Selección de parámetros para optimizar los algoritmos de Machine Learning Studio (clásico)
SE APLICA A:  Estudio de Azure Machine Learning (clásico)
Estudio de Azure Machine Learning (clásico)  Azure Machine Learning
Azure Machine Learning
Importante
El soporte técnico de Machine Learning Studio (clásico) finalizará el 31 de agosto de 2024. Se recomienda realizar la transición a Azure Machine Learning antes de esa fecha.
A partir del 1 de diciembre de 2021 no se podrán crear recursos de Machine Learning Studio (clásico). Hasta el 31 de agosto de 2024, puede seguir usando los recursos de Machine Learning Studio (clásico) existentes.
- Consulte la información acerca de traslado de proyectos de aprendizaje automático de ML Studio (clásico) a Azure Machine Learning.
- Más información acerca de Azure Machine Learning
La documentación de ML Studio (clásico) se está retirando y es posible que no se actualice en el futuro.
En este tema se describe cómo elegir el conjunto de hiperparámetros adecuado para un algoritmo en Machine Learning Studio (clásico). La mayoría de los algoritmos de aprendizaje automático tienen parámetros para configurar. Cuando entrena un modelo, tiene que especificar valores para esos parámetros. La eficacia del modelo entrenado depende de los parámetros del modelo que elija. El proceso de encontrar el conjunto óptimo de parámetros se conoce como selección del modelo.
Existen varias maneras de realizar la selección del modelo. En el aprendizaje automático, la validación cruzada es uno de los métodos más utilizados para la selección de modelos y es el mecanismo de selección de modelos predeterminado en Machine Learning Studio (clásico). Como R y Python se admiten en Machine Learning Studio (clásico), siempre puede implementar mecanismos de selección de modelos propios mediante R o Python.
Hay cuatro pasos en el proceso de encontrar el mejor conjunto de parámetros:
- Definir el espacio de parámetros: Para el algoritmo, primero decida los valores de parámetro exactos que quiere tener en cuenta.
- Definir la configuración de validación cruzada: Decida cómo elegir los plegamientos de validación cruzada.
- Definir la métrica: Decida qué métrica se va a usar para determinar el mejor conjunto de parámetros; por ejemplo, la precisión, el error cuadrático medio, la precisión, la recuperación o la puntuación f.
- Formar, evaluar y comparar: Para cada combinación única de los valores de parámetro, se lleva a cabo la validación cruzada y se basa en la métrica de error que defina. Después de la evaluación y la comparación, puede elegir el modelo de máximo rendimiento.
En la imagen siguiente se muestra cómo lograrlo en Machine Learning Studio (clásico).
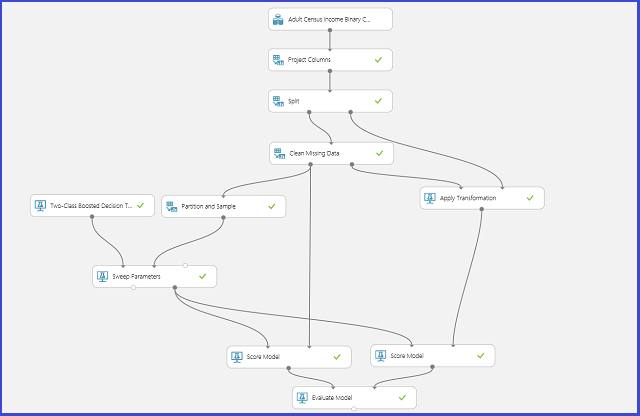
Definir el espacio de parámetros
Puede definir el conjunto de parámetros en el paso de inicialización del modelo. El panel de parámetros de todos los algoritmos de aprendizaje automático tiene dos modos de aprendizaje: Parámetro único y Rango de parámetros. Elija el modo del intervalo de parámetros. En el modo del intervalo de parámetros, puede escribir varios valores para cada parámetro. Puede escribir valores separados por comas en el cuadro de texto.
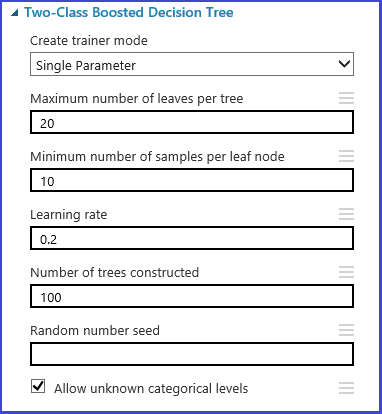
De manera alternativa, puede definir los puntos máximos y mínimos de la cuadrícula y el número total de puntos que se va a generar con Usar generador de intervalo. De manera predeterminada, se generan los valores de parámetro en una escala lineal. Pero si el cuadro Escala logarítmica está activado, los valores se generan en la escala logarítmica (es decir, la relación de los puntos adyacentes es constante en lugar de su diferencia). Para los parámetros de número entero, puede definir un intervalo con un guión. Por ejemplo, "1-10" significa que todos los valores enteros entre 1 y 10 (ambos inclusive) forman el conjunto de parámetros. También se admite un modo mixto. Por ejemplo, el conjunto de parámetros "1-10, 20, 50" incluirá números enteros de 1-10, 20 y 50.
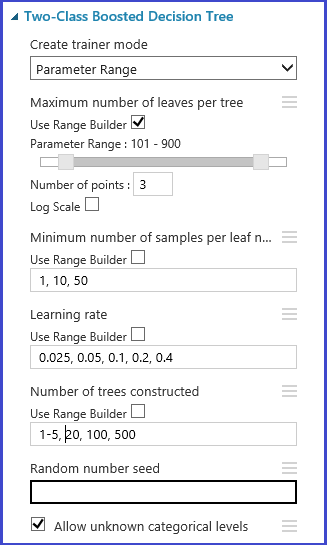
Definir los plegamientos de validación cruzada
El módulo de partición y ejemplo se puede usar para asignar pliegues a los datos de forma aleatoria. En la siguiente configuración de ejemplo del módulo, definimos cinco plegamientos y asignamos aleatoriamente un número de plegamientos a las instancias de ejemplo.
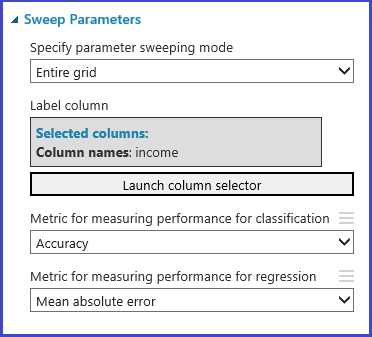
Definir la métrica
El módulo Optimizar el modelo Hiperparámetros proporciona compatibilidad para elegir empíricamente el mejor conjunto de parámetros para un algoritmo determinado y el conjunto de datos. El panel Propiedades de este módulo incluye, además de otra información referente a entrenar el modelo, la métrica para determinar el mejor conjunto de parámetros. Tiene dos cuadros de lista desplegables diferentes para los algoritmos de clasificación y regresión, respectivamente. Si el algoritmo en cuestión es un algoritmo de clasificación, se ignorará la métrica de regresión y viceversa. En este ejemplo concreto, la métrica es Precisión.
Formar, evaluar y comparar
El mismo módulo Optimizar los hiperparámetros de modelo entrena todos los modelos correspondientes al conjunto de parámetros, evalúa varias métricas y, después, genera el mejor modelo entrenado en función de la métrica que haya elegido. Este módulo contiene dos entradas obligatorias:
- El aprendiz no formado
- El conjunto de datos
El módulo también tiene una entrada de conjunto de datos opcional. Conecte el conjunto de datos con la información de plegamientos a la entrada del conjunto de datos obligatorio. Si el conjunto de datos no se asigna a ninguna información de plegamientos, se ejecuta automáticamente una validación cruzada 10 veces más rápida de manera predeterminada. Si no se realiza la asignación de plegamientos y se proporciona un conjunto de datos de validación en el puerto opcional del conjunto de datos, se usa un modo de prueba de aprendizaje elegido y el primer conjunto de datos para entrenar el modelo para cada combinación de parámetros.
Después, el modelo se evalúa en el conjunto de datos de validación. El puerto de salida izquierdo del módulo muestra métricas diferentes como funciones de los valores del parámetro. El puerto de salida derecho proporciona el modelo entrenado correspondiente al modelo de máximo rendimiento según la métrica elegida (Precisión en este caso).

Puede ver los parámetros exactos elegidos mediante la visualización del puerto de salida derecho. Este modelo puede utilizarse para determinar la puntuación de un conjunto de pruebas o en un servicio web de operaciones después de guardarlo como un modelo formado.