Uso de Apache Spark MLlib para compilar una aplicación de aprendizaje automático y analizar un conjunto de datos
Aprenda a usar Apache Spark MLlib para crear una aplicación de aprendizaje automático. La aplicación realiza análisis predictivos en un conjunto de datos abierto. De las bibliotecas de aprendizaje automático integradas de Spark, en este ejemplo se usa una clasificación mediante una regresión logística.
MLlib es una biblioteca básica de Spark que proporciona numerosas utilidades para las tareas de aprendizaje automático, por ejemplo:
- clasificación
- Regresión
- Agrupación en clústeres
- Modelado
- Descomposición en valores singulares (SVD) y Análisis de los componentes principales (PCA)
- Comprobación de hipótesis y cálculo de estadísticas de ejemplo
Comprensión de la clasificación y la regresión logística
Clasificación, una tarea habitual en el aprendizaje automático, es el proceso de ordenación de datos de entrada en categorías. Es trabajo de un algoritmo de clasificación averiguar cómo asignar "etiquetas" a los datos de entrada que usted proporciona. Por ejemplo, podría pensar en un algoritmo de aprendizaje automático que acepte información bursátil como entrada. A continuación, divide las acciones en dos categorías: las acciones que se deben vender y las acciones que se deben mantener.
La regresión logística es el algoritmo que se usa para la clasificación. La API de regresión logística de Spark es útil para la clasificación binaria, o para la clasificación de datos de entrada en uno de los dos grupos. Para obtener más información acerca de la regresión logística, consulte Wikipedia.
En resumen, el proceso de regresión logística produce una función logística. Utilice la función para predecir la probabilidad de que un vector de entrada pertenezca a un grupo u otro.
Ejemplo de análisis predictivo de datos de inspección de alimentos
En este ejemplo, se usa Spark para realizar un análisis predictivo de los datos de inspección de alimentos (Food_Inspections1.csv). Los datos adquiridos a través de City of Chicago Data Portal. Este conjunto de datos contiene información sobre las inspecciones a los establecimientos alimenticios que se llevaron a cabo en Chicago. Incluye información sobre cada establecimiento, las infracciones detectadas (de haber) y los resultados de la inspección. El archivo de datos CSV ya está disponible en la cuenta de almacenamiento asociada al clúster, en /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
En los pasos siguientes, desarrolla un modelo para ver lo que se necesita para pasar o producir un error en una inspección alimentaria.
Creación de una aplicación de aprendizaje automático de Apache Spark MLlib
Cree un cuaderno de Jupyter Notebook mediante el kernel de PySpark. Para obtener instrucciones, consulte Creación de un archivo de Jupyter Notebook.
Importe los tipos necesarios para esta aplicación. Copie y pegue el siguiente código en una celda vacía y presione Mayús + Entrar.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *Debido a la existencia del kernel PySpark, no necesitará crear ningún contexto explícitamente. Los contextos de Spark y Hive se crean automáticamente al ejecutar la primera celda de código.
Construcción de una trama de datos de entrada
Use el contexto de Spark para extraer los datos CSV sin procesar e incorporarlos en la memoria como texto no estructurado. A continuación, use la biblioteca CSV de Python para analizar cada línea de los datos.
Ejecute las líneas siguientes para crear un conjunto de datos distribuido resistente (RDD) mediante la importación y el análisis de los datos de entrada.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Ejecute el siguiente código para recuperar una fila del RDD, a fin de poder echar un vistazo al esquema de datos:
inspections.take(1)La salida es la siguiente:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]La salida nos da una idea del esquema del archivo de entrada. Incluye el nombre de cada establecimiento y el tipo de establecimiento. Además, la dirección, los datos de las inspecciones y la ubicación, entre otras cosas.
Ejecute el siguiente código para crear una trama de datos (df) y una tabla temporal (CountResults) con unas pocas columnas que son útiles para el análisis predictivo.
sqlContextse usa para realizar las transformaciones con datos estructurados.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')Las cuatro columnas de interés de el dataframe son ID (identificador), name (nombre), results (resultados) y violations (infracciones).
Ejecute el código siguiente para obtener una pequeña muestra de los datos:
df.show(5)La salida es la siguiente:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Comprensión de los datos
Vamos a empezar a hacernos una idea de lo que contiene el conjunto de datos.
Ejecute el siguiente código para mostrar los valores distintos en la columna results (resultados):
df.select('results').distinct().show()La salida es la siguiente:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Ejecute el siguiente código para visualizar la distribución de estos resultados:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsLa instrucción mágica
%%sqlseguida de-o countResultsdfgarantiza que el resultado de la consulta persista localmente en el servidor de Jupyter (normalmente, el nodo principal del clúster). El resultado se conserva como una trama de datos Pandas con el nombre especificado countResultsdf. Para más información sobre la instrucción mágica%%sql, así como otras instrucciones mágicas disponibles con el kernel de PySpark, consulte Kernels disponibles para cuadernos de Jupyter Notebook con clústeres de Apache Spark en HDInsight.La salida es la siguiente:
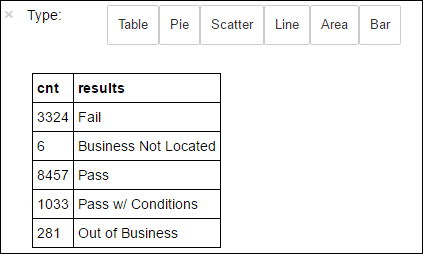
También puede utilizar Matplotlib, una biblioteca que se usa para construir la visualización de datos, para crear un gráfico. Dado que el gráfico debe crearse a partir de la trama de datos localmente persistente countResultsdf, el fragmento de código debe comenzar con la instrucción mágica
%%local. Esta acción garantiza que el código se ejecuta localmente en el servidor de Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Para predecir un resultado de inspección de alimentos, debe desarrollar un modelo basado en las infracciones. Puesto que la regresión logística es un método de clasificación binaria, tiene sentido agrupar los datos de los resultados en dos categorías: Fail y Pass:
Pass (pasado)
- Pass (pasado)
- Pass w/ conditions (superado con condiciones)
Incorrecto
- Incorrecto
Discard (Descartar)
- Business not located (no se encontró el negocio)
- Out of Business (negocio cerrado)
Los datos con los demás resultados, como "Business Not Located" (No se encontró el negocio) o "Out of Business" (Negocio cerrado), no son útiles y constituyen un pequeño porcentaje de los resultados.
Ejecute el siguiente código para convertir la trama de datos existente (
df) en una trama de datos nueva, donde cada inspección se representa como un par de etiquetas de infracción. En este caso, una etiqueta de0.0representa un resultado de "no superado", una etiqueta de1.0representa un resultado de "pasado", y una etiqueta de-1.0representa resultados distintos de esos dos resultados.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Ejecute el siguiente código para mostrar una fila de los datos etiquetados:
labeledData.take(1)La salida es la siguiente:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Creación de un modelo de regresión logística a partir de la trama de datos de entrada
La tarea final consiste en convertir los datos etiquetados. Convierta los datos en un formato analizado por regresión logística. La entrada a un algoritmo de regresión logística necesita un conjunto de pares de etiqueta-vector de característica. Donde el "vector de característica" es un vector de números que representa el punto de entrada. Por lo tanto, debemos convertir la columna "violations", que está semiestructurada y contiene muchos comentarios de texto sin formato. Convierta la columna en una matriz de números reales que una máquina pueda entender fácilmente.
Un enfoque de aprendizaje automático estándar para procesar lenguaje natural es asignar cada palabra distinta a un índice. Después, se pasa un vector al algoritmo de aprendizaje automático. De este modo, el valor de cada índice contiene la frecuencia relativa de esa palabra en la cadena de texto.
MLlib proporciona una forma sencilla de realizar esta operación. En primer lugar, vamos a tratar como tokens todas las cadenas de infracciones para obtener las palabras de cada cadena. Luego, use un HashingTF para convertir cada conjunto de tokens en un vector de característica que se pueda pasar al algoritmo de regresión logística para construir un modelo. Llevaremos a cabo todos estos pasos en secuencia mediante una canalización.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Evaluación del modelo con otro conjunto de datos
Puede usar el modelo que ha creado anteriormente para predecir cuáles son los resultados de las nuevas inspecciones. Las predicciones se basan en las infracciones observadas. Este modelo se ha probado en el conjunto de datos Food_Inspections1.csv. Puede usar un segundo conjunto de datos, Food_Inspections2.csv, para evaluar la solidez de este modelo con nuevos datos. Este segundo conjunto de datos (Food_Inspections2.csv) está en el contenedor de almacenamiento predeterminado asociado al clúster.
Ejecute el siguiente fragmento de código para crear una trama de datos, predictionsDf, que contiene la predicción generada por el modelo. El fragmento de código también crea una tabla temporal, llamada Predictions, basada en la trama de datos.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsLa salida debe ser parecida al siguiente texto:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Examine una de las predicciones. Ejecute este fragmento de código:
predictionsDf.take(1)Hay una predicción para la primera entrada en el conjunto de datos de prueba.
El método
model.transform()aplica la misma transformación a todos los datos nuevos que tengan el mismo esquema y llega a una predicción sobre cómo clasificar los datos. Puede hacer algunas estadísticas para tener una idea del acierto de las predicciones:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")La salida tendrá un aspecto similar al siguiente:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateEl uso de la regresión logística con Spark proporciona un modelo de la relación entre las descripciones de las infracciones en inglés, además de si un negocio determinado superaría o no una inspección alimentaria.
Creación de una representación visual de la predicción
Ahora se puede crear una visualización final para facilitar el análisis de los resultados de esta prueba.
Primero se extraen los distintos resultados y predicciones de la tabla temporal Predictions que se creó anteriormente. Las siguientes consultas separan la salida en distintos grupos: true_positive, false_positive, true_negative y false_negative. En las consultas siguientes, se desactiva la visualización mediante
-qy se guarda también la salida (con-o) como tramas de datos que se usen con la instrucción mágica%%local.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Por último, utilice el siguiente fragmento de código para generar el gráfico mediante Matplotlib.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Debería ver la siguiente salida:
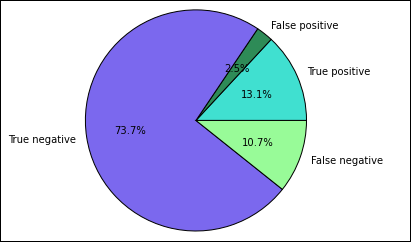
En este gráfico, un resultado "positivo" hace referencia a la inspección de alimentos no superada, mientras que un resultado negativo hace referencia a una inspección pasada.
Cierre del cuaderno
Después de ejecutar la aplicación, debe apagar el cuaderno para liberar los recursos. Para ello, en el menú File (Archivo) del cuaderno y seleccione Close and Halt (Cerrar y detener). Con esta acción se cerrará el cuaderno.