Uso de cuadernos de Apache Zeppelin con un clúster Apache Spark en Azure HDInsight
Los clústeres de HDInsight Spark incluyen cuadernos de Apache Zeppelin. Use los cuadernos para ejecutar los trabajos de Apache Spark. En este artículo, aprenderá a usar Zeppelin Notebook en un clúster de HDInsight.
Prerrequisitos
- Un clúster de Apache Spark en HDInsight. Para obtener instrucciones, vea Creación de clústeres Apache Spark en HDInsight de Azure.
- El esquema de URI para el almacenamiento principal de clústeres. El esquema sería
wasb://para Azure Blob Storage,abfs://para Azure Data Lake Storage Gen2 oadl://para Azure Data Lake Storage Gen1. Si se habilita la transferencia segura para Blob Storage, el identificador URI seríawasbs://. Para más información, consulte Requerir transferencia segura en Azure Storage.
Inicio de un cuaderno de Apache Zeppelin
Desde la Introducción el clúster de Spark, seleccione el cuaderno de Zeppelin en los paneles de clúster. Escriba las credenciales de administrador del clúster.
Nota
También puede comunicarse con su equipo portátil ligero Zeppelin en el clúster si abre la siguiente dirección URL en el explorador. Reemplace CLUSTERNAME por el nombre del clúster:
https://CLUSTERNAME.azurehdinsight.net/zeppelinCree un nuevo notebook. En el panel del encabezado, vaya a Notebook>Create new note (Cuaderno > Crear nueva nota).
Especifique un nombre para el cuaderno y haga clic en Create Note (Crear nota).
Por otro lado, asegúrese de que en el encabezado del cuaderno aparece el estado conectado. Esto se indica mediante un punto verde que se encuentra en la esquina superior derecha.

Cargue los datos de ejemplo en una tabla temporal. Cuando cree un clúster de Spark en HDInsight, el archivo de datos de ejemplo
hvac.csvse copia en la cuenta de almacenamiento asociada en\HdiSamples\SensorSampleData\hvac.En el párrafo vacío que se crea de manera predeterminada en el nuevo cuaderno, pegue el siguiente fragmento.
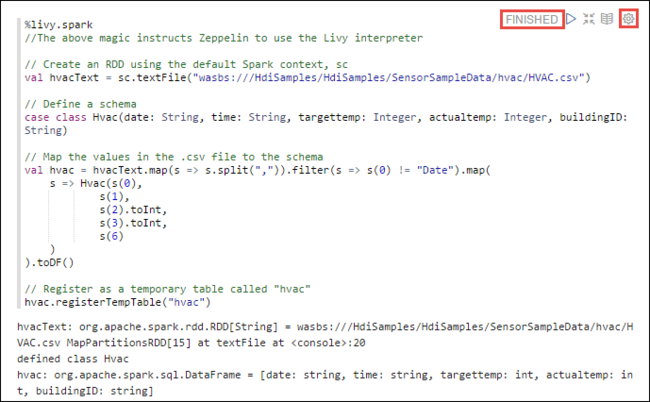
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Presione MAYÚS+ENTRAR o seleccione el botón Reproducir del párrafo para ejecutar el fragmento de código. El estado en la esquina derecha del párrafo debería avanzar de READY (Listo), PENDING (Pendiente) o RUNNING (En ejecución) a FINISHED (Finalizado). El resultado se muestra en la parte inferior del mismo párrafo. La captura de pantalla es similar a esta imagen:
También puede proporcionar un título para cada párrafo. Desde la esquina derecha del párrafo, seleccione el ícono Settings (Configuración) con forma de rueda dentada y seleccione Show title (Mostrar título).
Nota
El intérprete %spark2 no se admite en los cuadernos de Zeppelin en todas las versiones de HDInsight y el intérprete %sh no se admite en HDInsight 4.0 y versiones posteriores.
Ahora puede ejecutar instrucciones de Spark SQL en la tabla
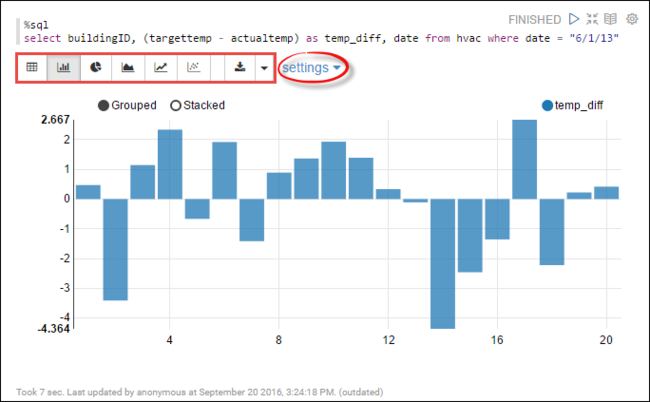
hvac. Pegue la siguiente consulta en un nuevo párrafo. La consulta recupera el identificador del edificio. También la diferencia entre la temperatura objetivo y la real para cada edificio en una fecha determinada. Presione MAYÚS + ENTRAR.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"La instrucción %sql del principio le indica al cuaderno que utilice el intérprete de Livy Scala.
Seleccione el icono del gráfico de barras para cambiar la visualización. configuración aparece después de haber seleccionado Gráfico de barras y le permite elegir Claves y Valores. En la captura de pantalla siguiente se muestra el resultado.
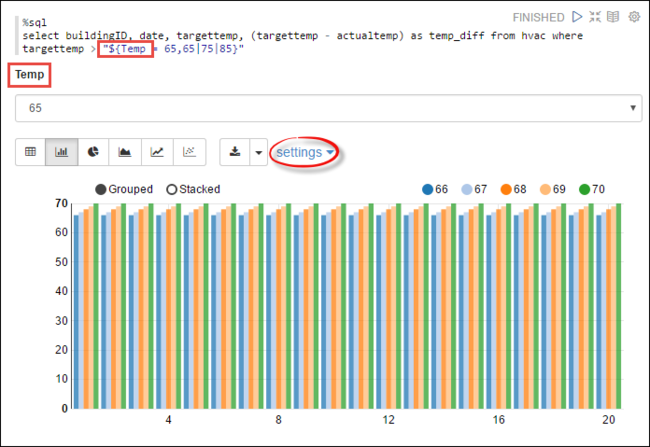
También puede ejecutar instrucciones Spark SQL usando variables en la consulta. El siguiente fragmento de código muestra cómo definir una variable
Tempen la consulta con los valores posibles con los que quiere hacer la consulta. Cuando ejecuta la consulta por primera vez, se rellena una lista desplegable automáticamente con los valores especificados para la variable.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Pegue este fragmento de código en un nuevo párrafo y presione MAYÚS + ENTRAR. A continuación, seleccione 65 en la lista desplegable Temp.
Seleccione el icono del gráfico de barras para cambiar la visualización. Seguidamente, seleccione configuración y realice los siguientes cambios:
Grupos: agregue targettemp.
Valores: 1. Quite la fecha. 2. Agregue temp_diff. 3. Cambie el agregador de SUM a AVG.
En la captura de pantalla siguiente se muestra el resultado.
Uso de paquetes externos con el cuaderno
El cuaderno de Zeppelin Notebook en un clúster Apache Spark de HDInsight puede usar paquetes externos que haya aportado la comunidad y que no estén incluidos en el clúster. Busque el repositorio de Maven para obtener una lista completa de los paquetes que están disponibles. También puede obtener una lista de paquetes disponibles de otras fuentes. Por ejemplo, dispone de la lista completa de los paquetes externos aportados por la comunidad en Spark Packages(Paquetes Spark).
En este artículo, aprenderá a utilizar el paquete spark-csv con el cuaderno de Jupyter Notebook.
Abra la configuración del intérprete. Desde la esquina superior derecha, seleccione el nombre de usuario registrado y, a continuación, seleccione Interpreter (Intérprete).

Desplácese hasta livy2 y seleccione la opción de editar.

Vaya a la clave
livy.spark.jars.packagesy establezca su valor en el formatogroup:id:version. Por ejemplo, si desea usar el paquete spark-csv, debe establecer el valor de la clave encom.databricks:spark-csv_2.10:1.4.0.
Seleccione Guardar y luego Aceptar para reiniciar el intérprete de Livy.
Si desea saber cómo acceder al valor de la clave especificada anteriormente, siga estos pasos.
a. Busque el paquete en el repositorio de Maven. En este artículo, hemos utilizado spark-csv.
b. En el repositorio, recopile los valores de GroupId, ArtifactId y Version.

c. Concatene los tres valores separados por dos puntos ( : ).
com.databricks:spark-csv_2.10:1.4.0
¿Dónde se guardan los cuadernos de Zeppelin Notebook?
Los cuadernos de Zeppelin Notebook se guardan en los nodos principales del clúster. Por tanto, si se elimina el clúster, también se eliminarán los cuadernos. Si desea guardar los cuadernos para utilizarlos más adelante en otros clústeres, debe exportarlos cuando haya terminado de ejecutar los trabajos. Para exportar un cuaderno, haga clic en el icono Export (Exportar), tal y como se muestra en la imagen siguiente.
De este modo, el cuaderno se guarda como un archivo JSON en la ubicación de descarga.
Nota:
En HDI 4.0, la ruta de acceso del directorio del cuaderno de Zeppelin es
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/P. ej. /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
Donde como en HDI 5.0 y en las versiones posteriores esta ruta de acceso es diferente
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/P. ej. /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
El nombre de archivo almacenado es diferente en HDI 5.0. Se almacena como
<notebook_name>_<sessionid>.zplnP. ej. testzeppelin_2JJK53XQA.zpln
En HDI 4.0, el nombre de archivo es solo note.json y está almacenado en el directorio session_id.
P. ej. /2JMC9BZ8X/note.json
HDI Zeppelin siempre guarda el cuaderno en la ruta de acceso
/usr/hdp/<version>/zeppelin/notebook/del disco local hn0.Si quiere que el cuaderno esté disponible incluso después de que se haya eliminado el clúster, puede intentar usar Azure File Storage (para lo que usará el protocolo SMB) y vincularlo a una ruta de acceso local. Para más información, consulte Montaje de un recurso compartido de archivos de Azure de SMB en Linux.
Después de montarlo, puede modificar la configuración de zeppelin.notebook.dir a la ruta de acceso montada en la interfaz de usuario de Ambari.
- No se recomienda el recurso compartido de archivos SMB como almacenamiento de GitNotebookRepo para la versión 0.10.1 de Zeppelin
Uso de Shiro para configurar el acceso a los intérpretes de Zeppelin en clústeres de Enterprise Security Package (ESP)
Como se indicó anteriormente, el intérprete %sh no se admite desde HDInsight 4.0 en adelante. Además, dado que el intérprete %sh introduce posibles problemas de seguridad, como el acceso a keytabs mediante comandos de shell, se ha quitado también de los clústeres de ESP de HDInsight 3.6. Es decir, el intérprete %sh no está disponible cuando se hace clic en Crear nueva nota ni en la interfaz de usuario del intérprete de forma predeterminada.
Los usuarios de dominio con privilegios pueden usar el archivo Shiro.ini para controlar el acceso a la interfaz de usuario del intérprete. Solo estos usuarios pueden crear nuevos intérpretes %sh y establecer permisos en cada nuevo intérprete %sh. Para controlar el acceso mediante el archivo shiro.ini, siga estos pasos:
Defina un nuevo rol con un nombre de grupo de dominio existente. En el ejemplo siguiente,
adminGroupNamees un grupo de usuarios con privilegios de AAD. No use caracteres especiales ni espacios en blanco en el nombre del grupo. Los caracteres después de=conceden los permisos para este rol.*significa que el grupo tiene permisos completos.[roles] adminGroupName = *Agregue el nuevo rol para el acceso a los intérpretes de Zeppelin. En el ejemplo siguiente, a todos los usuarios de
adminGroupNamese les concede acceso a los intérpretes de Zeppelin y pueden crear intérpretes nuevos. Puede colocar varios roles entre corchetes enroles[], separados por comas. A continuación, los usuarios que tienen los permisos necesarios pueden acceder a los intérpretes de Zeppelin.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Ejemplo de shiro.ini para varios grupos de dominios:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Administración de sesiones de Livy
El primer párrafo de código del cuaderno de Zeppelin crea una nueva sesión de Livy en el clúster. Esta sesión se compartirá con todos los cuadernos de Zeppelin Notebook que cree en el futuro. Si la sesión Livy se elimina por cualquier motivo, los trabajos no se ejecutarán desde el cuaderno de Zeppelin Notebook.
En este caso, debe seguir los pasos que se indican a continuación para poder ejecutar trabajos desde un cuaderno de Zeppelin Notebook.
Reinicie el intérprete de Livy desde el cuaderno de Zeppelin Notebook. Para ello, abra la configuración del intérprete haciendo clic en el nombre del usuario conectado que encontrará en la esquina superior derecha y después en Interpreter (Intérprete).
Desplácese hasta livy2 y seleccione la opción para reiniciar.
Ejecute una celda de código desde el cuaderno de Zeppelin Notebook existente. Este código crea una nueva sesión de Livy en el clúster de HDInsight.
Información general
Validar servicio
Para validar el servicio desde Ambari, navegue hasta https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary, donde CLUSTERNAME es el nombre del clúster.
Para validar el servicio desde una línea de comandos, use SSH en el nodo principal. Cambie el usuario a Zeppelin con el comando sudo su zeppelin. Comandos de estado:
| Get-Help | Descripción |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
Estado del servicio. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Versión del servicio. |
ps -aux | grep zeppelin |
Identificar PID. |
Ubicaciones de registro
| Servicio | Path |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| Registros del servidor | /var/log/zeppelin |
Intérprete de configuración, Shiro, site.xml, log4j |
/usr/hdp/current/zeppelin-server/conf o /etc/zeppelin/conf |
| Directorio de PID | /var/run/zeppelin |
Habilitación del registro de depuración
Vaya a
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary, donde CLUSTERNAME es el nombre del clúster.Navegue hasta CONFIGs>Advanced zeppelin-log4j-properties>log4j_properties_content.
Cambie
log4j.appender.dailyfile.Threshold = INFOporlog4j.appender.dailyfile.Threshold = DEBUG.Agregue
log4j.logger.org.apache.zeppelin.realm=DEBUG.Guarde los cambios y reinicie el servicio.