Mejora del rendimiento de las cargas de trabajo de Apache Spark con la memoria caché de E/S de Azure HDInsight
Nota
- La caché de E/S se admite hasta Spark 2.3 y no se admitirá en Spark 2.4 (HDInsight 4.0) ni Spark 3.1.2 (HDInsight 5.0)
La memoria caché de E/S es un servicio de almacenamiento en caché de datos para Azure HDInsight que mejora el rendimiento de trabajos de Apache Spark. La memoria caché de E/S también funciona con cargas de trabajo de Apache TEZ y Apache Hive, que se pueden ejecutar en clústeres de Apache Spark. La memoria caché de E/S usa un componente de almacenamiento en caché de código abierto denominado RubiX. RubiX es una caché de disco local para su uso con los motores de análisis de macrodatos que tienen acceso a datos desde sistemas de almacenamiento en la nube. RubiX es único entre los sistemas de almacenamiento en caché, porque utiliza unidades de estado sólido (SSD) en lugar de reservar memoria operativa para el almacenamiento en caché. El servicio de memoria caché de E/S inicia y administra servidores de los metadatos de RubiX en cada nodo de trabajo del clúster. También configura todos los servicios del clúster para su uso transparente de la memoria caché de RubiX.
La mayoría de discos SSD proporciona más de 1 GB por segundo de ancho de banda. Este ancho de banda, complementado por la memoria caché de archivos en memoria del sistema operativo, es suficiente para cargar los motores de procesamiento de cálculo de macrodatos, como Apache Spark. La memoria operativa queda disponible para que Apache Spark procese tareas muy dependientes de la memoria, como órdenes aleatorios. El hecho de disponer del uso exclusivo de la memoria operativa permite a Apache Spark alcanzar un uso óptimo de los recursos.
Nota
La memoria caché de E/S actualmente usa RubiX como un componente de almacenamiento en caché, pero esto podría cambiar en futuras versiones del servicio. Use las interfaces de la memoria caché de E/S y no tome las dependencias directamente en la implementación de RubiX. Actualmente, la memoria caché de E/S solo es compatible con Azure Blob Storage.
Ventajas de la memoria caché de E/S de Azure HDInsight
El uso de la memoria caché de E/S proporciona un aumento del rendimiento para los trabajos que leen datos desde Azure Blob Storage.
No tiene que realizar ningún cambio en los trabajos de Spark para ver un aumento del rendimiento cuando use la memoria caché de E/S. Cuando se deshabilita la memoria caché de E/S, este código de Spark podría leer datos de forma remota desde Azure Blob Storage: spark.read.load('wasbs:///myfolder/data.parquet').count(). Cuando se activa la memoria caché de E/S, la misma línea de código provoca una lectura almacenada en caché a través de la caché de E/S. En las siguientes lecturas, los datos se leen localmente desde el disco SSD. Los nodos de trabajo del clúster de HDInsight están equipados con unidades SSD conectadas localmente y dedicadas. La memoria caché de E/S de HDInsight usa estos discos SSD locales para almacenar en caché, lo cual proporciona el nivel más bajo de latencia y maximiza el ancho de banda.
Introducción
La memoria caché de E/S de Azure HDInsight está desactivada de forma predeterminada en la versión preliminar. La memoria caché de E/S está disponible en los clústeres de Spark de Azure HDInsight 3.6 +, que ejecutan Apache Spark 2.3. Para activar la caché de E/S en HDInsight 4.0, realice los pasos siguientes:
En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net, dondeCLUSTERNAMEes el nombre del clúster.Seleccione el servicio Memoria caché de E/S a la izquierda.
Seleccione Acciones (Acciones de servicio en HDI 3.6) y Activar.
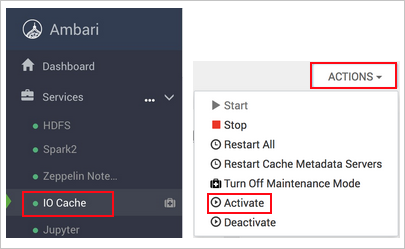
Confirme el reinicio de todos los servicios afectados en el clúster.
Nota
Aunque la barra de progreso la muestre activada, la memoria caché de E/S no está habilitada realmente hasta que reinicie los otros servicios afectados.
Solución de problemas
Es posible que aparezcan errores de espacio en disco al ejecutar trabajos de Spark después de habilitar la memoria caché de E/S. Estos errores se producen porque Spark también usa el almacenamiento en disco local para almacenar datos durante el orden aleatorio de las operaciones. Spark puede quedarse sin espacio en el disco SSD una vez que la memoria caché de E/S esté habilitada y se reduzca el espacio de almacenamiento de Spark. La cantidad de espacio utilizado por la memoria caché de E/S se establece de manera predeterminada en la mitad del espacio total de SSD. El uso de espacio en disco para la memoria caché de E/S es configurable en Ambari. Si recibe errores de espacio en disco, reduzca la cantidad de espacio de SSD usado para la memoria caché de E/S y reinicie el servicio. Para cambiar el espacio configurado para la memoria caché de E/S, realice los pasos siguientes:
En Apache Ambari, seleccione el servicio HDFS a la izquierda.
Seleccione las pestañas Configs (Configuraciones) y Advanced (Opciones avanzadas).

Desplácese hacia abajo y expanda el área Custom core-site (Personalizar sitio principal).
Busque la propiedad hadoop.cache.data.fullness.percentage.
Cambie el valor en el cuadro.
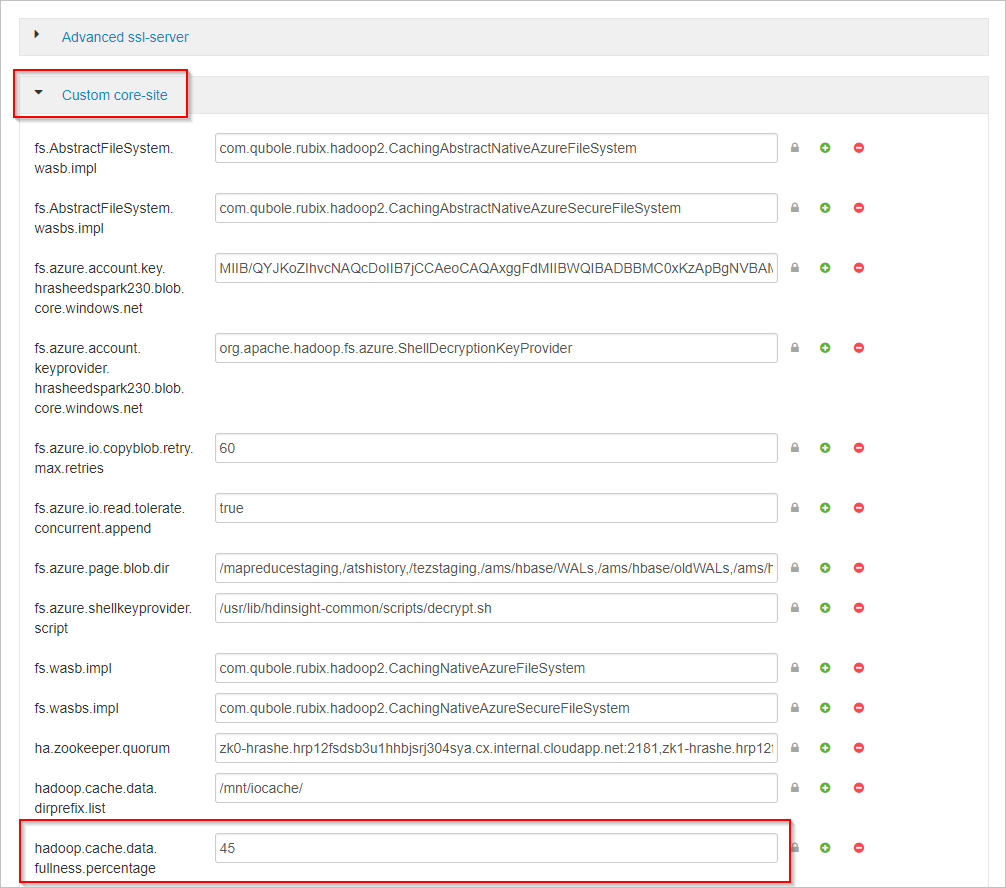
Seleccione Save (Guardar) en la esquina superior derecha.
Seleccione Restart (Reiniciar) >Restart All Affected (Reiniciar todos los servicios afectados).

Seleccione Confirm Restart All (Confirmar reinicio de todo).
Si esto no funciona, deshabilite la memoria caché de E/S.
Pasos siguientes
Obtenga más información acerca de la memoria caché de E/S, incluidas las pruebas comparativas de rendimiento en esta entrada de blog: Apache Spark jobs gain up to 9x speed up with HDInsight IO Cache (Los trabajos de Apache Spark consiguen una velocidad hasta 9 veces superior con la memoria caché de E/S de HDInsight).