Ejemplos de Azure Data Science Virtual Machines
Azure Data Science Virtual Machine (DSVM) incluye un conjunto completo de código de ejemplo. Estos ejemplos incluyen cuadernos de Jupyter Notebook y scripts en lenguajes como Python y R.
Nota:
Para más información acerca de cómo ejecutar los cuadernos de Jupyter Notebook en Data Science Virtual Machine, consulte la sección Acceso a Jupyter.
Prerrequisitos
Para ejecutar estos ejemplos, tiene que haber aprovisionado una instancia de Data Science Virtual Machine de Ubuntu.
Ejemplos disponibles
| Categoría de ejemplos | Descripción | Ubicaciones |
|---|---|---|
| Lenguaje Python | Ejemplos que explican escenarios como la conexión con los almacenes de datos en la nube basados en Azure y cómo trabajar con Azure Machine Learning. Lenguaje Python |
~notebooks |
| Lenguaje Julia | Proporciona una descripción detallada del trazado y el aprendizaje profundo en Julia. También explica cómo llamar a C y Python desde Julia. Lenguaje Julia |
Windows: ~notebooks/Julia_notebooksLinux: ~notebooks/julia |
| Azure Machine Learning | Explica cómo crear modelos de aprendizaje automático y aprendizaje profundo con Machine Learning. Implemente los modelos en cualquier lenguaje. Utilice el ajuste de hiperparámetros inteligente y el aprendizaje automático automatizado. También puede usar la administración de modelos y el aprendizaje distribuido. Machine Learning |
~notebooks/AzureML |
| Cuadernos de PyTorch | Ejemplos de aprendizaje profundo que usan redes neuronales basadas en PyTorch. Los cuadernos abarcan desde escenarios para principiantes a usuarios avanzados. Cuadernos de PyTorch |
~notebooks/Deep_learning_frameworks/pytorch |
| TensorFlow | Varios ejemplos diferentes de red neuronal y técnicas implementadas mediante la plataforma TensorFlow. TensorFlow |
~notebooks/Deep_learning_frameworks/tensorflow |
| H2O | Ejemplos basados en Python que usan H2O para escenarios de problemas reales. H2O |
~notebooks/h2o |
| Lenguaje SparkML | Ejemplos que usan características del kit de herramientas de Apache Spark MLLib mediante pySpark y MMLSpark: Microsoft Machine Learning para Apache Spark en Apache Spark 2.x. Lenguaje SparkML |
~notebooks/SparkML/pySpark~notebooks/MMLSpark |
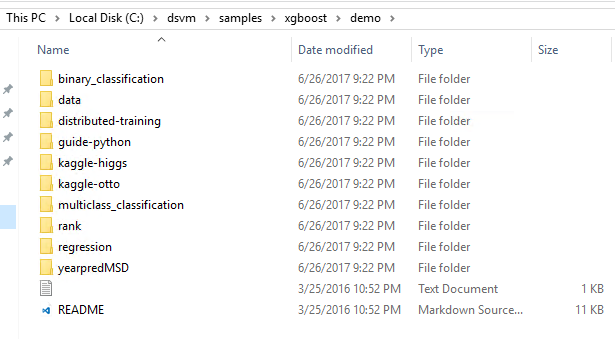
| XGBoost | Ejemplos de aprendizaje automático estándar en XGBoost para escenarios como clasificación y regresión. XGBoost |
Windows: \dsvm\samples\xgboost\demo |
Acceso a Jupyter
Para acceder a Jupyter, seleccione el icono de Jupyter en el escritorio o en el menú de la aplicación. También puede acceder a Jupyter en una edición de Linux de una instancia de DSVM. Para acceder remotamente desde un explorador web, vaya a https://<Full Domain Name or IP Address of the DSVM>:8000 en Ubuntu.
Para agregar excepciones y hacer que el acceso a Jupyter esté disponible desde un explorador, utilice la guía siguiente:
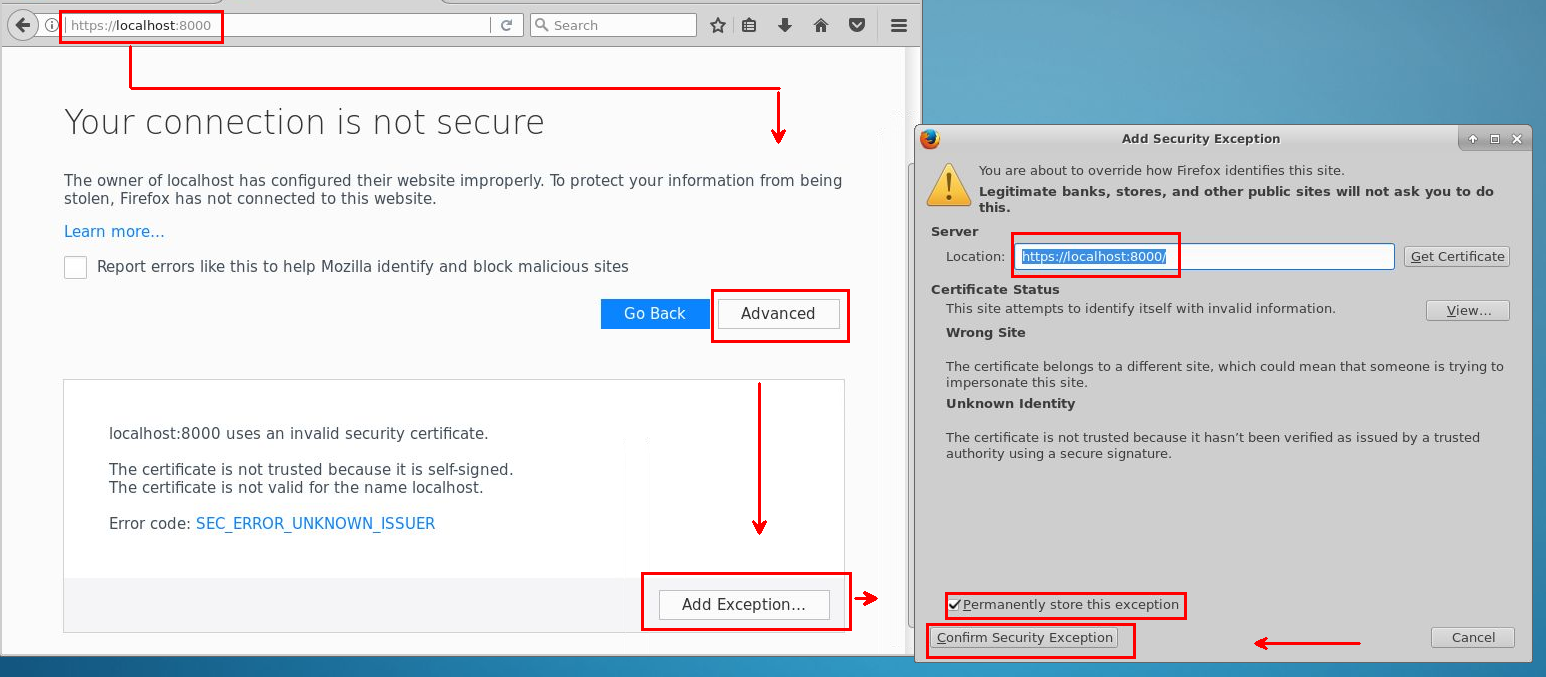
Inicie sesión con la misma contraseña que ha usado para el inicio de sesión en Data Science Virtual Machine.
Página de inicio de Jupyter
Lenguaje R
Lenguaje Python

Lenguaje Julia

Azure Machine Learning
PyTorch
TensorFlow

H2O
SparkML

XGBoost