede contener letras minúsculas, números y el carácter de guion (-). Debe tener una longitud de entre 3 y 31 caracteres. Nombre del clúster base este valor se utiliza como nombre base en los clústeres Spark y Kafka. Por ejemplo, si especifica myhdi, creará un clúster de Spark denominado spark-myhdi y un clúster de Kafka denominado kafka-myhdi. Versión del clúster versión del clúster de HDInsight. Este ejemplo se ha probado con HDInsight 4.0 y podría no funcionar con otros tipos de clúster. Cluster Login User Name (Nombre de usuario de inicio de sesión del clúster) nombre de usuario del administrador de los clústeres Spark y Kafka. Cluster Login Password (Contraseña de inicio de sesión del clúster) contraseña de usuario del administrador de los clústeres Spark y Kafka. Nombre de usuario de SSH usuario de SSH que se va a crear para los clústeres Spark y Kafka. Contraseña de SSH contraseña del usuario de SSH para los clústeres Spark y Kafka. 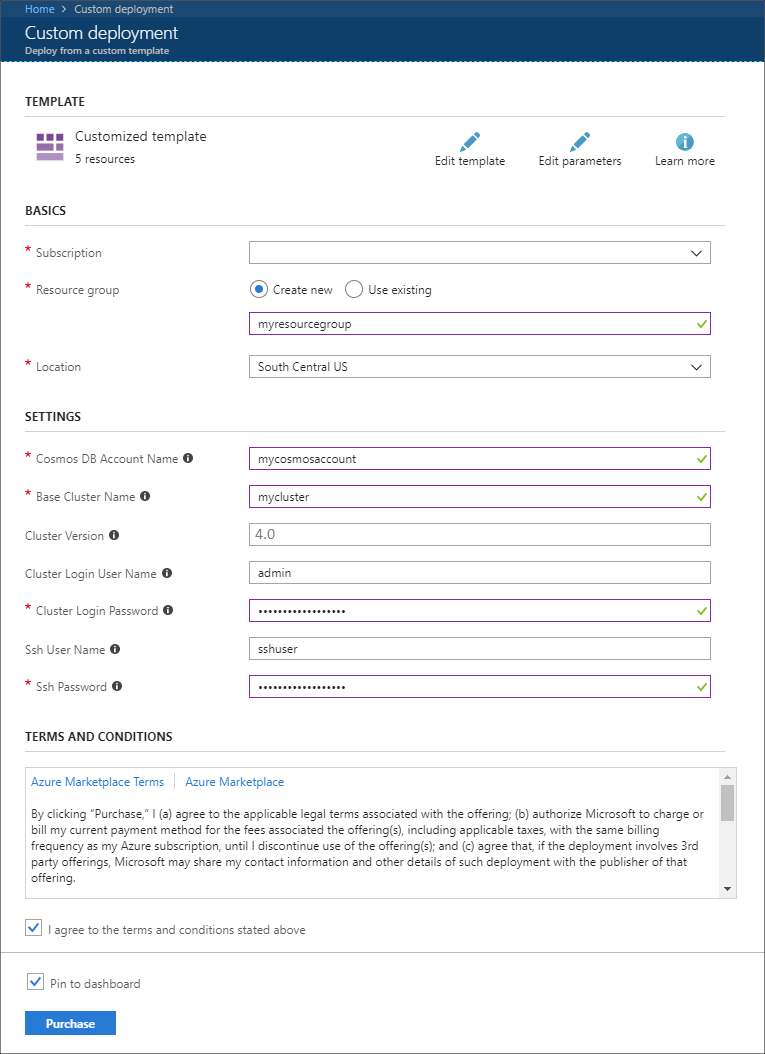
Consulte los Términos y condiciones y seleccione Acepto los términos y condiciones indicados anteriormente.
Por último, seleccione Adquirir. Puede tardar hasta 45 minutos en crear los clústeres, la red virtual y la cuenta de Azure Cosmos DB.
Creación de la base de datos y la colección de Azure Cosmos DB
El proyecto utilizado en este documento almacena los datos en Azure Cosmos DB. Antes de ejecutar el código, debe crear una base de datos y una colección en la instancia de Azure Cosmos DB. También debe recuperar el punto de conexión del documento y la clave usada para autenticar las solicitudes en Azure Cosmos DB.
Una manera de hacerlo es mediante la CLI de Azure. El script siguiente creará una base de datos denominada kafkadata y una colección denominada kafkacollection. A continuación, devuelve la clave principal.
#!/bin/bash
# Replace 'myresourcegroup' with the name of your resource group
resourceGroupName='myresourcegroup'
# Replace 'mycosmosaccount' with the name of your Azure Cosmos DB account name
name='mycosmosaccount'
# WARNING: If you change the databaseName or collectionName
# then you must update the values in the Jupyter Notebook
databaseName='kafkadata'
collectionName='kafkacollection'
# Create the database
az cosmosdb sql database create --account-name $name --name $databaseName --resource-group $resourceGroupName
# Create the collection
az cosmosdb sql container create --account-name $name --database-name $databaseName --name $collectionName --partition-key-path "/my/path" --resource-group $resourceGroupName
# Get the endpoint
az cosmosdb show --name $name --resource-group $resourceGroupName --query documentEndpoint
# Get the primary key
az cosmosdb keys list --name $name --resource-group $resourceGroupName --type keys
La información del punto de conexión del documento y de la clave principal es similar al siguiente texto:
# endpoint
"https://mycosmosaccount.documents.azure.com:443/"
# key
"YqPXw3RP7TsJoBF5imkYR0QNA02IrreNAlkrUMkL8EW94YHs41bktBhIgWq4pqj6HCGYijQKMRkCTsSaKUO2pw=="
Importante
Guarde los valores de punto de conexión y de clave, ya que son necesarios en las instancias de Jupyter Notebook.
Obtención de los cuadernos
El código para el ejemplo descrito en este documento está disponible en https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb.
Carga de los cuadernos
Siga estos pasos para cargar los cuadernos del proyecto en el clúster de Spark en HDInsight:
En el explorador web, conéctese a Jupyter Notebook en el clúster de Spark. En la siguiente URL, reemplace
CLUSTERNAMEpor el nombre del clúster de Spark:https://CLUSTERNAME.azurehdinsight.net/jupyterCuando se lo soliciten, escriba el nombre de inicio de sesión del clúster (administrador) y la contraseña que utilizó cuando creó el clúster.
En la parte superior derecha de la página, utilice el botón Cargar para cargar el archivo Stream-taxi-data-to-kafka.ipynb en el clúster. Seleccione Open (Abrir) para iniciar la carga.
Busque la entrada Stream-taxi-data-to-kafka.ipynb en la lista de cuadernos y seleccione el botón Cargar que está junto a ella.
Repita los pasos del 1 al 3 para cargar el cuaderno Stream-data-from-Kafka-to-Cosmos-DB.ipynb.
Cargar los datos del taxi en Kafka
Cuando se hayan cargado los archivos, seleccione la entrada Stream-taxi-data-to-kafka.ipynb para abrir el cuaderno. Siga los pasos descritos en el cuaderno para cargar datos en Kafka.
Procesamiento de datos de taxi mediante el flujo estructurado de Spark
En la página principal de Jupyter Notebook, seleccione la entrada Stream-data-from-Kafka-to-Cosmos-DB.ipynb. Siga los pasos descritos en el cuaderno para transmitir datos en secuencia de Kafka y en Azure Cosmos DB mediante el flujo estructurado de Spark.
Pasos siguientes
Ahora que ha aprendido a usar el flujo estructurado de Apache Spark, consulte los siguientes documentos para aprender más sobre cómo trabajar con Apache Spark, Apache Kafka y Azure Cosmos DB: