Usar modelos basados en Azure Machine Learning
Los datos unificados en Dynamics 365 Customer Insights - Data son un origen para crear modelos de aprendizaje automático que pueden generar información empresarial adicional. Customer Insights - Data se integra con Azure Machine Learning para usar sus propios modelos personalizados.
Requisitos previos
- Tener acceso a Customer Insights - Data
- Una suscripción de Azure Enterprise activa
- Perfiles de cliente unificados
- Exportación de tablas a Azure Blob Storage configurado
Configurar el área de trabajo de Azure Machine Learning
Consulte Crear un espacio de trabajo de Azure Machine Learning para ver diferentes opciones para crear el área de trabajo. Para obtener el mejor rendimiento, cree el espacio de trabajo en una región de Azure que esté geográficamente más cerca de su entorno de Customer Insights.
Acceda a su espacio de trabajo a través de Azure Machine Learning Studio. Hay varias formas de interactuar con su espacio de trabajo.
Trabajar con el diseñador de Azure Machine Learning
El diseñador de Azure Machine Learning proporciona un lienzo visual donde puede arrastrar y soltar conjuntos de datos y módulos. Una canalización por lotes creada en el diseñador se puede integrar en Customer Insights - Data si está configurada en consecuencia.
Trabajo con el SDK de Azure Machine Learning
Los científicos de datos y los desarrolladores de IA utilizan el SDK de Azure Machine Learning para crear flujos de trabajo de aprendizaje automático. Actualmente, los modelos entrenados con el SDK no se pueden integrar directamente. Se requiere una canalización de inferencia por lotes que use ese modelo para la integración con Customer Insights - Data.
Requisitos de la canalización por lotes para integración con Customer Insights - Data
Configuración del conjunto de datos
Cree conjuntos de datos para usar datos de tabla de Customer Insights para su canalización de inferencia por lotes. Registre estos conjuntos de datos en el espacio de trabajo. Actualmente, solo se admiten conjuntos de datos tabulares en formato .csv. Parametrice los conjuntos de datos que corresponden a los datos de la tabla como parámetro de canalización.
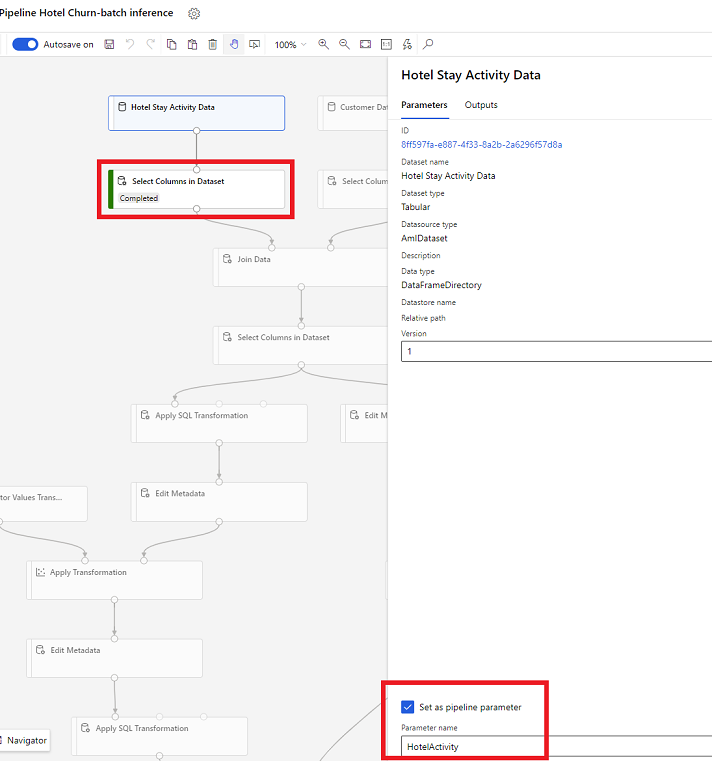
Parámetros de conjunto de datos en Designer
En el diseñador, abra Seleccionar columnas en conjunto de datos y seleccione Establecer como parámetro de canalización, donde proporciona un nombre para el parámetro.
Parámetro de conjunto de datos en SDK (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Canalización de inferencia por lotes
En el diseñador, use una canalización de aprendizaje para crear o actualizar una canalización de inferencia. Actualmente, solo se admiten canalizaciones de inferencia por lotes.
Con el SDK, publique la canalización en un punto de conexión. Actualmente, Customer Insights - Data se integra con la canalización predeterminada en un punto de conexión de canalización por lotes en el espacio de trabajo de Machine Learning.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
Importar datos de canalización
El diseñador proporciona el Módulo de exportación de datos que permite exportar la salida de una canalización al almacenamiento de Azure. Actualmente, el módulo debe usar el tipo de almacén de datos Almacenamiento de blobs de Azure y parametrizar el Almacén de datos y la Ruta relativa. El sistema anula ambos parámetros durante la ejecución de la canalización con un almacén de datos y una ruta a la que puede acceder la aplicación.
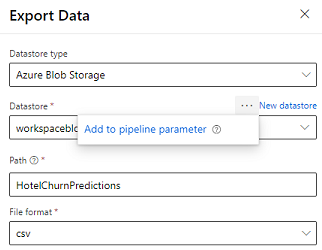
Al escribir la salida de la inferencia utilizando código, cargue la salida en una ruta dentro de un almacén de datos registrado del área de trabajo. Si la ruta y el almacén de datos están parametrizados en la canalización, Customer Insights puede leer e importar la salida de la inferencia. Actualmente, se admite una única salida tabular en formato csv. La ruta debe incluir el directorio y el nombre del archivo.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name