Supervisión del rendimiento de un clúster en Azure HDInsight
La supervisión del mantenimiento y rendimiento de un clúster de HDInsight es esencial para mantener un rendimiento y una utilización óptimos de los recursos. La supervisión puede ayudarle también a detectar y solucionar problemas de código de usuario y de errores de configuración del clúster.
En las secciones siguientes se describe cómo supervisar y optimizar la carga en los clústeres, las colas YARN de Apache Hadoop y detectar problemas de limitación de almacenamiento.
Supervisión de la carga del clúster
Los clústeres de Hadoop pueden ofrecer el rendimiento más óptimo cuando la carga del clúster se distribuye uniformemente entre todos los nodos. Esto permite que las tareas de procesamiento se ejecuten sin estar limitadas por la memoria RAM, la CPU o los recursos de disco en los nodos individuales.
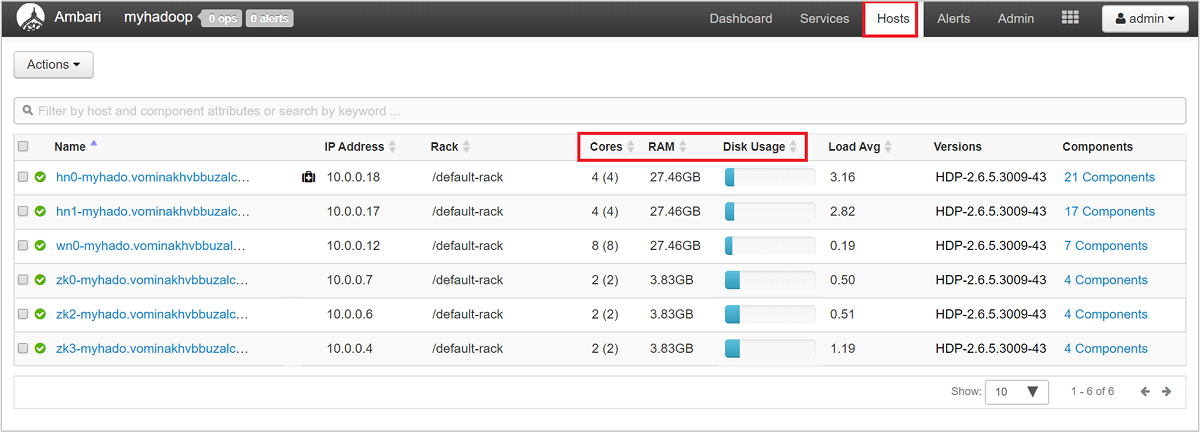
Para obtener una visión de alto nivel de los nodos de un clúster y su carga, inicie sesión en la interfaz de usuario web de Ambari y seleccione la pestaña Hosts. Los hosts se enumeran por sus nombres de dominio completos. El estado de funcionamiento de cada host se muestra mediante un indicador de mantenimiento de color:
| Color | Descripción |
|---|---|
| Rojo | Al menos un componente maestro del host está inactivo. Mueva el puntero encima para una información sobre herramientas que enumera los componentes afectados. |
| Naranja | Al menos un componente subordinado del host está inactivo. Mueva el puntero encima para una información sobre herramientas que enumera los componentes afectados. |
| Amarillo | El servidor de Ambari no recibió ningún latido del host durante más de 3 minutos. |
| Verde | Estado de funcionamiento normal. |
También verá columnas que muestra el número de núcleos y la cantidad de RAM de cada host, así como el uso del disco y el promedio de carga.
Seleccione cualquiera de los nombres de host para tener una vista detallada de los componentes que se ejecutan en el host y su métrica. La métrica se muestra como una escala de tiempo seleccionable de uso de la CPU, carga, uso del disco, uso de la memoria, uso de la red y números de procesos.
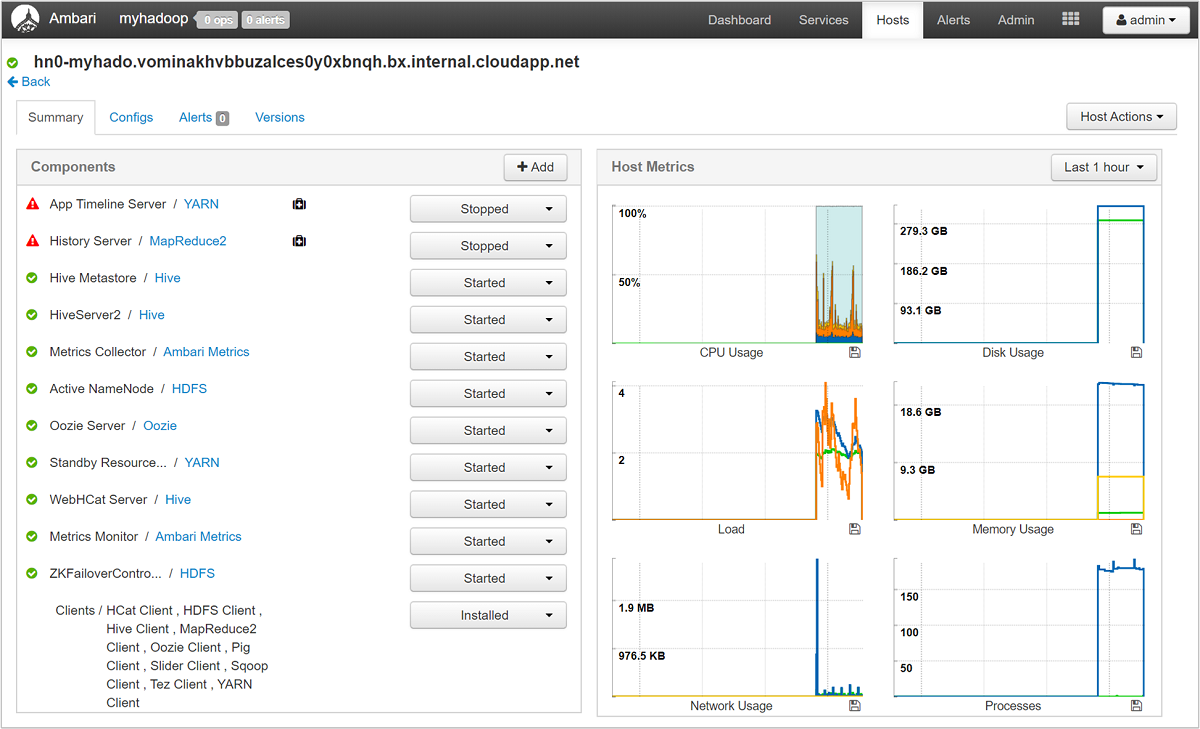
Para más información acerca del establecimiento de alertas y visualización de métricas, consulte Administración de clústeres de HDInsight con la interfaz de usuario web de Apache Ambari.
Configuración de la cola de YARN
Hadoop tiene varios servicios que se ejecutan a través de su plataforma distribuida. YARN (Yet Another Resource Negotiator) coordina estos servicios y asigna los recursos de clúster para asegurarse de que las cargas se distribuyen uniformemente en el clúster.
YARN divide las responsabilidades de JobTracker, la administración de recursos y la programación y supervisión de recursos, en dos demonios: ResourceManager global y ApplicationMaster (AM) por aplicación.
Resource Manager es un programador puro y únicamente arbitra los recursos disponibles entre todas las aplicaciones que compiten por ellos. Resource Manager garantiza que todos los recursos están siempre en uso y se optimizan para varias constantes como SLA, garantías de capacidad, etc. ApplicationMaster negocia los recursos de Resource Manager y funciona con NodeManager para ejecutar y supervisar los contenedores y su consumo de recursos.
Cuando varios inquilinos comparten un clúster grande, compiten por sus recursos. CapacityScheduler es un programador acoplable que sirve de ayuda al compartir recursos, ya que ponen las solicitudes en cola. CapacityScheduler también admite colas jerárquicas para asegurarse de que los recursos se comparten entre las subcolas de una organización, antes de que se permita a las colas de otras aplicaciones utilizar los recursos libres.
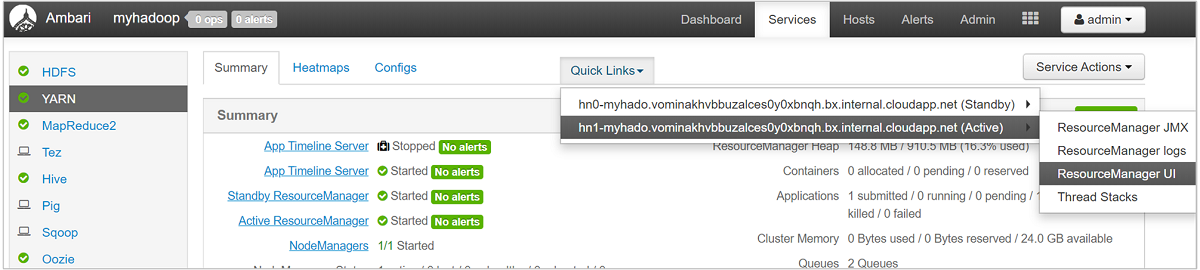
YARN nos permite asignar recursos a estas colas y muestra si todos los recursos disponibles están asignados. Para ver información acerca de las colas, inicie sesión en la interfaz de usuario web de Ambari y, después, seleccione YARN Queue Manager (Administrador de colas de YARN) en el menú superior.
La página YARN Queue Manager (Administrador de colas de YARN) muestra una lista de las colas, a la izquierda, y el porcentaje de la capacidad que se asigna a cada una.
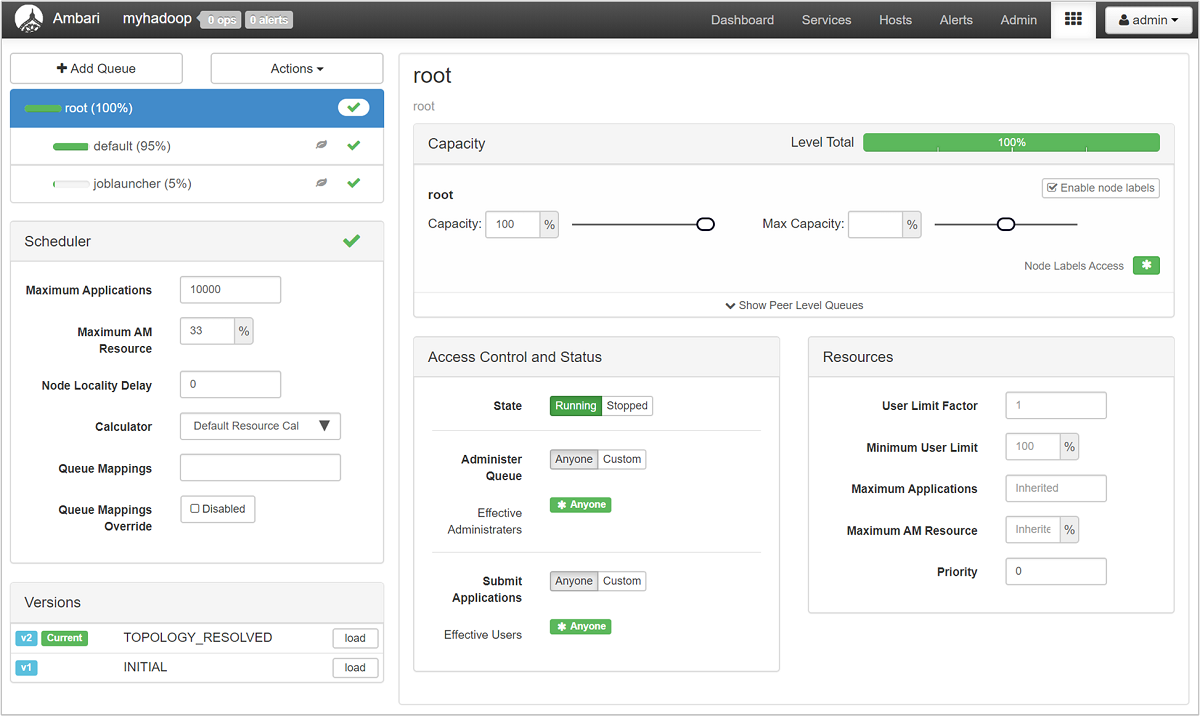
Para obtener una visión más detallada de las colas, seleccione en el panel de Ambari el servicio YARN en la lista de la izquierda. Después, en el menú desplegable Vínculos rápidos, seleccione ResourceManager UI (Interfaz de usuario de ResourceManager) debajo del nodo activo.
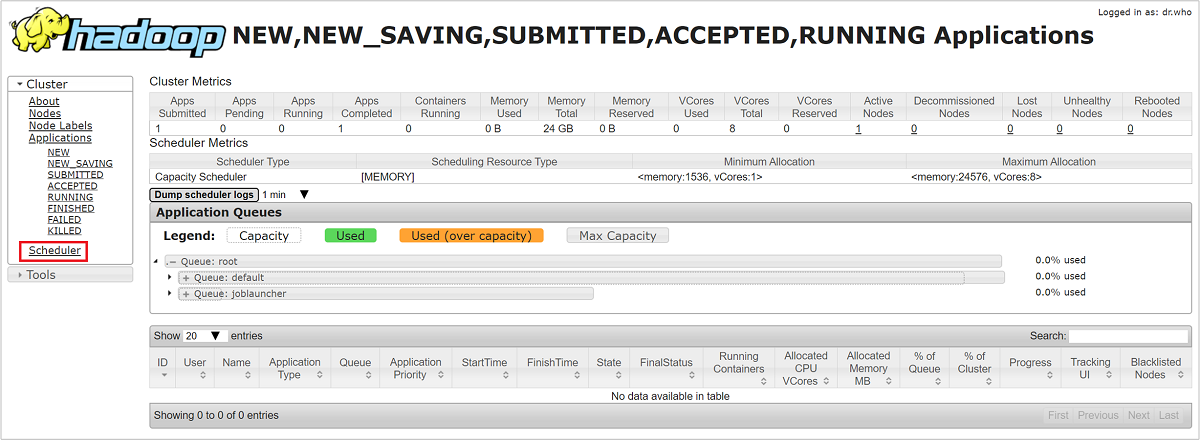
En la interfaz de usuario de Resource Manager, seleccione Scheduler (Programador) en el menú de la izquierda. Se ve una lista de las colas debajo de Application Queues (Colas de aplicación). Aquí puede ver la capacidad que se usa para cada una de las colas, cómo se distribuyen los trabajos entre ellas y si alguno de los trabajos tiene los recursos restringidos.
Limitación del almacenamiento
Se puede producir un cuello de botella de rendimiento de un clúster a nivel de almacenamiento. Con mucha frecuencia, este tipo de cuello de botella se debe al bloqueo de operaciones de entrada y salida (E/S), que se produce cuando las tareas en ejecución envían más operaciones de E/S de las que el servicio de almacenamiento puede controlar. Este bloqueo crea una cola de solicitudes de E/S que esperan a que se procesen las E/S actuales para procesarse. Los bloqueos se deben a una limitación del almacenamiento, que no es un límite físico, sino más bien un límite que impone el servicio de almacenamiento mediante un Acuerdo de Nivel de Servicio (SLA). Este límite garantiza que ningún cliente o inquilino individuales pueden monopolizar el servicio. El Acuerdo de Nivel de Servicio limita el número de operaciones de E/S por segundo (IOPS) de Azure Storage (para más información, consulte Objetivos de escalabilidad y rendimiento para cuentas de almacenamiento estándar).
Si usa Azure Storage, para información acerca de la supervisión de problemas relacionados con el almacenamiento, incluida la limitación, consulte el artículo Supervisión, diagnóstico y solución de problemas de Microsoft Azure Storage.
Si la memoria auxiliar del clúster es Azure Data Lake Storage (ADLS), lo más probable es que su limitación se deba al ancho de banda. En este caso, la limitación puede identificarse mediante la observación de los errores de limitación en los registros de tarea. En el caso de ADLS, consulte la sección relativa a la limitación del servicio apropiado en estos artículos:
- Guía para la optimización del rendimiento de Apache Hive en HDInsight y Azure Data Lake Storage
- Guía para la optimización del rendimiento de MapReduce en HDInsight y Azure Data Lake Storage
Solución de problemas de rendimiento lento del nodo
En algunos casos, puede producirse una lentitud debido a que hay poco espacio en disco en el clúster. Realice una investigación con estos pasos:
Use comandos de SSH para conectarse a cada uno de los nodos.
Compruebe el uso del disco mediante la ejecución de uno de los siguientes comandos:
df -h du -h --max-depth=1 / | sort -hRevise la salida y compruebe si hay archivos de gran tamaño en la carpeta
mntu otras carpetas. Normalmente, las carpetasusercacheyappcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) contienen archivos grandes.Si hay archivos grandes, o bien un trabajo actual está causando el aumento del archivo o bien un trabajo anterior con errores ha contribuido a este problema. Para comprobar si este comportamiento se debe a un trabajo actual, ejecute el siguiente comando: .
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/Si este comando indica un trabajo específico, puede elegir finalizar el trabajo con un comando similar al siguiente:
yarn application -kill -applicationId <application_id>Reemplace
application_idpor el identificador de la aplicación. Si no se indica ningún trabajo específico, vaya al paso siguiente.Cuando finalice el comando anterior o si no se indica ningún trabajo específico, elimine los archivos grandes que identificó, mediante la ejecución de un comando similar al siguiente:
rm -rf filecache usercache
Para más información acerca de los problemas de espacio en disco, consulte el artículo sobre espacio insuficiente en disco.
Nota:
Si tiene archivos grandes que desea conservar, pero que contribuyen al problema de poco espacio en disco, debe escalar verticalmente el clúster de HDInsight y reiniciar los servicios. Después de completar este procedimiento y esperar unos minutos, observará que el almacenamiento se libera y se restaura el rendimiento habitual del nodo.
Pasos siguientes
Para más información acerca de la solución de problemas y supervisión de los clústeres, visite los siguientes vínculos: