Migración del clúster de HDInsight a una versión más reciente
Para aprovechar las ventajas de las características más recientes de HDInsight, se recomienda que los clústeres de HDInsight se migren regularmente a la versión más reciente. HDInsight no admite actualizaciones locales en las que un clúster existente se actualiza a una versión más reciente del componente. Debe crear un nuevo clúster con la versión de plataforma y componente deseada y, a continuación, migrar las aplicaciones para que usen el nuevo clúster. Siga las directrices que aparecen a continuación para migrar las versiones del clúster de HDInsight.
Nota:
Si va a crear un clúster de Hive con un contenedor de almacenamiento principal, cópielo desde un clúster de HDInsight existente. No copie el contenido completo. Copie solo las carpetas de datos que están configuradas.
Tareas de migración
El flujo de trabajo para actualizar el clúster de HDInsight es el siguiente.
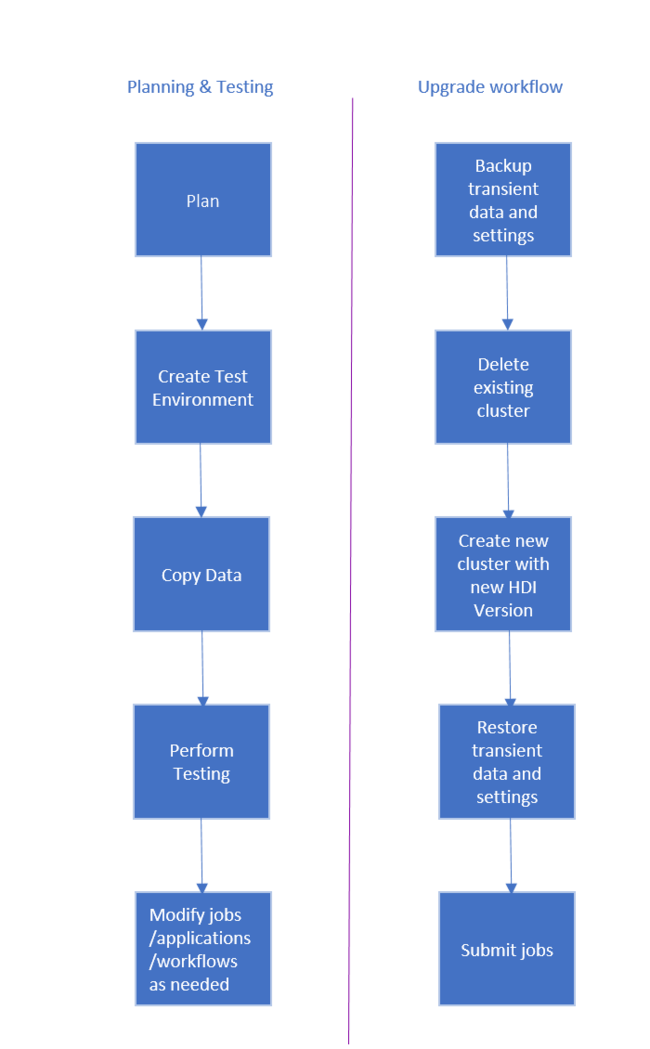
- Lea cada sección de este documento para entender los cambios que pueden ser necesarios al actualizar el clúster de HDInsight.
- Cree un clúster como entorno de control de calidad o de pruebas. Para más información sobre cómo crear un clúster, consulte Más información sobre cómo crear clústeres de HDInsight basados en Linux
- Copie los trabajos, los orígenes de datos y los receptores existentes en el nuevo entorno.
- Realice pruebas de validación para asegurarse de que los trabajos funcionan como se esperaba en el nuevo clúster.
Cuando haya comprobado que todo funciona según lo esperado, programe el tiempo de inactividad para la migración. Durante este tiempo de inactividad, realice las acciones siguientes:
- Haga copia de seguridad de todos los datos transitorios almacenados localmente en los nodos del clúster. Por ejemplo, si tiene datos que se almacenan directamente en un nodo principal.
- Elimine el clúster existente.
- Cree un clúster en la misma subred de red virtual con la versión de HDI más reciente (o compatible) con el mismo almacén de datos predeterminado que usaba el clúster anterior. Esto permitirá que el nuevo clúster siga trabajando con los datos de producción existentes.
- Importe los datos transitorios cuya copia de seguridad realizó.
- Inicie trabajos o continúe el procesamiento con el nuevo clúster.
Orientación específica de la carga de trabajo
En los siguientes documentos se proporcionan instrucciones sobre cómo migrar cargas de trabajo específicas:
Copia de seguridad y restauración
Para más información sobre la copia de seguridad y restauración de bases de datos, consulte Recuperación de una base de datos de Azure SQL Database mediante copias de seguridad de datos automatizadas.
Actualización de los escenarios
Como se mencionó anteriormente, Microsoft recomienda que los clústeres de HDInsight se migren periódicamente a la versión más reciente con el fin de aprovechar las características y correcciones nuevas. Consulte esta lista de motivos por los que es posible que solicitemos eliminar un clúster y volver a implementarlo:
- La versión del clúster está retirada o si tiene un problema de clúster que se resolvería con una versión más reciente.
- Se determina que la causa principal de un problema de clúster está relacionada con una máquina virtual de tamaño insuficiente. Consulte la configuración de nodo recomendada de Microsoft.
- Un cliente abre un caso de soporte técnico y el equipo de ingeniería de Microsoft determina que el problema ya se corrigió en una versión más reciente del clúster.
- Una base de datos de metastore predeterminada (Ambari, Hive, Oozie, Ranger) alcanzó su límite de uso. Microsoft le pide que vuelva a crear el clúster con una base de datos de metastore personalizada.
- La causa principal de un problema de clúster se debe a una operación no admitida. Entre las operaciones no admitidas comunes se encuentran las siguientes:
- Mover o agregar un servicio en Ambari. Consulte la información en los servicios de clúster en Ambari, una de las acciones disponibles en el menú Acciones del servicio es Mover [nombre del servicio]. Otra acción es Agregar [nombre del servicio] . No se admite ninguna de estas opciones.
- El paquete de Python está dañado. Los clústeres de HDInsight dependen de los entornos integrados de Python: Python 2.7 y Python 3.5. La instalación directa de paquetes personalizados en esos entornos integrados predeterminados puede producir cambios inesperados en la versión de la biblioteca e interrumpir el clúster. Aprenda a instalar de forma segura los paquetes externos personalizados de Python para las aplicaciones Spark.
- Software de terceros. Los clientes tienen la capacidad de instalar software de terceros en los clústeres de HDInsight, pero recomendaremos volver a crear el clúster si interrumpe la funcionalidad existente.
- Varias cargas de trabajo en el mismo clúster. En HDInsight 4.0, Hive Warehouse Connector necesita clústeres independientes para las cargas de trabajo de Spark y de Interactive Query. Siga estos pasos para configurar ambos clústeres en Azure HDInsight. De manera similar, la integración de Spark con HBASE requiere dos clústeres distintos.
- Cambio de la contraseña de la base de datos personalizada de Ambari. La contraseña de la base de datos de Ambari se establece al crear el clúster y actualmente no hay ningún mecanismo para actualizarla. Si un cliente implementa el clúster con una base de datos personalizada de Ambari, tiene la capacidad de cambiar la contraseña de la base de datos en la base de datos SQL, pero no hay cómo actualizar esta contraseña para un clúster de HDInsight en ejecución.
- Modificando los equilibradores de carga de HDInsight. Los balanceadores de carga de HDInsight que se implementan automáticamente para el acceso a Ambari y SSH no se deben modificar ni eliminar. Si modifica los equilibradores de carga de HDInsight y interrumpe la funcionalidad del clúster, se recomienda volver a implementar el clúster.