Tutorial: Depuración de un conjunto de aptitudes mediante sesiones de depuración
Un conjunto de aptitudes coordina las acciones de las aptitudes que analizan, transforman o crean contenido que se puede buscar. Con frecuencia, la salida de una aptitud se convierte en la entrada de otra. En los casos en que las entradas dependen de las salidas, los errores en las definiciones de los conjuntos de aptitudes y las asociaciones de campos pueden dar lugar a operaciones y datos que faltan.
Sesiones de depuración es una herramienta de Azure Portal que proporciona una visualización holística de un conjunto de aptitudes. Con esta herramienta, puede explorar en profundidad los pasos específicos para ver fácilmente dónde se puede estar produciendo un error en una acción.
En este artículo, se usan Sesiones de depuración para buscar y reparar las entradas y salidas que faltan. Este es un tutorial completo. Proporciona datos de ejemplo, un archivo REST que crea objetos e instrucciones para depurar problemas en el conjunto de aptitudes.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
Azure AI Search. Cree un servicio o busque uno existente en su suscripción actual. Puede usar un servicio gratuito para este tutorial.
Una cuenta de Azure Storage con Blob Storage que se usará para hospedar los datos de ejemplo y conservar los datos almacenados en la caché que se creen durante una sesión de depuración.
Visual Studio Code con un cliente REST.
Archivo depurar-sesiones.rest de ejemplo que se usa para crear la canalización de enriquecimiento.
Nota:
En este tutorial también se usan los servicios de Azure AI para la detección de idiomas, el reconocimiento de entidades y la extracción de frases clave. Dado que la carga de trabajo es tan pequeña, servicios de Azure AI se aprovechan en segundo plano del procesamiento gratuito de hasta 20 transacciones. Esto que significa que el ejercicio se puede completar sin tener que crear un recurso de servicios de Azure AI facturable.
Configurar la base de datos de muestra
En esta sección se crea el conjunto de datos de ejemplo en Azure Blob Storage para que el indexador y el conjunto de aptitudes tengan contenido con el que trabajar.
Descargue los datos de ejemplo (clinical-trials-pdf-19), que constan de 19 archivos.
Cree una cuenta de Azure Storage o busque una cuenta existente.
Para evitar cargos por el ancho de banda, elija la misma región que Azure AI Search.
Elija el tipo de cuenta StorageV2 (uso general V2).
Vaya a las páginas de servicios de Azure Storage en el portal y cree un contenedor de blobs. El procedimiento recomendado es especificar el nivel de acceso "privado". Asigne al contenedor el nombre
clinicaltrialdataset.En el contenedor, seleccione Cargar para cargar los archivos de ejemplo que descargó y descomprimió en el primer paso.
Mientras se encuentra en el portal, copie la cadena de conexión de Azure Storage. Puede obtener la cadena de conexión en Configuración>Claves de acceso en el portal.
Copia de una clave y una dirección URL
Las llamadas de REST requieren el punto de conexión de servicio de búsqueda y una clave de API en cada solicitud. Puede obtener estos valores en Azure Portal.
En Azure Portal, inicie sesión, vaya a la página Información general y copie la dirección URL. Un punto de conexión de ejemplo podría ser similar a
https://mydemo.search.windows.net.En Configuración>Claves, copie una clave de administrador. Las claves de administrador se utilizan para agregar, modificar y eliminar objetos. Hay dos claves de administrador intercambiables. Copie una de las dos.
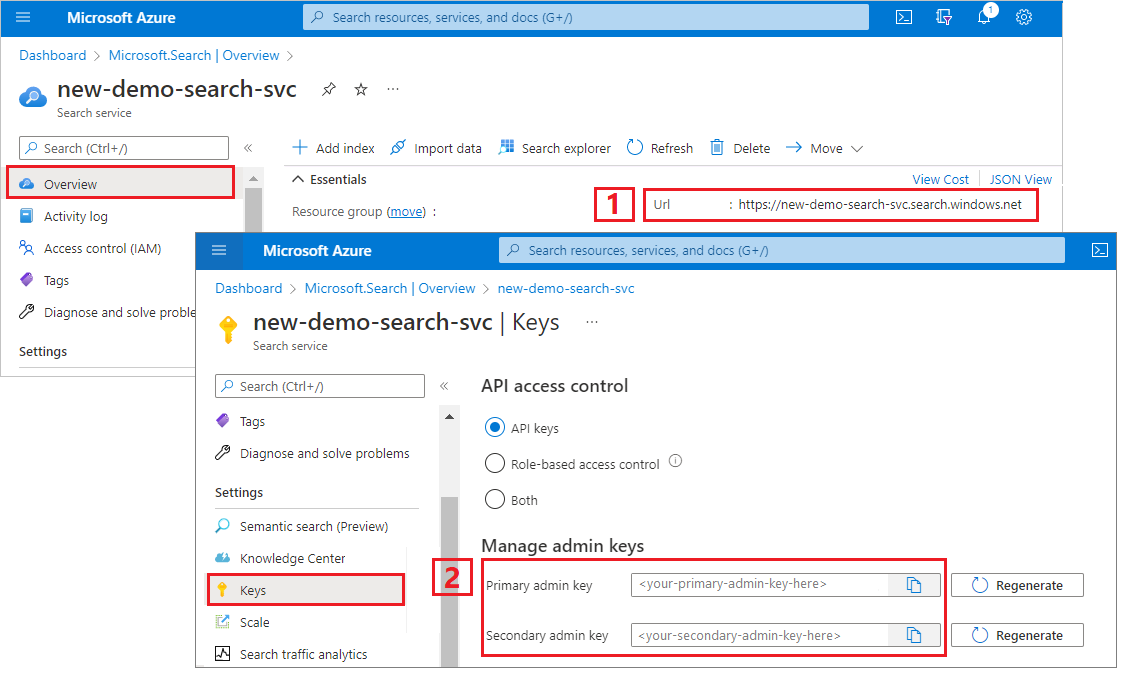
Una clave de API válida genera la confianza, solicitud a solicitud, entre la aplicación que la envía y el servicio que se encarga de ella.
Creación de un origen de datos, un conjunto de aptitudes, un índice y un indexador
En esta sección, cree un flujo de trabajo "con errores" que puede corregir en este tutorial.
Inicie Visual Studio Code y abra el archivo
debug-sessions.rest.Proporcione las siguientes variables: dirección URL del servicio de búsqueda, clave de API de administración de servicios de búsqueda, cadena de conexión de almacenamiento y el nombre del contenedor de blobs que almacena los ARCHIVOS PDF.
Envíe cada solicitud a su vez. La creación del indexador tarda varios minutos en completarse.
Cierre el archivo .
Comprobación de los resultados en el portal
El código de ejemplo crea intencionadamente un índice erróneo como consecuencia de problemas que se produjeron durante la ejecución del conjunto de aptitudes. El problema en el índice es que faltan datos.
En Azure Portal, en la página Información general del servicio de búsqueda, seleccione la pestaña Índices.
Seleccione clinical-trials.
Escriba esta cadena de consulta JSON en la vista JSON del Explorador de búsqueda. Devuelve campos para documentos específicos (identificados por el campo de
metadata_storage_pathúnico)."select": "metadata_storage_path, organizations, locations", "count"=true`Ejecute la consulta. Debería ver valores vacíos para
organizationsylocations.Estos campos se deben haber rellenado mediante la aptitud Reconocimiento de entidades del conjunto de aptitudes, que se usa para detectar organizaciones y ubicaciones en el contenido del blob. En el siguiente ejercicio, se usará la depuración del conjunto de aptitudes para determinar qué salió mal.
Otra manera de investigar los errores y advertencias es mediante Azure Portal.
Abra la pestaña Indizadores y seleccione clinical-trials-idxr.
Tenga en cuenta que aunque el trabajo del indexador se completó correctamente en general, hubo advertencias.
Seleccione Operación correcta para ver las advertencias (si se hubieran producido principalmente errores, el vínculo de detalle sería Con errores). Verá una lista larga de cada advertencia que emite el indexador.

Inicio de la sesión de depuración
En el panel de navegación izquierdo del servicio de búsqueda, en Administración de búsquedas, seleccione Sesiones de depuración.
Seleccione + Agregar sesión de depuración.
Asigne un nombre a la sesión.
Conecte la sesión a su cuenta de almacenamiento. Cree un contenedor denominado "sesiones de depuración". Puede usar este contenedor repetidamente para almacenar todos los datos de la sesión de depuración.
Si configuró una conexión de confianza entre la búsqueda y el almacenamiento, seleccione la identidad administrada por el usuario o la identidad del sistema para la conexión. De lo contrario, use el valor predeterminado (Ninguna).
En la plantilla del indexador, proporcione el nombre de este. El indexador hace referencia al origen de datos, al conjunto de aptitudes y al índice.
Acepte la opción de documento predeterminada para el primer documento de la colección. Una sesión de depuración solo funciona con un único documento. Puede elegir qué documento quiere depurar o simplemente utilizar el primero.
Guarde la sesión. Al guardar la sesión se iniciará la canalización de enriquecimiento, como lo define el conjunto de aptitudes para el documento seleccionado.
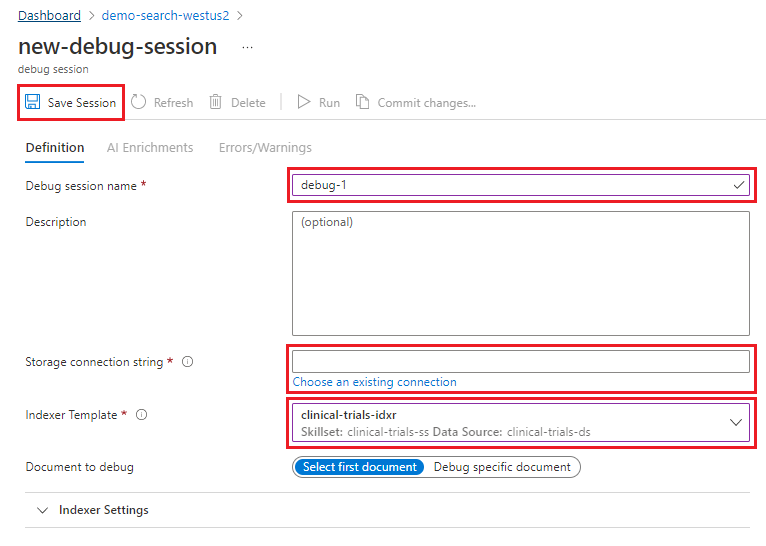
Una vez completada la inicialización de la sesión de depuración, la sesión muestra de forma predeterminada la pestaña Enriquecimientos con IA, resaltando el gráfico de aptitudes. El gráfico de aptitudes proporciona una jerarquía visual del conjunto de aptitudes y su orden de ejecución secuencial y en paralelo.
Búsqueda de los problemas del conjunto de aptitudes
Los problemas que notifica el indexador se pueden encontrar en la pestaña adyacente Errores o advertencias.
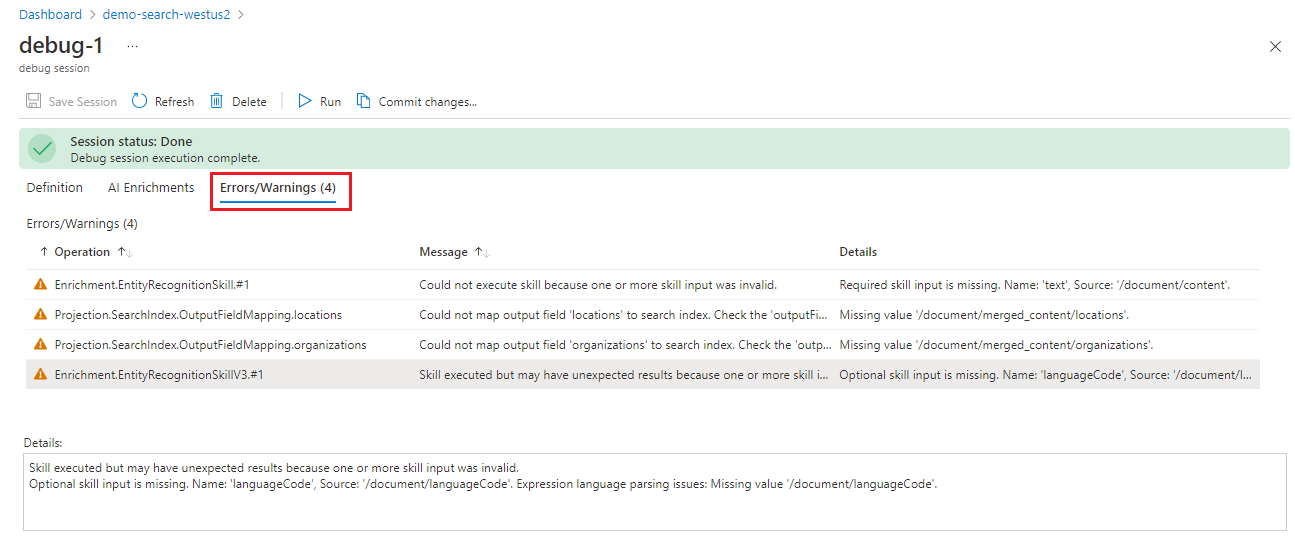
Observe que la pestaña Errores o advertencias proporcionará una lista mucho más reducida que la mostrada anteriormente, ya que esta lista solo detalla los errores de un único documento. Al igual que la lista mostrada por el indexador, puede seleccionar en un mensaje de advertencia y ver los detalles de esta advertencia.
Seleccione Errores o advertencias para revisar las notificaciones. Debería ver cuatro:
"No se pudo ejecutar la aptitud porque una o varias entradas de aptitud no eran válidas. Falta la entrada de aptitud requerida. Nombre: 'text', Origen: '/document/content'."
"No se pudo asignar el campo de salida "locations" al índice de búsqueda. Compruebe la propiedad "outputFieldMappings" del indexador. Falta el valor "/document/merged_content/locations"."
"No se pudo asignar el campo de salida "organizations" al índice de búsqueda. Compruebe la propiedad "outputFieldMappings" del indexador. Falta el valor "/document/merged_content/organizations"."
"La aptitud se ejecutó pero puede tener resultados inesperados porque una o varias entradas de aptitudes no eran válidas. Falta la entrada de aptitud opcional. Nombre: "languageCode", origen: "/document/languageCode". Problemas de análisis del lenguaje de expresiones: Falta el valor "/document/languageCode"."
Muchas aptitudes tienen un parámetro "languageCode". Al inspeccionar la operación, puede ver que falta esta entrada de código de idioma de la aptitud EntityRecognitionSkill.#1, que es la misma aptitud de reconocimiento de entidades que tiene problemas con la salida de "locations" (ubicaciones) y "organizations" (organizaciones).
Dado que las cuatro notificaciones son sobre esta aptitud, el siguiente paso es depurarla. Si es posible, resuelva los problemas de la entrada antes de pasar a los de salida.
Corrección de valores de entrada de las aptitudes que faltan
En la pestaña Errores o advertencias, hay dos entradas que faltan en una operación con la etiqueta EntityRecognitionSkill.#1. En los detalles del primer error se explica que falta una entrada necesaria para "text". El segundo indica un problema con un valor de entrada, "/document/languageCode".
In AI Enrichments>Skill Graph (Enriquecimientos de IA > Grafo de aptitudes), seleccione la aptitud con la etiqueta n.º 1 para que aparezcan sus detalles en el panel derecho.
Seleccione la pestaña Executions (Ejecuciones) y busque la entrada de "text".
Seleccione el símbolo </> para abrir el evaluador de expresiones. El resultado mostrado para esta entrada no parece una entrada de texto. Más bien parece una serie de caracteres de línea nuevos,
\n \n\n\n\n, en lugar de texto. La falta de texto significa que no se puede identificar ninguna entidad, por lo que este documento no cumple los requisitos previos de la aptitud o hay otra entrada que se debe usar en su lugar.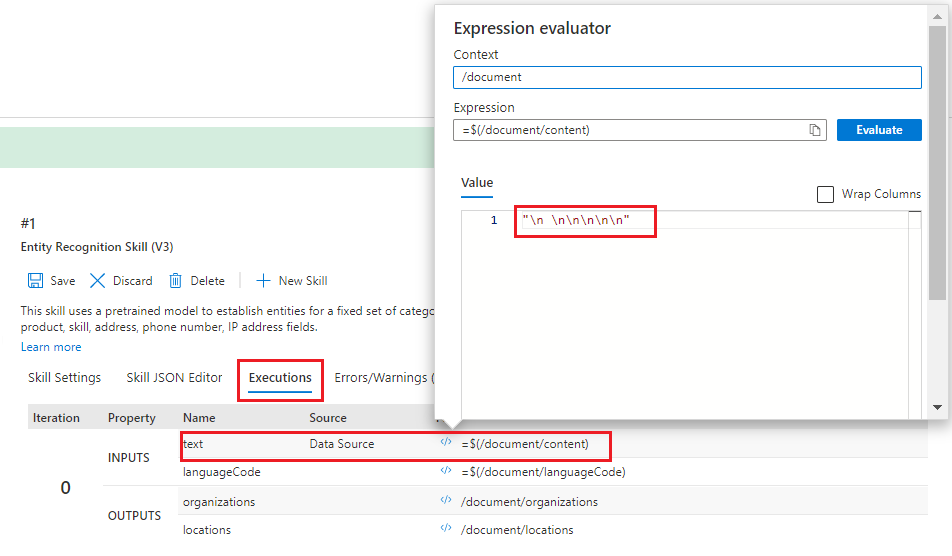
Cambie el panel izquierdo a Enriched Data Structure (Estructura de datos enriquecidos) y desplácese hacia abajo en la lista de nodos de enriquecimiento de este documento. Observe que los caracteres
\n \n\n\n\nde "content" no tienen ningún origen, pero otro valor de "merged_content" tiene salida OCR. Aunque no hay ninguna indicación, el contenido de este PDF parece ser un archivo JPEG, como lo evidencia el texto extraído y procesado en "merged_content".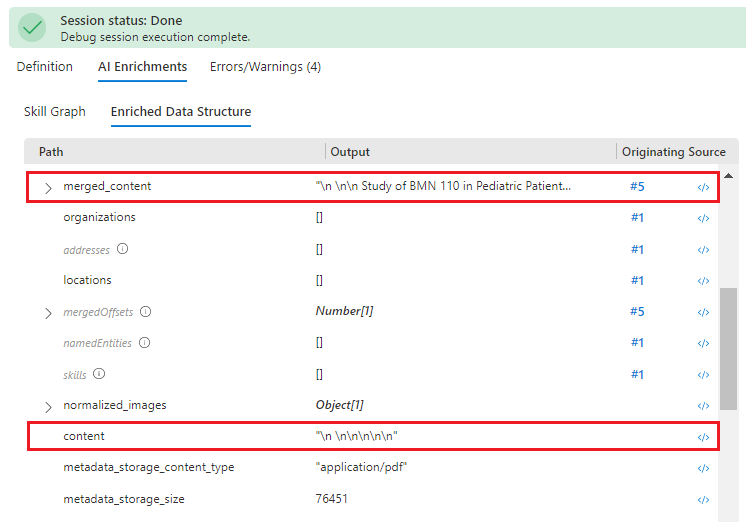
En el panel derecho, seleccione Executions (Ejecuciones) para la aptitud 1 y abra el evaluador de expresiones </> para el valor de "text" de entrada.
Cambie la expresión de
/document/contenta/document/merged_contenty seleccione Evaluate (Evaluar). Observe que el contenido es ahora un fragmento de texto y, por tanto, se puede procesar para el reconocimiento de entidades.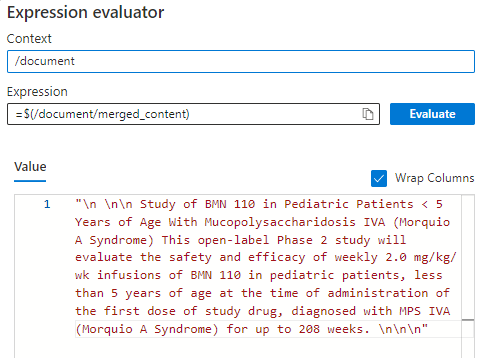
Cambie al editor JSON de aptitudes.
En la línea 16, en "entradas", cambie
/document/contenta/document/merged_content.{ "name": "text", "source": "/document/merged_content" },Haga clic en Guardar en el panel Skill Details (Detalles de aptitud).
Seleccione Run (Ejecutar) en el menú de la ventana de la sesión. Esto iniciará otra ejecución del conjunto de aptitudes con el documento.
Una vez completada la ejecución de la sesión de depuración, fíjese la pestaña Errores o advertencias, que mostrará que el error de la entrada de texto ha desaparecido, pero las restantes advertencias permanecen. El siguiente paso consiste en solucionar la advertencia sobre "languageCode".

Seleccione la pestaña Executions (Ejecuciones) y busque la entrada de "languageCode".
Seleccione el símbolo </> para abrir el evaluador de expresiones. Observe la confirmación de que la propiedad "languageCode" no es una entrada válida.
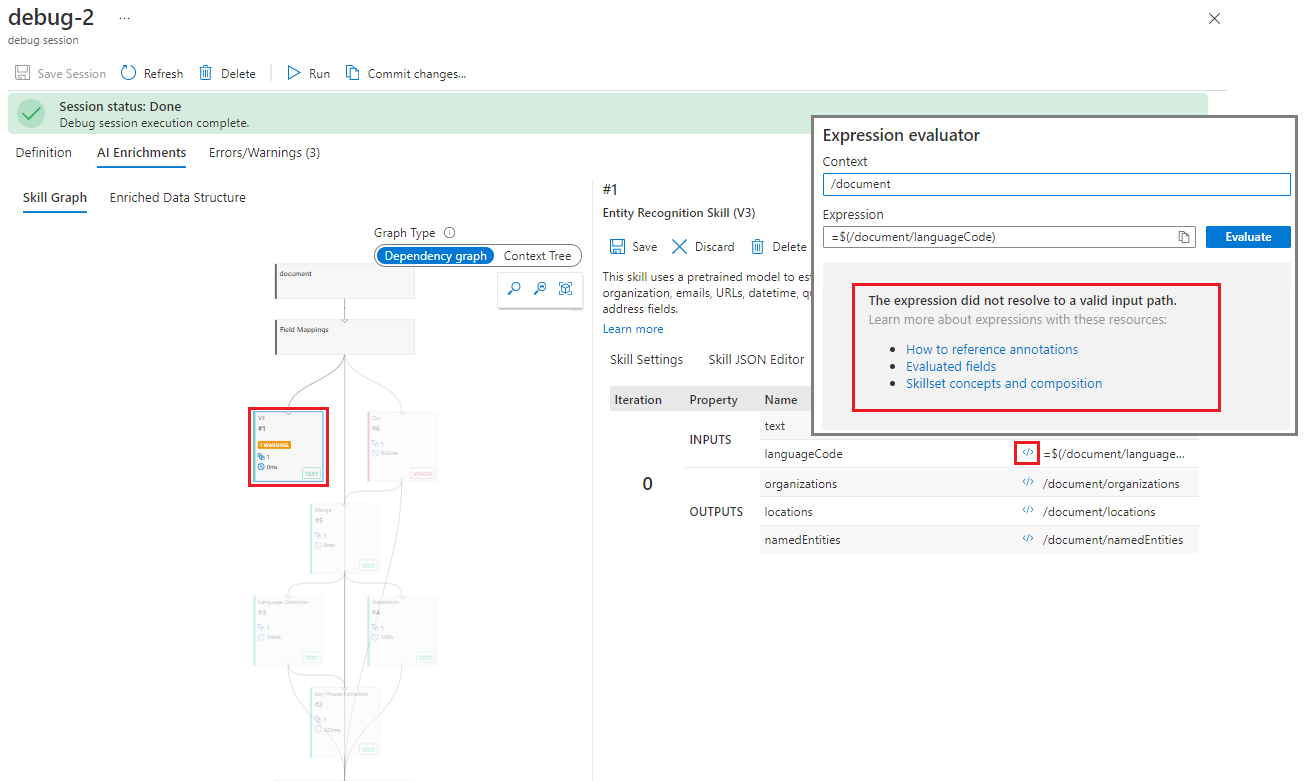
Hay dos maneras de investigar este error. La primera es examinar de dónde procede la entrada. ¿Qué aptitud de la jerarquía se supone que genera este resultado? En la pestaña Ejecuciones del panel de detalles de la aptitud debe aparecer el origen de la entrada. Si no hay ningún origen, esto indica un error de asignación de campos.
En la pestaña Executions (Ejecuciones), examine las entradas y busque "languageCode". No hay ningún origen para esta entrada enumerada.
Cambie el panel izquierdo a Enriched Data Structure (Estructura de datos enriquecidos). Desplácese hacia abajo en la lista de nodos de enriquecimiento de este documento. Observe que no hay ningún nodo "languageCode", pero hay uno para "lenguaje". Por lo tanto, hay un error tipográfico en la configuración de aptitudes.
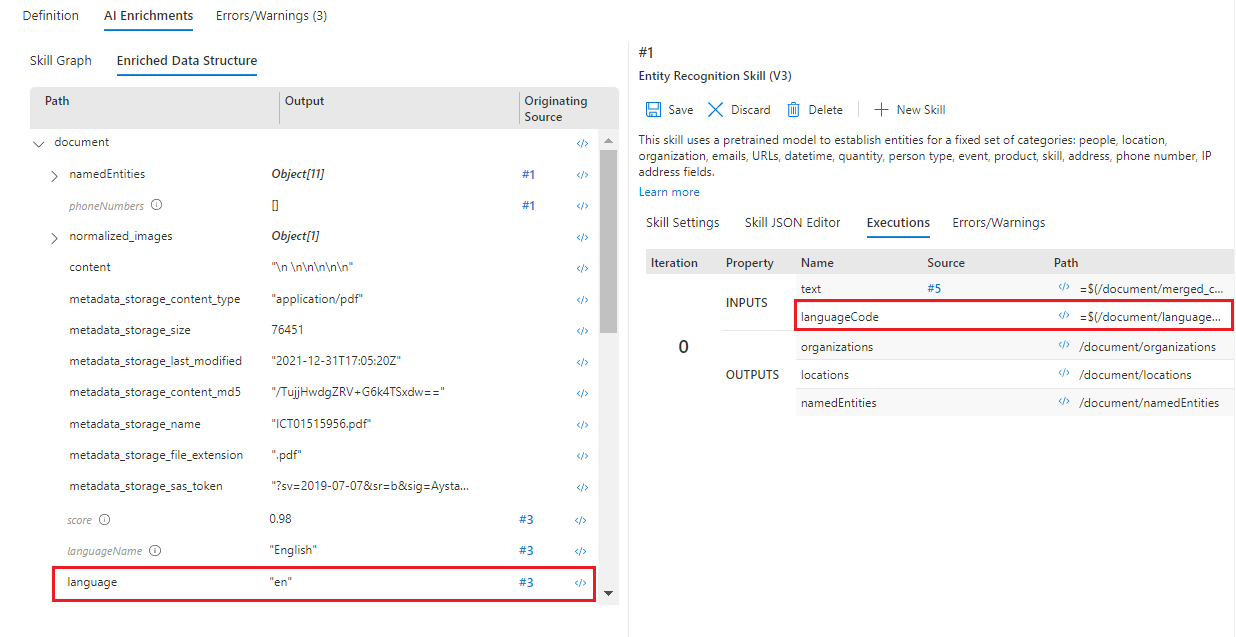
En Enriched Data Structure (Estructura de datos enriquecidos), abra el evaluador de expresiones </> para el nodo "language" y copie la expresión
/document/language.En el panel derecho, seleccione Skill Settings de la aptitud 1 y abra el evaluador de expresiones </> para la entrada "languageCode".
Pegue el nuevo valor,
/document/languageen el cuadro Expresión y seleccione Evaluar. Debe mostrar la entrada correcta "en".Seleccione Guardar.
Seleccione Run (Ejecutar).
Una vez completada la ejecución de la sesión de depuración, fíjese en la pestaña Errores o advertencias y verá que todas las advertencias de entrada han desaparecido. Solo quedan las dos advertencias sobre los campos de salida de las organizaciones y las ubicaciones.
Corrección de valores de salida de aptitud que faltan
Los mensajes indican que se compruebe la propiedad "outputFieldMappings" del indexador, así que vamos a empezar por ahí.
Vaya al Skill Graph (Grafo de aptitudes) y seleccione Output Field Mappings (Asignaciones de campos de salida). Las asignaciones son correctas, pero lo habitual es que se compruebe la definición del índice para asegurarse de que existen campos para "ubicaciones" y "organizaciones".
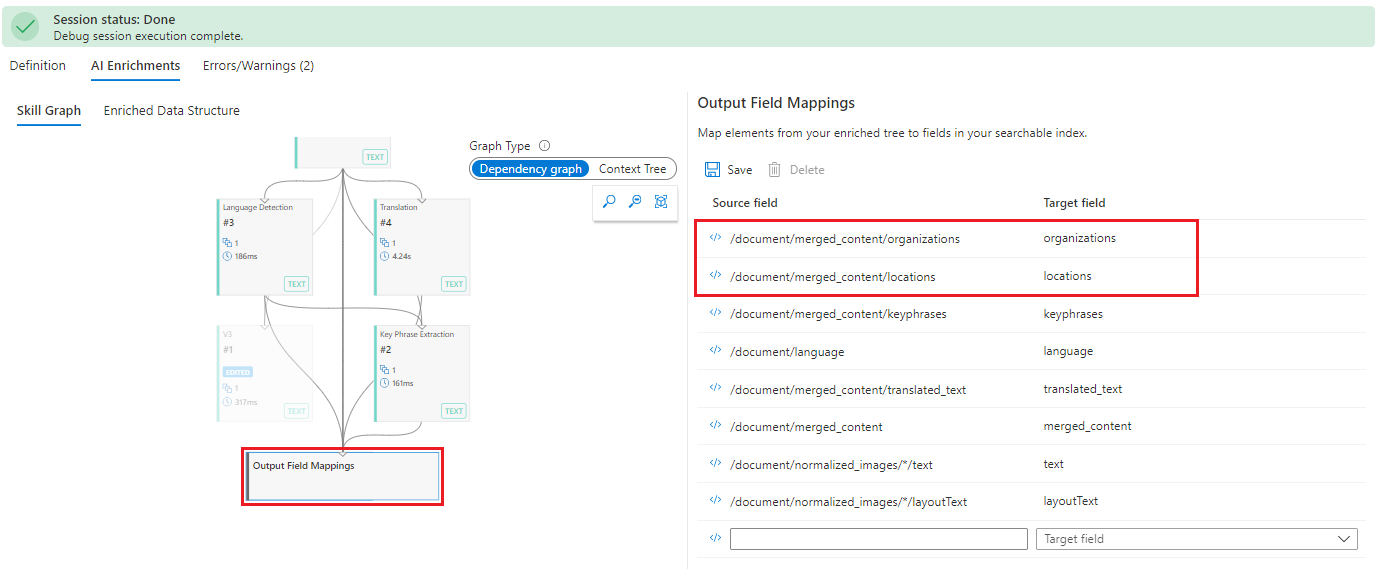
Si no hay ningún problema con el índice, el siguiente paso es comprobar las salidas de aptitud. Como antes, seleccione Enriched Data Structure (Estructura de datos enriquecidos) y desplácese por los nodos para buscar "ubicaciones" y "organizaciones". Observe que el elemento primario es "content", en lugar de "merged_content". El contexto es incorrecto.
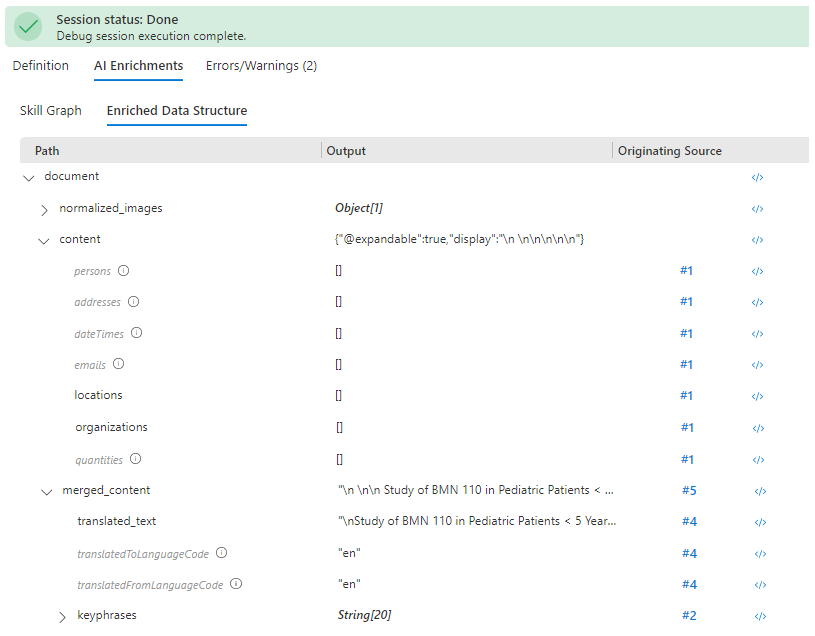
Vuelva a Skill Graph (Grafo de aptitudes) y seleccione la aptitud de reconocimiento de entidades.
Navegue por la configuración de las aptitudes y busque "context".
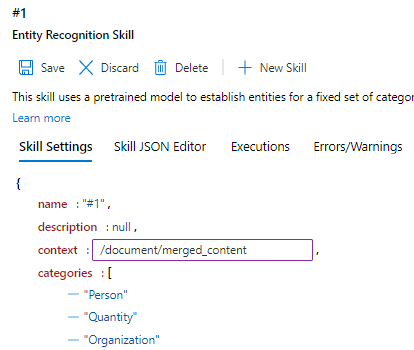
Haga doble clic en el valor de "context" y cámbielo a "/document/merged_content".
Seleccione Guardar.
Seleccione Run (Ejecutar).
Todos los errores se han resuelto.
Confirmación de los cambios en el conjunto de aptitudes
Cuando se inició la sesión de depuración, el servicio de búsqueda creó una copia del conjunto de aptitudes. Esto se hizo para proteger el conjunto de aptitudes original en el servicio de búsqueda. Ahora que ha finalizado la depuración del conjunto de aptitudes, las correcciones se pueden confirmar (sobrescribir el conjunto de aptitudes original).
Como alternativa, si no está listo para confirmar los cambios, puede guardar la sesión de depuración y volver a abrirla más adelante.
Seleccione Commit changes (Confirmar cambios) en el menú principal de Sesiones de depuración.
Selecciones OK (Aceptar) para confirmar que desea actualizar el conjunto de aptitudes.
Cierre la sesión de depuración y abra Indexadores en el panel de navegación izquierdo.
Seleccione "clinical-trials-idxr".
Seleccione Restablecer.
Seleccione Run (Ejecutar).
Seleccione Actualizar para mostrar el estado de los comandos de restablecimiento y ejecución.
Cuando el indexador haya terminado de ejecutarse, aparecerá una marca de verificación verde y la palabra Correcto junto a la marca de tiempo de la última ejecución en la pestaña Historial de ejecución. Para asegurarse de que se han aplicado los cambios:
En el panel de navegación izquierdo, abra Índices.
Abra el índice de "clinical-trials" y, en la pestaña Explorador de búsqueda, escriba esta cadena de consulta:
$select=metadata_storage_path, organizations, locations&$count=truepara que devuelva los campos de documentos específicos (identificados mediante el campometadata_storage_pathúnico).Seleccione Search.
Los resultados deberían mostrar que las organizaciones y las ubicaciones ahora contienen los valores esperados.
Limpieza de recursos
Cuando trabaje con su propia suscripción, es una buena idea al final de un proyecto identificar si todavía se necesitan los recursos que ha creado. Los recursos que se dejan en ejecución pueden costarle mucho dinero. Puede eliminar los recursos de forma individual o eliminar el grupo de recursos para eliminar todo el conjunto de recursos.
Puede encontrar y administrar recursos en el portal, mediante el vínculo Todos los recursos o Grupos de recursos en el panel de navegación izquierdo.
El servicio gratuito se limita a tres índices, indexadores y orígenes de datos. Puede eliminar elementos individuales en el portal para mantenerse por debajo del límite.
Pasos siguientes
Este tutorial ha tratado sobre varios aspectos de la definición y el procesamiento de los conjuntos de aptitudes. Para más información sobre conceptos y flujos de trabajo, consulte los siguientes artículos: