Componente Evaluate Model
En este artículo se describe un componente del diseñador de Azure Machine Learning.
Use este componente para medir la precisión de un modelo entrenado. Hay que proporcionar un conjunto de datos que contenga las puntuaciones generadas a partir de un modelo, y el componente Evaluate Model (Evaluar modelo) calculará un conjunto de métricas de evaluación estándar del sector.
Las métricas devueltas por Evaluate Model dependen del tipo de modelo que va a evaluar:
- Modelos de clasificación
- Modelos de regresión
- Modelos de agrupación en clústeres
Sugerencia
Si no está familiarizado con la evaluación de modelos, le recomendamos la serie de vídeos del Dr. Stephen Elston, como parte del curso de aprendizaje automático de EdX.
Cómo usar Evaluar modelo
Conecte la salida de Scored dataset (Conjunto de datos puntuados) de Score Model (Puntuar modelo) o la salida del conjunto de datos Resultado de Assign Data to Clusters (Asignar datos a los clústeres) al puerto de entrada izquierdo de Evaluate Model (Evaluar modelo).
Nota
Si se usan componentes como "Select Columns in Dataset" (Seleccionar columnas del conjunto de datos) para seleccionar parte del conjunto de datos de entrada, asegúrese de que la columna de etiqueta Real (usada en el entrenamiento) y las columnas "Scored Probabilities" y "Scored Labels" existan para calcular métricas, como AUC o Precisión, para la clasificación binaria o la detección de anomalías. La columna de etiqueta Real y la columna "Etiquetas puntuadas" existen para calcular las métricas para la clasificación o regresión de varias clases. La columna "Assignments" y las columnas "DistancesToClusterCenter no.X" (X es índice centroide, que va de 0, ..., a número de centroides -1) existen para calcular las métricas de la agrupación en clústeres.
Importante
- Para evaluar los resultados, el conjunto de datos de resultados debe contener nombres de columnas de puntuación específicos que cumplan con los requisitos del componente Evaluate Model (Evaluar modelo).
- La columna
Labelsse considerará como etiquetas reales. - En la tarea de regresión, el conjunto de datos que se va a evaluar debe tener una columna, denominada
Regression Scored Labels, que representa las etiquetas con puntuación. - En la tarea de clasificación binaria, el conjunto de datos que se va a evaluar debe tener dos columnas, denominadas
Binary Class Scored LabelsyBinary Class Scored Probabilities, que representan las etiquetas con puntuación y las probabilidades, respectivamente. - En la tarea de clasificación múltiple, el conjunto de datos que se va a evaluar debe tener una columna, denominada
Multi Class Scored Labels, que representa las etiquetas con puntuación. Si las salidas del componente ascendente no tienen estas columnas, debe modificarse según los requisitos anteriores.
[Opcional] Conecte la salida de Scored dataset (Conjunto de datos puntuados) de Score Model (Puntuar modelo) o la salida del conjunto de datos Resultado de Assign Data to Clusters (Asignar datos a los clústeres) del segundo modelo al puerto de entrada derecho de Evaluate Model (Evaluar modelo). Puede comparar fácilmente los resultados de dos modelos distintos con los mismos datos. Los dos algoritmos de entrada deben ser del mismo tipo. O bien, puede comparar las puntuaciones de las dos ejecuciones diferentes con los mismos datos con parámetros diferentes.
Nota
El tipo de algoritmo hace referencia a la "clasificación de dos clases", la "clasificación multiclase", la "regresión" y la "agrupación en clústeres" en los "algoritmos de aprendizaje automático".
Envíe la canalización para generar las puntuaciones de evaluación.
Results
Después de ejecutar Evaluate Model (Evaluar modelo), seleccione el componente para abrir el panel de navegación Evaluate Model a la derecha. Luego, elija la pestaña Outputs + Logs (Salidas y registros) y, en esa pestaña, la sección Data Outputs (Salidas de datos) tiene varios iconos. El icono Visualizar tiene un icono gráfico de barras y es una primera forma de ver los resultados.
En el caso de la clasificación binaria, después de hacer clic en el icono Visualizar, puede visualizar la matriz de confusión binaria. En el caso de la clasificación múltiple, puede encontrar el archivo de trazado de la matriz de confusión en la pestaña Salidas y registros, como se muestra a continuación:
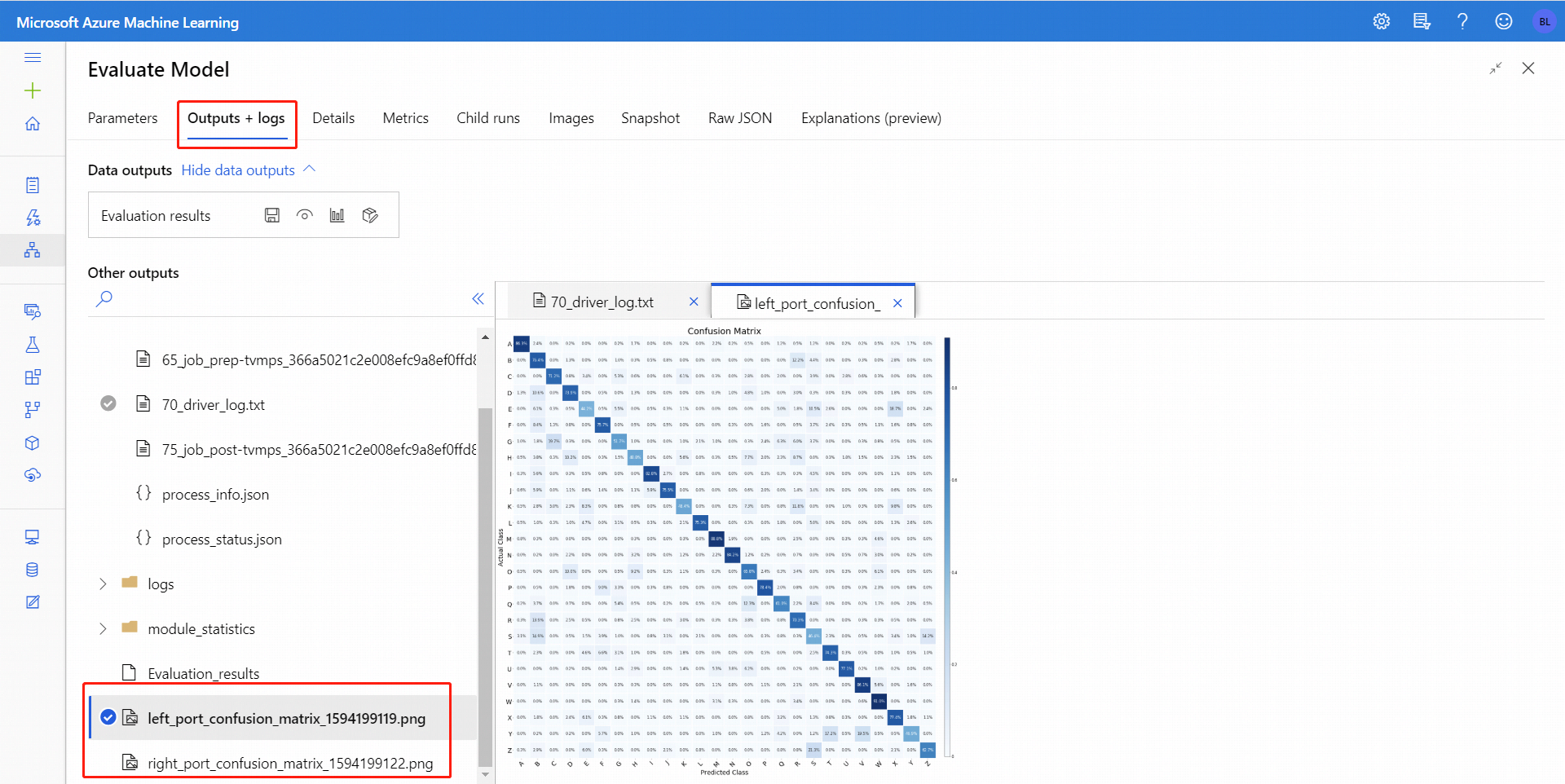
Si conecta los conjuntos de datos a las dos entradas de Evaluate Model, los resultados contendrán las métricas para ambos conjuntos de datos, o ambos modelos. El modelo o los datos conectados al puerto izquierdo aparecen en primer lugar en el informe, seguido de las métricas del conjunto de datos, o el modelo conectado al puerto derecho.
Por ejemplo, la imagen siguiente representa una comparación de los resultados de dos modelos de agrupación en clústeres que se crearon con los mismos datos, pero con distintos parámetros.

Debido a que se trata de un modelo de agrupación en clústeres, los resultados de evaluación son diferentes de si compara las puntuaciones de dos modelos de regresión o si compara dos modelos de clasificación. Pero la presentación general es la misma.
Métricas
Esta sección describe las métricas devueltas para los tipos específicos de los modelos admitidos para su uso con Evaluate Model:
Métricas para modelos de clasificación
Las siguientes métricas se notifican al evaluar los modelos de clasificación binaria.
Precisión (Accuracy) mide la calidad de un modelo de clasificación como la proporción de resultados verdaderos en el total de casos.
Precisión es la proporción de resultados verdaderos de todos los resultados positivos. Precisión = TP/(TP+FP)
Recuperación es la fracción de la cantidad total de instancias pertinentes que se recuperaron en realidad. Recuperación = TP/(TP+FN)
Puntuación F1 se calcula como el promedio ponderado de precisión y recuperación entre 0 y 1, donde el valor ideal de puntuación F1 es 1.
AUC mide el área bajo la curva trazada con los verdaderos positivos en el eje y los falsos positivos en el eje x. Esta métrica es útil porque proporciona un número único que le permite comparar los modelos de diferentes tipos. AUC es el umbral de clasificación invariable. Mide la calidad de las predicciones del modelo con independencia del umbral de clasificación elegido.
Métricas para los modelos de regresión
Las métricas devueltas para los modelos de regresión están diseñadas para estimar la cantidad de errores. Se considera que un modelo se ajusta a los datos correctamente si la diferencia entre los valores observados y los previstos es pequeña. Pero el patrón de los valores residuales (la diferencia entre un punto previsto y su valor real correspondiente) puede indicarle mucho sobre el sesgo potencial en el modelo.
Se notifican las siguientes métricas para evaluar los modelos de regresión lineal. Otros modelos de re gression, como la regresión cuantiles de bosque rápido, pueden tener métricas diferentes.
Error medio absoluto (MAE) : mide la proximidad de las predicciones con respecto a los resultados reales; por lo tanto, cuanto menor es la puntuación, mejor.
Error cuadrático medio (RMSE) : crea un valor único que resume el error en el modelo. Al elevar al cuadrado la diferencia, la métrica no tiene en cuenta la diferencia entre un exceso o un defecto de predicción.
Error absoluto relativo (RAE) : es la diferencia absoluta relativa entre los valores esperados y los reales; es relativa porque la diferencia media se divide por la media aritmética.
Error cuadrático relativo (RSE) : del mismo modo, normaliza el error cuadrático medio total de los valores previstos dividiendo entre el total de errores al cuadrado de los valores reales.
Coeficiente de determinación: a menudo conocido como R2, representa la eficacia predictiva del modelo como un valor entre 0 y 1. Cero significa que el modelo es aleatorio (no explica nada); 1 significa que hay un ajuste perfecto. Sin embargo, hay que tener precaución al interpretar los valores de R2, ya que los valores bajos pueden ser completamente normales y los valores altos pueden ser sospechosos.
Métricas para modelos de agrupación en clústeres
Dado que los modelos de agrupación en clústeres se diferencian considerablemente de los modelos de clasificación y regresión en muchos aspectos, Evaluar modelo también devuelve un conjunto distinto de estadísticas para los modelos de agrupación en clústeres.
Las estadísticas devueltas para un modelo de agrupación en clústeres describen el número de puntos de datos que se han asignado a cada clúster, la cantidad de separación entre clústeres y cómo de estrechamente están agrupados los puntos de datos dentro de cada clúster.
El promedio de las estadísticas del modelo de agrupación en clústeres se realiza en todo el conjunto de datos, con filas adicionales que contienen las estadísticas por clúster.
Se notifican las siguientes métricas para evaluar los modelos de agrupación en clústeres.
Las puntuaciones de la columna Average Distance to Other Center (Distancia media a otro centro) representan la cercanía, como media, de cada punto del clúster a los centroides de todos los demás clústeres.
Las puntuaciones de la columna Average Distance to Cluster Center (Distancia media al centro del clúster) representan la cercanía de todos los puntos del clúster al centroide de ese clúster.
La columna Number of Points (Número de puntos) muestra cuántos puntos de datos se han asignado a cada clúster, junto con el número total de puntos de datos en cualquier clúster.
Si el número de puntos de datos asignado a los clústeres es menor que el número total de puntos de datos disponibles, significa que no se han podido asignar los puntos de datos a un clúster.
Las puntuaciones de la columna Maximal Distance to Cluster Center (Distancia máxima al centro del clúster) representan las distancias máximas entre cada punto y el centroide del clúster de ese punto.
Si este número es alto, puede significar que el clúster está muy disperso. Debe revisar esta estadística junto con Average Distance to Cluster Center (Distancia media al centro del clúster) para determinar la dispersión del clúster.
La puntuación de Combined Evaluation (Evaluación combinada) en la parte inferior de cada sección de resultados indica las puntuaciones medias de los clústeres creados en ese modelo determinado.
Pasos siguientes
Vea el conjunto de componentes disponibles para Azure Machine Learning.