Optimización del rendimiento con el índice de almacén de columnas agrupado ordenado
Se aplica a: grupos de SQL dedicados de Azure Synapse Analytics, SQL Server 2022 (16.x) y versiones posteriores
Cuando los usuarios consultan una tabla de almacén de columnas en el grupo de SQL dedicado, el optimizador comprueba los valores mínimo y máximo almacenados en cada segmento. Los segmentos que están fuera de los límites del predicado de la consulta no se leen del disco a la memoria. Una consulta puede finalizar más rápido si el número de segmentos que se van a leer y su tamaño total son pequeños.
Índice de almacén de columnas agrupado ordenado frente al no ordenado
De forma predeterminada, para cada tabla creada sin una opción de índice, un componente interno (generador de índices) crea en ellas un índice de almacén de columnas agrupado (CCI) no ordenado. Los datos de cada columna se comprimen en un segmento de grupo de filas de CCI independiente. Hay metadatos en el intervalo de valores de cada segmento, por lo que los segmentos que están fuera de los límites del predicado de la consulta no se leen desde el disco durante la ejecución de la consulta. CCI ofrece el máximo nivel de compresión de datos y reduce el tamaño de los segmentos que se van a leer para que las consultas se ejecuten más rápido. Sin embargo, dado que el generador de índices no ordena los datos antes de comprimirlos en segmentos, pueden darse segmentos con intervalos de valores superpuestos, lo que hace que las consultas lean más segmentos del disco y tarden más en finalizar.
Índices de almacén de columnas agrupados ordenados mediante la habilitación de una eliminación de segmentos eficaz, lo que se traduce en un rendimiento mucho más rápido omitiendo grandes cantidades de datos ordenados que no coinciden con el predicado de consulta. Al crear un CCI ordenado, el motor de grupo de SQL dedicado ordena los datos existentes en memoria por las claves de orden antes de que el generador de índices los comprima en segmentos de índice. Con los datos ordenados, se reduce la superposición de segmentos, lo que permite que las consultas tengan una eliminación de segmentos más eficaz y, por tanto, un rendimiento más rápido, ya que el número de segmentos que se leerán desde el disco es menor. Si todos los datos se pueden ordenar en memoria de una vez, se puede evitar la superposición de segmentos. Dado el gran tamaño de las tablas de los almacenamientos de datos, este escenario no se produce con frecuencia.
Para comprobar los intervalos de segmentos de una columna, ejecute el comando siguiente con el nombre de la tabla y el nombre de la columna:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Nota
En una tabla de CCI ordenada, los nuevos datos resultantes del mismo lote de DML o de operaciones de carga de datos se organizan dentro de ese lote, no hay ninguna organización global de todos los datos de la tabla. Los usuarios pueden RECOMPILAR el CCI ordenado para ordenar todos los datos de la tabla. En el grupo de SQL dedicado, el índice de almacén de columnas REBUILD es una operación sin conexión. En el caso de una tabla con particiones, la RECOMPILACIÓN se realiza en una partición cada vez. Los datos de la partición que se está recompilando estarán "sin conexión" y no estarán disponibles hasta que la RECOMPILACIÓN se complete para esa partición.
Rendimiento de las consultas
La mejora del rendimiento de una consulta desde un CCI ordenado depende de los patrones de consulta, el tamaño de los datos, el grado de orden de los datos, la estructura física de los segmentos y la unidad de almacenamiento de datos y la clase de recurso elegidos para la ejecución de la consulta. Los usuarios deben revisar todos estos factores antes de elegir las columnas de ordenación al diseñar una tabla de CCI ordenado.
Las consultas con todos estos patrones suelen ejecutarse más rápido con CCI ordenado.
- Las consultas tienen predicados de igualdad, desigualdad o intervalo.
- Las columnas de predicado y las columnas de CCI ordenado son las mismas.
En este ejemplo, la tabla T1 tiene un índice de almacén de columnas en clúster ordenado en la secuencia Col_C, Col_B y Col_A.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
El rendimiento de la consulta 1 y la consulta 2 puede beneficiarse más del CCI ordenado que las demás consultas, ya que hacen referencia a todas las columnas de CCI ordenadas.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Rendimiento de la carga de datos
El rendimiento de la carga de datos en una tabla de CCI ordenado es similar a una tabla con particiones. La carga de datos en una tabla de CCI ordenado puede tardar más que en una tabla de CCI no ordenado debido a la operación de ordenación de datos; sin embargo, posteriormente las consultas podrán ejecutarse más rápidamente con el CCI ordenado.
A continuación se muestra un ejemplo de comparación de rendimiento de la carga de datos en tablas con esquemas diferentes.
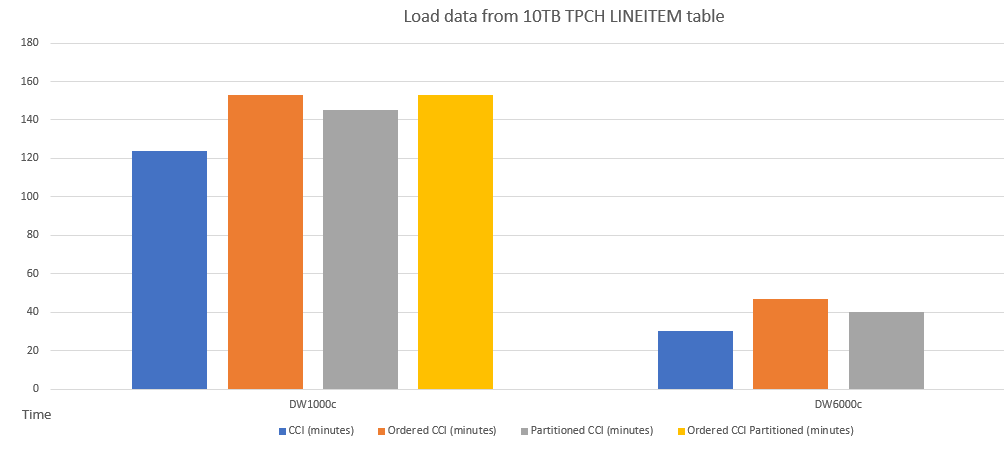
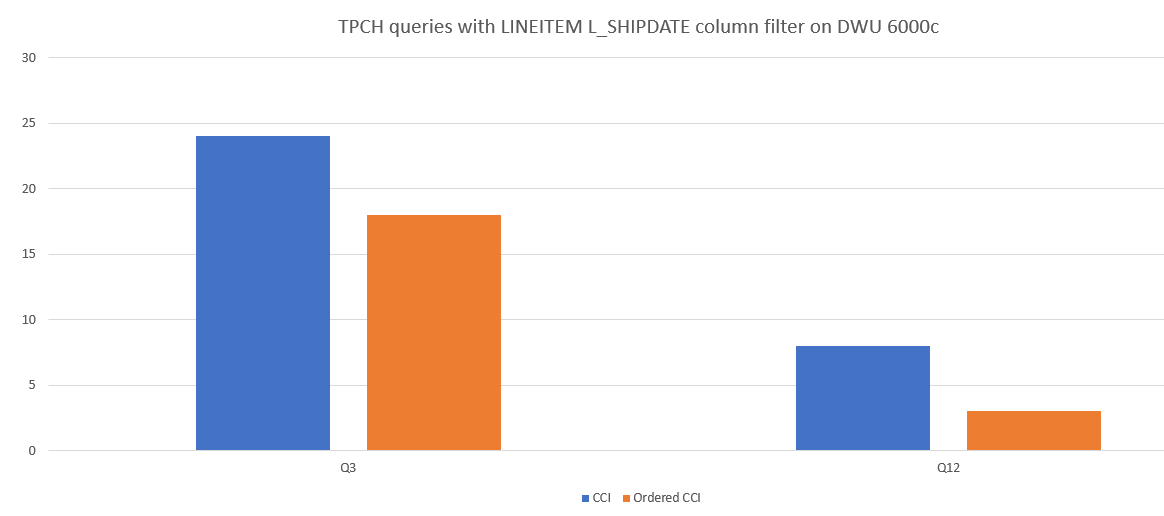
A continuación se ofrece una comparación de rendimiento de consultas de ejemplo entre CCI y CCI ordenado.
Reducción de la superposición de segmentos
El número de segmentos superpuestos depende del tamaño de los datos que se van a ordenar, la memoria disponible y el grado máximo de paralelismo (MAXDOP) durante la creación del CCI ordenado. Las estrategias siguientes reducen la superposición de segmentos al crear un CCI ordenado.
Use la clase de recurso
xlargercen una unidad de almacenamiento de datos superior para permitir más memoria para la ordenación de datos antes de que el generador de índices comprima los datos en segmentos. Una vez que está en un segmento de índice, no se puede cambiar la ubicación física de los datos. No hay ningún tipo de organización de datos dentro de un segmento o entre segmentos.Cree un CCI ordenado con
OPTION (MAXDOP = 1). Cada subproceso que se usa para la creación del CCI ordenado trabaja en un subconjunto de datos y lo ordena localmente. No hay ninguna ordenación global entre los datos ordenados por subprocesos diferentes. El uso de subprocesos paralelos puede reducir el tiempo de creación de un CCI ordenado, pero se generarán más segmentos superpuestos que con el uso de un único subproceso. El uso de una sola operación en subproceso ofrece la máxima calidad de compresión. Por ejemplo:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Nota
Actualmente, en grupos de SQL dedicados en Azure Synapse Analytics, la opción MAXDOP solo se admite en la creación de una tabla CCI ordenada mediante el comando CREATE TABLE AS SELECT. La creación de un CCI ordenado mediante los comandos CREATE INDEX o CREATE TABLE no admite la opción MAXDOP. Esta limitación no se aplica a SQL Server 2022 y versiones posteriores, donde puede especificar MAXDOP con los comandos CREATE INDEX o CREATE TABLE.
- Ordene previamente los datos por las claves de ordenación antes de cargarlos en tablas.
El siguiente es un ejemplo de una distribución de tabla de CCI ordenado que no tiene ningún segmento superpuesto tras aplicar las recomendaciones anteriores. La tabla de CCI ordenada se crea en una base de datos de DWU1000c a través de la instrucción CTAS a partir de una tabla de montón de 20 GB mediante MAXDOP 1 y xlargerc. El CCI se ordena en una columna BIGINT sin duplicados.
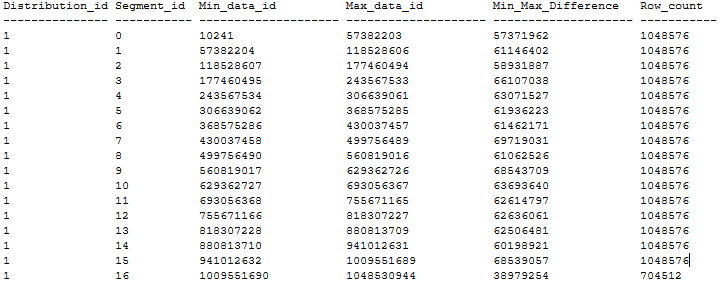
Creación de un CCI ordenado en tablas grandes
La creación de un CCI ordenado es una operación sin conexión. En el caso de tablas sin particiones, los datos no serán accesibles para los usuarios hasta que se complete el proceso de creación del CCI ordenado. En el caso de tablas con particiones, como el motor crea el CCI ordenado partición a partición, los usuarios todavía pueden acceder a los datos de las particiones en las que la creación del CCI ordenado no está en curso. Puede usar esta opción para minimizar el tiempo de inactividad durante la creación del CCI ordenado en tablas grandes:
- Cree particiones en la tabla grande de destino (llamada
Table_A). - Cree una tabla de CCI ordenado vacía (llamada
Table_B) con la misma tabla y esquema de particiones queTable_A. - Cambie una partición de
Table_AaTable_B. - Ejecute
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>para volver a generar la partición cambiada enTable_B. - Repita los pasos 3 y 4 para cada partición de
Table_A. - Una vez que todas las particiones se han cambiado de
Table_AaTable_By se han vuelto a generar, elimineTable_Ay cambie el nombre deTable_BaTable_A.
Sugerencia
Para una tabla del grupo de SQL dedicada con un CCI ordenado, ALTER INDEX REBUILD volverá a ordenar los datos mediante tempdb. Supervise tempdb durante las operaciones de regeneración. Si necesita más espacio en tempdb, escale verticalmente el grupo. Vuelva a reducirlo verticalmente una vez completada la recompilación del índice.
Para una tabla del grupo de SQL dedicada con un CCI ordenado, ALTER INDEX REORGANIZE no vuelve a ordenar los datos. Para volver a ordenar los datos, use ALTER INDEX REBUILD.
Para obtener más información sobre el mantenimiento de CCI ordenado, consulte Optimización de índices de almacén de columnas en clúster.
Diferencias de características en las funcionalidades de SQL Server 2022
SQL Server 2022 (16.x) introdujo índices de almacén de columnas en clúster y ordenados de forma similar a la característica de los grupos de SQL dedicados en Azure Synapse.
- Actualmente, solo SQL Server 2022 (16.x) y versiones posteriores admiten funcionalidades mejoradas de eliminación de segmentos agrupados de almacén de columnas en clúster para los tipos de datos string, binary y guid, y el tipo de datos datetimeoffset para la escala superior a dos. Anteriormente, esta eliminación de segmentos se aplica a los tipos de datos numéricos, de fecha y hora, y al tipo de datos datetimeoffset con escala menor o igual que dos.
- Actualmente, solo SQL Server 2022 (16.x) y versiones posteriores admiten la eliminación de grupos de filas de almacén de columnas agrupados para el prefijo de predicados
LIKE, por ejemplocolumn LIKE 'string%'. No se admite la eliminación de segmentos para el uso sin prefijo de LIKE, comocolumn LIKE '%string'.
Para obtener más información, consulte Novedades de los índices de almacén de columnas.
Ejemplos
A. Para comprobar las columnas ordenadas y el ordinal del orden:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Para cambiar el ordinal de la columna, agregar o eliminar columnas de la lista de ordenación o cambiar de CCI a CCI ordenado:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Pasos siguientes
- Para obtener más sugerencias sobre desarrollo, vea la información general sobre desarrollo.
- Introducción a los índices de almacén de columnas
- Novedades de los índices de almacén de columnas
- Guía de diseño de índices de almacén de columnas
- Rendimiento de las consultas de índices de almacén de columnas