Información general de los trabajos de exportación e importación de datos
Para crear y administrar la importación y exportación de datos de trabajos, debe usar el espacio de trabajo Gestión de datos. De forma predeterminada, el proceso de importación y exportación de datos crea una tabla de almacenamiento provisional para cada entidad en la base de datos de destino. Las tablas de almacenamiento provisional le permiten verificar, limpiar o convertir datos antes de moverlos de sitio.
Nota
Este artículo asumen que está familiarizado con las entidades de datos.
Proceso de exportación e importación de datos
Aquí tiene los pasos que debe realizar para importar o exportar datos.
Cree un trabajo de importación o exportación en el que pueda realizar las tareas siguientes:
- Defina la categoría del proyecto.
- Identifique las entidades que se importarán o exportarán.
- Establezca el formato de datos del trabajo.
- Ordene las entidades para que puedan procesarse en grupos lógicos que tengan sentido.
- Determine si quiere usar las tablas de almacenamiento provisional.
Confirme que los datos de origen y destino estén asignados correctamente.
Compruebe la seguridad del trabajo de importación o exportación.
Ejecute el trabajo de importación o exportación.
Confirme que el trabajo se ejecutó del modo esperado; para ello, consulte el historial del trabajo.
Limpie las tablas de almacenamiento provisional.
En las secciones restantes de este artículo se proporcionan más información acerca de cada paso del proceso.
Billete
Para actualizar el formulario de importación y exportación de datos para ver el último progreso, utilice el icono de actualización del formulario. No se recomienda la actualización del nivel del explorador porque interrumpirá cualquier trabajo de importación o exportación que no se ejecute en un lote.
Crear un trabajo de importación o exportación
Un trabajo de importación o exportación de datos puede ejecutarse una o varias veces.
Definir la categoría del proyecto
Le recomendamos que se tome el tiempo necesario para seleccionar una categoría de proyecto apropiada para el trabajo de importación o exportación. Las categorías de proyecto pueden ayudarle a administrar los trabajos relacionados.
Identificar las entidades que se importarán o exportarán
Puede agregar entidades específicas a un trabajo de importación o exportación o seleccionar la plantilla que se aplicará. Las plantillas rellenan un trabajo con una lista de entidades. La opción Aplicar la plantilla solo está disponible después de nombrar el trabajo y guardarlo.
Establecer el formato de datos del trabajo
Al seleccionar una entidad, debe seleccionar el formato de los datos que se exportan o importan. Puede definir los formatos mediante el icono Configuración de orígenes de datos. Un formato de datos de origen es una combinación de Tipo, Formato de archivo, Delimitador de la fila y Delimitador de columna. También hay otros atributos, pero estos son los clave para comprender. En la tabla siguiente aparecen las combinaciones válidas.
| Formato de archivo | Delimitador de columna/fila | Estilo XML |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | Elemento-XML atributo-XML |
| Delimitado, ancho fijo | Coma, punto y coma, tabulador, barra vertical, dos puntos | -NA- |
Billete
Es importante seleccionar el valor correcto para Delimitador de fila, Delimitador de columna, y Calificador de texto si la opción Formato de archivo está configurada en Delimitado. Asegúrese de que sus datos no contengan el carácter utilizado como delimitador o calificador, ya que esto puede provocar errores durante la importación y exportación.
Nota
Para formatos de archivo basados en XML, asegúrese de usar solo caracteres legales. Para obtener más información sobre los caracteres válidos, consulte Caracteres válidos en XML 1.0. XML 1.0 no permite ningún carácter de control excepto tabulaciones, retornos de carro y saltos de línea. Ejemplos de caracteres ilegales son corchetes, corchetes y barras invertidas.
Utilice Unicode en lugar de una página de códigos específica para importar o exportar datos. Esto ayuda a proporcionar los resultados más consistentes y eliminará los trabajos de administración de datos que fallan porque incluyen caracteres Unicode. Todos los formatos de datos de origen definidos por el sistema que usan Unicode tienen Unicode en el nombre del origen. El formato Unicode se aplica seleccionando una página de códigos ANSI de codificación Unicode como Página de códigos en la ficha Configuración regional. Seleccione una de las siguientes páginas de códigos para Unicode:
| Página de códigos | Nombre para mostrar |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Para obtener más información sobre las páginas de códigos, consulte Identificadores de páginas de códigos.
Ordenar las entidades
Puede ordenar las entidades en una plantilla de datos o en trabajos de importación y exportación. Cuando ejecute un trabajo que contenga más de una entidad de datos, asegúrese de que están correctamente ordenadas. Puede ordenar las entidades principales para trabajar con cualquier dependencia funcional que esté entre ellas. Si las entidades no tienen dependencias funcionales, pueden ser programadas en una la importación o exportación paralela.
Unidades de ejecución, niveles y secuencias
La unidad de ejecución, el nivel de la unidad de ejecución y el orden de una entidad le permiten controlar el orden de los datos que se exportan o importan.
- Las entidades que estén en unidades de ejecución diferentes se procesarán en paralelo.
- En cada unidad de ejecución, se procesan las entidades en paralelo si tienen el mismo nivel.
- En cada nivel, se procesan las entidades según su número de secuencia en dicho nivel.
- Una vez procesado un nivel, se procesa el siguiente.
Volver a ordenar
Es posible que quiera volver a ordenar las entidades según las siguientes situaciones:
- Si solo usó un trabajo de datos para todos los cambios, puede usar las opciones para volver a ordenar y así optimizar el tiempo de ejecución del trabajo completo. En estos casos, puede usar la unidad de ejecución para representar el módulo, el nivel para representar el área de características en el módulo y la secuencia para representar la entidad. Al usar este método, puede trabajar en paralelo con diferentes módulos, pero aun así puede seguir trabajando en el orden de un módulo. Para que garantizar que las operaciones paralelas se realizan correctamente, debe tener en cuenta todas las dependencias.
- Si se utilizan varios trabajos de datos (por ejemplo, un trabajo para cada módulo), puede utilizar la secuenciación en el nivel y ordenar las entidades para asegurar una ejecución óptima.
- Si no hay dependencias en absoluto, puede ordenar las entidades en diferentes unidades de ejecución para garantizar una optimización máxima.
El menú Volver a ordenar está disponible cuando se seleccionan varias entidades. Puede volver a ordenar según la unidad de ejecución, el nivel o las opciones de secuencia. Puede establecer un incremento al volver a ordenar las entidades que haya seleccionado. Cada incremento específico actualizará la unidad, el nivel o el número de secuencia que se haya seleccionado para cada entidad.
Ordenación
Puede usar la opción Ordenar por para ver la lista de entidades en orden secuencial.
Truncar
Para proyectos de importación, puede optar por truncar registros en las entidades antes de la importación. El truncamiento resulta útil si los registros deben importarse en un conjunto claro de tablas. Esta configuración está desactivada de forma predeterminada.
Confirmar que los datos de origen y destino estén asignados correctamente
La asignación es una función que se aplica a los trabajos de exportación e importación.
- En un trabajo de importación, la función de asignación indica qué columnas del archivo de origen serán las columnas de la tabla de almacenamiento provisional. Por lo tanto, el sistema puede determinar qué datos de columna del archivo de origen se deberán copiar las columnas correspondientes de la tabla de almacenamiento provisional.
- En un trabajo de exportación, la función de asignación indica qué columnas de la tabla de almacenamiento provisional (esto es, el origen) serán las columnas del archivo de destino.
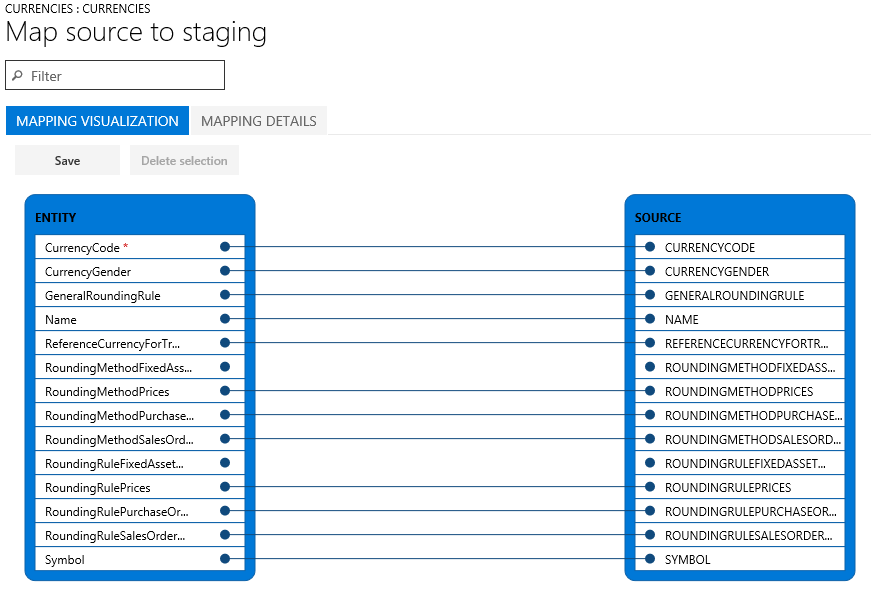
Si coinciden los nombres de columna en la tabla de almacenamiento provisional y el archivo, el sistema establecerá automáticamente la asignación según esos nombres. Sin embargo, si los nombres difieren, las columnas no se asignarán automáticamente. En estos casos, debe completar la asignación seleccionando la opción Ver mapa en la entidad del trabajo de datos.
Existen dos vistas de asignación: Visualización de la asignación que es la vista predeterminada y Detalles de la asignación. Un asterisco rojo (*) identifica los campos requeridos en la entidad. Estos campos deben asignarse para poder ejecutar la entidad. Puede desasignar otros campos según necesite cuando trabaje con la entidad. Para desasignar un campo seleccione el campo de la columna Entidad o la columna Origen y, a continuación, seleccione Eliminar selección. Seleccione Guardar para guardar los cambios y cierre la página para volver al proyecto. Puede usar el mismo proceso para editar la asignación de campos de origen para que se ejecute una vez realizada la importación.
Puede crear una asignación en la página seleccionando Crear la asignación de origen. Una asignación generada actúa como una asignación automática. Por lo tanto, debe asignar manualmente cualquier campo sin asignar.
Compruebe la seguridad del trabajo de importación o exportación
El acceso al área de trabajo Administración de datos puede ser limitado, de modo que los usuarios que no sean administradores solo pueden acceder a ciertos trabajos de datos. El acceso a un trabajo de datos implica acceso total al historial de ejecución de ese trabajo y acceso a las tablas de ensayo. Por lo tanto, debe asegurarse de que los controles de acceso son los adecuados al crear un trabajo de datos.
Proteger un trabajo mediante roles y usuarios
Utilice el menú Roles aplicables para limitar el trabajo a una o más funciones de seguridad. Solo los usuarios con esos roles tendrán acceso al trabajo.
También puede restringir un trabajo a usuarios específicos. Al asegurar un trabajo mediante usuarios en vez de roles, conseguirá más control si se asignan varios usuarios a un rol.
Proteger un trabajo mediante una entidad jurídica
Los trabajos de datos son globales por naturaleza. Por lo tanto, si un trabajo de datos se creó y se usó en una entidad jurídica, ese trabajo está visible en otras entidades jurídicas del sistema. Este comportamiento predeterminado puede ser útil en algunos escenarios de aplicaciones. Por ejemplo, una organización que importa facturas mediante entidades de datos, puede proporcionar un equipo de procesamiento de facturas centralizado que sea responsable de administrar los errores de facturación de todas las divisiones de la organización. En esta situación, resulta útil que el equipo de procesamiento de facturas centralizado tenga acceso a los trabajos de importación de facturas de todas las entidades jurídicas. Por lo tanto, el comportamiento predeterminado cumple con los requisitos establecidos para la entidad jurídica.
Sin embargo, es posible que una organización quiera tener varios equipos de procesamiento de facturas por cada entidad jurídica. En este caso, un equipo en una entidad jurídica debe tener acceso solo al trabajo de importación de facturas en su propia entidad jurídica. Para cumplir este requisito, puede configurar el control de acceso basado en entidades jurídicas mediante el menú Entidades jurídicas aplicables que está dentro del trabajo de datos. Una vez realizada la configuración, los usuarios podrán ver solo los trabajos que estén disponibles en la entidad jurídica en la que hayan iniciado sesión. Para ver trabajos de otra entidad jurídica, los usuarios deben cambiarse a esa entidad jurídica.
Un trabajo se puede proteger según los roles, usuarios y entidades jurídicas al mismo tiempo.
Ejecutar el trabajo de importación o exportación
Puede ejecutar un trabajo una vez; para ello, seleccione el botón Importar o Exportar después de definir el trabajo. Para configurar un trabajo periódico, seleccione Crear un trabajo de datos recurrente.
Nota
Un trabajo de importación o exportación se puede ejecutar seleccionando el botón Importar o Exportar. Esto programará un trabajo por lotes para que se ejecute solo una vez. Es posible que el trabajo no se ejecute inmediatamente si el servicio por lotes se está ralentizando debido a la carga del servicio por lotes. Los trabajos también se pueden ejecutar sincrónicamente seleccionando Importar ahora o Exportar ahora. Esto inicia el trabajo inmediatamente y resulta útil si el lote no empiezan debido a limitaciones. Los trabajos también se pueden programar para que se ejecuten en un momento posterior. Esto se puede hacer eligiendo la opción Ejecutar por lotes. Los recursos por lote están sujetos a limitaciones, por lo que el trabajo por lotes podría no empezar inmediatamente. El uso de un lote es la opción recomendada porque también ayudará con grandes volúmenes de datos que se deben importar o exportar. Los trabajos por lotes se pueden programar para su ejecución en grupos por lotes específicos, que permiten más control desde una perspectiva de equilibrio de carga.
Confirme que el trabajo funciona como es debido.
Tiene disponible el historial de trabajos por si necesita solucionar algún problema o investigar algún trabajo de importación o exportación. Las ejecuciones de trabajos del historial se organizan según intervalos de tiempo.

Cada ejecución de trabajo proporciona los siguientes detalles:
- Detalles de ejecución
- Registro de ejecución
Los detalles de la ejecución muestran el estado de cada entidad de datos que procesó el trabajo. Por lo tanto, puede buscar rápidamente la siguiente información:
- Qué entidades se procesaron.
- En una entidad, cuántos registros se procesaron correctamente y cuántos fallaron.
- Los registros provisionales de cada entidad.
Puede descargar los datos provisionales en un archivo dedicado a los trabajos de exportación, o bien descargarlo como un paquete de los trabajos de exportación e importación.
Desde la opción de detalles de ejecución, también puede abrir el registro de ejecución.
Importaciones paralelas
Para acelerar la importación de datos, se puede habilitar el procesamiento paralelo de la importación de un archivo si la entidad admite importaciones paralelas. Para configurar la importación paralela para una entidad, se deben seguir los siguientes pasos.
Vaya a Administración del sistema > Áreas de trabajo > Administración de datos.
En la sección Importación y exportación, seleccione el icono Parámetros de marco para abrir la página Parámetros del marco de importación/exportación de datos.
En la pestaña Configuraciones de entidad, seleccione Configurar parámetros de ejecución de entidad para abrir la página Parámetros de ejecución de importación de entidad.
Establezca los siguientes campos para configurar la importación paralela para una entidad:
- En el campo Entidad, seleccione la entidad. Si el campo de la entidad está vacío, el valor vacío se utiliza como configuración predeterminada para todas las importaciones posteriores, si la entidad admite la importación paralela.
- En el campo Importar recuento de registros de umbral, ingrese el recuento de registros de umbral para la importación. Esto determina el recuento de registros que debe procesar un subproceso. Si un archivo tiene 10K registros, un recuento de registros de 2500 con un recuento de tareas de cuatro significará que cada subproceso procesa 2500 registros.
- En el campo Recuento de tareas de importación, ingrese el recuento de tareas de importación. El recuento no debe exceder los subprocesos de lote máximos asignados para el procesamiento por lotes en Administracion del sistema >Configuración del servidor.
Limpieza del historial de trabajos
De forma predeterminada, las entradas del historial de trabajos y los datos de la tabla de preparación relacionados que tengan más de 90 días se eliminan automáticamente. La funcionalidad de limpieza del historial de trabajos en la gestión de datos se puede utilizar para configurar la limpieza periódica del historial de ejecución con un período de retención inferior al predeterminado. Esta funcionalidad reemplaza la funcionalidad anterior de limpieza de tablas de almacenamiento provisional, que ahora ha quedado en desuso. Se limpiarán las tablas siguientes mediante el proceso de limpieza.
Todas las tablas de almacenamiento provisional
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
Se accede a la función Limpieza del historial de ejecución desde Gestión de datos > Limpieza del historial de trabajos.
Parámetros de programación
Al programar el proceso de limpieza, hay que especificar los siguientes parámetros para definir los criterios de limpieza.
Número de días del historial que se conservarán: este valor se usa para controlar la cantidad de historial de ejecución que se va a conservar. El historial se especifica como un número de días. Cuando el trabajo de limpieza se programa como trabajo por lotes periódico, este valor representa un intervalo de tiempo que se mueve continuamente, manteniendo siempre intacto el número de días especificado del historial y eliminando el resto. El valor predeterminado es de siete días.
Número total de horas necesarias para ejecutar el trabajo: en función de la cantidad de historial que haya que limpiar, el tiempo total de ejecución del trabajo de limpieza puede variar de unos minutos a unas horas. Este parámetro debe establecerse en la cantidad de horas que se ejecutará el trabajo. Después de que el trabajo de limpieza se haya ejecutado durante el número de horas especificado, el trabajo saldrá y reanudará la limpieza la próxima vez que se ejecute según el programa de repetición.
Con esta opción de configuración se puede especificar un tiempo de ejecución máximo estableciendo un límite máximo del número de horas que el trabajo debe ejecutarse. La lógica de limpieza pasa por un identificador de ejecución de trabajo a la vez en una secuencia ordenada cronológicamente, donde el más antiguo es el primero para la limpieza del historial de ejecución relacionado. Deja de seleccionar nuevos id. de ejecución para la limpieza cuando la duración restante de la ejecución esté dentro del último 10 % de la duración especificada. En algunos casos, se esperará que el trabajo de limpieza continúe más allá del tiempo máximo especificado. Esto depende en gran parte del número de registros que se deben eliminar para el id. de ejecución actual que se inició antes de que se alcanzara el umbral del 10 %. La limpieza iniciada debe completarse para garantizar la integridad de los datos, lo que significa que la limpieza continúa aunque se supere el límite especificado. Una vez completada, no se seleccionan nuevos identificadores de ejecución y el trabajo de limpieza finaliza. El historial de ejecución restante que no se haya limpiado por falta de tiempo de ejecución se seleccionará la próxima vez que se programe el trabajo de limpieza. El valor predeterminado (y el valor mínimo) de esta configuración está establecido en 2 horas.
Lote periódico: el trabajo de limpieza se puede ejecutar como una ejecución manual puntual o se puede programar para una ejecución periódica por lotes. El lote se puede programar con la opción de configuración Ejecutar en segundo plano, que es la configuración de lote estándar.
Billete
Si no se utiliza la función de limpieza del historial de trabajos, el historial de ejecución de más de 90 días aún se elimina automáticamente. La limpieza del historial de trabajos se puede ejecutar además de esta eliminación automática. Asegúrese de que el trabajo de limpieza esté programado para ejecutarse periódicamente. Como se explicó anteriormente, en cualquier ejecución de limpieza, el trabajo solo limpiará tantas ID de ejecución como sea posible dentro de las horas máximas proporcionadas.
Limpieza y archivo del historial de trabajos
La función de limpieza y archivo del historial de trabajos reemplaza las versiones anteriores de la función de limpieza. Esta sección explica estas nuevas capacidades.
Uno de los principales cambios en la funcionalidad de limpieza es el uso del trabajo por lotes del sistema para limpiar el historial. El uso del trabajo por lotes del sistema permite a las aplicaciones de finanzas y operaciones que el trabajo por lotes de limpieza se programe y se ejecute automáticamente tan pronto como el sistema esté listo. Ya no es necesario programar el trabajo por lotes manualmente. En este modo de ejecución predeterminado, el trabajo por lotes se ejecuta cada hora a partir de medianoche y conserva el historial de ejecución de los siete días más recientes. El historial depurado se archiva para su futura recuperación. A partir de la versión 10.0.20, esta función está siempre activa.
El segundo cambio en el proceso de limpieza es el archivo del historial de ejecución depurado. El trabajo de limpieza archiva los registros eliminados en el almacenamiento de blobs que DIXF usa para integraciones regulares. El archivo archivado está en el formato de paquete DIXF y está disponible durante siete días en el blob durante el cual se podrá descargar. La longevidad predeterminada de siete días para el archivo archivado se puede cambiar a un máximo de 90 días en los parámetros.
Cambiar la configuración predeterminada
Esta funcionalidad se encuentra actualmente en versión preliminar y debe activarse explícitamente habilitando el paquete piloto DMFEnableExecutionHistoryCleanupSystemJob. La función de limpieza por etapas también debe estar activada en la gestión de funciones.
Para cambiar la configuración predeterminada para la longevidad del archivo archivado, vaya al espacio de trabajo de administración de datos y seleccione Limpieza del historial de trabajos. Establezca Días para retener el paquete en blob a un valor entre 7 y 90 (inclusive). Esto tiene efecto en los archivos que se creen después de que se realizó este cambio.
Descarga del paquete archivado
Esta funcionalidad se encuentra actualmente en versión preliminar y debe activarse explícitamente habilitando el paquete piloto DMFEnableExecutionHistoryCleanupSystemJob. La función de limpieza por etapas también debe estar activada en la gestión de funciones.
Para descargar el historial de ejecución archivado, vaya al espacio de trabajo de gestión de datos y seleccione Limpieza del historial de trabajos. Seleccione Historial de copias de seguridad del paquete para abrir el formulario de historial. Este formulario muestra la lista de todos los paquetes archivados. Se puede seleccionar y descargar un archivo seleccionando Descargar paquete. El paquete descargado tiene el formato de paquete DIXF y contiene los siguientes archivos:
- El archivo de la tabla de etapas de entidad
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de