Conectores de Power Query (versión preliminar)
Importante
La compatibilidad con el conector de Power Query se introdujo como versión preliminar pública controlada según los Términos de uso complementarios para las Versiones preliminares de Microsoft Azure, pero ahora está descontinuada. Si tiene una solución de búsqueda que usa un conector de Power Query, migre a una solución alternativa.
Migración del 28 de noviembre de 2022
La versión preliminar del conector de Power Query se anunció en mayo de 2021 y no avanzará hacia la disponibilidad general. La siguiente guía de migración está disponible para Snowflake y PostgreSQL. Si usa otro conector y necesita instrucciones de migración, use la información de contacto de correo electrónico proporcionada en el registro de la versión preliminar para solicitar ayuda o abrir una incidencia con el equipo de Soporte técnico de Azure.
Requisitos previos
- Una cuenta de Azure Storage. Si aún no tiene una, cree una cuenta de almacenamiento.
- Una instancia de Azure Data Factory. Si no tiene una, cree una instancia de Data Factory. Consulte Precios de las canalizaciones de datos antes de la implementación para comprender los costos asociados. Consulte también Descripción de los precios de Data Factory a través de ejemplos.
Migración de una canalización de datos de Snowflake
En esta sección, se explica cómo copiar datos de una base de datos de Snowflake a un índice de Azure Cognitive Search. No hay ningún proceso para indexar directamente desde Snowflake a Azure Cognitive Search, por lo que esta sección incluye una fase de almacenamiento provisional que copia el contenido de la base de datos en un contenedor de blobs de Azure Storage. A continuación, realizará la indexación desde ese contenedor de almacenamiento provisional mediante una canalización de Data Factory.
Paso 1: Recuperación de la información de la base de datos de Snowflake
Vaya a Snowflake e inicie sesión en su cuenta de Snowflake. Una cuenta de Snowflake es similar a https://<nombre_de_cuenta>.snowflakecomputing.com.
Una vez que haya iniciado sesión, recopile la siguiente información en el panel izquierdo. Utilizará esta información en el siguiente paso:
- En Data (Datos), seleccione Databases (Bases de datos) y copie el nombre del origen de la base de datos.
- En Administración, seleccione Usuarios & Roles y copie el nombre del usuario. Asegúrese de que el usuario tenga permisos de lectura.
- En Admin (Administración), seleccione Accounts (Cuentas) y copie el valor de LOCATOR (Localizador) de la cuenta.
- Desde la dirección URL de Snowflake, que es similar a
https://app.snowflake.com/<region_name>/xy12345/organization), copie el nombre de la región. Por ejemplo, enhttps://app.snowflake.com/south-central-us.azure/xy12345/organization, el nombre de la región essouth-central-us.azure. - En Admin (Administración), seleccione Warehouses (Almacenes) y copie el nombre del almacén asociado a la base de datos que usará como origen.
Paso 2: Configuración del servicio vinculado de Snowflake
Inicie sesión en Azure Data Factory Studio con su cuenta de Azure.
Seleccione la factoría de datos y, a continuación, seleccione Continuar.
En el menú izquierdo, seleccione el icono Administrar.
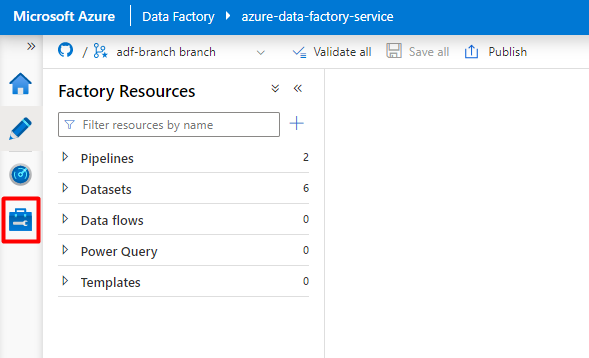
En Servicios vinculados, seleccione Nuevo.
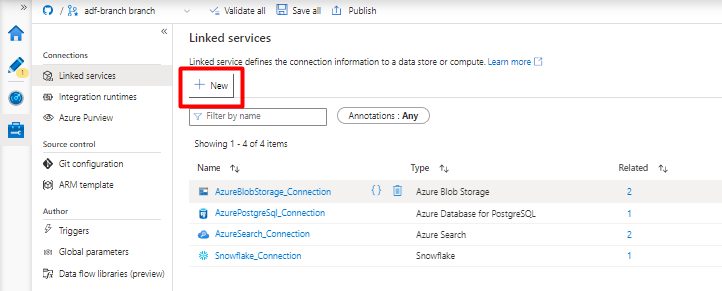
En el panel derecho, en la búsqueda del almacén de datos, escriba "snowflake". Seleccione el icono de Snowflake y seleccione Continuar.
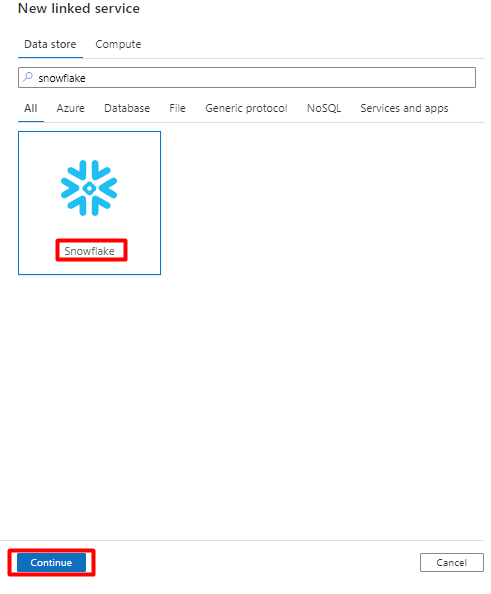
Rellene el formulario Nuevo servicio vinculado con los datos recopilados en el paso anterior. El nombre de la cuenta incluye un valor LOCATOR (Localizador) y la región (por ejemplo:
xy56789south-central-us.azure).
Una vez completado el formulario, seleccione Probar conexión.
Si la prueba se realiza correctamente, seleccione Crear.
Paso 3: Configuración del conjunto de datos de Snowflake
En el menú izquierdo, seleccione el icono Crear.
Seleccione Conjuntos de datos y, a continuación, seleccione el menú de puntos suspensivos de acciones de conjuntos de datos (
...).
Seleccione Nuevo conjunto de datos.
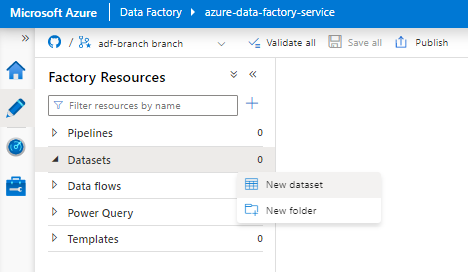
En el panel derecho, en la búsqueda del almacén de datos, escriba "snowflake". Seleccione el icono de Snowflake y seleccione Continuar.
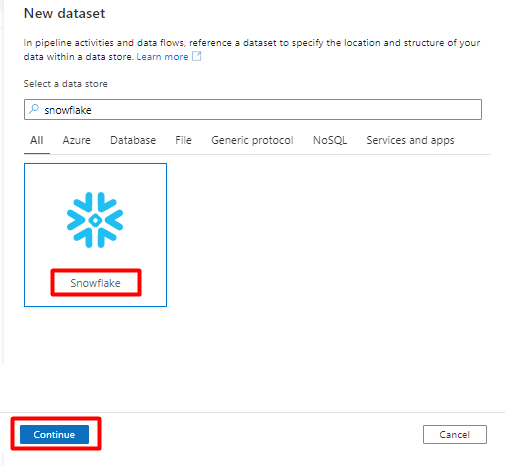
En Definir propiedades:
- Seleccione el servicio vinculado que creó en el paso 2.
- Seleccione la tabla que desea importar y, a continuación, seleccione Aceptar.

Seleccione Guardar.
Paso 4: Creación de un índice nuevo en Azure Cognitive Search
Cree un nuevo índice en el servicio Azure Cognitive Search con el mismo esquema que el que ha configurado actualmente para los datos de Snowflake.
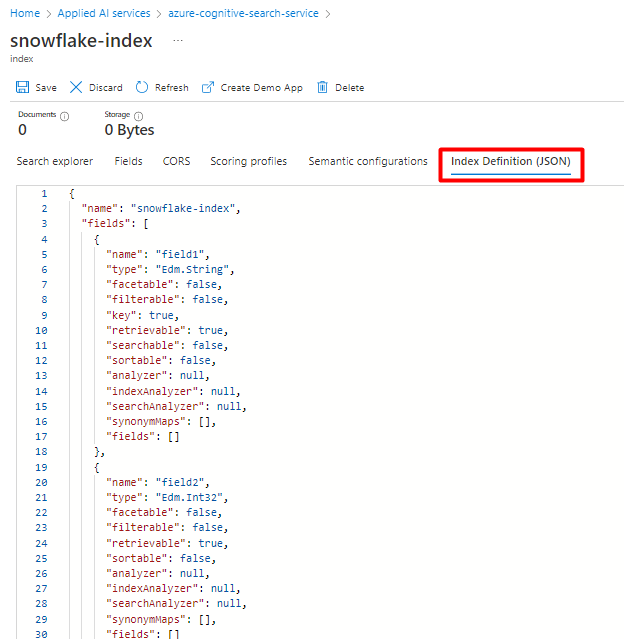
Puede reasignar el índice que está usando actualmente para el conector de Power Query de Snowflake. En Azure Portal, busque el índice y seleccione Definición de índice (JSON). Seleccione la definición y cópiela en el cuerpo de la nueva solicitud de índice.
Paso 5: Configuración del servicio vinculado de Azure Cognitive Search
En el menú izquierdo, seleccione el icono Administrar.
En Servicios vinculados, seleccione Nuevo.
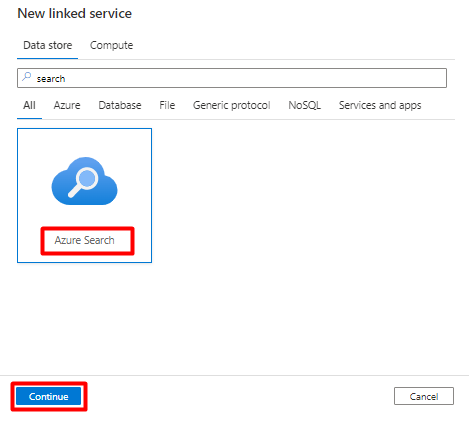
En el panel derecho, en la búsqueda del almacén de datos, escriba "search". Seleccione el icono de Azure Search y seleccione Continuar.
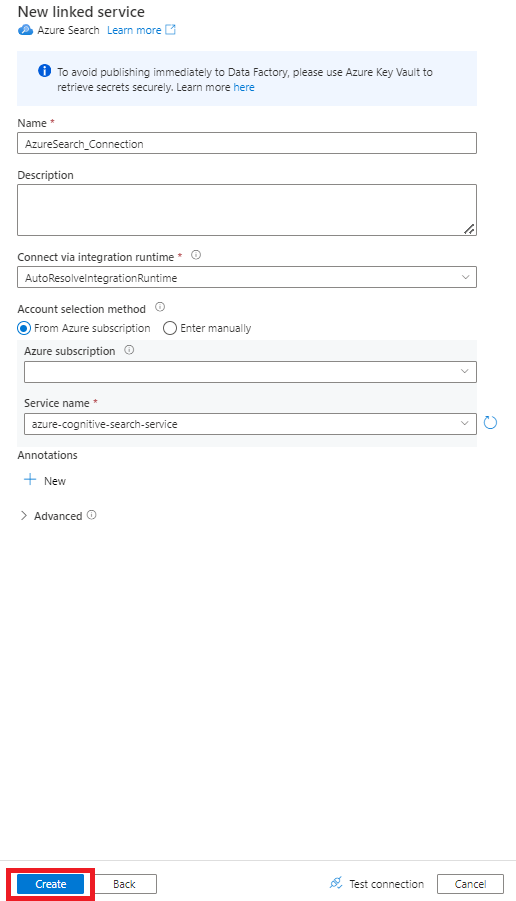
Rellene los valores de Nuevo servicio vinculado:
- Elija la suscripción de Azure donde reside el servicio Azure Cognitive Search.
- Elija el servicio Azure Cognitive Search que tiene el indexador del conector de Power Query.
- Seleccione Crear.
Paso 6: Configuración del conjunto de datos de Azure Cognitive Search
En el menú izquierdo, seleccione el icono Crear.
Seleccione Conjuntos de datos y, a continuación, seleccione el menú de puntos suspensivos de acciones de conjuntos de datos (
...).
Seleccione Nuevo conjunto de datos.
En el panel derecho, en la búsqueda del almacén de datos, escriba "search". Seleccione el icono de Azure Search y seleccione Continuar.

En Definir propiedades:
Seleccione Guardar.

Paso 7: Configuración del servicio vinculado de Azure Blob Storage
En el menú izquierdo, seleccione el icono Administrar.
En Servicios vinculados, seleccione Nuevo.
En el panel derecho, en la búsqueda del almacén de datos, escriba "storage". Seleccione el icono de Azure Blob Storage en la lista y, a continuación, seleccione Continuar.
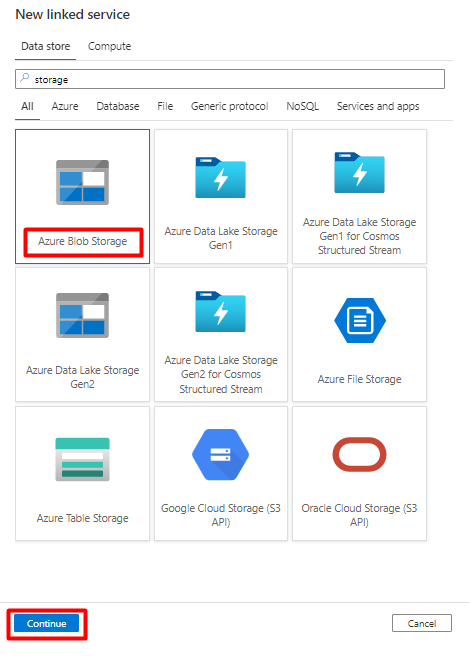
Rellene los valores de Nuevo servicio vinculado:
Elija el tipo de autenticación: URI de SAS. Solo se puede usar este tipo de autenticación para importar datos de Snowflake en Azure Blob Storage.
Genere una dirección URL de SAS para la cuenta de almacenamiento que usará para el almacenamiento provisional. Pegue la dirección URL de SAS del blob en el campo Dirección URL de SAS.
Seleccione Crear.

Paso 8: Configuración del conjunto de datos de Storage
En el menú izquierdo, seleccione el icono Crear.
Seleccione Conjuntos de datos y, a continuación, seleccione el menú de puntos suspensivos de acciones de conjuntos de datos (
...).
Seleccione Nuevo conjunto de datos.
En el panel derecho, en la búsqueda del almacén de datos, escriba "storage". Seleccione el icono de Azure Blob Storage en la lista y, a continuación, seleccione Continuar.
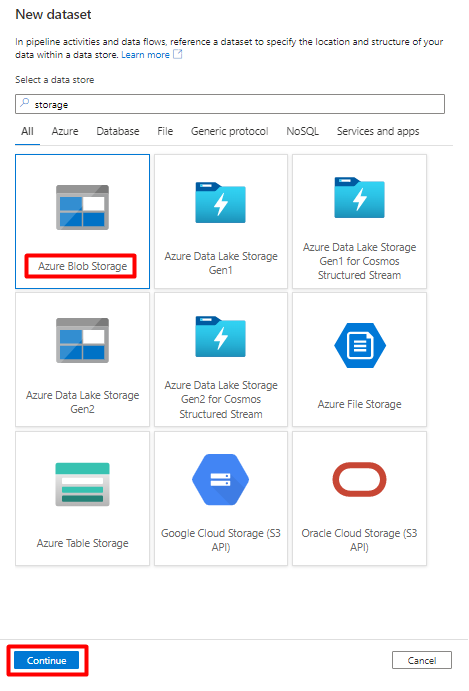
Seleccione DelimitedText como formato y, luego, seleccione Continuar.
En Definir propiedades:
En Servicio vinculado, seleccione el servicio vinculado creado en el paso 7.
En Ruta de acceso del archivo, elija el contenedor que será el receptor para el proceso de almacenamiento provisional y seleccione Aceptar.

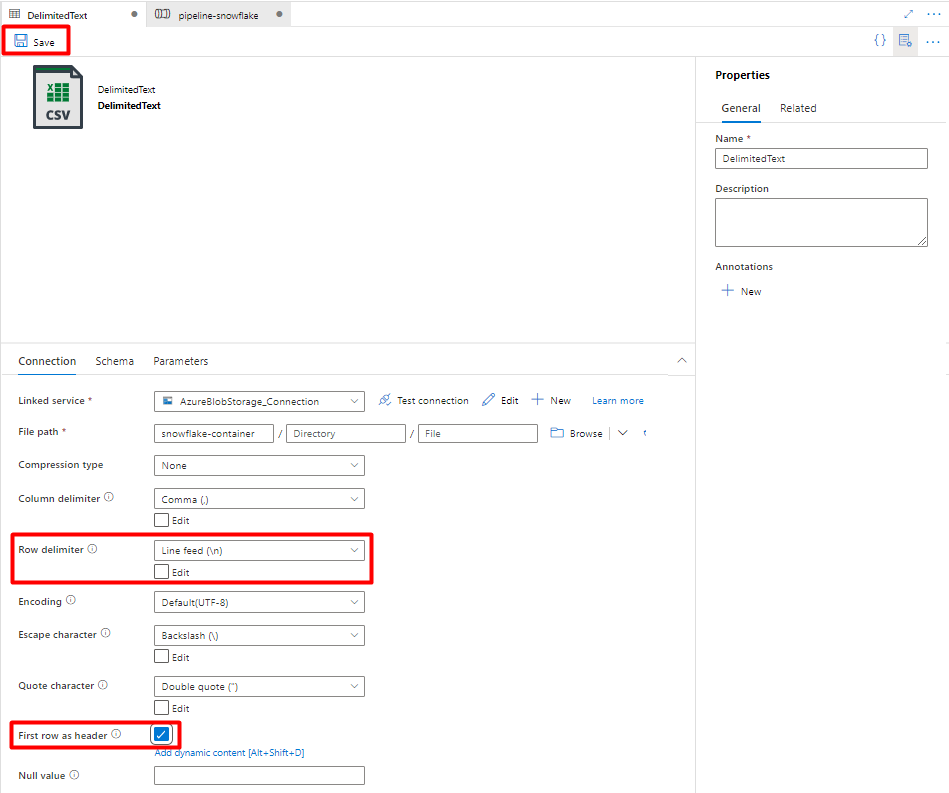
En Delimitador de fila, seleccione Avance de línea (\n).
Active la casilla Primera fila como encabezado.
Seleccione Guardar.
Paso 9: Configuración de la canalización
En el menú izquierdo, seleccione el icono Crear.
Seleccione Canalizaciones y, a continuación, seleccione el menú de puntos suspensivos de acciones de canalizaciones (
...).
Selecciona Nueva canalización.
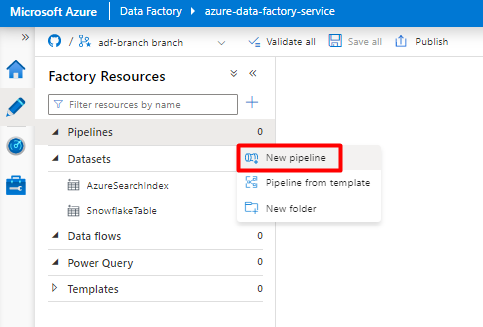
Cree y configure las actividades de Data Factory que copian desde Snowflake al contenedor de Azure Storage:
Expanda Mover & sección de transformación y arrastre y coloque la actividad Copiar datos en el lienzo del editor de canalizaciones en blanco.
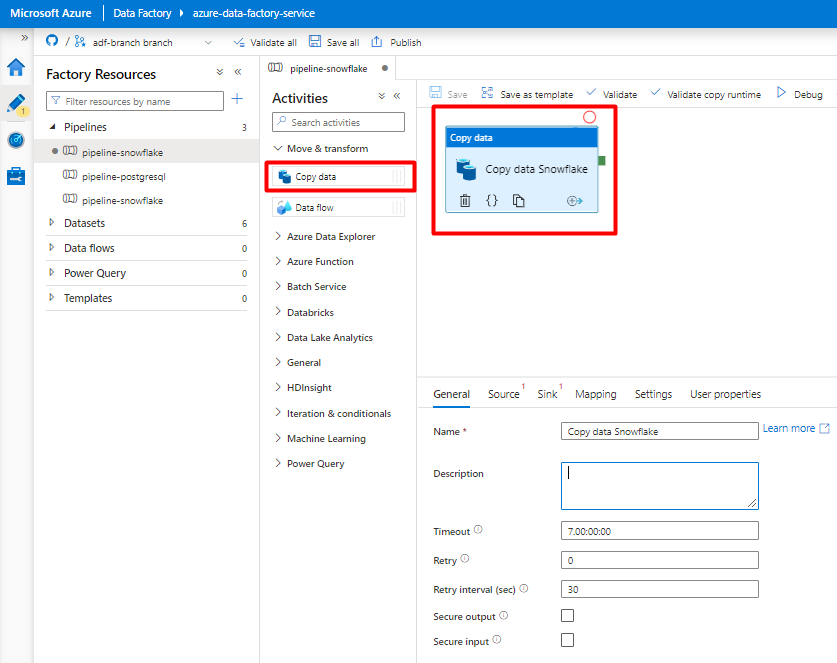
Abra la pestaña General. Acepte los valores predeterminados a menos que necesite personalizar la ejecución.
En la pestaña Origen, seleccione la tabla de Snowflake. Deje las opciones restantes con los valores predeterminados.

En la pestaña Receptor:
Seleccione el conjunto de datos Storage DelimitedText creado en el paso 8.
En Extensión de archivo, agregue .csv.
Deje las opciones restantes con los valores predeterminados.
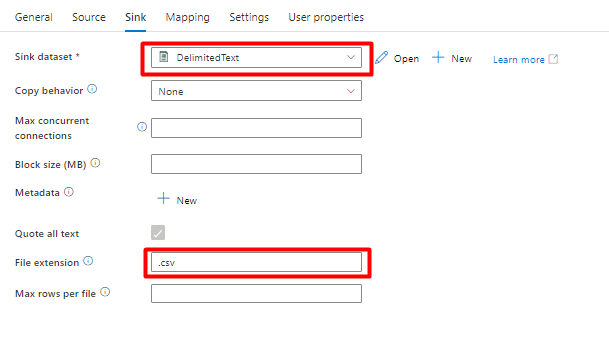
Seleccione Guardar.
Configure las actividades que copian de Azure Storage Blob a un índice de búsqueda:
Expanda Mover & sección de transformación y arrastre y coloque la actividad Copiar datos en el lienzo del editor de canalizaciones en blanco.
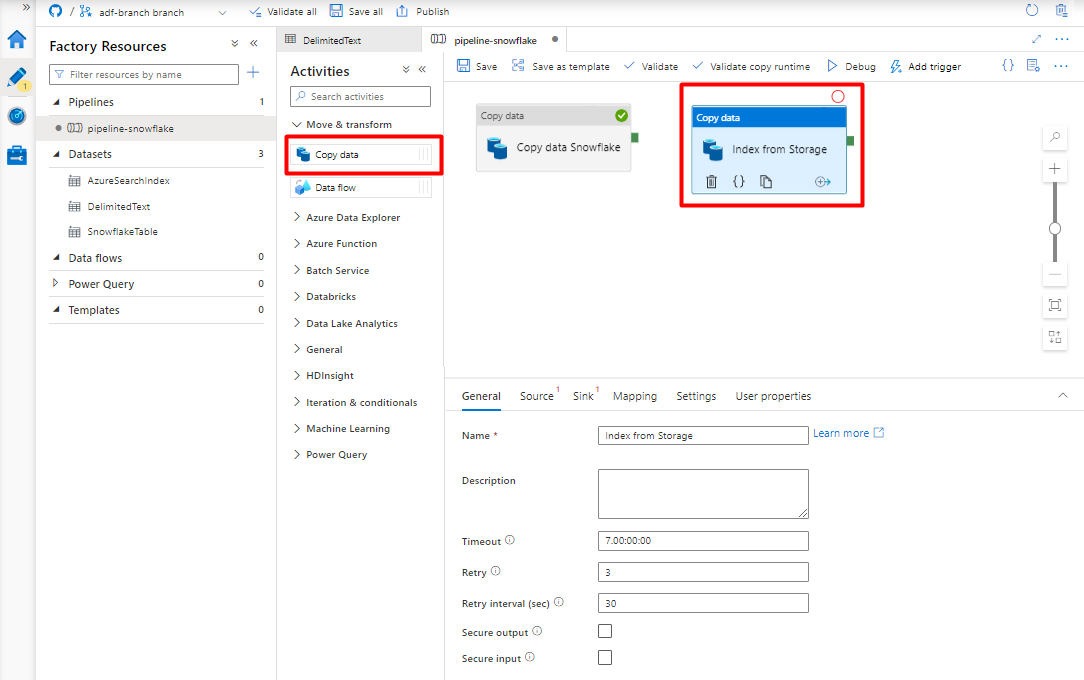
En la pestaña General, acepte los valores predeterminados a menos que necesite personalizar la ejecución.
En la pestaña Origen:
- Seleccione el conjunto de datos Storage DelimitedText creado en el paso 8.
- En el campo Tipo de ruta de acceso de archivo, seleccione Ruta de acceso de archivo comodín.
- Deje todos los campos restantes con los valores predeterminados.
En la pestaña Receptor, seleccione el índice de Azure Cognitive Search. Deje las opciones restantes con los valores predeterminados.
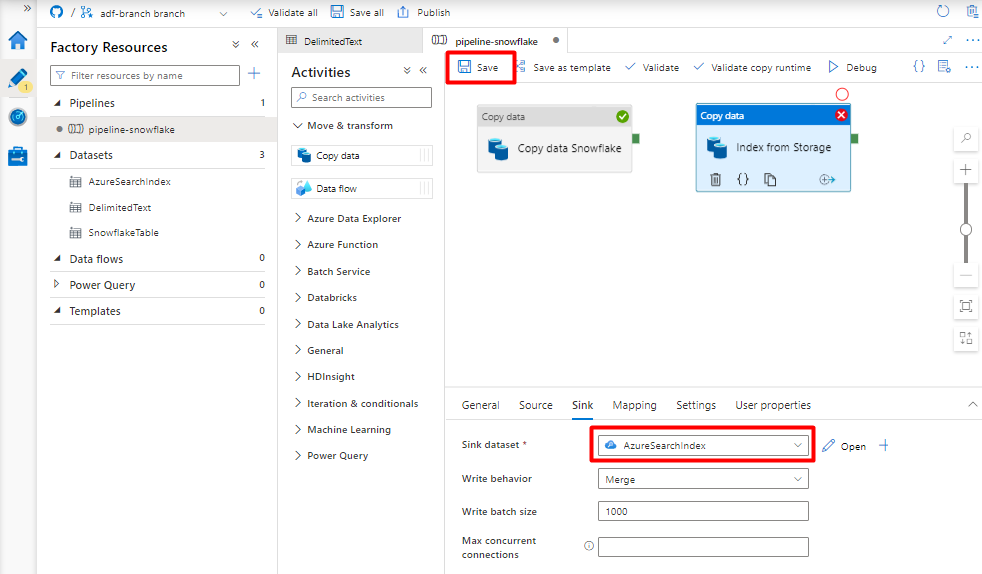
Seleccione Guardar.
Paso 10: Configuración del orden de las actividades
En el editor de lienzo de la canalización, seleccione el pequeño cuadrado verde situado en el borde del icono de actividad de canalización. Arrástrelo a la actividad "Índices desde la cuenta de Storage a Azure Cognitive Search" para establecer el orden de ejecución.
Seleccione Guardar.

Paso 11: Adición de un desencadenador de canalización
Seleccione Agregar desencadenador para programar la ejecución de la canalización y seleccione Nuevo/Editar.

En la lista desplegable Elegir desencadenador, seleccione Nuevo.

Revise las opciones del desencadenador para ejecutar la canalización y seleccione Aceptar.

Seleccione Guardar.
Seleccione Publicar.

Migración de una canalización de datos de PostgreSQL
En esta sección, se explica cómo copiar datos de una base de datos de PostgreSQL a un índice de Azure Cognitive Search. No hay ningún proceso para indexar directamente desde PostgreSQL a Azure Cognitive Search, por lo que esta sección incluye una fase de almacenamiento provisional que copia el contenido de la base de datos en un contenedor de blobs de Azure Storage. A continuación, realizará la indexación desde ese contenedor de almacenamiento provisional mediante una canalización de Data Factory.
Paso 1: Configuración del servicio vinculado de PostgreSQL
Inicie sesión en Azure Data Factory Studio con su cuenta de Azure.
Seleccione la factoría de datos y, a continuación, seleccione Continuar.
En el menú izquierdo, seleccione el icono Administrar.
En Servicios vinculados, seleccione Nuevo.
En el panel derecho, en la búsqueda del almacén de datos, escriba "postgresql". Seleccione el icono de PostgreSQL que representa dónde se encuentra la base de datos de PostgreSQL (Azure u otro) y seleccione Continuar. En este ejemplo, la base de datos de PostgreSQL se encuentra en Azure.

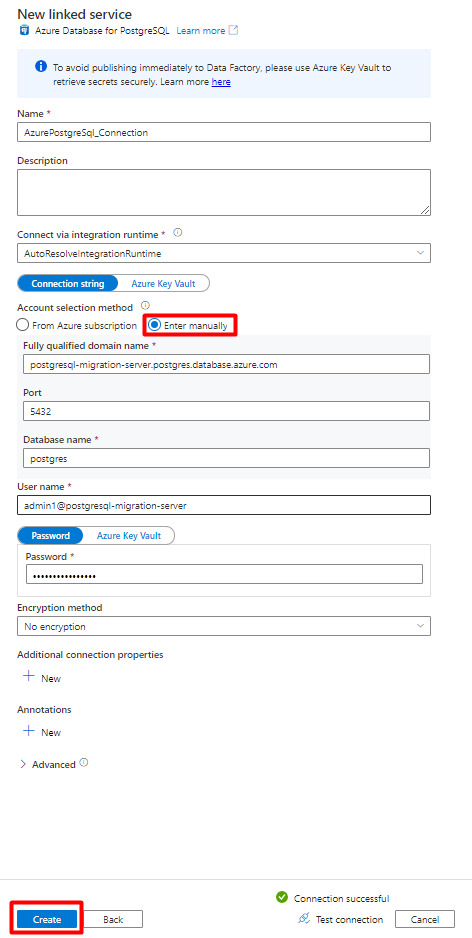
Rellene los valores de Nuevo servicio vinculado:
En Método de selección de cuenta, seleccione Especificar manualmente.
En la página de información general de la instancia de Azure Database for PostgreSQL en Azure Portal, pegue los valores siguientes en su campo respectivo:
- Agregue el nombre del servidor al nombre de dominio completo.
- Agregue el nombre de usuario administrador a Nombre de usuario.
- Agregue la base de datos a Nombre de base de datos.
- Escriba la contraseña del nombre de usuario administrador en Contraseña de nombre de usuario.
- Seleccione Crear.
Paso 2: Configuración del conjunto de datos de PostgreSQL
En el menú izquierdo, seleccione el icono Crear.
Seleccione Conjuntos de datos y, a continuación, seleccione el menú de puntos suspensivos de acciones de conjuntos de datos (
...).
Seleccione Nuevo conjunto de datos.
En el panel derecho, en la búsqueda del almacén de datos, escriba "postgresql". Seleccione el icono de Azure PostgreSQL. Seleccione Continuar.

Rellene los valores de Definir propiedades:
Elija el servicio vinculado de PostgreSQL creado en el paso 1.
Seleccione la tabla que quiere importar o indexar.
Seleccione Aceptar.
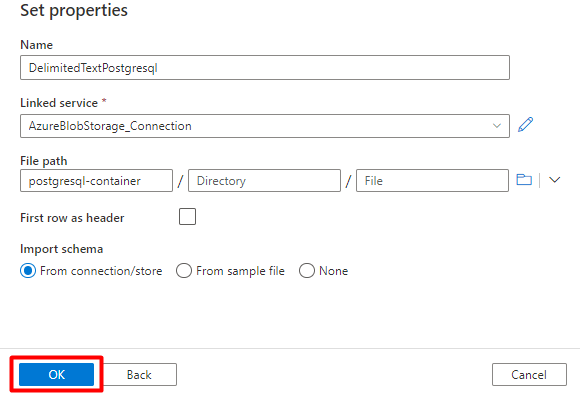
Seleccione Guardar.
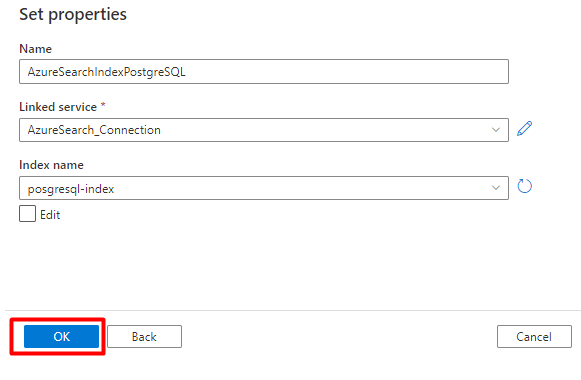
Paso 3: Creación de un índice nuevo en Azure Cognitive Search
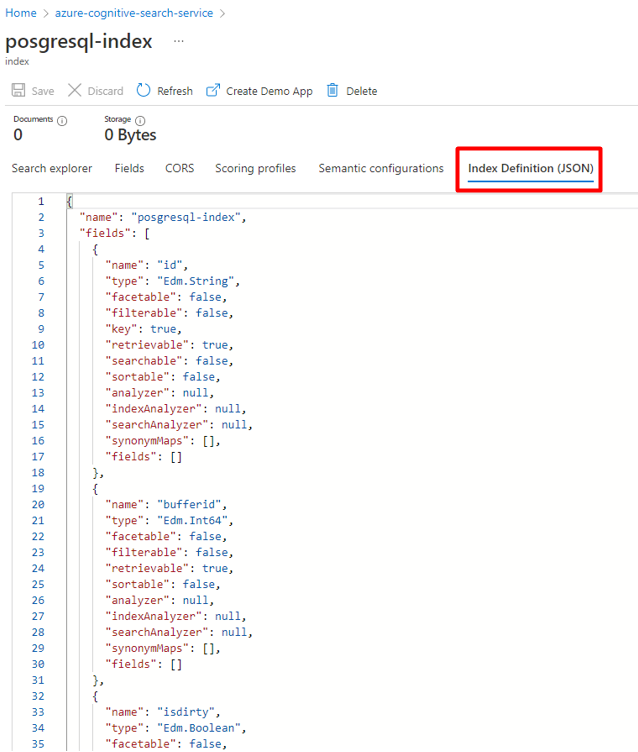
Cree un nuevo índice en el servicio Azure Cognitive Search con el mismo esquema que el que se usa para los datos de PostgreSQL.
Puede reasignar el índice que está usando actualmente para el conector de Power Query de PostgreSQL. En Azure Portal, busque el índice y seleccione Definición de índice (JSON). Seleccione la definición y cópiela en el cuerpo de la nueva solicitud de índice.
Paso 4: Configuración del servicio vinculado de Azure Cognitive Search
En el menú izquierdo, seleccione el icono Administrar.
En Servicios vinculados, seleccione Nuevo.
En el panel derecho, en la búsqueda del almacén de datos, escriba "search". Seleccione el icono de Azure Search y seleccione Continuar.
Rellene los valores de Nuevo servicio vinculado:
- Elija la suscripción de Azure donde reside el servicio Azure Cognitive Search.
- Elija el servicio Azure Cognitive Search que tiene el indexador del conector de Power Query.
- Seleccione Crear.
Paso 5: Configuración del conjunto de datos de Azure Cognitive Search
En el menú izquierdo, seleccione el icono Crear.
Seleccione Conjuntos de datos y, a continuación, seleccione el menú de puntos suspensivos de acciones de conjuntos de datos (
...).
Seleccione Nuevo conjunto de datos.
En el panel derecho, en la búsqueda del almacén de datos, escriba "search". Seleccione el icono de Azure Search y seleccione Continuar.
En Definir propiedades:
Seleccione Guardar.
Paso 6: Configuración del servicio vinculado de Azure Blob Storage
En el menú izquierdo, seleccione el icono Administrar.
En Servicios vinculados, seleccione Nuevo.
En el panel derecho, en la búsqueda del almacén de datos, escriba "storage". Seleccione el icono de Azure Blob Storage en la lista y, a continuación, seleccione Continuar.
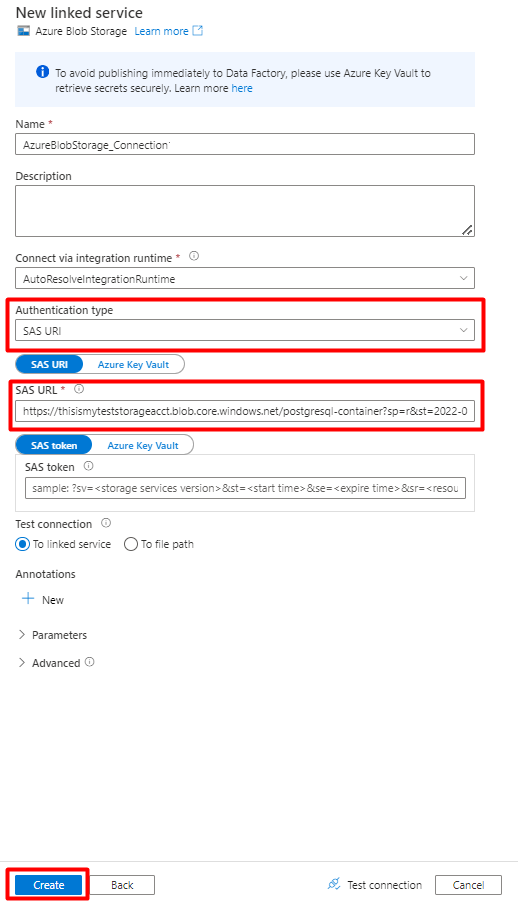
Rellene los valores de Nuevo servicio vinculado:
Elija el Tipo de autenticación: URI de SAS. Solo se puede usar este método para importar datos de PostgreSQL en Azure Blob Storage.
Genere una dirección URL de SAS para la cuenta de almacenamiento que va a usar para el almacenamiento provisional y copie la dirección URL de SAS del blob en el campo Dirección URL de SAS.
Seleccione Crear.
Paso 7: Configuración del conjunto de datos de Storage
En el menú izquierdo, seleccione el icono Crear.
Seleccione Conjuntos de datos y, a continuación, seleccione el menú de puntos suspensivos de acciones de conjuntos de datos (
...).
Seleccione Nuevo conjunto de datos.
En el panel derecho, en la búsqueda del almacén de datos, escriba "storage". Seleccione el icono de Azure Blob Storage en la lista y, a continuación, seleccione Continuar.
Seleccione DelimitedText como formato y, luego, seleccione Continuar.
En Delimitador de fila, seleccione Avance de línea (\n).
Active la casilla Primera fila como encabezado.
Seleccione Guardar.

Paso 8: Configuración de la canalización
En el menú izquierdo, seleccione el icono Crear.
Seleccione Canalizaciones y, a continuación, seleccione el menú de puntos suspensivos de acciones de canalizaciones (
...).
Selecciona Nueva canalización.
Cree y configure las actividades de Data Factory que copian desde PostgreSQL al contenedor de Azure Storage.
Expanda Mover & sección de transformación y arrastre y coloque la actividad Copiar datos en el lienzo del editor de canalizaciones en blanco.
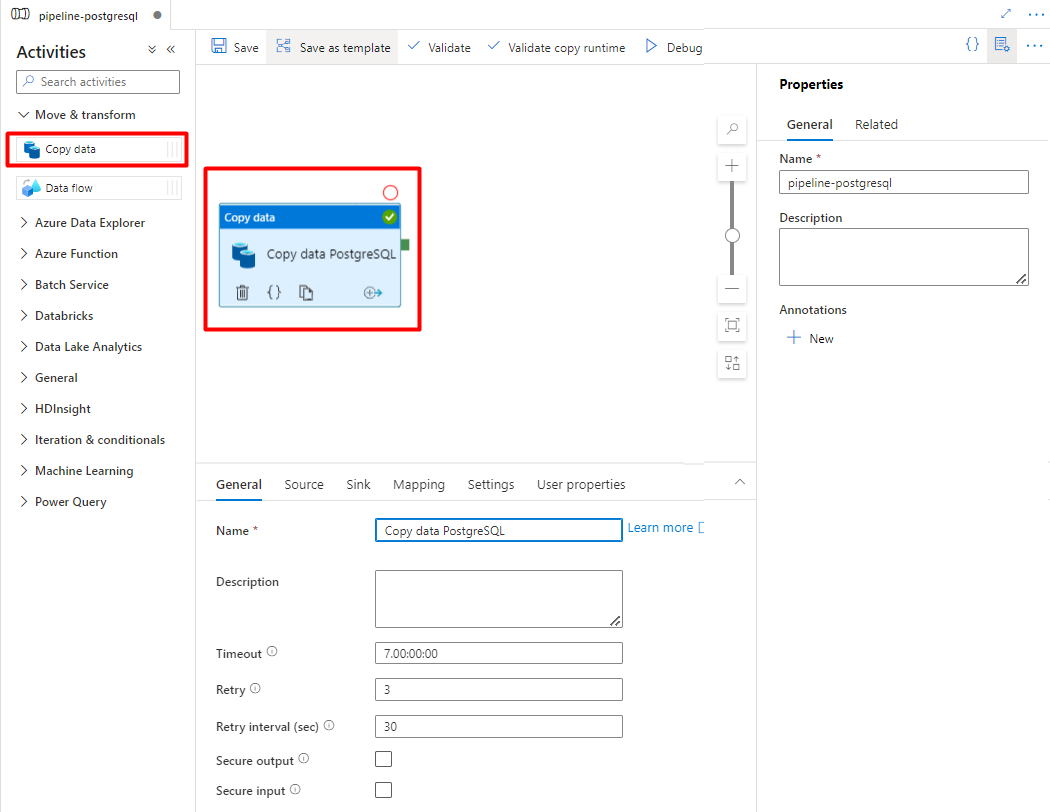
Abra la pestaña General y acepte los valores predeterminados a menos que necesite personalizar la ejecución.
En la pestaña Origen, seleccione la tabla de PostgreSQL. Deje las opciones restantes con los valores predeterminados.

En la pestaña Receptor:
Seleccione el conjunto de datos de PostgreSQL llamado Storage DelimitedText configurado en el paso 7.
En Extensión de archivo, agregue .csv.
Deje las opciones restantes con los valores predeterminados.

Seleccione Guardar.
Configure las actividades que copian de Azure Storage a un índice de búsqueda:
Expanda Mover & sección de transformación y arrastre y coloque la actividad Copiar datos en el lienzo del editor de canalizaciones en blanco.

En la pestaña General, deje los valores predeterminados a menos que necesite personalizar la ejecución.
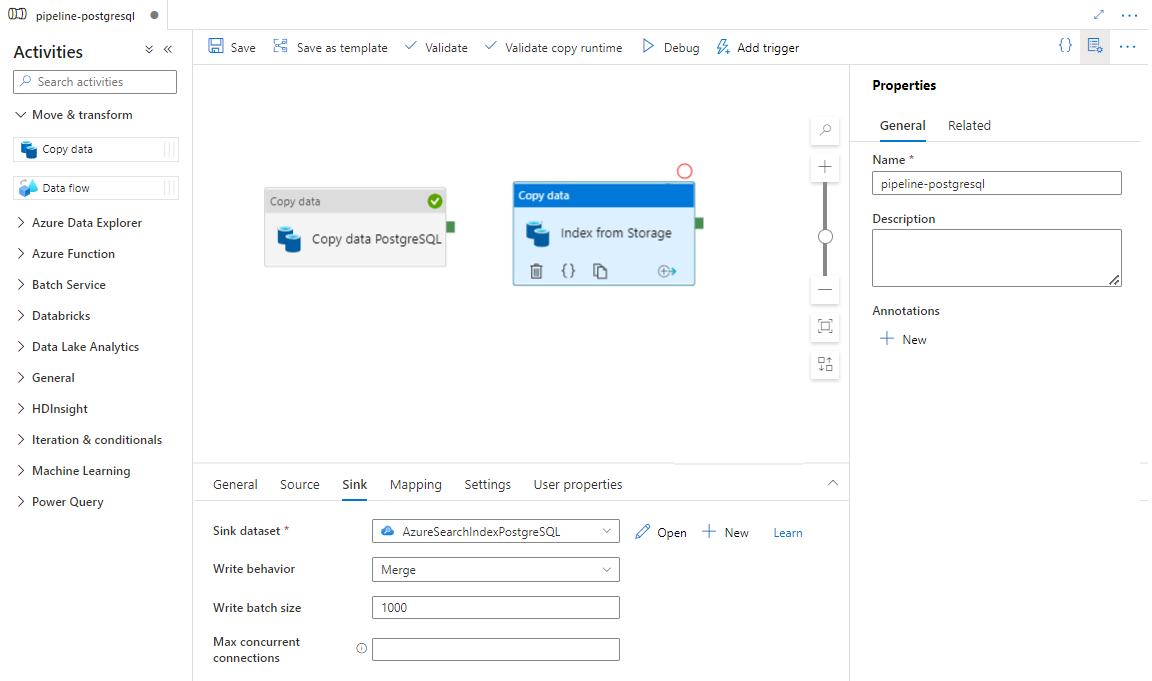
En la pestaña Origen:
- Seleccione el conjunto de datos de origen Storage configurado en el paso 7.
- En el campo Tipo de ruta de acceso de archivo, seleccione Ruta de acceso de archivo comodín.
- Deje todos los campos restantes con los valores predeterminados.

En la pestaña Receptor, seleccione el índice de Azure Cognitive Search. Deje las opciones restantes con los valores predeterminados.
Seleccione Guardar.
Paso 9: Configuración del orden de las actividades
En el editor de lienzo de la canalización, seleccione el pequeño cuadrado verde situado en el borde de la actividad de canalización. Arrástrelo a la actividad "Índices desde la cuenta de Storage a Azure Cognitive Search" para establecer el orden de ejecución.
Seleccione Guardar.

Paso 10: Adición de un desencadenador de canalización
Seleccione Agregar desencadenador para programar la ejecución de la canalización y seleccione Nuevo/Editar.
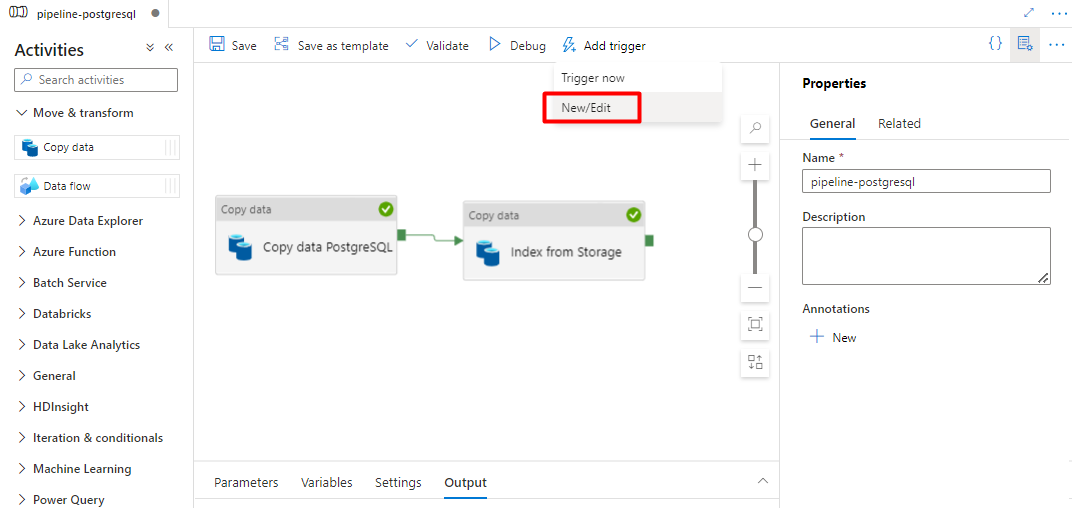
En la lista desplegable Elegir desencadenador, seleccione Nuevo.
Revise las opciones del desencadenador para ejecutar la canalización y seleccione Aceptar.
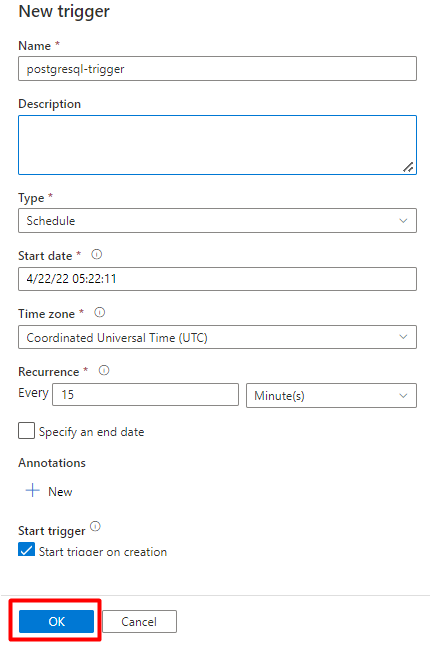
Seleccione Guardar.
Seleccione Publicar.
Contenido heredado para la versión preliminar del conector de Power Query
Se usa un conector de Power Query con un indexador de búsqueda para automatizar la ingesta de datos de varios orígenes de datos, incluidos los de otros proveedores de nube. Usa Power Query para recuperar los datos.
Los orígenes de datos admitidos en la versión preliminar incluyen:
- Amazon Redshift
- Elasticsearch
- PostgreSQL
- Objetos de Salesforce
- Informes de Salesforce
- Smartsheet
- Snowflake
Funcionalidad admitida
Los conectores de Power Query se usan en indizadores. Un indizador de Azure Cognitive Search es un rastreador (crawler) que extrae datos y metadatos utilizables en búsquedas de un origen de datos externo y rellena un índice basado en las asignaciones de un campo a otro entre el índice y su origen de datos. Este enfoque se denomina a veces "modelo de extracción", porque el servicio extrae datos sin que sea preciso escribir código que agregue datos en un índice. Los indizadores proporcionan un método cómodo para que los usuarios indexen el contenido de su origen de datos sin tener que escribir su propio rastreador o modelo de inserción.
Los indizadores que hacen referencia a los orígenes de datos de Power Query tienen el mismo nivel de compatibilidad con conjuntos de aptitudes, programaciones, lógica de detección de cambios de límite máximo y la mayoría de los parámetros que admiten otros indizadores.
Requisitos previos
Aunque ya no puede usar esta característica, tenía los siguientes requisitos durante la versión preliminar:
El servicio Azure Cognitive Search en una región admitida.
Vista previa del registro. Esta característica debe estar habilitada en el back-end.
Cuenta de Azure Blob Storage, que se usa como intermediario para los datos. Los datos fluirán desde el origen de datos, luego a Blob Storage y, después, al índice. Este requisito solo existe con la versión preliminar validada inicial.
Disponibilidad regional
La versión preliminar solo estaba disponible en los servicios de búsqueda en las siguientes regiones:
- Centro de EE. UU.
- Este de EE. UU.
- Este de EE. UU. 2
- Centro-Norte de EE. UU
- Norte de Europa
- Centro-sur de EE. UU.
- Centro-Oeste de EE. UU.
- Oeste de Europa
- Oeste de EE. UU.
- Oeste de EE. UU. 2
Limitaciones de vista previa
En esta sección se describen las limitaciones específicas de la versión preliminar actual.
No se admite la extracción de datos binarios del origen de datos.
No se admite la sesión de depuración.
Introducción al uso de Azure Portal
Azure Portal proporciona compatibilidad con los conectores de Power Query. Mediante el muestre de datos y la lectura de metadatos en el contenedor, el asistente Importar datos de Azure Cognitive Search puede crear un índice predeterminado, asignar campos de origen a campos de índice de destino y cargar el índice en una sola operación. Según el tamaño y la complejidad del origen de datos, puede tener un índice de búsqueda de texto completo y operativo en cuestión de minutos.
En el vídeo siguiente se muestra cómo configurar un conector Power Query en Azure Cognitive Search.
Paso 1: preparación de los datos de origen
Asegúrese de que el origen de datos contenga datos. El Asistente para importar datos lee los metadatos y realiza el muestreo de datos para inferir un esquema de índice, pero también carga los datos del origen de datos. Si faltan los datos, el asistente se detendrá y devolverá un error.
Paso 2: inicio del asistente para la importación de datos
Una vez aprobada la versión preliminar, el equipo de Azure Cognitive Search le proporcionará un vínculo de Azure Portal que usa una marca de características para que pueda acceder a los conectores de Power Query. Abra esta página e inicie el asistente desde la barra de comandos de la página del servicio Azure Cognitive Search; para ello, seleccione Importar datos.
Paso 3: selección de los datos
Hay algunos orígenes de datos de los que puede extraer datos mediante esta versión preliminar. Todos los orígenes de datos que usan Power Query incluirán la leyenda "Con tecnología de Power Query" en su icono. Seleccione el origen de datos.
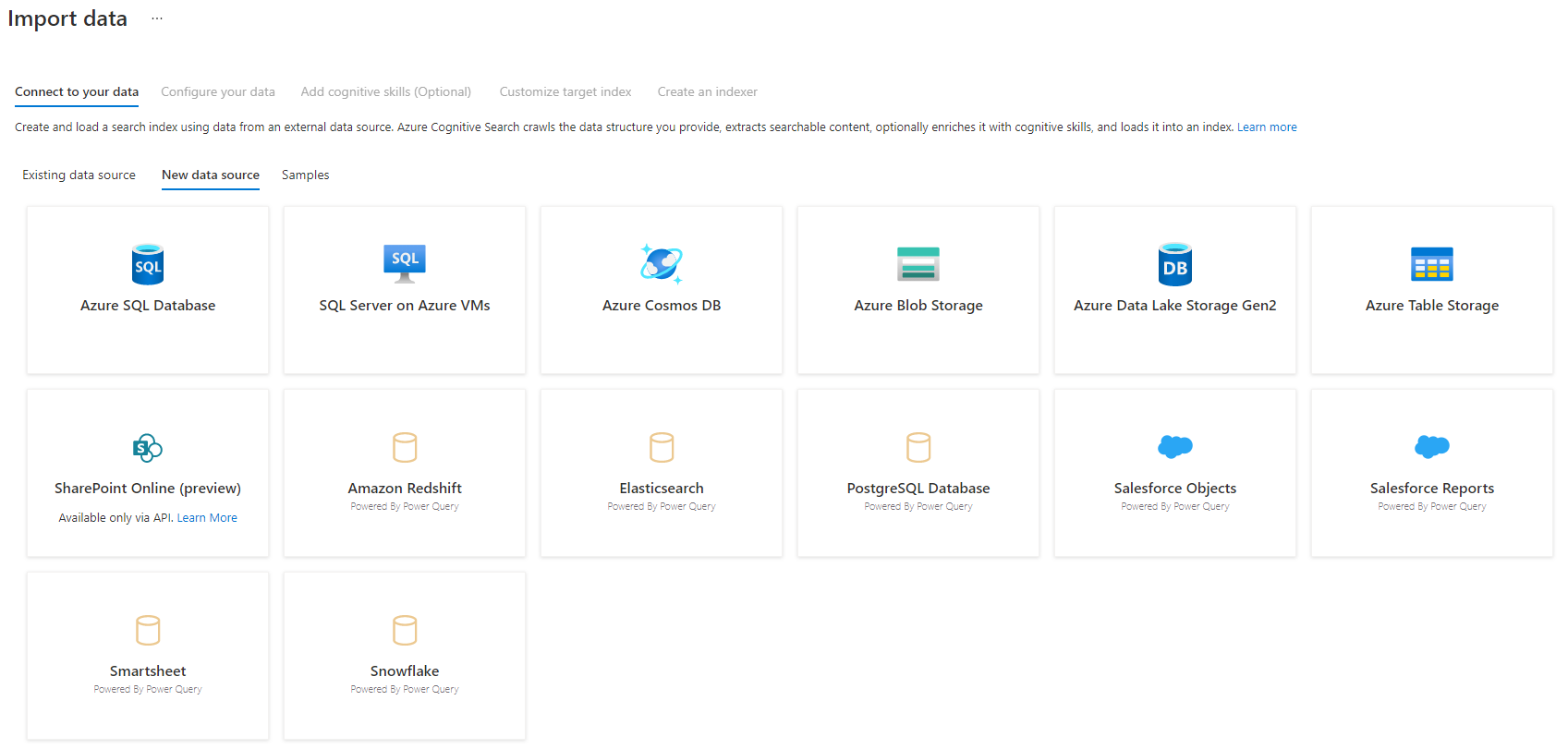
Una vez que haya seleccionado el origen de datos, seleccione Siguiente: Configuración de los datos para pasar a la sección siguiente.
Paso 4: configuración de los datos
En este paso, va a configurar la conexión. Cada origen de datos requerirá información diferente. Para algunos orígenes de datos, la documentación de Power Query proporciona detalles adicionales sobre cómo conectarse a los datos.
Una vez que haya proporcionado las credenciales de conexión, seleccione Siguiente.
Paso 5: selección de los datos
El Asistente para importación mostrará una vista previa de varias tablas que están disponibles en el origen de datos. En este paso, va a comprobar una tabla que contiene los datos que desea importar en el índice.
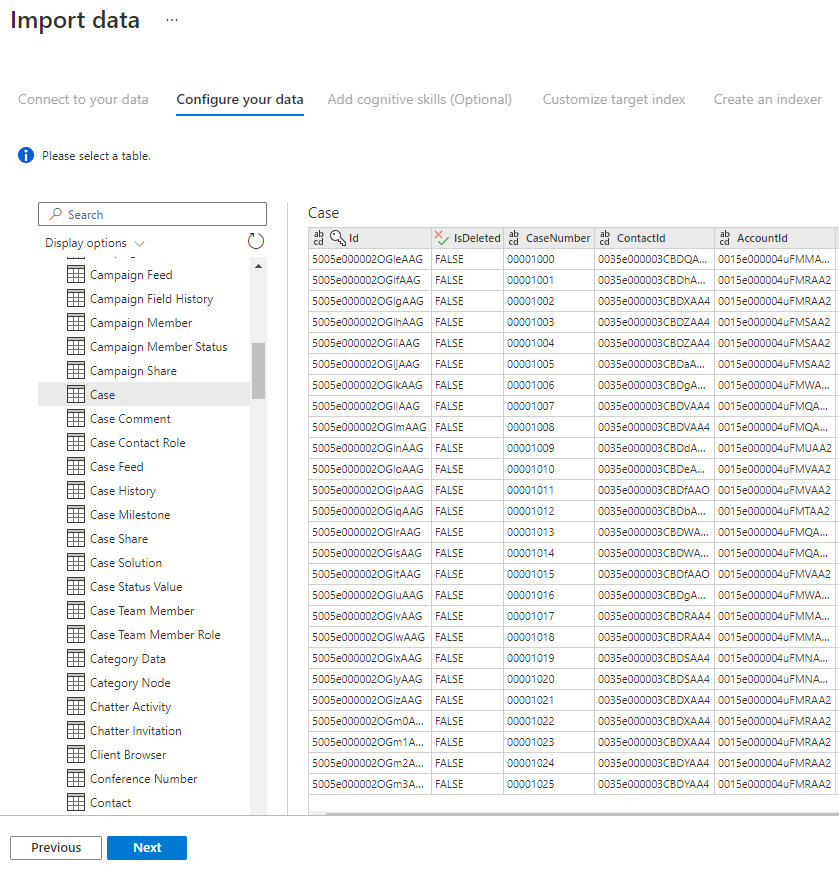
Una vez que haya seleccionado la tabla, seleccione Siguiente.
Paso 6: transformación de los datos (opcional)
Los conectores de Power Query proporcionan una experiencia de interfaz de usuario enriquecida que le permite manipular los datos para que pueda enviar los datos correctos al índice. Puede quitar columnas, filtrar filas y mucho más.
No es necesario transformar los datos antes de importarlos en Azure Cognitive Search.

Para obtener más información sobre cómo transformar datos con Power Query, consulte Uso de Power Query en Power BI Desktop.
Una vez transformados los datos, seleccione Siguiente.
Paso 7: adición de Azure Blob Storage
Actualmente, la versión preliminar del conector de Power Query requiere que proporcione una cuenta de almacenamiento de blobs. Este paso solo existe con la versión preliminar validada inicial. Esta cuenta de almacenamiento de blobs servirá como almacenamiento temporal para los datos que se mueven del origen de datos a un índice de Azure Cognitive Search.
Se recomienda proporcionar una cadena de conexión de acceso completo para la cuenta de almacenamiento:
{ "connectionString" : "DefaultEndpointsProtocol=https;AccountName=<your storage account>;AccountKey=<your account key>;" }
Para obtener la cadena de conexión de Azure Portal, vaya a la hoja de la cuenta de almacenamiento > Configuración > Claves (para las cuentas de almacenamiento del modelo clásico) o Configuración > Claves de acceso (para las cuentas de almacenamiento de Azure Resource Manager).
Después de proporcionar un nombre de origen de datos y una cadena de conexión, seleccione "Siguiente: adición de aptitudes cognitivas (opcional)".
Paso 8: adición de aptitudes cognitivas (opcional)
El enriquecimiento con IA es una extensión de indizadores que se puede usar para que el contenido sea más fácil de buscar.
Puede agregar cualquier enriquecimiento que agregue ventajas a su escenario. Cuando haya terminado, seleccione Siguiente: personalización del índice de destino.
Paso 9: personalización del índice de destino
En la página Índice, debería mostrarse una lista de campos con un tipo de datos y una serie de casillas de verificación para configurar los atributos del índice. El asistente puede generar una lista de campos basada en metadatos y mediante el muestreo de los datos de origen.
Puede seleccionar atributos de forma masiva si activa la casilla situada en la parte superior de una columna de atributos. Elija Se puede recuperar y Se puede buscar para cada campo que se debe devolver a una aplicación cliente y está sujeto a un proceso de búsqueda de texto completo. Observará que los números enteros no permiten búsquedas de texto completo o de texto parcial (los números se evalúan literalmente y suelen ser útiles en los filtros).
Revise la descripción de atributos de índice y analizadores de lenguaje para más información.
Dedique un momento a la revisión de las selecciones. Una vez que se ejecuta al asistente, se crean las estructuras de datos físicas y no podrá modificar la mayoría de las propiedades de estos campos sin quitar y volver a crear todos los objetos.
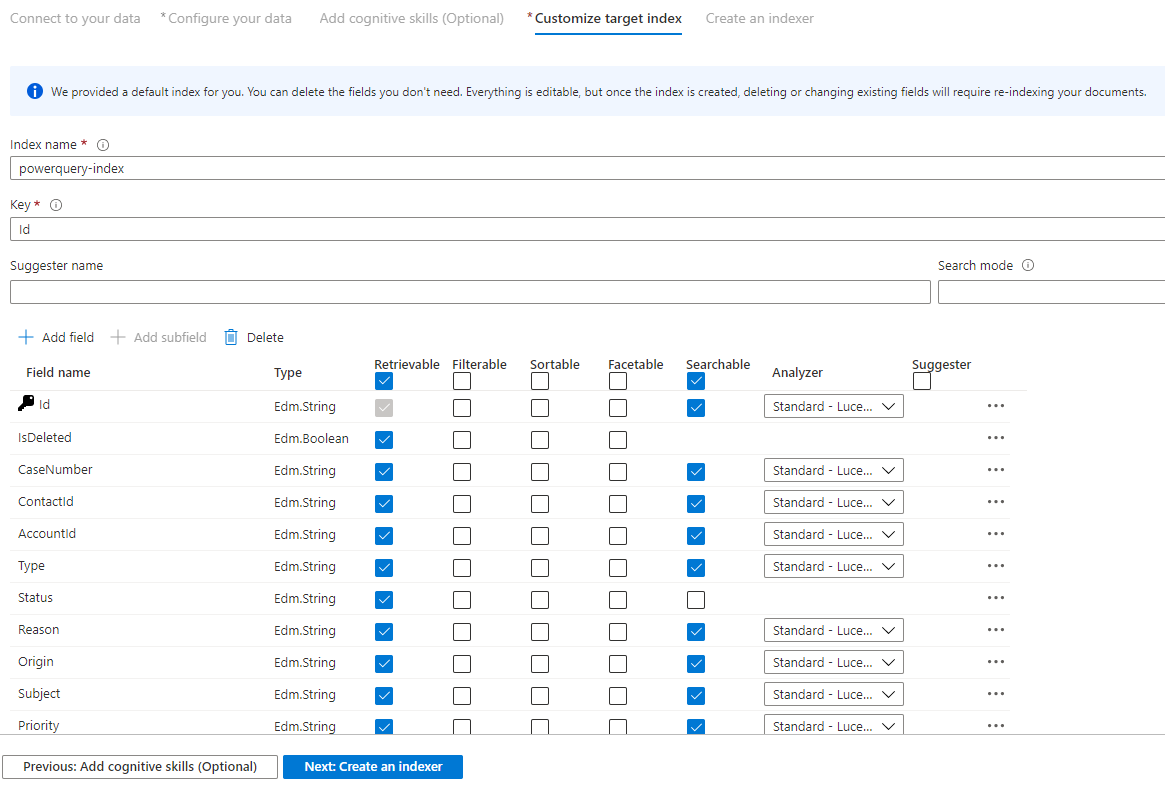
Cuando haya terminado, seleccione Siguiente: creación de un indizador.
Paso 10: creación de un indizador
El último paso crea el indizador. Al asignarle un nombre al indizador, este puede existir como un recurso independiente que se puede programar y administrar independientemente de los objetos de origen de datos y del de índice que se crearon en la misma secuencia del asistente.
La salida del Asistente para importar datos es un indizador que rastrea el origen de datos e importa los datos seleccionados a un índice en Azure Cognitive Search.
Al crear el indizador, opcionalmente puede elegir ejecutarlo según una programación y agregar la detección de cambios. Para agregar la detección de cambios, designe una columna como "límite máximo".

Cuando haya terminado de rellenar esta página, seleccione Enviar.
Directiva de detección de cambios de límite superior
Esta directiva de detección de cambios se basa en una columna de "marca de límite superior" que captura la versión o la hora en que se actualizó por última vez una fila.
Requisitos
- Todas las inserciones especifican un valor para la columna.
- Todas las actualizaciones de un elemento también cambian el valor de la columna.
- El valor de esta columna aumenta con cada inserción o actualización.
Nombres de columna no admitidos
Los nombres de campo de un índice de Azure Cognitive Search deben cumplir ciertos requisitos. Uno de estos requisitos es que no se permiten algunos caracteres, como "/". Si un nombre de columna de la base de datos no cumple estos requisitos, la detección del esquema del índice no reconocerá la columna como un nombre de campo válido, ni se mostrará esa columna como un campo sugerido para el índice. Normalmente, el uso de asignaciones de campos solucionaría este problema, pero no se admiten en el portal.
Para indexar el contenido de una columna de la tabla que tiene un nombre de campo no admitido, cambie el nombre de la columna durante la fase "Transformación de los datos" del proceso de importación de datos. Por ejemplo, puede cambiar el nombre de una columna denominada "Código postal o código postal de facturación" por "código postal". Al cambiar el nombre de la columna, la detección del esquema de índice la reconocerá como un nombre de campo válido y la agregará como una sugerencia a la definición del índice.
Pasos siguientes
En este artículo, se ha explicado cómo extraer datos mediante los conectores de Power Query. Dado que esta característica en versión preliminar está descontinuada, también se explica cómo migrar las soluciones existentes a un escenario admitido.
Para obtener más información sobre los indizadores, consulte Indizadores en Azure Cognitive Search.