Tutorial: Compilación de aplicaciones de aprendizaje automático de Apache Spark en Azure HDInsight
En este tutorial, aprenderá a usar Jupyter Notebook para compilar una aplicación de aprendizaje de automático de Azure Spark para Apache HDInsight.
MLlib es una biblioteca de aprendizaje automático adaptable de Spark que consta de utilidades y algoritmos de aprendizaje comunes (Clasificación, regresión, agrupación en clústeres, filtrado colaborativo y reducción de dimensionalidad. Además, primitivas de optimización subyacentes).
En este tutorial, aprenderá a:
- Desarrollar una aplicación de aprendizaje automático de Apache Spark
Prerrequisitos
Un clúster de Apache Spark en HDInsight. Vea Creación de un clúster de Apache Spark.
Experiencia en el uso de Jupyter Notebooks con Spark en HDInsight. Para más información, consulte Carga de datos y ejecución de consultas en un clúster de Apache Spark en Azure HDInsight.
Información acerca del conjunto de datos
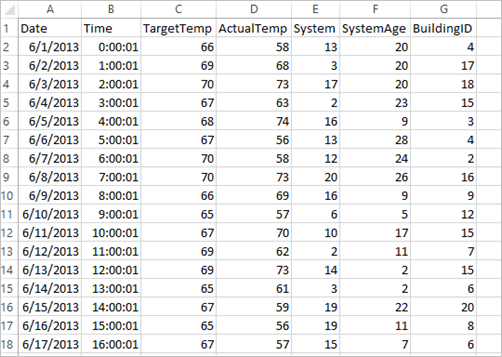
La aplicación usa los datos de ejemplo de HVAC.csv, que están disponibles en todos los clústeres de manera predeterminada. El archivo se encuentra en \HdiSamples\HdiSamples\SensorSampleData\hvac. Los datos muestran la temperatura objetivo y la temperatura real de algunos edificios que tienen sistemas de calefacción, ventilación y aire acondicionado instalados. La columna System representa el identificador del sistema y la columna SystemAge, el número de años que lleva el sistema HVAC instalado en el edificio. Se puede predecir si un edificio será más cálido o frío en función de la temperatura objetivo, dados un identificador del sistema y la antigüedad del sistema.
Desarrollo de una aplicación de aprendizaje automático de Spark mediante Spark MLlib
En esta aplicación se usa una canalización de Machine Learning de Spark para realizar una clasificación de documentos. Las canalizaciones de Machine Learning proporcionan un conjunto uniforme de API de alto nivel basadas en DataFrames. Mediante DataFrames, los usuarios pueden crear y ajustar prácticas canalizaciones de aprendizaje automático. En la canalización, se divide el documento en palabras, se convierten las palabras en un vector numérico de característica y finalmente se genera un modelo de predicción que use los vectores de característica y las etiquetas. Realice los siguientes pasos para crear la aplicación:
Cree un cuaderno de Jupyter Notebook mediante el kernel de PySpark. Para obtener instrucciones, consulte Creación de un archivo de Jupyter Notebook.
Importe los tipos necesarios para este escenario. Pegue el siguiente fragmento de código en una celda vacía y presione MAYÚS + ENTRAR.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayCargue los datos (hvac.csv), analícelos y úselos para entrenar el modelo.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()En el fragmento de código, se define una función que compara la temperatura real con la temperatura de destino. Si la temperatura real es mayor, el edificio está cálido, lo que viene indicado por el valor 1.0. De lo contrario, el edificio está frío, lo que se indica con el valor 0.0.
Configure la canalización de aprendizaje automático de Spark, que consta de tres fases:
tokenizer,hashingTFylr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])Para más información acerca de las canalizaciones y cómo funcionan, consulte Canalización de aprendizaje automático de Apache Spark.
Ajuste la canalización al documento de formación.
model = pipeline.fit(training)Compruebe el documento de aprendizaje para controlar el progreso con la aplicación.
training.show()La salida es parecida a esta:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+La comparación de la salida con el archivo CSV sin procesar. Por ejemplo, la primera fila del archivo CSV tiene estos datos:

Observe que la temperatura real es menor que la temperatura objetivo, lo que indica que el edificio está frío. El valor de label en la primera fila es 0.0, lo que significa que la temperatura del edificio no es cálida.
Prepare un conjunto de datos con el que ejecutar el modelo entrenado. Para ello, pase un identificador del sistema y la antigüedad del sistema (indicada como SystemInfo en la salida de entrenamiento). El modelo predice si el edificio con ese identificador del sistema y esa antigüedad del sistema será más cálido (indicado por 1.0) o más fresco (indicado por 0.0).
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Por último, realice predicciones basadas en los datos de prueba.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)La salida es parecida a esta:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Observe la primera fila de la predicción. En un sistema HVAC con el identificador 20 y una antigüedad de 25 años, el edificio tiene una temperatura cálida (prediction=1.0). El primer valor de DenseVector (0,49999) corresponde a la predicción 0,0 y el segundo, (0,5001), corresponde a la predicción 1,0. En la salida, aunque el segundo valor solo es levemente superior, el modelo muestra prediction=1.0.
Cierre el cuaderno para liberar los recursos. Para ello, en el menú File (Archivo) del cuaderno y seleccione Close and Halt (Cerrar y detener). Con esta acción se cerrará el cuaderno.
Uso de la biblioteca scikit-learn de Anaconda para el aprendizaje automático de Spark
Los clústeres Apache Spark de HDInsight incluyen bibliotecas de Anaconda. También incluyen la biblioteca scikit-learn para el aprendizaje automático. La biblioteca también contiene diversos conjuntos de datos que se pueden usar para crear aplicaciones de ejemplo directamente desde Jupyter Notebook. Para obtener ejemplos sobre el uso de la biblioteca scikit-learn, consulte https://scikit-learn.org/stable/auto_examples/index.html.
Limpieza de recursos
Si no va a seguir usando esta aplicación, elimine el clúster que creó mediante los siguientes pasos:
Inicie sesión en Azure Portal.
En el cuadro Búsqueda en la parte superior, escriba HDInsight.
Seleccione Clústeres de HDInsight en Servicios.
En la lista de clústeres de HDInsight que aparece, seleccione el signo ... situado junto al clúster que ha creado para este tutorial.
Seleccione Eliminar. Seleccione Sí.
Pasos siguientes
En este tutorial, ha aprendido a usar Jupyter Notebook para compilar una aplicación de aprendizaje de automático de Azure Spark para Apache HDInsight. Para aprender a usar IntelliJ IDEA para trabajos de Spark, pase al siguiente tutorial.