Tutorial: Supervisión de un clúster de Service Fabric en Azure
La supervisión y el diagnóstico son fundamentales para el desarrollo, las pruebas y la implementación de flujos de trabajo en cualquier entorno de la nube. Este tutorial es la segunda parte de una serie, y en él se muestra cómo supervisar y diagnosticar un clúster de Service Fabric mediante eventos, contadores de rendimiento e informes de mantenimiento. Para más información, lea la información general sobre la supervisión de clústeres y la supervisión de infraestructuras.
En este tutorial, aprenderá a:
- Visualización de eventos de Service Fabric
- Consulta de las API del servicio EventStore para obtener eventos de clúster
- Supervisar la infraestructura y recopilar contadores de rendimiento
- Ver los informes de mantenimiento del clúster
En esta serie de tutoriales, se aprende a:
- Creación de un clúster de Windows en Azure mediante una plantilla
- Supervisión de un clúster
- Escalado o reducción horizontal
- Actualización del entorno en tiempo de ejecución de un clúster
- Eliminación de un clúster
Nota:
Se recomienda usar el módulo Azure Az de PowerShell para interactuar con Azure. Consulte Instalación de Azure PowerShell para empezar. Para más información sobre cómo migrar al módulo Az de PowerShell, consulte Migración de Azure PowerShell de AzureRM a Az.
Prerrequisitos
Antes de empezar este tutorial:
- Si no tiene ninguna suscripción a Azure, cree una cuenta gratuita
- Instale Azure Powershell o la CLI de Azure.
- Cree un clúster de Windows seguro.
- Configure la recopilación de diagnósticos para el clúster.
- Habilite el servicio EventStore en el clúster.
- Configure los registros de Azure Monitor y el agente de Log Analytics para el clúster.
Visualización de eventos de Service Fabric mediante los registros de Azure Monitor
Los registros de Azure Monitor recopilan y analizan la telemetría de las aplicaciones y los servicios hospedados en la nube y proporcionan herramientas de análisis para ayudarle a maximizar su disponibilidad y rendimiento. Puede ejecutar consultas en los registros de Azure Monitor para obtener conclusiones sobre lo que sucede en el clúster y solucionar sus problemas.
Para acceder la solución Service Fabric Analytics, vaya a Azure Portal y seleccione el grupo de recursos en el que creó la solución Service Fabric Analytics.
Seleccione el recurso ServiceFabric(mysfomsworkspace) .
En Información general, verá iconos en forma de gráfico para cada una de las soluciones habilitadas, entre ellos uno para Service Fabric. Haga clic en el grafo de Service Fabric para ir a la solución Service Fabric Analytics.
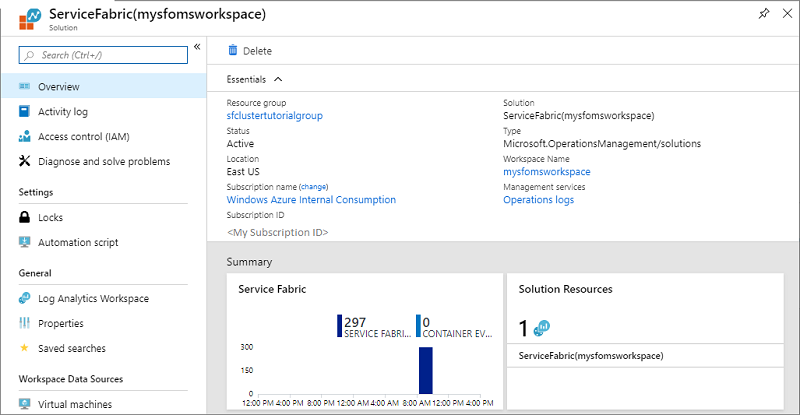
En la siguiente imagen se muestra la página principal de la solución Service Fabric Analytics. Esta página principal proporciona una instantánea de lo que sucede en el clúster.
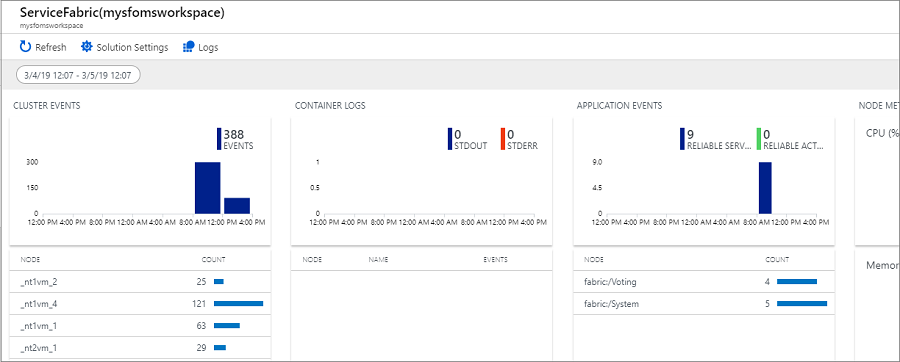
Si habilitó el diagnóstico durante la creación del clúster, puede ver eventos de
- Eventos de clúster de Service Fabric
- Eventos del modelo de programación de Reliable Actors
- Eventos del modelo de programación de Reliable Services
Nota:
Además de los eventos de Service Fabric estándar, se pueden recopilar eventos del sistema más detallados mediante la actualización de la configuración de la extensión de diagnósticos.
Visualización de eventos de Service Fabric, como acciones en nodos
En la página de Service Fabric Analytics, haga clic en el gráfico de Eventos de clúster. Aparecen los registros de todos los eventos del sistema que se han recopilado. Como referencia, proceden de WADServiceFabricSystemEventsTable en la cuenta de Azure Storage y, de manera similar, los eventos de Reliable Services y Reliable Actors que ve a continuación provienen de esas tablas respectivas.
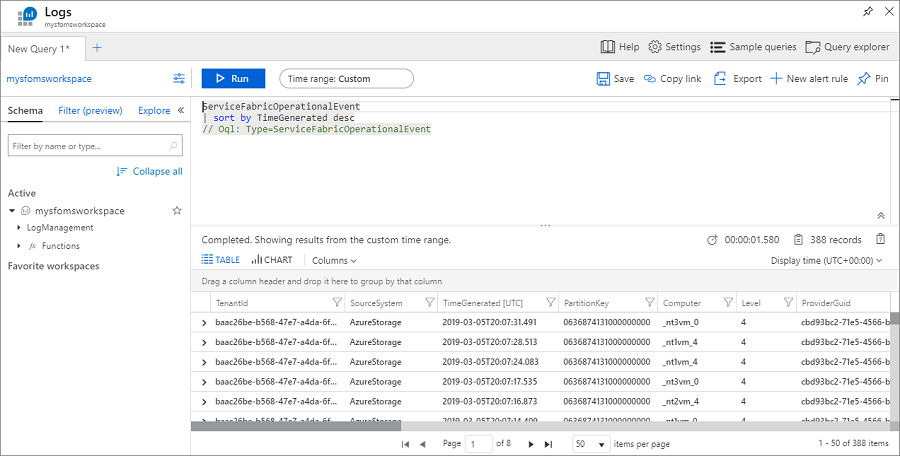
La consulta usa el lenguaje de consulta Kusto, que se puede modificar para optimizar la búsqueda. Por ejemplo, para buscar todas las acciones realizadas en los nodos del clúster, puede usar la consulta siguiente. Los identificadores de evento que se usan a continuación se encuentran en la referencia de eventos del canal operativo.
ServiceFabricOperationalEvent
| where EventId < 25627 and EventId > 25619
El lenguaje de consulta Kusto es eficaz. Estas son algunas otras consultas útiles.
Cree una tabla de búsqueda ServiceFabricEvent como una función definida por el usuario y, para ello, guarde la consulta como una función con el alias ServiceFabricEvent:
let ServiceFabricEvent = datatable(EventId: int, EventName: string)
[
...
18603, 'NodeUpOperational',
18604, 'NodeDownOperational',
...
];
ServiceFabricEvent
Devolver eventos operativos registrados en la última hora:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Devolver eventos operativos con EventId == 18604 y EventName == "NodeDownOperational":
ServiceFabricOperationalEvent
| where EventId == 18604
| project EventId, EventName = 'NodeDownOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Devolver eventos operativos con EventId == 18604 y EventName == "NodeUpOperational":
ServiceFabricOperationalEvent
| where EventId == 18603
| project EventId, EventName = 'NodeUpOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Devolver informes de mantenimiento con HealthState == 3 (Error) y extraer propiedades adicionales del campo EventMessage:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Devolver un gráfico temporal de eventos con EventId! = 17523:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| where EventId != 17523
| summarize Count = count() by Timestamp = bin(TimeGenerated, 1h), strcat(tostring(EventId), " - ", case(EventName != "", EventName, "Unknown"))
| render timechart
Obtener eventos operativos de Service Fabric agregados con el servicio y el nodo específicos:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Representar el recuento de eventos de Service Fabric por EventId/EventName mediante una consulta entre recursos:
app('PlunkoServiceFabricCluster').traces
| where customDimensions.ProviderName == 'Microsoft-ServiceFabric'
| extend EventId = toint(customDimensions.EventId), TaskName = tostring(customDimensions.TaskName)
| where EventId != 17523
| join kind=leftouter ServiceFabricEvent on EventId
| extend EventName = case(EventName != '', EventName, 'Undocumented')
| summarize ["Event Count"]= count() by bin(timestamp, 30m), EventName = strcat(tostring(EventId), " - ", EventName)
| render timechart
Visualización de eventos de aplicación de Service Fabric
Puede ver los eventos de las aplicaciones de Reliable Services y Reliable Actors implementadas en el clúster. En la página de Service Fabric Analytics, haga clic en gráfico de Eventos de aplicaciones.
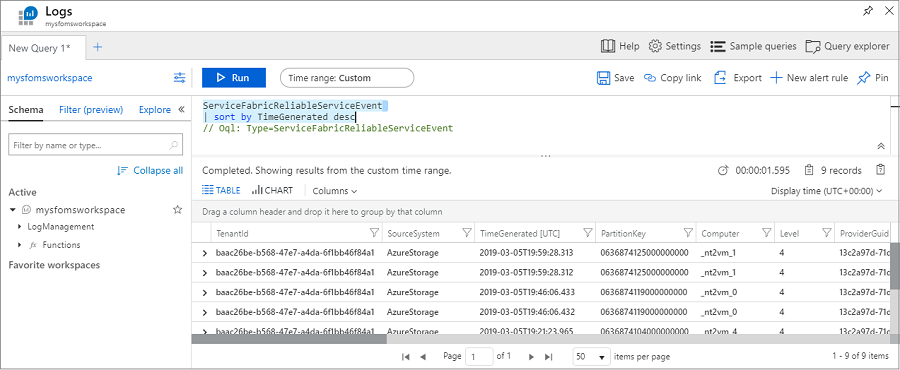
Ejecute la siguiente consulta para ver los eventos de las aplicaciones de Reliable Services:
ServiceFabricReliableServiceEvent
| sort by TimeGenerated desc
Puede ver eventos diferentes para cuando el servicio runasync se inicia y se completa, lo que ocurre habitualmente en las implementaciones y las actualizaciones.
También puede encontrar eventos para el servicio confiable con ServiceName == "fabric:/Watchdog/WatchdogService":
ServiceFabricReliableServiceEvent
| where ServiceName == "fabric:/Watchdog/WatchdogService"
| project TimeGenerated, EventMessage
| order by TimeGenerated desc
Los eventos de Reliable Actors pueden verse de forma similar:
ServiceFabricReliableActorEvent
| sort by TimeGenerated desc
Para configurar eventos más detallados para Reliable Actors, debe cambiar scheduledTransferKeywordFilter en la configuración de la extensión de diagnóstico de la plantilla del clúster. Los detalles de los valores de estos están en la referencia de eventos de Reliable Actors.
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
Visualización de contadores de rendimiento con los registros de Azure Monitor
Para ver los contadores de rendimiento, vaya a Azure Portal y al grupo de recursos en el que creó la solución de Service Fabric Analytics.
Seleccione el recurso ServiceFabric(mysfomsworkspace) , luego Área de trabajo de Log Analytics y, finalmente, Configuración avanzada.
Haga clic en Datos y luego en Contadores de rendimiento de Windows. Existe una lista de contenedores predeterminados que puede elegir para habilitar, y también puede establecer el intervalo para la recopilación. También puede agregar contadores de rendimiento adicionales para recopilar. En este artículo puede comprobar el formato adecuado. Haga clic en Guardar y luego en Aceptar.
Cierre la hoja de configuración avanzada y seleccione Resumen del área de trabajo en el encabezado General. Para cada una de las soluciones habilitadas hay un icono gráfico (también se incluye uno para Service Fabric). Haga clic en el grafo de Service Fabric para ir a la solución Service Fabric Analytics.
Hay iconos gráficos para los eventos del canal operativo y de Reliable Services. La representación gráfica de los datos que fluyen para los contadores que seleccionó aparecerán bajo la métricas de nodo.
Seleccione el gráfico de Métrica de contenedor para ver detalles adicionales. También puede consultar los datos del contador de rendimiento de forma similar a los eventos de clúster y filtrar en los nodos, el nombre del contador de rendimiento y los valores mediante el lenguaje de consulta Kusto.
Consulta del servicio EventStore
El servicio EventStore proporciona una manera de comprender el estado del clúster o las cargas de trabajo en un momento dado. EventStore es un servicio de Service Fabric con estado que mantiene los eventos del clúster. Los eventos se exponen a través de Service Fabric Explorer, REST y las API. EventStore consulta el clúster directamente para obtener datos de diagnóstico de cualquier entidad del clúster. Para ver una lista completa de los eventos disponibles en EventStore, consulte Eventos de Service Fabric.
Las API de EventStore se pueden consultar mediante programación con la biblioteca cliente de Service Fabric.
Esta es una solicitud de ejemplo de todos los eventos de clúster entre 2018-04-03T18:00:00Z y 2018-04-04T18:00:00Z, mediante la función GetClusterEventListAsync.
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl, settings);
var clstrEvents = sfhttpClient.EventsStore.GetClusterEventListAsync(
"2018-04-03T18:00:00Z",
"2018-04-04T18:00:00Z")
.GetAwaiter()
.GetResult()
.ToList();
Este es otro ejemplo que consulta el estado del clúster y todos los eventos del nodo en septiembre de 2018 e imprime los resultados.
const int timeoutSecs = 60;
var clusterUrl = new Uri(@"http://localhost:19080"); // This example is for a Local cluster
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl);
var clusterHealth = sfhttpClient.Cluster.GetClusterHealthAsync().GetAwaiter().GetResult();
Console.WriteLine("Cluster Health: {0}", clusterHealth.AggregatedHealthState.Value.ToString());
Console.WriteLine("Querying for node events...");
var nodesEvents = sfhttpClient.EventsStore.GetNodesEventListAsync(
"2018-09-01T00:00:00Z",
"2018-09-30T23:59:59Z",
timeoutSecs,
"NodeDown,NodeUp")
.GetAwaiter()
.GetResult()
.ToList();
Console.WriteLine("Result Count: {0}", nodesEvents.Count());
foreach (var nodeEvent in nodesEvents)
{
Console.Write("Node event happened at {0}, Node name: {1} ", nodeEvent.TimeStamp, nodeEvent.NodeName);
if (nodeEvent is NodeDownEvent)
{
var nodeDownEvent = nodeEvent as NodeDownEvent;
Console.WriteLine("(Node is down, and it was last up at {0})", nodeDownEvent.LastNodeUpAt);
}
else if (nodeEvent is NodeUpEvent)
{
var nodeUpEvent = nodeEvent as NodeUpEvent;
Console.WriteLine("(Node is up, and it was last down at {0})", nodeUpEvent.LastNodeDownAt);
}
}
Supervisión del estado del clúster
Service Fabric presenta un modelo de mantenimiento con entidades de estado en las que componentes y guardianes del sistema pueden notificar las condiciones locales que están supervisando. El almacén de estado agrega todos los datos de mantenimiento para determinar si las entidades son correctas.
El clúster se rellena automáticamente con informes de estado enviados por los componentes del sistema. Lea más en Uso de informes de mantenimiento del sistema para solucionar problemas.
Service Fabric expone las consultas de mantenimiento para cada uno de los tipos de entidadadmitidos. Se puede acceder a ellas mediante la API, con los métodos de FabricClient.HealthManager, los cmdlets de PowerShell y REST. Estas consultas devuelven información completa de mantenimiento sobre la entidad: el estado de mantenimiento agregado, los eventos de mantenimiento de la entidad, los estados de mantenimiento de los elementos secundarios (si procede), las evaluaciones de estado incorrecto y las estadísticas de mantenimiento de los elementos secundarios (cuando corresponde).
Obtención del mantenimiento de clúster
El cmdlet Get-ServiceFabricClusterHealth devuelve el mantenimiento de la entidad del clúster y contiene los estados de mantenimiento de las aplicaciones y los nodos (hijos del clúster). En primer lugar, conéctese al clúster mediante el cmdlet Connect-ServiceFabricCluster.
El estado del clúster es 11 nodos, la aplicación del sistema y fabric:/WordCount configurado tal como se ha descrito.
En el siguiente ejemplo se obtiene el mantenimiento del clúster mediante directivas de mantenimiento predeterminadas. Los 11 nodos están en buen estado, pero el estado de mantenimiento agregado del clúster es Error porque la aplicación fabric:/Voing está en estado de error. Observe cómo las evaluaciones de mantenimiento incorrecto muestran detalles de las condiciones que desencadenaron el mantenimiento agregado.
Get-ServiceFabricClusterHealth
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
33% (1/3) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates :
NodeName : _nt2vm_3
AggregatedHealthState : Ok
NodeName : _nt1vm_4
AggregatedHealthState : Ok
NodeName : _nt2vm_2
AggregatedHealthState : Ok
NodeName : _nt1vm_3
AggregatedHealthState : Ok
NodeName : _nt2vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_2
AggregatedHealthState : Ok
NodeName : _nt2vm_0
AggregatedHealthState : Ok
NodeName : _nt1vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_0
AggregatedHealthState : Ok
NodeName : _nt3vm_0
AggregatedHealthState : Ok
NodeName : _nt2vm_4
AggregatedHealthState : Ok
ApplicationHealthStates :
ApplicationName : fabric:/System
AggregatedHealthState : Ok
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
HealthStatistics :
Node : 11 Ok, 0 Warning, 0 Error
Replica : 4 Ok, 0 Warning, 0 Error
Partition : 2 Ok, 0 Warning, 0 Error
Service : 2 Ok, 0 Warning, 0 Error
DeployedServicePackage : 3 Ok, 1 Warning, 1 Error
DeployedApplication : 1 Ok, 1 Warning, 1 Error
Application : 0 Ok, 0 Warning, 1 Error
En el ejemplo siguiente se obtiene el mantenimiento del clúster mediante una directiva de aplicación personalizada. Filtra los resultados para obtener solo los nodos y las aplicaciones con error o advertencia. En este ejemplo no se devuelve ningún nodo, ya que todos ellos tienen un estado correcto. Solo la aplicación fabric:/Voting respeta el filtro de aplicaciones. Puesto que la directiva personalizada especifica que hay que considerar que las advertencias son errores en la aplicación fabric:/Voting, la aplicación se evalúa como con errores y lo mismo el clúster.
$appHealthPolicy = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicy
$appHealthPolicy.ConsiderWarningAsError = $true
$appHealthPolicyMap = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicyMap
$appUri1 = New-Object -TypeName System.Uri -ArgumentList "fabric:/Voting"
$appHealthPolicyMap.Add($appUri1, $appHealthPolicy)
Get-ServiceFabricClusterHealth -ApplicationHealthPolicyMap $appHealthPolicyMap -ApplicationsFilter "Warning,Error" -NodesFilter "Warning,Error" -ExcludeHealthStatistics
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
100% (5/5) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_2' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2466f2f9-d5fd-410c-a6a4-5b1e00630cca' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376486201388'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_4' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '5faa5201-eede-400a-865f-07f7f886aa32' is in Error.
'System.Hosting' reported Warning for property 'CodePackageActivation:Code:SetupEntryPoint:131959376207396204'. The evaluation treats
Warning as Error.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_0' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '204f1783-f774-4f3a-b371-d9983afaf059' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959375885791093'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt3vm_0' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2533ae95-2d2a-4f8b-beef-41e13e4c0081' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376108346272'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates : None
ApplicationHealthStates :
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
Obtención del mantenimiento de nodo
El cmdlet Get-ServiceFabricNodeHealth devuelve el mantenimiento de una entidad del nodo y contiene los eventos de mantenimiento notificados en el nodo. Conéctese primero al clúster mediante el cmdlet Connect-ServiceFabricCluster. En el ejemplo siguiente se obtiene el mantenimiento de un nodo específico mediante directivas de mantenimiento predeterminadas:
Get-ServiceFabricNodeHealth _nt1vm_3
En el siguiente ejemplo se obtiene el mantenimiento de todos los nodos del clúster:
Get-ServiceFabricNode | Get-ServiceFabricNodeHealth | select NodeName, AggregatedHealthState | ft -AutoSize
Obtención del mantenimiento de los servicios del sistema
Obtenga el mantenimiento agregado de los servicios del sistema:
Get-ServiceFabricService -ApplicationName fabric:/System | Get-ServiceFabricServiceHealth | select ServiceName, AggregatedHealthState | ft -AutoSize
Pasos siguientes
En este tutorial, ha aprendido a:
- Visualización de eventos de Service Fabric
- Consulta de las API del servicio EventStore para obtener eventos de clúster
- Supervisar la infraestructura y recopilar contadores de rendimiento
- Ver los informes de mantenimiento del clúster
A continuación, avance al siguiente tutorial para aprender a escalar un clúster.