Solución de problemas de escalado automático de conjuntos de escalado de máquinas virtuales
Problema: ha creado una infraestructura de escalado automático en Azure Resource Manager mediante conjuntos de escalado de máquinas virtuales (por ejemplo, mediante la implementación de una plantilla como esta: https://github.com/Azure/azure-quickstart-templates/blob/master/application-workloads/python/vmss-bottle-autoscale/azuredeploy.parameters.json), ha definido las reglas de escalado y funciona perfectamente, salvo que, con independencia de la cantidad de carga que coloque en las máquinas virtuales, no se escala de forma automática.
Pasos para solucionar problemas
Entre los aspectos que debe considerar se incluyen:
¿Cuántas vCPU tiene cada máquina virtual? ¿Está cargando cada vCPU? La plantilla de inicio rápido de Azure del ejemplo anterior incluye un script do_work.php, que carga una única vCPU. Si usa una máquina virtual con un tamaño superior a una única vCPU, como Standard_A1 o D1, tendrá que ejecutar esta carga varias veces. Compruebe el número de vCPU de las máquinas virtuales después de consultar Tamaños de las máquinas virtuales Windows en Azure.
¿Cuántas máquinas virtuales hay en el conjunto de escalado de máquinas virtuales? ¿Está realizando trabajos en cada una de ellas?
Solo se produce un evento de escalabilidad horizontal si el promedio de uso de CPU en todas las máquinas virtuales de un conjunto de escalado supera el valor de umbral durante el tiempo interno definido en las reglas de escalado automático.
¿Falta cualquier evento de escalado?
Compruebe los registros de auditoría en el Portal de Azure para ver los eventos de escalado. Tal vez se haya producido un escalado o una reducción vertical que se ha perdido. Puede filtrar por "Escala".

¿Son los umbrales de reducción y escalado horizontal suficientemente diferentes?
Imagine que establece una regla de escalado horizontal cuando el promedio de uso de la CPU es mayor del 50 % durante más de cinco minutos y de reducción horizontal cuando el promedio de uso de la CPU es inferior al 50 %. Este valor puede provocar un problema de "oscilación" cuando el uso de la CPU está cerca del umbral, con acciones de escalado que aumentan y disminuyen constantemente el tamaño del conjunto. Debido a este valor, el servicio de escalado automático intenta evitar una "oscilación", lo que puede resultar en la no realización del escalado. Por tanto, asegúrese de que los umbrales de escalabilidad y reducción horizontal son lo suficiente diferentes como para permitir un cierto espacio entre el escalado.
¿Escribió su propia plantilla JSON?
Es fácil cometer errores, así que comience con una plantilla como la anterior que ya sabemos que funciona y haga pequeños cambios incrementales.
¿Puede escalar o reducir horizontalmente de forma manual?
Intente volver a implementar el recurso de conjunto de escalado de máquinas virtuales con otra configuración de "capacidad" para cambiar el número de máquinas virtuales manualmente. Este es un ejemplo de plantilla : https://github.com/Azure/azure-quickstart-templates/tree/master/quickstarts/microsoft.compute/vmss-scale-existing (es posible que tenga que editar la plantilla para asegurarse de que tiene el mismo tamaño de máquina que usa el conjunto de escalado. Si puede cambiar correctamente el número de máquinas virtuales de forma manual, sabrá que ha aislado el problema al escalado automático.
Compruebe los recursos Microsoft.Compute/virtualMachineScaleSet y Microsoft.Insights en el Explorador de recursos de Azure
Azure Resource Explorer es una herramienta indispensable de solución de problemas que muestra el estado de los recursos de Azure Resource Manager. Haga clic en la suscripción y examine el grupo de recursos que se están diagnosticando. En el proveedor de recursos de Compute, mire el conjunto de escalado de máquinas virtuales que ha creado y compruebe la vista de instancias, en la que se muestra el estado de una implementación. Compruebe también la vista de instancias del conjunto de escalado de máquinas virtuales. Después, entre en el proveedor de recursos de Microsoft.Insights y compruebe que las reglas de escalado automático están bien.
¿Funciona la extensión Diagnóstico y emite los datos de rendimiento?
Actualización: el escalado automático de Azure se ha mejorado para usar una canalización de métricas basada en host que ya no requiere la instalación de una extensión de diagnóstico. Los siguientes párrafos ya no se aplican si crea una aplicación de escalado automático con la nueva canalización. Un ejemplo de plantillas de Azure que se han convertido para usar la canalización del host está disponible aquí: https://github.com/Azure/azure-quickstart-templates/blob/master/application-workloads/python/vmss-bottle-autoscale/azuredeploy.parameters.json.
El uso de métricas basadas en host para el escalado automático es mejor por las razones siguientes:
Menos partes móviles ya que no es necesario instalar ninguna extensión de diagnóstico.
Plantillas más sencillas. Basta con que agregue reglas de escalado automático de Insights a una plantilla de conjunto de escalado existente.
Informes más confiable e inicio rápido de nuevas máquinas virtuales.
El único motivo por el que querría seguir usando una extensión de diagnóstico es si necesita informes o escalado de diagnósticos de memoria. Las métricas basadas en host no informan sobre memoria.
Teniendo este en cuenta, siga el resto de este artículo si usa extensiones de diagnóstico para el escalado automático.
El escalado automático en Azure Resource Manager puede funcionar (aunque ya no es necesario) por medio de una extensión de máquina virtual llamada extensión de diagnóstico. Emite datos de rendimiento para una cuenta de almacenamiento que se define en la plantilla. A continuación, el servicio Azure Monitor agrega estos datos.
Si el servicio Insights no puede leer datos de las máquinas virtuales, debería enviarle un correo electrónico. Por ejemplo, recibirá un correo electrónico si las máquinas virtuales están fuera de servicio. Asegúrese de comprobar el correo electrónico, en la dirección de correo electrónico especificada al crear la cuenta de Azure.
También puede comprobar los datos usted mismo. Observe la cuenta de almacenamiento de Azure mediante Cloud Explorer. Por ejemplo, si usa Cloud Explorer de Visual Studio, inicie sesión y elija la suscripción de Azure que utilice. Después, mire el nombre de la cuenta de almacenamiento de Diagnostics al que se hace referencia en la definición de extensión de Diagnostics en la plantilla de la implementación.
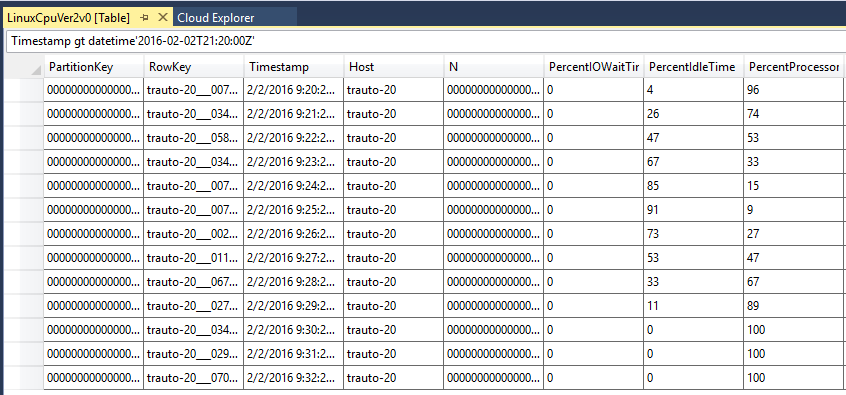
Verá una serie de tablas en las que se almacenan los datos de cada máquina virtual. Tomando como ejemplo Linux y las métricas de CPU, observe las filas más recientes. Visual Studio Cloud Explorer es compatible con un lenguaje de consulta para que pueda ejecutar una consulta. Por ejemplo, puede ejecutar la consulta "Timestamp gt datetime"2016-02-02T21:20:00Z"" para asegurarse de que obtiene los eventos más recientes. La zona horaria se corresponde con la hora UTC. ¿Se corresponden los datos que puede ver allí con las reglas de escalado que ha configurado? En el ejemplo siguiente, el uso de la CPU para la máquina 20 empezó a aumentar al 100 % durante los últimos cinco minutos.
Si los datos no están allí, significa que el problema está relacionado con la extensión de diagnóstico que se ejecuta en las máquinas virtuales. Si los datos están allí, significa que hay un problema con las reglas de escalado o con el servicio Insights. Compruebe el estado de Azure.
Una vez que haya realizado estos pasos, si sigue teniendo problemas con el escalado automático, puede probar los recursos siguientes:
- Visite la página Solución de problemas comunes con los conjuntos de escalado de máquinas virtuales.
- Lea los foros en Página de preguntas y respuestas de Microsoft o Desbordamiento de pila
- Realice una llamada de soporte técnico. Esté preparado para compartir la plantilla y una vista de los datos de rendimiento.