Fragmentación de documentos grandes para soluciones de vector de búsqueda en Azure AI Search
La creación de particiones de documentos grandes en fragmentos más pequeños puede ayudarle a mantenerse bajo los límites máximos de entrada de tokens de inserción de modelos. Por ejemplo, la longitud máxima del texto de entrada para los modelos de inserción de Azure OpenAI es de 8191 tokens. Dado que cada token tiene alrededor de cuatro caracteres de texto para los modelos comunes de OpenAI, este límite máximo equivale a aproximadamente 6 000 palabras de texto. Si usas estos modelos para generar inserciones, es fundamental que el texto de entrada permanezca bajo el límite. La creación de particiones del contenido en fragmentos garantiza que los datos se puedan procesar mediante los modelos de inserción usados para rellenar almacenes de vectores y conversiones de consultas de texto a vector.
En este artículo se describen varios enfoques para la fragmentación de datos. La fragmentación solo es necesaria si los documentos de origen son demasiado grandes para el tamaño máximo de entrada impuesto por los modelos.
Nota:
Si usa la versión disponible con carácter general de vector de búsqueda, la fragmentación y la inserción de datos requieren código externo, como biblioteca o una aptitud personalizada. Una nueva característica denominada vectorización integrada, actualmente en versión preliminar, ofrece fragmentación e inserción de datos internos. La vectorización integrada depende de indexadores, conjuntos de aptitudes, la aptitud División de texto y la aptitud AzureOpenAiEmbedding (o una aptitud personalizada). Si no puede usar las características en vista previa (gb), los ejemplos de este artículo proporcionan una ruta de acceso alternativa.
Técnicas comunes de fragmentación
Estas son algunas técnicas comunes de fragmentación, empezando por el método más usado:
Fragmentos de tamaño fijo: definir un tamaño fijo que sea suficiente para párrafos semánticamente significativos (por ejemplo, 200 palabras) y permitir una superposición (por ejemplo, 10-15 % del contenido) puede dar como resultado fragmentos buenos como entrada para insertar generadores de vectores.
Fragmentos de tamaño variable basados en contenido: divide los datos en función de las características de contenido, como las marcas de puntuación de fin de oración, los marcadores de fin de línea o el uso de características en las bibliotecas de procesamiento del lenguaje natural (NLP). La estructura del lenguaje Markdown también se puede usar para dividir los datos.
Personaliza o itera en una de las técnicas anteriores. Por ejemplo, al trabajar con documentos grandes, puedes usar fragmentos de tamaño variable, pero también anexar el título del documento a fragmentos del centro del documento para evitar la pérdida de contexto.
Consideraciones de superposición de contenido
Al fragmentar datos, la superposición de una pequeña cantidad de texto entre fragmentos puede ayudar a conservar el contexto. Se recomienda comenzar con una superposición de aproximadamente el 10 %. Por ejemplo, dado un tamaño fijo de fragmento de 256 tokens, empezarías a probar con una superposición de 25 tokens. La cantidad real de superposición varía según el tipo de datos y el caso de uso específico, pero hemos averiguado que el 10-15 % funciona en muchos escenarios.
Factores para fragmentar datos
Cuando se trata de fragmentar datos, piensa en estos factores:
Forma y densidad de los documentos. Si necesitas texto o pasajes intactos, los fragmentos más grandes y la fragmentación variable que conserva la estructura de oraciones pueden generar mejores resultados.
Consultas de usuario: los fragmentos más grandes y las estrategias superpuestas ayudan a conservar el contexto y la riqueza semántica de las consultas destinadas a información específica.
Los modelos de lenguaje de gran tamaño (LLM) tienen directrices de rendimiento para el tamaño del fragmento. Debes establecer un tamaño de fragmento que funcione mejor para todos los modelos que usas. Por ejemplo, si usas modelos para resúmenes e incrustaciones, elige un tamaño de fragmento óptimo que funcione para ambos.
Cómo encaja la fragmentación en el flujo de trabajo
Si tiene documentos grandes, debe insertar un paso de fragmentación en los flujos de trabajo de indexación y consulta que divida texto grande. Al usar la vectorización integrada (versión preliminar), se aplica una estrategia de fragmentación predeterminada mediante la aptitud de división de texto. También puede aplicar una estrategia de fragmentación personalizada mediante una aptitud personalizada. Algunas bibliotecas que proporcionan fragmentación incluyen:
La mayoría de las bibliotecas proporcionan técnicas comunes de fragmentación para un tamaño fijo, un tamaño variable o una combinación. También puede especificar una superposición que duplica una pequeña cantidad de contenido en cada fragmento para la conservación del contexto.
Ejemplos de fragmentación
Los siguientes ejemplos demuestran cómo se aplican las estrategias de fragmentación al archivo PDF Libro electrónico Earth at Night de la NASA:
Ejemplo de aptitud Separador de texto
La fragmentación de datos integrada a través de la aptitud Separador de texto está en versión preliminar pública. Use una API de REST en versión preliminar o un paquete beta del SDK de Azure para este escenario.
Esta sección describe la fragmentación de datos integrada con un enfoque basado en aptitudes y parámetros de aptitudes de separación de texto.
Puede encontrar un cuaderno de muestra para este ejemplo en el repositorio azure-search-vector-samples.
Establezca textSplitMode para dividir el contenido en fragmentos más pequeños:
pages(valor predeterminado). Los fragmentos se componen de varias oraciones.sentences. Los fragmentos se componen de frases simples. Lo que constituye una "oración" depende del lenguaje. En inglés, se usa una puntuación final de oración estándar, como.o!. El idioma se controla mediante el parámetrodefaultLanguageCode.
El parámetro pages agrega parámetros adicionales:
maximumPageLengthdefine el número máximo de caracteres 1 en cada fragmento. El separador de texto evita dividir las oraciones, por lo que el recuento de caracteres real depende del contenido.pageOverlapLengthdefine cuántos caracteres del final de la página anterior se incluyen al principio de la página siguiente. Si se establece, debe ser menor que la mitad de la longitud máxima de la página.maximumPagesToTakedefine cuántas páginas o fragmentos se van a tomar de un documento. El valor predeterminado es 0, lo que significa tomar todas las páginas o fragmentos del documento.
1 Los caracteres no se alinean con la definición de un token. El número de tokens medidos por el LLM podría ser diferente del tamaño de carácter medido por la aptitud División de texto.
La siguiente tabla muestra cómo la elección de parámetros afecta el recuento total de fragmentos del libro electrónico Earth at Night:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Recuento total de fragmentos |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
N/D | N/D | 13361 |
El uso de textSplitMode de pages da como resultado que la mayoría de los fragmentos tengan un recuento total de caracteres cercano a maximumPageLength. El recuento de caracteres de fragmento varía debido a las diferencias en las que los límites de oración se encuentran dentro del fragmento. La longitud del token de fragmento varía debido a las diferencias en el contenido del fragmento.
Los histogramas siguientes muestran cómo la distribución de la longitud de caracteres de fragmento se compara con la longitud del token de fragmento para gpt-35-turbo cuando se usa un textSplitMode de pages, un maximumPageLength de 2000 y un pageOverlapLength de 500 en el libro electrónico Earth at Night:

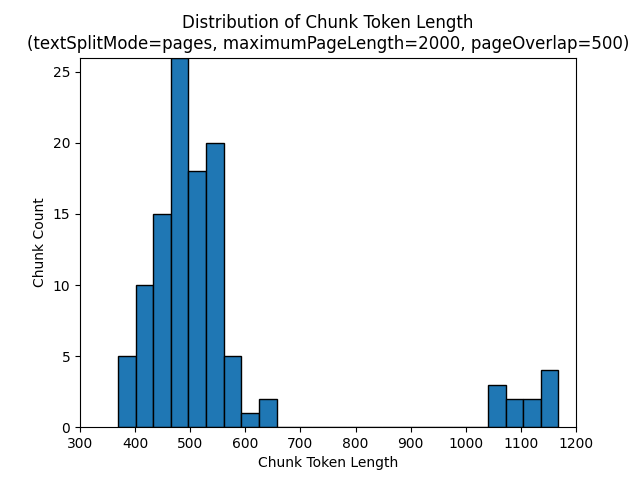
El uso de un textSplitMode de sentences da como resultado un gran número de fragmentos que constan de oraciones individuales. Estos fragmentos son significativamente más pequeños que los producidos por pages y el recuento de tokens de los fragmentos coincide más con el recuento de caracteres.
Los histogramas siguientes muestran cómo la distribución de la longitud de caracteres de fragmento se compara con la longitud del token de fragmento para gpt-35-turbo cuando se usa un textSplitMode de sentences en el libro electrónico Earth at Night:
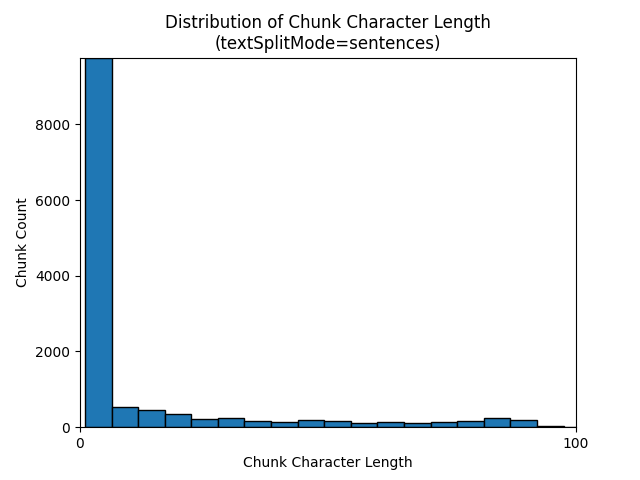
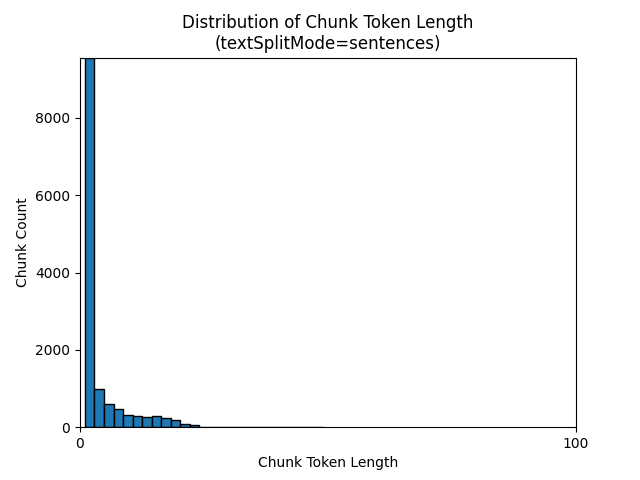
La elección óptima de parámetros depende de cómo se usarán los fragmentos. Para la mayoría de las aplicaciones, se recomienda empezar con los siguientes parámetros predeterminados:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
Ejemplo de fragmentación de datos de LangChain
LangChain proporciona cargadores de documentos y divisores de texto. En este ejemplo se muestra cómo cargar un PDF, obtener recuentos de tokens y configurar un divisor de texto. La obtención de recuentos de tokens le ayuda a tomar una decisión informada sobre el ajuste de tamaño de fragmentos.
Puede encontrar un cuaderno de muestra para este ejemplo en el repositorio azure-search-vector-samples.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
La salida indica 200 documentos o páginas en el PDF.
Para obtener un recuento estimado de tokens para estas páginas, use TikToken.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
La salida indica que ninguna página tiene cero tokens, la longitud media del token por página es de 189 tokens y el número máximo de tokens de cualquier página es 1583.
Conocer el tamaño medio y máximo del token le proporciona información sobre cómo establecer el tamaño del fragmento. Aunque podría usar la recomendación estándar de 2 000 caracteres con una superposición de 500 caracteres, en este caso tiene sentido reducirse según los recuentos de tokens del documento de ejemplo. De hecho, establecer un valor de superposición demasiado grande puede provocar que no aparezca ninguna superposición.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
La salida de dos fragmentos consecutivos muestra el texto del primer fragmento que se superpone al segundo fragmento. La salida se edita ligeramente para mejorar la legibilidad.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Habilidad personalizada
Una muestra de generación de fragmentación e inserción de tamaño fijo muestra la generación de fragmentación e inserción de vectores mediante modelos de inserción de Azure OpenAI. En este ejemplo se usa una aptitud personalizada de Búsqueda de Azure AI en el repositorio Power Skills para ajustar el paso de fragmentación.