Diseño y rendimiento de las migraciones de Netezza
Este artículo es la primera parte de una serie de siete partes, que proporciona instrucciones sobre cómo migrar de Netezza a Azure Synapse Analytics. Este artículo se centra en los procedimientos recomendados para el diseño y el rendimiento.
Información general
Debido al fin de soporte técnico por parte de IBM, muchos usuarios existentes de sistemas de almacenamiento de datos de Netezza quieren aprovechar las innovaciones proporcionadas por los entornos de nube modernos. Los entornos en la nube de infraestructura como servicio (IaaS) y plataforma como servicio (PaaS) permiten delegar tareas como el mantenimiento de la infraestructura y el desarrollo de plataformas en el proveedor de nube.
Sugerencia
Más que una base de datos: el entorno de Azure incluye un conjunto completo de características y herramientas.
Aunque Netezza y Azure Synapse Analytics son bases de datos SQL que usan técnicas de procesamiento paralelo masivo (MPP) con el fin de lograr un alto rendimiento de las consultas en volúmenes de datos excepcionalmente grandes, hay algunas diferencias básicas en cuanto al enfoque que utilizan:
Los sistemas heredados de Netezza suelen estar instalados en el entorno local y usan hardware propietario, mientras que Azure Synapse se basa en la nube y usa recursos de proceso y almacenamiento de Azure.
La actualización de una configuración de Netezza es una tarea importante que supone hardware físico adicional y una reconfiguración o volcado y recarga de las bases de datos potencialmente grandes. Dado que los recursos de almacenamiento y de proceso son independientes en el entorno de Azure y tienen funcionalidad de escalado elástico, se pueden escalar o reducir verticalmente de manera independiente.
Puede pausar o cambiar el tamaño de Azure Synapse según sea necesario para reducir el costo y el uso de recursos.
Microsoft Azure es un entorno en la nube escalable, muy seguro, está disponible en todo el mundo e incluye Azure Synapse y un ecosistema de herramientas y funcionalidades complementarias. En el siguiente diagrama, se resume el ecosistema de Azure Synapse.
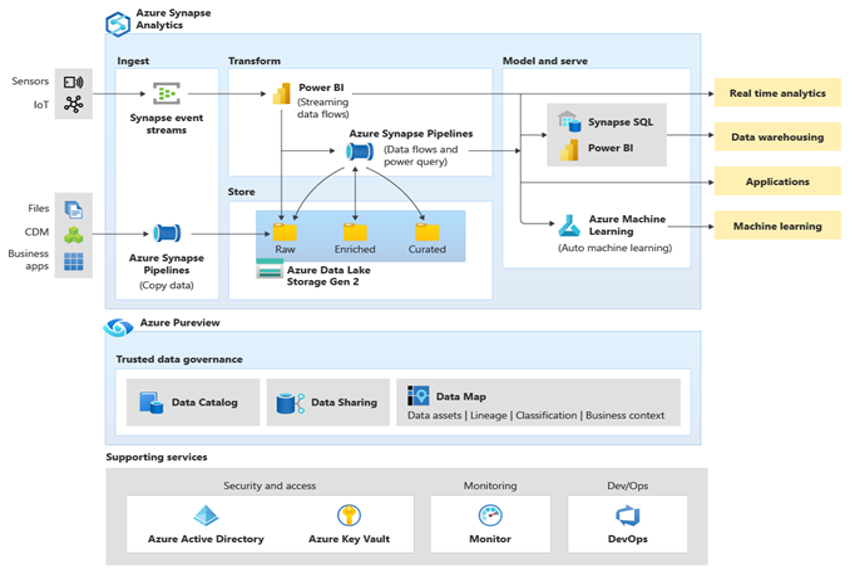
Azure Synapse proporciona el mejor rendimiento de las bases de datos relacionales mediante el uso de técnicas como el procesamiento paralelo masivo (MPP) y varios niveles de almacenamiento en caché automatizado para los datos que se usan con frecuencia. Puede ver los resultados de estas técnicas en pruebas comparativas independientes, como la ejecutada recientemente por GigaOm, que compara Azure Synapse con otras ofertas conocidas de almacenamiento de datos en la nube. Los clientes que migran al entorno de Azure Synapse se benefician de muchas ventajas, entre las que se incluyen:
Rendimiento y relación precio/rendimiento mejorados.
Mayor agilidad y tiempo de rentabilidad menor.
Implementación de servidores y desarrollo de aplicaciones más rápidos.
Escalabilidad elástica: solo se paga por el uso real.
Mayor seguridad y cumplimiento.
Costos reducidos de almacenamiento y recuperación ante desastres.
Menor TCO global, mejor control de costos y gastos de funcionamiento (OPEX) optimizados.
Para maximizar estas ventajas, migre los datos y aplicaciones existentes o nuevos a la plataforma Azure Synapse. En muchas organizaciones, este enfoque incluye la migración de un almacenamiento de datos existente desde una plataforma local heredada, como Netezza, a Azure Synapse. A grandes rasgos, el proceso de migración incluye los siguientes pasos:
Preparación 🡆
Definir el ámbito: qué se va a migrar.
Generar el inventario de datos y procesos para la migración.
Definir los cambios en el modelo de datos (si procede).
Definir el mecanismo de extracción de datos de origen.
Identificar las herramientas y características adecuadas de Azure (y de terceros) que se usarán.
Entrene al personal en la nueva plataforma desde el principio.
Configure la plataforma de destino de Azure.
Migración 🡆
Comience con algo pequeño y sencillo.
Automatice siempre que sea posible.
Aprovechar las herramientas y características integradas de Azure para reducir el esfuerzo de migración.
Migre los metadatos de tablas y vistas.
Migrar los datos históricos que se van a mantener.
Migre o refactorice los procedimientos almacenados y los procesos empresariales.
Migre o refactorice los procesos de carga incremental ETL/ELT.
Tareas posteriores a la migración
Supervisar y documentar todas las fases del proceso.
Aprovechar la experiencia adquirida para generar una plantilla de cara a migraciones futuras.
Volver a diseñar el modelo de datos, si es necesario, con el nuevo rendimiento y escalabilidad de la plataforma.
Pruebe las aplicaciones y herramientas de consulta.
Realice evaluaciones comparativas y optimice el rendimiento de las consultas.
En este artículo se proporciona información general y directrices para la optimización del rendimiento al migrar un almacenamiento de datos desde un entorno de Netezza existente a Azure Synapse. El objetivo de la optimización del rendimiento es lograr el mismo o mejor rendimiento del almacenamiento de datos en Azure Synapse después de la migración del esquema.
Consideraciones de diseño
Ámbito de la migración
Cuando esté preparando la migración desde un entorno de Netezza, tenga en cuenta las siguientes opciones de migración.
Elección de la carga de trabajo para la migración inicial
Normalmente, los entornos heredados de Netezza han evolucionado con el tiempo para abarcar varias áreas temáticas y cargas de trabajo mixtas. Al decidir por dónde empezar en un proyecto de migración inicial, elija un área en la que pueda hacer lo siguiente:
Demostrar la viabilidad de la migración a Azure Synapse con la obtención de beneficios rápidos del nuevo entorno.
Permitir que el personal técnico interno obtenga experiencia pertinente con los procesos y herramientas que usarán al migrar otras áreas.
Crear una plantilla para migraciones adicionales que sea específica del entorno de origen de Netezza y de las herramientas y los procesos actuales que ya están en funcionamiento.
Un buen candidato para una migración inicial desde un entorno de Netezza admite los elementos anteriores y además:
Implementa una carga de trabajo de BI y análisis en lugar de una carga de trabajo de procesamiento de transacciones en línea (OLTP).
Tiene un modelo de datos, como un esquema de estrella o copo de nieve, que se puede migrar con una modificación mínima.
Sugerencia
Cree un inventario de objetos que es necesario migrar y documente el proceso de migración.
El volumen de datos migrados en una migración inicial debe ser lo suficientemente grande como para demostrar las funcionalidades y ventajas del entorno de Azure Synapse, pero no demasiado grande para demostrar rápidamente el valor. Un tamaño en el intervalo de 1 a 10 terabytes es lo habitual.
Para el proyecto de migración inicial, minimice el riesgo, el esfuerzo y el tiempo de migración para que pueda ver rápidamente las ventajas del entorno en la nube de Azure. Los enfoques de migración por fases y lift-and-shift limitan el ámbito de la migración inicial a solo los data marts y no abordan aspectos de migración más amplios, como la migración de ETL y la migración de datos históricos. Sin embargo, puede abordar esos aspectos en fases posteriores del proyecto una vez que la capa de data mart migrada se rellene con los datos y los procesos de compilación necesarios.
Migración mediante lift-and-shift frente al enfoque por fases
En general, hay dos tipos de migración independientemente del propósito y el ámbito de la migración planeada: lift-and-shift tal cual y un enfoque por fases que incorpora cambios.
migración mediante lift-and-shift
En una migración mediante lift-and-shift, un modelo de datos existente, como un esquema de estrella, se migra sin cambios a la nueva plataforma de Azure Synapse. Este enfoque minimiza el riesgo y el tiempo necesario para la migración reduciendo el trabajo necesario para lograr las ventajas de migrar al entorno en la nube de Azure. La migración mediante lift-and-shift es una buena opción para estos escenarios:
- Tiene un entorno de Netezza existente con un único data mart para migrar, o bien
- Tiene un entorno de Netezza existente con datos que ya están en un esquema de estrella o copo de nieve bien diseñado, o bien
- Está afectado por limitaciones de tiempo y dinero para pasar a un entorno en la nube moderno.
Sugerencia
La migración mediante "Lift and shift" es un buen punto inicial, incluso si las fases posteriores implementan cambios en el modelo de datos.
Estrategia por fases que incorpora cambios
Si un almacén heredado ha evolucionado con el tiempo, es posible que tenga que volver a diseñarlo para mantener el rendimiento necesario. También es posible que tenga que volver a diseñar para admitir nuevos datos, como los flujos de Internet de las cosas (IoT). Migre a Azure Synapse para obtener las ventajas de un entorno en la nube escalable como parte del proceso de reingeniería. La migración también puede incluir un cambio en el modelo de datos subyacente; por ejemplo, pasar de un modelo Inmon a un almacén de datos.
Microsoft recomienda trasladar el modelo de datos actual tal y como está a Azure y usar el rendimiento y la flexibilidad del entorno de Azure para aplicar los cambios del nuevo diseño. De este modo, puede usar las funcionalidades de Azure para realizar los cambios sin afectar al sistema de origen existente.
Uso de Azure Data Factory para implementar una migración controlada por metadatos
Puede automatizar y organizar el proceso de migración mediante las funcionalidades del entorno de Azure. Este enfoque minimiza el impacto del rendimiento en el entorno de Netezza existente, que es posible que ya funcione casi a plena capacidad.
Azure Data Factory es un servicio de integración de datos basado en la nube que permite crear flujos de trabajo basados en datos en la nube a fin de orquestar y automatizar el movimiento y la transformación de datos. Con Azure Data Factory puede crear y programar flujos de trabajo basados en datos (llamados canalizaciones) que ingieren datos de distintos almacenes de datos. Data Factory puede procesar y transformar datos mediante servicios de proceso, como Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics y Azure Machine Learning.
Cuando planee usar las utilidades de Data Factory para administrar el proceso de migración, cree metadatos que enumeren todas las tablas de datos que se van a migrar y su ubicación.
Diferencias de diseño entre Netezza y Azure Synapse
Como se mencionó anteriormente, hay algunas diferencias básicas en el enfoque entre las bases de datos de Netezza y Azure Synapse Analytics, y estas diferencias se describen a continuación.
Varias bases de datos frente a esquemas y bases de datos únicas
El entorno de Netezza suele contener varias bases de datos independientes. Por ejemplo, podría haber bases de datos independientes para: tablas de ingesta y almacenamiento provisional de datos, tablas de almacenamiento principal y data marts (a veces denominada capa semántica). Los procesos de canalización ETL o ELT pueden implementar combinaciones entre bases de datos y mover datos entre las bases de datos independientes.
Por otro lado, el entorno de Azure Synapse tiene una sola base de datos y se usan esquemas para separar las tablas en grupos lógicamente distintos. Se recomienda usar una serie de esquemas en la base de datos de Azure Synapse de destino para imitar las bases de datos independientes migradas desde el entorno de Netezza. Si ya se usan esquemas en el entorno de Netezza, es posible que sea necesario utilizar una nueva convención de nomenclatura para trasladar las tablas y vistas de Netezza existentes al nuevo entorno. Por ejemplo, podría concatenar los nombres de tabla y esquema de Netezza existentes en el nuevo nombre de tabla de Azure Synapse y, luego, usar nombres de esquema del nuevo entorno para mantener los nombres originales de las bases de datos independientes. Si la nomenclatura de la consolidación de esquemas tiene puntos, Azure Synapse Spark podría tener problemas. Puede usar vistas SQL en las tablas subyacentes para mantener las estructuras lógicas, pero este enfoque presenta algunas posibles desventajas:
Las vistas de Azure Synapse son de solo lectura, por lo que toda actualización de los datos debe realizarse en las tablas base subyacentes.
Es posible que ya haya una o varias capas de vistas y agregar una capa de vistas más podría afectar al rendimiento y la compatibilidad, porque los problemas con vistas anidadas son difíciles de solucionar.
Sugerencia
Combine varias bases de datos en una base de datos única en Azure Synapse y utilice esquemas para separar las tablas de manera lógica.
Consideraciones sobre las tablas
Al migrar tablas entre distintos entornos, normalmente solo los datos sin procesar y los metadatos que lo describen migran físicamente. Otros elementos de base de datos del sistema de origen, como los índices, normalmente no se migran porque podrían ser innecesarios o implementados de forma diferente en el nuevo entorno.
Las optimizaciones de rendimiento en el entorno de origen, como los índices, indican dónde puede agregar la optimización del rendimiento en el nuevo entorno. Por ejemplo, si las consultas del entorno de Netezza de origen usan con frecuencia mapas de zona, puede indicar que se debe crear un índice no agrupado en Azure Synapse. Otras técnicas de optimización del rendimiento nativas, como la replicación de tablas, pueden ser más adecuadas que la creación directa de un índice equivalente.
Sugerencia
Los índices que ya existen indican candidatos para la indexación en el almacenamiento migrado.
Tipos de objetos de base de datos de Netezza no admitidos
A menudo, las características específicas de Netezza se pueden reemplazar por características de Azure Synapse. Sin embargo, algunos objetos de base de datos de Netezza no se admiten directamente en Azure Synapse. En la siguiente lista de objetos de base de datos de Netezza no admitidos, se describe cómo se puede lograr una funcionalidad equivalente en Azure Synapse.
Mapas de zona: en Netezza, se crean y mantienen automáticamente mapas de zona para los siguientes tipos de columna y se usan en el momento de la consulta para restringir la cantidad de datos que se van a examinar:
- Columnas
INTEGERde 8 bytes o menos. - Columnas temporales, como
DATE,TIMEyTIMESTAMP. - Columnas
CHAR, si forman parte de una vista materializada y se mencionan en la cláusulaORDER BY.
Puede averiguar qué columnas tienen mapas de zona mediante la utilidad
nz_zonemap, que forma parte del kit de herramientas de NZ. Azure Synapse no incluye mapas de zona, pero se pueden obtener resultados similares con otros tipos de índice definidos por el usuario o por medio de la creación de particiones.- Columnas
Tablas base agrupadas (CBT): en Netezza, las CBT se usan normalmente para tablas de hechos, que pueden tener miles de millones de registros. El examen de una tabla de gran tamaño requiere mucho tiempo de procesamiento, ya que podría ser necesario realizar un recorrido de tabla completo para obtener los registros de interés. La organización de los registros en tablas CBT restrictivas permite a Netezza agruparlos en las mismas extensiones o en otras próximas. Este proceso también crea mapas de zona que mejoran el rendimiento al reducir la cantidad de datos que se deben examinar.
En Azure Synapse, se puede conseguir un efecto parecido mediante la creación de particiones y el uso de otros índices.
Vistas materializadas: Netezza admite vistas materializadas y recomienda crear una o varias de estas vistas en tablas grandes que tengan muchas columnas si solo algunas columnas se usan con frecuencia en las consultas. El sistema actualiza las vistas materializadas automáticamente cuando se actualizan los datos de la tabla base.
Azure Synapse admite vistas materializadas, con la misma funcionalidad que Netezza.
Asignación de tipos de datos de Netezza
la mayoría de los tipos de datos de Netezza tienen un equivalente directo en Azure Synapse. En la tabla siguiente, se muestra el enfoque recomendado para asignar los tipos de datos de Netezza a Azure Synapse.
| Tipo de datos de Netezza | Tipo de datos de Azure Synapse |
|---|---|
| bigint | bigint |
| BINARY VARYING(n) | VARBINARY(n) |
| BOOLEAN | BIT |
| BYTEINT | TINYINT |
| CHARACTER VARYING(n) | VARCHAR(n) |
| CHARACTER(n) | CHAR(n) |
| DATE | DATE(date) |
| DECIMAL(p,s) | DECIMAL(p,s) |
| DOUBLE PRECISION | FLOAT |
| FLOAT(n) | FLOAT(n) |
| INTEGER | INT |
| INTERVAL | Actualmente, los tipos de datos INTERVAL no se admiten directamente en Azure Synapse, pero se pueden calcular mediante funciones temporales, como DATEDIFF. |
| MONEY | MONEY |
| NATIONAL CHARACTER VARYING(n) | NVARCHAR(n) |
| NATIONAL CHARACTER(n) | NCHAR(n) |
| NUMERIC(p,s) | NUMERIC(p,s) |
| real | REAL |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Los tipos de datos espaciales, como ST_GEOMETRY, actualmente no se admiten en Azure Synapse, pero los datos se pueden almacenar como VARCHAR o VARBINARY. |
| TIME | TIME |
| TIME WITH TIME ZONE | DATETIMEOFFSET |
| timestamp | DATETIME |
Sugerencia
Evalúe el número y la clase de tipos de datos no admitidos durante la fase de preparación de la migración.
Hay proveedores de terceros que ofrecen herramientas y servicios para automatizar la migración, incluida la asignación de tipos de datos. Si ya se utiliza una herramienta de ETL de terceros en el entorno de Netezza, use dicha herramienta para implementar cualquier transformación de datos necesaria.
Diferencias de sintaxis de DML de SQL
Existen diferencias de sintaxis de DML de SQL entre Netezza SQL y Azure Synapse T-SQL. Estas diferencias se describen detalladamente en Minimización de los problemas de SQL para migraciones de Netezza.
STRPOS: en Netezza, la funciónSTRPOSdevuelve la posición de una subcadena dentro de una cadena. La función equivalente en Azure Synapse esCHARINDEX, con el orden de los argumentos invertido. Por ejemplo,SELECT STRPOS('abcdef','def')...en Netezza es equivalente aSELECT CHARINDEX('def','abcdef')...en Azure Synapse.AGE: Netezza admite el operadorAGEpara proporcionar el intervalo entre dos valores temporales, como marcas de tiempo o fechas, por ejemplo:SELECT AGE('23-03-1956','01-01-2019') FROM.... En Azure Synapse, useDATEDIFFpara obtener el intervalo, por ejemplo:SELECT DATEDIFF(day, '1956-03-26','2019-01-01') FROM.... Anote la secuencia de representación de fecha.NOW(): Netezza usaNOW()para representarCURRENT_TIMESTAMPen Azure Synapse.
Funciones, procedimientos almacenados y secuencias
Al migrar un almacenamiento de datos de un entorno consolidado como Netezza, probablemente tenga que migrar elementos que no sean tablas y vistas simples. Compruebe si las herramientas del entorno de Azure pueden reemplazar la funcionalidad de funciones, procedimientos almacenados y secuencias, ya que normalmente es más eficaz usar herramientas integradas de Azure que volver a codificar esos elementos para Azure Synapse.
Como parte de la fase de preparación, cree un inventario de objetos que deban migrarse, defina un método para controlarlos y asigne los recursos adecuados en el plan de migración.
Los asociados de integración de datos ofrecen herramientas y servicios que pueden automatizar la migración de funciones, procedimientos almacenados y secuencias.
En las secciones siguientes se describe aún más la migración de funciones, procedimientos almacenados y secuencias.
Functions
Al igual que en la mayoría de los productos de base de datos, Netezza admite funciones del sistema y funciones definidas por el usuario en una implementación de SQL. Al migrar una plataforma de base de datos heredada a Azure Synapse, las funciones comunes del sistema normalmente se pueden migrar sin cambios. Algunas funciones del sistema pueden tener una sintaxis ligeramente diferente, pero se pueden automatizar los cambios necesarios.
En el caso de las funciones del sistema de Netezza o funciones arbitrarias definidas por el usuario que no tienen ningún equivalente en Azure Synapse, vuelva a codificar esas funciones mediante un lenguaje del entorno de destino. Las funciones definidas por el usuario de Netezza se programan mediante los lenguajes nzLua o C++. Azure Synapse usa el lenguaje Transact-SQL para la implementación de las funciones definidas por el usuario.
Procedimientos almacenados
La mayoría de los productos de base de datos modernos permite almacenar los procedimientos en la base de datos. Para este propósito, Netezza proporciona el lenguaje NZPLSQL, que se basa en PL/pgSQL de Postgres. Normalmente, un procedimiento almacenado contiene instrucciones SQL y lógica de procedimiento, y puede devolver datos o un estado.
Azure Synapse admite procedimientos almacenados mediante T-SQL, por lo que debe volver a codificar los procedimientos almacenados migrados en ese lenguaje.
Secuencias
En Netezza, una secuencia es un objeto de base de datos con nombre creado con CREATE SEQUENCE. Una secuencia proporciona valores numéricos únicos mediante el método NEXT VALUE FOR. Puede usar los números únicos generados como valores de clave suplente para las claves principales.
Azure Synapse no implementa CREATE SEQUENCE, pero puede implementar secuencias mediante columnas IDENTITY o código SQL que genera el siguiente número de secuencia de una serie.
Extracción de metadatos y datos de un entorno de Netezza
Generación del lenguaje de definición de datos (DDL)
El estándar ANSI SQL define la sintaxis básica para los comandos DDL (Lenguaje de definición de datos). Algunos comandos DDL, como CREATE TABLE y CREATE VIEW, son comunes tanto para Netezza como para Azure Synapse, pero se han ampliado para proporcionar características específicas de la implementación.
Puede editar los scripts con CREATE TABLE y CREATE VIEW de Netezza existentes para lograr definiciones equivalentes en Azure Synapse. Para ello, es posible que tenga que usar tipos de datos modificados y quitar o modificar cláusulas específicas de Netezza, como ORGANIZE ON.
En el entorno de Netezza, las tablas del catálogo del sistema especifican la definición de vista y tabla actual. A diferencia de la documentación mantenida por el usuario, la información del catálogo del sistema siempre está completa y sincronizada con las definiciones de tabla actuales. Mediante el uso de utilidades como nz_ddl_table, puede acceder a la información del catálogo del sistema para generar instrucciones DDL CREATE TABLE que creen tablas equivalentes en Azure Synapse.
También puede usar herramientas de ETL y migración de terceros que procesan la información del catálogo del sistema para lograr resultados similares.
Extracción de datos de Netezza
Puede extraer datos de tabla sin procesar de las tablas de Netezza en archivos delimitados planos, como archivos CSV, mediante utilidades estándar de Netezza como nzsql y nzunload, o mediante tablas externas. Después, puede comprimir los archivos delimitados planos mediante gzip y cargar los archivos comprimidos en Azure Blob Storage mediante AzCopy o herramientas de transporte de datos de Azure, como Azure Data Box.
Extraiga los datos de las tablas de la forma más eficaz posible. Use el enfoque de tablas externas, ya que es el método de extracción más rápido. Para maximizar el rendimiento de la extracción de datos, realice varias extracciones en paralelo. La siguiente instrucción SQL realiza una extracción de tabla externa:
CREATE EXTERNAL TABLE '/tmp/export_tab1.csv' USING (DELIM ',') AS SELECT * from <TABLENAME>;
Si hay suficiente ancho de banda de red disponible, puede extraer los datos de un sistema de Netezza local directamente en tablas de Azure Synapse o Azure Blob Data Storage. Para ello, use procesos de Data Factory o productos de migración de datos o de ETL de terceros.
Sugerencia
Use tablas externas de Netezza para extraer los datos de la forma más eficaz.
Los archivos de datos extraídos deben contener texto delimitado en formato CSV, Optimized Row Columnar (ORC) o Parquet.
Para obtener más información sobre la migración de datos y ETL desde un entorno de Netezza, consulte Migración de datos, ETL y carga para migraciones de Netezza.
Recomendaciones de rendimiento para migraciones de Netezza
El objetivo de la optimización del rendimiento es obtener el mismo o mejor rendimiento del almacenamiento de datos después de la migración a Azure Synapse.
Similitudes en los conceptos del enfoque de optimización del rendimiento:
Muchos conceptos de optimización del rendimiento para las bases de datos de Netezza son válidos para las bases de datos de Azure Synapse. Por ejemplo:
Utilice la distribución de datos para colocar conjuntamente los datos que se van a combinar en el mismo nodo de procesamiento.
Utilice el tipo de datos más pequeño para una columna determinada para ahorrar espacio de almacenamiento y acelerar el procesamiento de las consultas.
Asegúrese de que las columnas que se van a combinar tengan el mismo tipo de datos para optimizar el procesamiento de las combinaciones y reducir la necesidad de transformaciones de datos.
Para ayudar al optimizador a generar el mejor plan de ejecución, asegúrese de que las estadísticas estén actualizadas.
Supervise el rendimiento mediante las funcionalidades de base de datos integradas para asegurarse de que los recursos se usen de forma eficaz.
Sugerencia
Priorice la familiaridad con las opciones de optimización de Azure Synapse al principio de una migración.
Diferencias en el enfoque de optimización del rendimiento
En esta sección, se tratan las diferencias de implementación de nivel inferior entre Netezza y Azure Synapse para el ajuste del rendimiento.
Opciones de distribución de datos
Para el rendimiento, Azure Synapse se diseñó con arquitectura de varios nodos y usa el procesamiento en paralelo. Para optimizar el rendimiento de las tablas, puede definir una opción de distribución de datos en las instrucciones CREATE TABLE mediante DISTRIBUTION en Azure Synapse y DISTRIBUTE ON en Netezza.
A diferencia de Netezza, Azure Synapse admite combinaciones locales entre una tabla pequeña y una tabla grande mediante la replicación de la tabla pequeña. Por ejemplo, considere una tabla de dimensiones pequeña y una tabla de hechos grande en un modelo de esquema en estrella. Azure Synapse puede replicar la tabla de dimensiones más pequeña en todos los nodos para asegurarse de que el valor de cualquier clave de combinación para la tabla grande tenga una fila de dimensión disponible localmente coincidente. La sobrecarga de replicación de tablas de dimensiones es relativamente baja para una tabla de dimensiones pequeña. En el caso de las tablas de dimensiones grandes, un enfoque de distribución hash es más adecuado. Para obtener más información sobre las opciones de distribución de datos, consulte Instrucciones de diseño para el uso de tablas replicadas en un grupo de Synapse SQL y Guía de diseño de tablas distribuidas mediante un grupo de SQL dedicado en Azure Synapse Analytics.
Indexación de datos
Azure Synapse admite varias opciones de indexación definibles por el usuario que tienen una operación y un uso diferentes en comparación con los mapas de zona administrados por el sistema de Netezza. Para obtener más información sobre las distintas opciones de indexación en Azure Synapse, consulte Indexaciones de tablas en un grupo de SQL dedicado en Azure Synapse Analytics.
Los mapas de zona existentes administrados por el sistema de un entorno de Netezza de origen proporcionan indicaciones útiles del uso de los datos y las columnas candidatas para la indexación en el entorno de Azure Synapse.
Creación de particiones de datos
En un almacén de datos empresarial, las tablas de hechos pueden contener miles de millones de filas de datos. La creación de particiones optimiza el mantenimiento y el rendimiento de consultas de estas tablas al dividirlas en partes independientes para reducir la cantidad de datos que se procesan. En Azure Synapse, la especificación de creación de particiones de una tabla se define en la instrucción CREATE TABLE.
En la creación de particiones, solo se puede usar un campo por tabla. Suele ser un campo de fecha porque muchas consultas se filtran por una fecha o un intervalo de fechas. Puede cambiar la creación de particiones de una tabla después de la carga inicial; para ello, vuelva a crear la tabla con la nueva distribución mediante la instrucción CREATE TABLE AS (o CTAS). Para obtener una explicación detallada de la creación de particiones en Azure Synapse, consulte Creación de particiones de tablas en el grupo de SQL dedicado.
Estadísticas de tablas de datos
Incluya un paso para las estadísticas en los trabajos de ETL/ELT para asegurarse de que las estadísticas de las tablas de datos están actualizadas.
PolyBase o COPY INTO para la carga de datos
PolyBase admite la carga eficaz de grandes cantidades de datos en un almacenamiento de datos mediante flujos de carga paralelos. Para más información, consulte Estrategia de carga de datos de PolyBase.
COPY INTO también admite la ingesta de datos de alto rendimiento y:
Recuperación de datos de todos los archivos dentro de una carpeta y subcarpetas.
Recuperación de datos desde varias ubicaciones en la misma cuenta de almacenamiento. Puede especificar varias ubicaciones mediante rutas de acceso separadas por comas.
Azure Data Lake Storage (ADLS) y Azure Blob Storage.
Formatos de archivo CSV, PARQUET y ORC.
Administración de cargas de trabajo
La ejecución de cargas de trabajo mixtas puede suponer desafíos de recursos en sistemas ocupados. Un esquema de administración de cargas de trabajo correcto administra los recursos de manera eficaz, garantiza un uso de recursos muy eficaz y maximiza la rentabilidad de la inversión (ROI). Los valores de clasificación de la carga de trabajo, importancia de la carga de trabajo y aislamiento de la carga de trabajo proporcionan más control sobre cómo la carga de trabajo utiliza los recursos del sistema.
La guía de administración de cargas de trabajo describe las técnicas para analizar la carga de trabajo y administrar y supervisar la importancia de la carga de trabajo, junto con los pasos necesarios para convertir una clase de recurso en un grupo de cargas de trabajo. Use Azure Portal y las consultas de T-SQL en DMV para supervisar la carga de trabajo para asegurarse de que los recursos aplicables se usan de forma eficaz.
Pasos siguientes
Para obtener más información sobre ETL y carga para la migración de Netezza, consulte el siguiente artículo de esta serie: Migración de datos, ETL y carga para migraciones de Netezza.