Extracción, transformación y carga de datos (ETL) a escala
Extracción, transformación y carga de datos (ETL) es el proceso por el que se obtienen los datos de diversos orígenes. Los datos se recopilan en una ubicación estándar, se limpian y se procesan. En última instancia,los datos se cargan en un almacén de datos desde los que se pueden consultar. Los procesos ETL heredados importan los datos, los limpian localmente y, a continuación, los almacenan en un motor de datos relacionales. Con Azure HDInsight, una gran variedad de componentes del entorno de Apache Hadoop admiten ETL a escala.
Esta canalización resume el uso de HDInsight en el proceso de ETL:
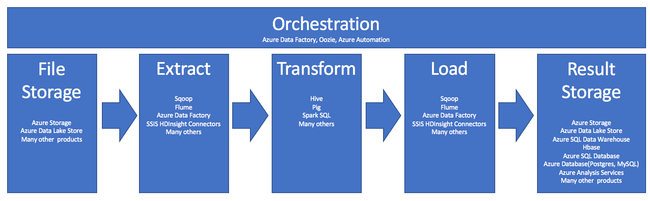
En las siguientes secciones se explica cada una de las fases de ETL y sus componentes asociados.
Orquestación
La orquestación se expande a lo largo de todas las fases de la canalización de ETL. Los trabajos de ETL en HDInsight a menudo implican varios productos diferentes que funcionan con dependencia el uno del otro. Por ejemplo:
- Puede usar Apache Hive para limpiar una parte de los datos y Apache Pig para limpiar otra parte.
- Puede usar Azure Data Factory para cargar datos en Azure SQL Database desde Azure Data Lake Store.
La orquestación es necesaria para ejecutar el trabajo pertinente en el momento adecuado.
Apache Oozie
Apache Oozie es un sistema de coordinación de flujos de trabajo que administra trabajos de Hadoop. Oozie se ejecuta dentro de un clúster de HDInsight y se integra con la pila de Hadoop. Oozie es compatible con los trabajos de Hadoop para Apache Hadoop MapReduce, Pig, Hive y Sqoop. Puede usar Oozie para programar trabajos específicos de un sistema, como scripts de shell o programas Java.
Para obtener más información, consulte Uso de Apache Oozie con Apache Hadoop para definir y ejecutar un flujo de trabajo en HDInsight. Consulte también Uso de una canalización de datos.
Azure Data Factory
Azure Data Factory proporciona funcionalidades de orquestación en forma de plataforma como servicio (PaaS). Azure Data Factory es un servicio de integración de datos en la nube. Permite crear flujos trabajo controlados por datos para orquestar y automatizar el movimiento y la transformación de los datos.
Use Azure Data Factory para:
- Crear y programar flujos de trabajo controlados por datos. Estas canalizaciones ingieren datos de distintos almacenes de datos.
- Procesar y transformar los datos mediante servicios de proceso, como HDInsight o Hadoop. También puede usar Spark, Azure Data Lake Analytics, Azure Batch o Azure Machine Learning en este paso.
- Publicación de datos de salida en almacenes de datos como Azure Synapse Analytics para que las aplicaciones de inteligencia empresarial los consuman.
Para obtener más información sobre Azure Data Factory, consulte la documentación.
Ingesta de almacenamiento de archivos y de resultados
Normalmente, los archivos de datos de origen se cargan en una ubicación de Azure Storage o Azure Data Lake Storage. Los archivos suelen tener un formato plano, como CSV. Sin embargo, pueden tener cualquier formato.
Azure Storage
Azure Storage tiene objetivos de adaptabilidad específicos. Para más información, vea Objetivos de escalabilidad y rendimiento de Blob Storage. Para los nodos más analíticos, Azure Storage se escala mejor cuando trabaja con muchos archivos pequeños. Azure Storage garantiza el mismo rendimiento, independientemente del tamaño de los archivos, siempre y cuando se encuentre dentro de los límites de la cuenta. Puede almacenar terabytes de datos y seguir teniendo un rendimiento coherente. Esta instrucción es cierta si usa un subconjunto o todos los datos.
Azure Storage tiene varios tipos de blobs. Un blob en anexos es una opción ideal para almacenar los registros web o los datos del sensor.
Varios blobs pueden distribuirse en distintos servidores para escalar horizontalmente su acceso. Sin embargo, un solo servidor aprovisiona a un único blob. Aunque los blobs pueden agruparse de forma lógica en contenedores de blob, esta agrupación no afecta a la creación de particiones.
Azure Storage tiene una capa de API de WebHDFS para el almacenamiento de blobs. Todos los servicios de HDInsight pueden acceder a los archivos de Azure Blob Storage para la limpieza y el procesamiento de datos. Esto es similar al modo en que esos servicios usarían el sistema de archivos distribuido de Hadoop (HDFS).
Normalmente, los datos se ingieren en Azure Storage mediante PowerShell, el SDK de Azure Storage o AzCopy.
Azure Data Lake Storage
Azure Data Lake Storage es un repositorio administrado de hiperescala para datos de análisis. Es compatible con un paradigma de diseño similar a HDFS y, por tanto, lo utiliza. Data Lake Storage ofrece adaptabilidad ilimitada tanto para la capacidad total como para el tamaño de los archivos individuales. Es una buena opción para trabajar con archivos grandes, ya que estos se pueden almacenar en varios nodos. La creación de particiones de datos de Data Lake Storage se realiza en segundo plano. Obtiene un rendimiento masivo para ejecutar trabajos de análisis con miles de ejecutores simultáneos que leen y escriben cientos de terabytes de datos con gran eficacia.
Normalmente, los datos se ingieren en Data Lake Storage mediante Azure Data Factory. También puede usar los SDK de Data Lake Storage, AdlCopy Service, Apache DistCp o Apache Sqoop. El servicio que elija dependerá de la ubicación de los datos. Si estos se encuentran en un clúster de Hadoop existente, puede usar Apache DistCp, AdlCopy Service o Azure Data Factory. Si los datos se encuentran en Azure Blob Storage, puede usar el SDK de .NET para Azure Data Lake Storage, Azure PowerShell o Azure Data Factory.
Data Lake Storage está optimizado para la ingesta de eventos mediante Azure Event Hubs.
Consideraciones para ambas opciones de almacenamiento
Para cargar conjuntos de datos en el intervalo de terabytes, la latencia de red puede ser un problema importante. Esto sucede en particular si los datos proceden de una ubicación local. En tales casos, puede utilizar las opciones siguientes:
Azure ExpressRoute: permite crear conexiones privadas entre los centros de datos de Azure y la infraestructura local. Estas conexiones ofrecen una opción confiable para transferir grandes cantidades de datos. Para obtener más información, consulte la documentación de Azure ExpressRoute.
Carga de datos desde unidades de disco duro: puede usar el servicio Azure Import/Export para enviar unidades de disco duro con sus datos a un centro de datos de Azure. Los datos se cargan primero en Azure Blob Storage. Después, puede usar Azure Data Factory o la herramienta AdlCopy para copiar datos desde Azure Blob Storage a Data Lake Storage.
Azure Synapse Analytics
Azure Synapse Analytics es una opción adecuada para almacenar los resultados preparados. Puede usar Azure HDInsight para ejecutar estos servicios para Azure Synapse Analytics.
Azure Synapse Analytics es un almacén de bases de datos relacionales optimizado para cargas de trabajo de análisis. Se escala según las tablas con particiones. La tablas se pueden dividir en particiones entre varios nodos. Los nodos se seleccionan en el momento de la creación. Se pueden escalar a posteriori, pero es un proceso activo que puede requerir el movimiento de datos. Para más información, consulte Administración de proceso en Azure Synapse Analytics.
HBase Apache
Apache HBase es un almacén de par clave-valor disponible en Azure HDInsight. Es una base de datos NoSQL de código abierto basada en Hadoop y modelada según Google BigTable. HBase proporciona un acceso aleatorio y eficaz y una enorme coherencia para grandes cantidades de datos no estructurados y semiestructurados.
Dado que HBase es una base de datos sin esquemas, no es necesario definir columnas ni tipos de datos antes de usarlos. Los datos se almacenan en las filas de una tabla y se agrupan por familia de columnas.
El código abierto se escala linealmente para controlar petabytes de datos en miles de nodos. HBase se basa en la redundancia de datos, el procesamiento por lotes y otras características proporcionadas por aplicaciones distribuidas en el entorno de Hadoop.
Es un destino adecuado para los datos del sensor y de registro para su posterior análisis.
La adaptabilidad de HBase depende del número de nodos del clúster de HDInsight.
Bases de datos de Azure SQL
Azure ofrece tres bases de datos relacionales de PaaS:
- Azure SQL Database es una implementación de Microsoft SQL Server. Para obtener más información sobre el rendimiento, consulte Ajuste del rendimiento en Azure SQL Database.
- Azure Database for MySQL es una implementación de MySQL de Oracle.
- Azure Database for PostgreSQL es una implementación de PostgreSQL.
Agregue más CPU y memoria para escalar verticalmente estos productos. También puede optar por usar los discos premium con los productos para mejorar el rendimiento de E/S.
Azure Analysis Services
Azure Analysis Services es un motor de datos analíticos que se usa para la ayuda a la toma de decisiones y el análisis empresarial. Proporciona los datos analíticos para los informes empresariales y las aplicaciones cliente, como Power BI. Los datos analíticos también funcionan con Excel, informes de SQL Server Reporting Services y otras herramientas de visualización de datos.
Escale los cubos de análisis cambiando los niveles de cada cubo individual. Para más información, vea Precios de Azure Analysis Services.
Extracción y carga
Una vez que los datos existan en Azure, puede usar muchos servicios para extraerlos y cargarlos en otros productos. HDInsight admite Sqoop y Flume.
Apache Sqoop
Apache Sqoop es una herramienta que se ha diseñado para transferir datos eficazmente entre orígenes de datos estructurados, semiestructurados y no estructurados.
Sqoop usa MapReduce para importar y exportar los datos y para proporcionar tolerancia a errores y una operación paralela.
Apache Flume
Apache Flume es un servicio distribuido, confiable y disponible para recopilar, agregar y mover grandes cantidades de datos de registro de forma eficaz. Su arquitectura flexible se basa en los flujos de datos de streaming. Flume es sólido y tolerante a errores con mecanismos de confiabilidad ajustables. Tiene numerosos mecanismos de conmutación por error y recuperación. Flume utiliza un modelo de datos extensible simple que permite la aplicación de análisis en línea.
No se puede usar Flume Apache con Azure HDInsight. Sin embargo, en una instalación de Hadoop local, se puede usar Flume para enviar datos a Azure Blob Storage o Azure Data Lake Storage. Para obtener más información, consulte Using Apache Flume with HDInsight (Uso de Apache Flume con HDInsight).
Transformación
Una vez que existan los datos en la ubicación elegida, deberá limpiarlos, combinarlos o prepararlos para un patrón de uso específico. Hive, Pig y Spark SQL son buenas opciones para ese tipo de trabajo. Todos se admiten en HDInsight.