Tutorial: Una solución integral con Azure Machine Learning y IoT Edge
Se aplica a:![]() IoT Edge 1.1
IoT Edge 1.1
Importante
IoT Edge 1.1: la fecha de finalización del soporte técnico fue el 13 de diciembre de 2022. Consulte la página del ciclo de vida de productos de Microsoft para obtener información sobre cómo se admite este producto, servicio, tecnología o API. Para obtener más información sobre cómo actualizar a la versión más reciente de IoT Edge, vea Actualizar IoT Edge.
Con frecuencia, las aplicaciones de IoT buscan aprovechar las ventajas de la nube inteligente y la inteligencia perimetral. En este tutorial, te guiaremos por el entrenamiento de un modelo de Machine Learning con datos recopilados de los dispositivos de IoT en la nube, la implementación de ese modelo en IoT Edge y el mantenimiento y ajuste periódicos del modelo.
Nota
Los conceptos de este conjunto de tutoriales se aplican a todas las versiones de IoT Edge, pero el dispositivo de ejemplo que se crea para probar el escenario utiliza la versión 1.1 de IoT Edge.
El objetivo principal de este tutorial es presentar el procesamiento de datos de IoT con aprendizaje automático, específicamente en el borde. Si bien se abordan muchos aspectos de un flujo de trabajo de aprendizaje automático general, este tutorial no está pensado como una introducción detallada del aprendizaje automático. Como caso en el punto, no intentamos crear un modelo altamente optimizado para el caso de uso: solo hacemos lo suficiente para ilustrar el proceso de creación y uso de un modelo viable para el procesamiento de datos de IoT.
En esta sección del tutorial se tratan los siguientes aspectos:
- Los requisitos previos para completar las siguientes secciones del tutorial.
- El público de destino del tutorial.
- El caso de uso que el tutorial aborda.
- El proceso general que el tutorial sigue para completar el caso de uso.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Prerrequisitos
Para completar el tutorial, necesitas acceso a una suscripción a Azure en la que tengas derechos para crear recursos. Varios de los servicios usados en este tutorial incurrirán en cargos de Azure. Si no dispones de una suscripción a Azure, es posible que puedas empezar a trabajar con un cuenta gratuita de Azure.
También necesitas una máquina con PowerShell instalado, donde puede ejecutar scripts para configurar una máquina virtual de Azure como equipo de desarrollo.
En el documento se usan los conjuntos de herramientas siguientes:
Azure IoT Hub para la captura de datos.
Azure Notebooks como front-end principal para la preparación de datos y la experimentación de aprendizaje automático. Ejecutar código de Python en un cuaderno en un subconjunto de los datos de ejemplo es una excelente manera de obtener una respuesta rápida iterativa e interactiva durante la preparación de datos. Las instancias de Jupyter Notebook también pueden usarse para preparar scripts para ejecutarlos a escala en un back-end de proceso.
Azure Machine Learning como back-end para el aprendizaje automático a escala y para generación de imágenes de aprendizaje automático. Controlamos el back-end de Azure Machine Learning mediante scripts preparados y probados en instancias de Jupyter Notebook.
Azure IoT Edge para aplicación fuera de la nube de una imagen de aprendizaje automático.
Evidentemente, hay otras opciones disponibles. En determinados escenarios, por ejemplo, IoT Central puede usarse como alternativa sin código para capturar datos iniciales de aprendizaje de dispositivos IoT.
Público y roles de destino
Este conjunto de artículos está pensado para desarrolladores sin experiencia previa en el desarrollo de IoT ni aprendizaje automático. Implementar el aprendizaje automático en el borde requiere un conocimiento de cómo conectar una amplia gama de tecnologías. Por lo tanto, en este tutorial se explica un escenario integral completo para demostrar una manera de combinar estas tecnologías para lograr una solución de IoT. En un entorno real, estas tareas podrían estar distribuidas entre varias personas con especializaciones diferentes. Por ejemplo, los desarrolladores se centrarían en el código de dispositivo o de nube, mientras que los científicos de datos diseñarían los modelos de análisis. Para permitir que un desarrollador individual complete correctamente este tutorial, hemos proporcionado una guía complementaria con información y vínculos a información adicional que esperamos sea suficiente para comprender qué se está haciendo y por qué.
Como alternativa, puede asociarse con compañeros de trabajo con diferentes roles para seguir el tutorial juntos, para aportar su experiencia completa y aprender en equipo cómo funcionan las cosas.
En cualquier caso, para ayudar a orientar a los lectores, cada artículo en este tutorial indica el rol del usuario. Estos roles incluyen:
- Desarrollo de nube (incluido un desarrollador de nube que se trabaja en calidad de DevOps)
- Análisis de datos
Caso de uso: Mantenimiento predictivo
Este escenario se basa en un caso de uso presentado en la conferencia Prognostics and Health Management (PHM08) en 2008. El objetivo es predecir la vida útil restante (RUL) de un conjunto de motores de avión turbofán. Estos datos se generaron mediante C-MAPSS, la versión comercial del software MAPSS (simulación de sistema modular de aeropropulsión). Este software proporciona un entorno flexible de simulación de motor turbofán para simular fácilmente los parámetros de estado, control y del motor.
Los datos usados en este tutorial se toman del conjunto de datos de simulación de degradación de motores turbofán.
Del archivo Léame:
Escenarios experimentales
Los conjuntos de datos constan de varias series temporales multivariantes. Cada conjunto de datos se divide en subconjuntos de entrenamiento y prueba. Cada serie temporal es de un motor diferente, es decir, los datos se pueden considerar de una flota de motores del mismo tipo. Cada motor se inicia con diferentes grados de desgaste inicial y variación de fabricación desconocida para el usuario. Este desgaste y variación se consideran normales, es decir, no se consideran una condición de error. Hay tres configuraciones operativas que tienen un efecto considerable en el rendimiento del motor. Estas configuraciones también se incluyen en los datos. Los datos están contaminados con ruido de sensores.
El motor funciona con normalidad al comienzo de cada serie temporal y desarrolla un error en algún momento durante la serie. En el conjunto de entrenamiento, el error aumenta en magnitud hasta convertirse en error del sistema. En el conjunto de prueba, la serie temporal finaliza un tiempo antes de un error del sistema. El objetivo de la competición es predecir el número de ciclos operativos restantes antes de un error en el conjunto de pruebas, es decir, el número de ciclos operativos después del último ciclo en los que el motor seguirá en funcionamiento. También proporciona un vector de valores verdaderos de vida útil restante (RUL) para los datos de prueba.
Dado que los datos se han publicado para una competición, se han publicado de manera independiente varios enfoques para derivar los modelos de Machine Learning. Hemos encontrado que estudiar los ejemplos es útil para comprender el proceso y el razonamiento involucrados en la creación de un modelo de Machine Learning específico. Por ejemplo, consulte:
El modelo de predicción de errores de motor de avión por el usuario de GitHub jancervenka.
La degradación del motor de turbofán por el usuario de GitHub hankroark.
Proceso
En la siguiente imagen se ilustran los pasos generales que se siguen en este tutorial:
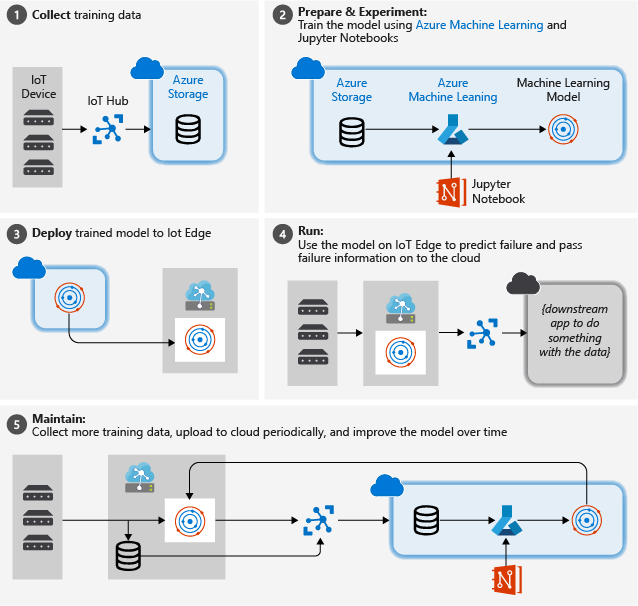
Recolección de datos de entrenamiento: El proceso comienza con la recopilación de datos de entrenamiento. En algunos casos, los datos ya se han recopilado y están disponibles en una base de datos, o en forma de archivos de datos. En otros casos, especialmente para escenarios de IoT, los datos deben recopilarse de sensores y dispositivos IoT y almacenarse en la nube.
Se supone que no tienes una colección de motores turbofán, por lo que los archivos del proyecto incluyen un simulador de dispositivos simple que envía los datos de los dispositivos de la NASA a la nube.
Prepara los datos. En la mayoría de los casos, los datos sin procesar según se recopilan de los dispositivos y sensores requerirán preparación para el aprendizaje automático. Este paso puede implicar la limpieza de datos, volver a formatear los datos o un procesamiento previo para inyectar información adicional para que el aprendizaje automático pueda comenzar a usar.
Para los datos de motores de avión, la preparación de los datos implica calcular los tiempos explícitos hasta que se produce un error para cada punto de datos en el ejemplo, según las observaciones reales de los datos. Esta información permite que el algoritmo de aprendizaje automático busque correlaciones entre los patrones de datos reales de los sensores y el tiempo de vida restante esperado del motor. Este paso es muy específico del dominio.
Compila un modelo de Machine Learning. En función de los datos preparados, podemos experimentar con distintos algoritmos y parametrizaciones de aprendizaje automático para entrenar los modelos y comparar los resultados entre sí.
En este caso, para las pruebas vamos a comparar el resultado previsto calculado por el modelo con el resultado real observado en un conjunto de motores. En Azure Machine Learning, podemos administrar las distintas iteraciones de modelos que se crean en un registro de modelo.
Implementa el modelo. Una vez que tenemos un modelo que satisface los criterios de éxito, podemos pasar a la implementación. Esto involucra encapsular el modelo en una aplicación de servicio web que pueda consumir datos mediante llamadas REST y devolver los resultados del análisis. La aplicación de servicio web luego se empaqueta en un contenedor de Docker que, a su vez, puede implementarse en la nube o como un módulo de IoT Edge. En este ejemplo, nos centramos en la implementación de IoT Edge.
Mantén y perfecciona el modelo. Nuestro trabajo no termina una vez que se implementa el modelo. En muchos casos, queremos seguir recopilando datos y cargar esos datos periódicamente a la nube. A continuación, podemos usar estos datos para volver a entrenar y refinar nuestro modelo, que luego podemos volver a implementar en IoT Edge.
Limpieza de recursos
Este tutorial forma parte de una serie en la que cada artículo complementa el trabajo realizado en los anteriores. No borre ningún recurso hasta que complete el tutorial final.
Pasos siguientes
Este tutorial se divide en las secciones siguientes:
- Configuración de la máquina de desarrollo y los servicios de Azure.
- Generación de los datos de entrenamiento para el módulo de aprendizaje automático.
- Entrenamiento e implementación de un módulo de aprendizaje automático.
- Configuración de un dispositivo IoT Edge para que actúe como puerta de enlace transparente.
- Creación e implementación de módulos de IoT Edge.
- Envío de datos al dispositivo IoT Edge.
Continúa con el siguiente artículo para configurar una máquina de desarrollo y aprovisionar los recursos de Azure.