Administración de costos del grupo de SQL sin servidor en Azure Synapse Analytics
En este artículo se explica cómo puede calcular y administrar los costos de un grupo de SQL sin servidor en Azure Synapse Analytics:
- Cantidad estimada de datos procesados antes de emitir una consulta.
- Uso de la característica de control de costos para establecer el presupuesto.
Tenga en cuenta que los costos del grupo SQL sin servidor en Azure Synapse Analytics son tan solo una parte de los costos mensuales de la factura de Azure. Si usa otros servicios de Azure, se le facturarán todos los servicios y recursos de Azure usados en la suscripción de Azure, incluidos los servicios de terceros. En este artículo se explica cómo planear y administrar los costos de un grupo de SQL sin servidor en Azure Synapse Analytics.
Datos procesados
Los datos procesados conforman la cantidad de datos que el sistema almacena temporalmente mientras se ejecuta una consulta. Los datos procesados se componen de las siguientes cantidades:
- Cantidad de datos leídos del almacenamiento. Esta cantidad incluye:
- Los datos leídos al leer los datos.
- Los datos leídos al leer los metadatos (para formatos de archivo que contienen metadatos, como Parquet).
- Cantidad de datos en resultados intermedios. Estos datos se transfieren entre los nodos mientras se ejecuta la consulta. Incluye la transferencia de datos al punto de conexión, en un formato sin comprimir.
- Cantidad de datos escritos en el almacenamiento. Si usa CETAS para exportar el conjunto de resultados al almacenamiento, se agrega la cantidad de datos escritos a la cantidad de datos procesados de la parte SELECT de CETAS.
La lectura de archivos del almacenamiento está muy optimizada. Este proceso utiliza las siguientes opciones:
- Una captura previa, que puede agregar cierta sobrecarga a la cantidad de datos leídos. Si una consulta lee un archivo completo, no habrá ninguna sobrecarga. En cambio, si un archivo se lee parcialmente igual que sucede en las consultas de tipo TOP N, se leen más datos mediante la captura previa.
- Un analizador de valores separados por comas (CSV) optimizado. Si usa PARSER_VERSION='2.0' para leer archivos CSV, se incrementa ligeramente la cantidad de datos leídos en el almacenamiento. Un analizador de CSV optimizado lee archivos en paralelo y en fragmentos de igual tamaño. Asimismo, estos fragmentos no contienen necesariamente filas completas. Para asegurarse de que se analizan todas las filas, el analizador de CSV optimizado también lee pequeños fragmentos de partes adyacentes. Tenga en cuenta que este proceso agrega una pequeña cantidad de sobrecarga.
Estadísticas
El optimizador de consultas del grupo SQL sin servidor se basa en las estadísticas para generar planes de ejecución de consulta óptimos. Puede crear estadísticas de forma manual. De lo contrario, el grupo SQL sin servidor las crea automáticamente. En cualquier caso, las estadísticas se crean mediante la ejecución de una consulta independiente que devuelve una columna específica a una velocidad de muestra proporcionada. Esta consulta tiene asociada una cantidad de datos procesados.
Si ejecuta la misma consulta o cualquier otra que se beneficie de las estadísticas creadas, las estadísticas se reutilizarán si es posible. Igualmente, no se procesan datos adicionales en la creación de estadísticas.
Cuando se crean estadísticas para una columna de Parquet, solo se lee la columna pertinente en los archivos. Asimismo, cuando se crean estadísticas para una columna CSV, se leen y analizan archivos completos.
Redondeo
La cantidad de datos procesados se redondea al número de MB más cercano por consulta. Cada consulta tiene un mínimo de 10 MB de datos procesados.
Los datos procesados no incluyen
- Metadatos de nivel de servidor (como inicios de sesión, roles y credenciales de nivel de servidor).
- Bases de datos que se crean en el punto de conexión. Estas bases de datos solo contienen metadatos (como usuarios, roles, esquemas, vistas, funciones con valores de tabla insertados [TVF], procedimientos almacenados, credenciales de ámbito de base de datos, orígenes de datos externos, formatos de archivo externos y tablas externas).
- Si usa la inferencia de esquemas, se leerán los fragmentos de archivo para inferir los nombres de columna y los tipos de datos, y la cantidad de datos leídos se agregará a la cantidad de datos procesados.
- Instrucciones del lenguaje de definición de datos (DDL), excepto la instrucción CREATE STATISTICS, ya que procesa los datos del almacenamiento en función del porcentaje de muestra especificado.
- Consultas solo de metadatos.
Reducción de la cantidad de datos procesados
Puede optimizar la cantidad de datos procesados por consulta y mejorar el rendimiento mediante la creación de particiones y la conversión de los datos en un formato comprimido basado en columnas, como Parquet.
Ejemplos
Imagine tres tablas.
- La tabla population_csv tiene una copia de seguridad de 5 TB de archivos CSV. Los archivos se organizan en cinco columnas de igual tamaño.
- La tabla population_parquet tiene los mismos datos que la tabla population_csv. Asimismo, cuenta con 1 TB de archivos de Parquet. Esta tabla es más pequeña que la anterior porque los datos se comprimen en formato Parquet.
- La tabla very_small_csv tiene una copia de seguridad de 100 KB de archivos CSV.
Consulta 1: SELECT SUM(population) FROM population_csv
Esta consulta lee y analiza archivos completos para obtener los valores de la columna de rellenado. Los nodos procesan fragmentos de esta tabla y la suma de los valores rellenados de cada fragmento se transfiere entre los nodos. La suma final se transfiere al punto de conexión.
Esta consulta procesa 5 TB de datos más una pequeña sobrecarga de cantidad de transferencia de sumas de fragmentos.
Consulta 2: SELECT SUM(population) FROM population_parquet
Cuando se consultan formatos comprimidos y basados en columnas como Parquet, se leen menos datos que en la consulta 1. Verá este resultado porque el grupo de SQL sin servidor lee una sola columna comprimida en lugar de todo el archivo. En este caso, se leen 0,2 TB. (Cinco columnas de igual tamaño son 0,2 TB cada una). Los nodos procesan fragmentos de esta tabla y la suma de los valores rellenados de cada fragmento se transfiere entre los nodos. La suma final se transfiere al punto de conexión.
Esta consulta procesa 0,2 TB de datos más una pequeña sobrecarga de cantidad de transferencia de sumas de fragmentos.
Consulta 3: SELECT * FROM population_parquet
Esta consulta lee todas las columnas y transfiere todos los datos en un formato sin comprimir. Si el formato de compresión es 5:1, la consulta procesa 6 TB porque Lee 1 TB y transfiere 5 TB de datos sin comprimir.
Consulta 4: SELECT COUNT(*) FROM very_small_csv
Esta consulta lee archivos completos. El tamaño total de los archivos de almacenamiento de esta tabla es de 100 KB. Los nodos procesan fragmentos de esta tabla y la suma de los valores de cada fragmento se transfiere entre los nodos. La suma final se transfiere al punto de conexión.
Esta consulta procesa poco más de 100 KB de datos. La cantidad de datos procesados en esta consulta se redondea a 10 MB, tal como se especifica en la sección de Redondeo de este artículo.
Control de costos
La característica de control de costos del grupo de SQL sin servidor permite establecer el presupuesto para la cantidad de datos procesados. Puede establecer el presupuesto en TB de datos procesados por día, semana y mes. Al mismo tiempo, puede tener uno o más presupuestos establecidos. Para configurar el control de costos para el grupo de SQL sin servidor, puede usar Synapse Studio o T-SQL.
Configuración del control de costos para el grupo de SQL sin servidor en Synapse Studio
Para configurar el control de costos para el grupo de SQL sin servidor en Synapse Studio, vaya a la opción para administrar elementos en el menú de la izquierda y seleccione el elemento del grupo de SQL en la opción Grupos de análisis. Al mantener el mouse sobre el grupo de SQL sin servidor, observará un icono para el control de costos; haga clic en él.
Una vez que haga clic en el icono del control de costos, aparecerá una barra lateral:
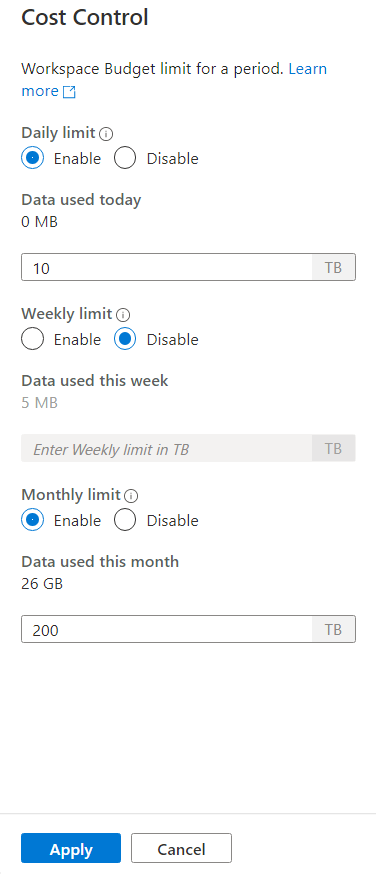
Para establecer uno o más presupuestos, haga clic primero en el botón de radio Habilitar del presupuesto que quiera establecer y, a continuación, escriba el valor entero en el cuadro de texto. La unidad del valor está en TB. Una vez que haya configurado los presupuestos que quiera, haga clic en el botón de aplicar en la parte inferior de la barra lateral. Con estos pasos ya tendrá establecido el presupuesto.
Configuración del control de costos para el grupo de SQL sin servidor en T-SQL
Para configurar el control de costos para el grupo de SQL sin servidor en T-SQL, debe ejecutar uno o varios de los siguientes procedimientos almacenados.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Para ver la configuración actual, ejecute la siguiente instrucción de T-SQL:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Para ver la cantidad de datos procesados durante el día, la semana o el mes actuales, ejecute la siguiente instrucción de T-SQL:
SELECT * FROM sys.dm_external_data_processed
Superación de los límites definidos en el control de costos
En caso de que se supere cualquier límite durante la ejecución de la consulta, esta no se completará.
Si se supera el límite, se rechazará la nueva consulta con el mensaje de error que contiene los detalles, el límite definido y los datos procesados del período. Por ejemplo, en caso de que se ejecute una nueva consulta, donde el límite semanal se establezca en 1 TB y se supere, el mensaje de error sería el siguiente:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Pasos siguientes
Para obtener información sobre cómo optimizar las consultas para el rendimiento, consulte Prácticas recomendadas para el grupo de SQL sin servidor.