Agregaciones automáticas
Las agregaciones automáticas usan el aprendizaje automático (ML) de última generación para optimizar continuamente los modelos semánticos de DirectQuery a fin de obtener el máximo rendimiento de las consultas de informes. Las agregaciones automáticas se construyen sobre la infraestructura existente de agregaciones definidas por el usuario que se presentó por primera vez con los modelos compuestos para Power BI. A diferencia de las agregaciones definidas por el usuario, no se necesitan amplias aptitudes de modelado de datos y optimización de consultas para configurar y mantener las agregaciones automáticas. Las agregaciones automáticas son de entrenamiento y optimización automáticos. Permiten a los propietarios de modelos semánticos de cualquier nivel de aptitud mejorar el rendimiento de las consultas, lo que proporciona visualizaciones de informes más rápidas para modelos semánticos grandes.
Con las agregaciones automáticas:
- Las visualizaciones de informes son más rápidas: un porcentaje óptimo de consultas de informe se devuelve mediante una caché de agregaciones en memoria mantenidas automáticamente en lugar de sistemas de origen de datos de back-end. Las consultas de valores atípicos que la caché en memoria no devuelve se pasan directamente al origen de datos mediante DirectQuery.
- Arquitectura equilibrada: en comparación con el modo de DirectQuery puro, la mayoría de los resultados de la consulta los devuelve el motor de consultas de Power BI y la caché de agregaciones en memoria. La carga de procesamiento de consultas en los sistemas de origen de datos durante horas punta de creación de informes se puede reducir significativamente, lo que significa una mayor escalabilidad en el back-end del origen de datos.
- Configuración sencilla: los propietarios de modelos semánticos pueden habilitar el entrenamiento de agregaciones automáticas y programar una o varias actualizaciones para el modelo semántico. Con el primer entrenamiento y la primera actualización, las agregaciones automáticas comienzan a crear un marco de agregaciones y agregaciones óptimas. El sistema se ajusta automáticamente en el tiempo.
- Ajuste preciso: con una interfaz de usuario sencilla e intuitiva en la configuración del modelo, puede calcular las mejoras de rendimiento para un porcentaje diferente de las consultas devueltas desde la caché de agregaciones en memoria y realizar ajustes para obtener mejoras aún mayores. Un único control de barra deslizante le ayuda a ajustar el entorno con facilidad.
Requisitos
Planes admitidos
Las agregaciones automáticas son compatibles con modelos de Power BI Premium por capacidad, Premium por usuario y Power BI Embedded.
Orígenes de datos admitidos
Se admiten agregaciones automáticas para los siguientes orígenes de datos:
- Azure SQL Database
- Grupo de SQL dedicado de Azure Synapse
- SQL Server 2019 o posterior
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Modos admitidos
Las agregaciones automáticas se admiten para los modelos del modo DirectQuery. Se admiten modelos de modelo compuesto con tablas de importación y conexiones de DirectQuery. Las agregaciones automáticas solo se admiten para la conexión de DirectQuery.
Permisos
Para habilitar y configurar las agregaciones automáticas, debe ser el propietario del modelo. Los administradores de áreas de trabajo pueden asumir el control como propietarios para configurar las agregaciones automáticas.
Configuración de agregaciones automáticas
Las agregaciones automáticas se configuran en la configuración del modelo. La configuración es sencilla: habilite el entrenamiento de agregaciones automáticas y programe una o varias actualizaciones. Antes de configurar las agregaciones automáticas para el modelo, asegúrese de leer este artículo completo. Proporciona una buena descripción de cómo funcionan las agregaciones automáticas y puede ayudarle a decidir si son adecuadas para el entorno. Cuando esté listo para obtener instrucciones paso a paso sobre cómo habilitar el entrenamiento de las agregaciones automáticas, configurar una programación de actualización y ajustar el entorno, vea Configuración de agregaciones automáticas.
Ventajas
Con DirectQuery, cada vez que un usuario del modelo abre un informe o interactúa con una visualización de informe, las consultas de Data Analysis Expressions (DAX) se pasan al motor de consultas y, después, al origen de datos de back-end como consultas SQL. El origen de datos debe calcular y devolver los resultados de cada consulta. En comparación con los modelos en modo de importación almacenados en memoria, los recorridos de ida y vuelta del origen de datos de DirectQuery pueden consumir mucho tiempo y procesos, lo que a menudo provoca tiempos de respuesta de consulta lentos en las visualizaciones de los informes.
Cuando se habilitan para un modelo de DirectQuery, las agregaciones automáticas pueden mejorar el rendimiento de las consultas de informes, ya que evitan los recorridos de ida y vuelta de las consultas al origen de datos. Los resultados de la consulta agregados previamente se devuelven de forma automática mediante una caché de agregaciones en memoria en lugar de enviarse al origen de datos y devolverse desde ahí. La cantidad de datos agregados previamente en la caché de agregaciones en memoria es una pequeña fracción de los datos que se mantienen en tablas de hechos y de detalles en el origen de datos. El resultado no solo es un mejor rendimiento de las consultas de informes, sino que también reduce la carga en los sistemas de origen de datos de back-end. Con las agregaciones automáticas, solo una pequeña parte de las consultas ad-hoc y de informe que necesitan agregaciones no incluidas en la caché en memoria se pasan al origen de datos de back-end, como sucede con el modo DirectQuery puro.
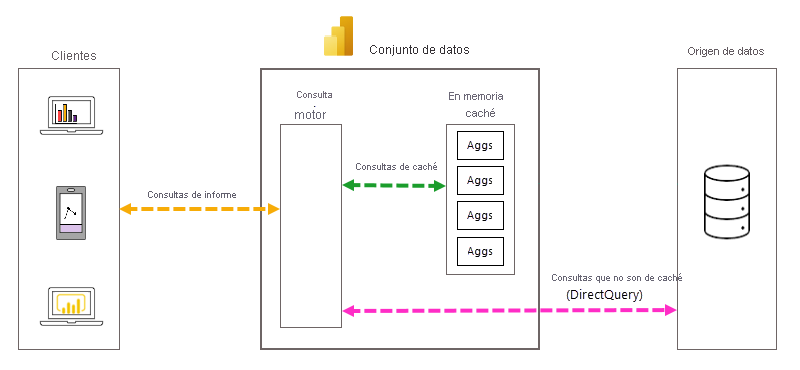
Administración automática de consultas y agregaciones
Aunque las agregaciones automáticas eliminan la necesidad de crear tablas de agregación definidas por el usuario y simplifican considerablemente la implementación de una solución de datos agregada previamente, un conocimiento más profundo de los procesos y dependencias subyacentes resulta útil para comprender cómo funcionan las agregaciones automáticas. Power BI se basa en lo siguiente para crear y administrar agregaciones automáticas.
Registro de consultas
Power BI realiza el seguimiento de las consultas de informe de usuario y modelo en un registro de consultas. Para cada modelo, Power BI mantiene siete días de datos del registro de consultas. Los datos del registro de consultas se ponen al día diariamente. El registro de consultas es seguro y no es visible para los usuarios ni mediante el punto de conexión XMLA.
Operaciones de entrenamiento
Como parte de la primera operación de actualización programada del modelo para la frecuencia seleccionada (Día o Semana), Power BI inicia primero una operación de entrenamiento que evalúa el registro de consultas para garantizar que las agregaciones en la caché de agregaciones en memoria se adaptan a los patrones de consulta cambiantes. Las tablas de agregación en memoria se crean, actualizan o se descartan, y se envían consultas especiales al origen de datos para determinar las agregaciones que se van a incluir en la caché. Pero los datos de las agregaciones calculadas no se cargan en la caché en memoria durante el entrenamiento; se cargan durante la operación de actualización posterior.
Por ejemplo, si elige una frecuencia de Día y el programa actualiza a las 4:00, 9:00, 14:00 y 19:00, solo la actualización diaria a las 4:00 incluirá una operación de entrenamiento y una operación de actualización. Las siguientes actualizaciones programadas a las 9:00, 14:00 y 19:00 para ese día son operaciones de solo actualización que actualizan las agregaciones existentes en la caché.
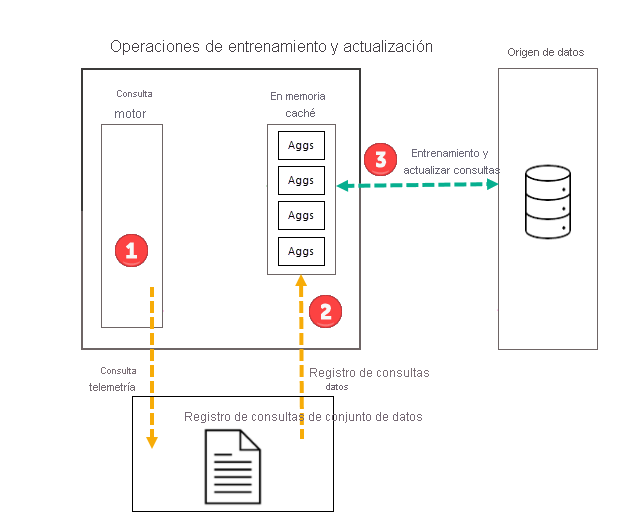
Aunque las operaciones de entrenamiento evalúan las consultas anteriores del registro de consultas, los resultados son lo suficientemente precisos como para garantizar que se abarquen las consultas futuras. Pero no existen garantías de que la caché de agregaciones en memoria devuelva consultas futuras, ya que esas consultas nuevas podrían ser diferentes de las derivadas del registro de consultas. Esas consultas no devueltas por la caché de agregaciones en memoria se pasan al origen de datos mediante DirectQuery. En función de la frecuencia y la clasificación de esas consultas nuevas, sus agregaciones se pueden incluir en la caché de agregaciones en memoria con la siguiente operación de entrenamiento.
La operación de entrenamiento tiene un límite de tiempo de 60 minutos. Si el entrenamiento no puede procesar todo el registro de consultas dentro del límite de tiempo, se registra una notificación en el Historial de actualización del modelo y el entrenamiento se reanuda la próxima vez que se inicie. El ciclo de entrenamiento finaliza y reemplaza las agregaciones automáticas existentes cuando se procesa todo el registro de consultas.
Operaciones de actualización
Como se ha descrito antes, una vez que se completa la operación de entrenamiento como parte de la primera actualización programada para la frecuencia seleccionada, Power BI realiza una operación de actualización que consulta y carga datos de agregaciones nuevas y actualizadas en la caché de agregaciones en memoria y quita las agregaciones que ya no tienen una clasificación suficientemente alta (según lo determinado por el algoritmo de entrenamiento). Todas las actualizaciones posteriores de la frecuencia diaria o semanal elegida son operaciones de solo actualización que consultan el origen de datos para actualizar los datos de agregaciones existentes en la caché. En el ejemplo anterior, las actualizaciones programadas a las 9:00, 14:00 y 19:00 para ese día son operaciones de solo actualización.
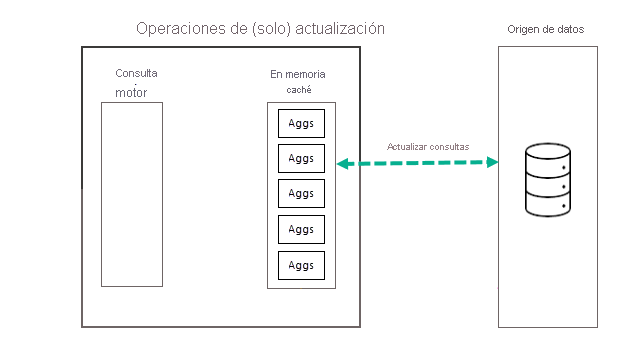
Las actualizaciones programadas de forma periódica durante el día (o la semana) garantizan que los datos de agregaciones en la caché estén más actualizados con los del origen de datos de back-end. Por medio de la configuración del modelo, puede programar hasta 48 actualizaciones al día para asegurarse de que las consultas de informe devueltas por la caché de agregaciones obtengan resultados basados en los datos actualizados más recientes del origen de datos de back-end.
Precaución
Las operaciones de entrenamiento y actualización consumen muchos recursos y procesos tanto para el servicio Power BI como para los sistemas de origen de datos. El aumento del porcentaje de consultas que usan agregaciones significa que se deben consultar y calcular más agregaciones de los orígenes de datos durante las operaciones de entrenamiento y actualización, lo que aumenta la probabilidad de un uso excesivo de los recursos del sistema y puede provocar tiempos de espera. Para obtener más información, vea Ajuste preciso.
Entrenamiento a petición
Como hemos mencionado anteriormente, es posible que un ciclo de entrenamiento no se complete dentro de los límites de tiempo de un solo ciclo de actualización de los datos. Si no desea esperar hasta el siguiente ciclo de actualización programado que incluye entrenamiento, también puede desencadenar a petición el entrenamiento de agregaciones automáticas seleccionando Entrenar y actualizar ahora en la configuración del modelo. El uso de Entrenar y actualizar ahora desencadena una operación de entrenamiento y una operación de actualización. Compruebe el historial de actualización del modelo para ver si la operación actual ha finalizado antes de ejecutar otra operación de entrenamiento y actualización, si es necesario.
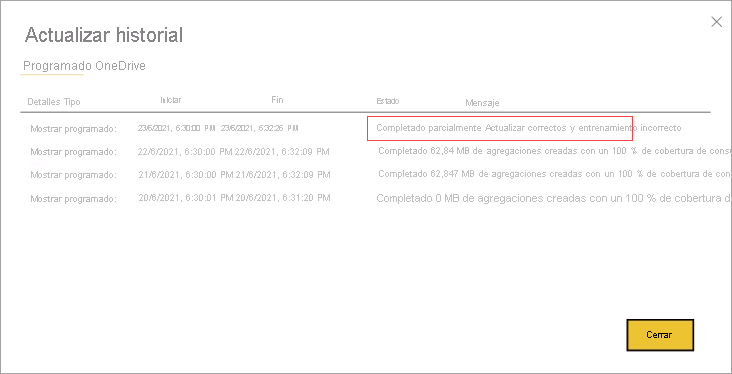
Actualizar historial
Cada operación de actualización se registra en el historial de actualización del modelo. Se muestra información importante sobre cada actualización, incluida el número de agregaciones de memoria que se consumen en la caché para el porcentaje de consultas configurado. Para ver el historial de actualizaciones, en la página Configuración del modelo, haga clic en Historial de actualización. Si quiere profundizar un poco más, seleccione Mostrar detalles.
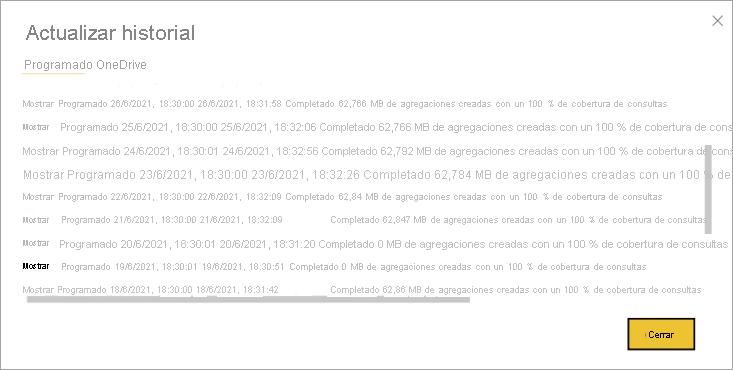
Si comprueba el historial de actualizaciones de forma periódica, puede asegurarse de que las operaciones de actualización programadas se completan dentro de un período aceptable. Asegúrese de que las operaciones de actualización se completan correctamente antes de que comience la siguiente actualización programada.
Errores de entrenamiento y actualización
Aunque Power BI realiza las operaciones de entrenamiento y actualización como parte de la primera actualización programada para la frecuencia diaria o semanal que elija, estas operaciones se implementan como transacciones independientes. Si una operación de entrenamiento no puede procesar completamente el registro de consultas dentro de sus límites de tiempo, Power BI continúa actualizando las agregaciones que hay (y las tablas normales en un modelo compuesto) usando el estado de entrenamiento anterior. En este caso, el historial de actualización indica que la actualización se ha realizado correctamente y el entrenamiento reanudará el procesamiento del registro de consultas la próxima vez que se inicie el entrenamiento. Es posible que el rendimiento de las consultas esté menos optimizado si los patrones de consulta de informe de cliente han cambiado y las agregaciones aún no se han ajustado, pero el nivel de rendimiento alcanzado debería ser mucho mejor que un modelo de DirectQuery sin agregaciones.
Si una operación de entrenamiento requiere demasiados ciclos para finalizar el procesamiento del registro de consultas, considere la posibilidad de reducir el porcentaje de consultas que usan la memoria caché de agregaciones en memoria en la configuración del modelo. Esto reducirá el número de agregaciones creadas en la caché, pero permitirá más tiempo para que se completen las operaciones de entrenamiento y actualización. Para obtener más información, vea Ajuste preciso.
Si el entrenamiento se realiza correctamente pero se produce un error en la actualización, toda la actualización se marca como Error porque el resultado es una caché de agregaciones en memoria no disponible.
Al programar la actualización, puede especificar notificaciones por correo electrónico si hay errores de actualización.
Agregaciones automáticas y definidas por el usuario
En Power BI, se pueden configurar manualmente agregaciones definidas por el usuario en función de las tablas agregadas ocultas del modelo. La configuración de agregaciones definidas por el usuario suele ser compleja y se necesita un mayor nivel de aptitudes de modelado de datos y optimización de consultas. Por otro lado, las agregaciones automáticas eliminan esta complejidad como parte de un sistema controlado por inteligencia artificial. A diferencia de las agregaciones definidas por el usuario que permanecen estáticas, Power BI mantiene continuamente los registros de consulta y, a partir de esos registros, determina patrones de consulta basados en algoritmos de modelado predictivo de aprendizaje automático (ML). Los datos agregados previamente se calculan y almacenan en memoria en función del análisis de patrones de consulta. Con las agregaciones automáticas, los modelos son de entrenamiento y optimización automáticos. A medida que cambian los patrones de consulta de los informes de cliente, las agregaciones automáticas ajustan, priorizan y almacenan en caché las agregaciones que se usan con más frecuencia.
Como las agregaciones automáticas se construyen sobre la infraestructura existente de agregaciones definidas por el usuario, es posible usar tanto agregaciones definidas por el usuario como automáticas de manera conjunta en el mismo modelo. Los modeladores de datos cualificados pueden definir agregaciones para tablas mediante DirectQuery, Importación (con o sin actualización incremental) o modos de almacenamiento dual, al tiempo que tienen las ventajas de más agregaciones automáticas para las consultas mediante conexiones DirectQuery que no acceden a las tablas de agregación definidas por el usuario. Esta flexibilidad permite arquitecturas equilibradas que pueden reducir las cargas de consultas y evitar cuellos de botella.
Las agregaciones creadas en la caché en memoria mediante el algoritmo de entrenamiento de agregaciones automáticas se identifican como agregaciones System. El algoritmo de entrenamiento solo crea y elimina esas agregaciones System a medida que se analizan las consultas de informes y se realizan ajustes a fin de mantener las agregaciones óptimas para el modelo. Tanto las agregaciones definidas por el usuario como las automáticas se actualizan con la actualización. Solo las agregaciones creadas por agregaciones automáticas y marcadas como agregaciones generadas por el sistema se incluyen en el procesamiento automático de agregaciones.
Almacenamiento en caché de consultas y agregaciones automáticas
Power BI Premium también admite el almacenamiento en caché de consultas en Power BI Premium/Embedded para mantener los resultados de la consulta. El almacenamiento en caché de consultas es una característica diferente de las agregaciones automáticas. Con el almacenamiento en caché de consultas, Power BI Premium usa su servicio de almacenamiento en caché local para implementarlo, mientras que las agregaciones automáticas se implementan en el nivel del modelo. Con el almacenamiento en caché de consultas, el servicio solo almacena en caché las consultas para la carga inicial de la página del informe, por lo que el rendimiento de las consultas no mejora cuando los usuarios interactúan con un informe. Por el contrario, las agregaciones automáticas optimizan la mayoría de las consultas de informes mediante el almacenamiento en caché previo de los resultados de las consultas agregadas, incluidas las que se generan cuando los usuarios interactúan con los informes. Tanto el almacenamiento en caché de consultas como las agregaciones automáticas se pueden habilitar para un modelo, pero es probable que no sea necesario.
Supervisión con Azure Log Analytics
Azure Log Analytics (LA) es un servicio de Azure Monitor que Power BI puede usar para guardar los registros de actividad. Con el conjunto de aplicaciones de Azure Monitor, puede recopilar, analizar y actuar sobre los datos de telemetría de los entornos locales y de Azure. Ofrece almacenamiento a largo plazo, una interfaz de consulta ad-hoc y acceso de API para permitir la exportación e integración de datos con otros sistemas. Para obtener más información, vea Uso de Azure Log Analytics en Power BI.
Si Power BI se configura con una cuenta de Azure LA, como se describe en Configuración de Azure Log Analytics para Power BI, puede analizar la tasa de éxito de las agregaciones automáticas. Entre otros aspectos, puede determinar si las consultas de informe se responden desde la caché en memoria.
Para usar esta funcionalidad, descargue la plantilla PBIT y conéctela a la cuenta del análisis de registros, como se describe en esta entrada de blog de Power BI. En el informe, puede ver los datos en tres niveles diferentes: vista de resumen, vista de nivel de consulta DAX y vista de nivel de consulta SQL.
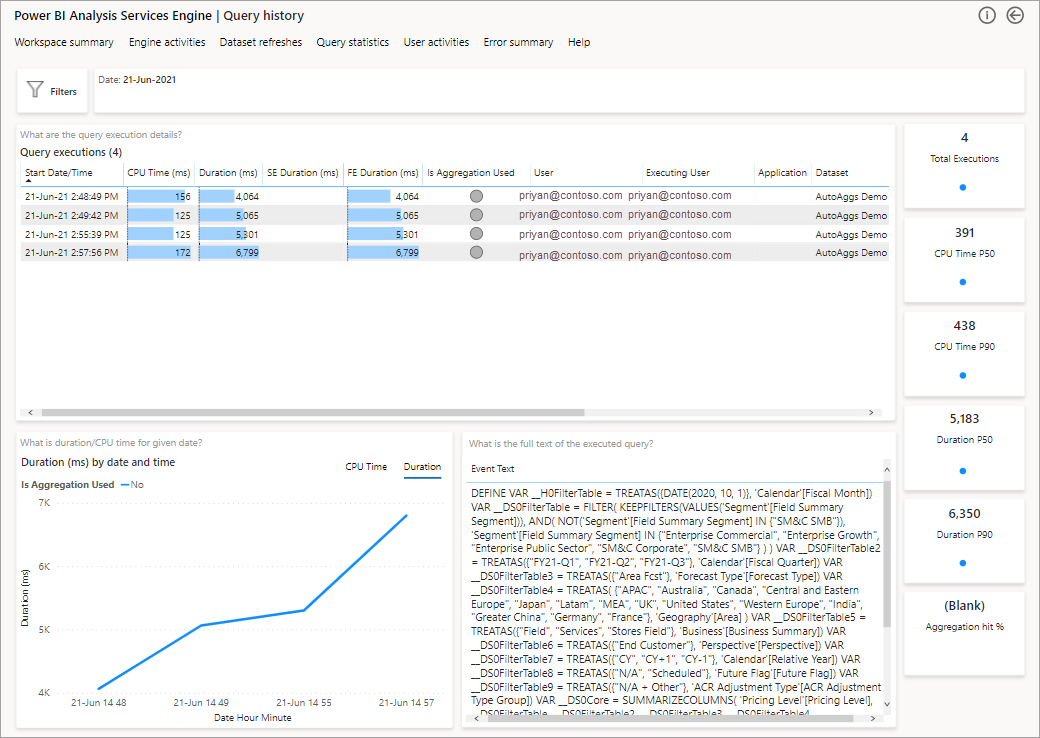
En la imagen siguiente se muestra la página de resumen de todas las consultas. Como puede ver, en el gráfico marcado se muestra el porcentaje de consultas totales que satisfacen las agregaciones frente a las que han tenido que usar el origen de datos.

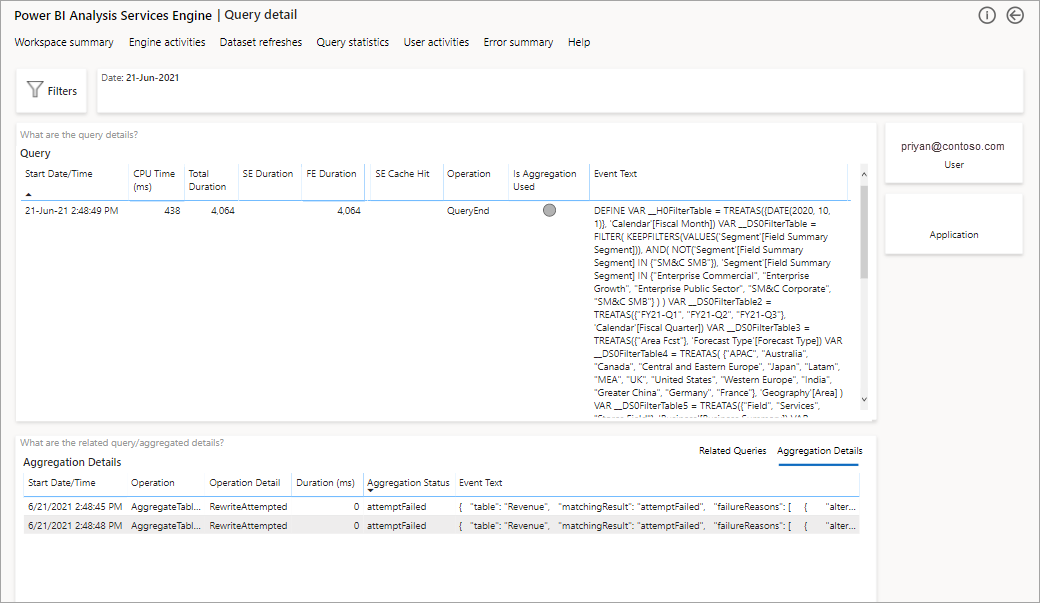
El paso siguiente para profundizar consiste en examinar el uso de las agregaciones en un nivel de consulta DAX. Haga clic con el botón derecho en una consulta DAX de la lista (parte inferior izquierda) >Obtener detalles>Historial de consultas.
Esto le proporcionará una lista de todas las consultas pertinentes. Explore en profundidad hasta el siguiente nivel para mostrar más detalles de agregación.
Administración del ciclo de vida de las aplicaciones
Desde el desarrollo hasta las pruebas y desde las pruebas hasta la producción, los modelos con agregaciones automáticas habilitadas tienen requisitos especiales para las soluciones de ALM.
Canalizaciones de implementación
Con canalizaciones de implementación, Power BI puede copiar los modelos con su configuración de modelo de la fase actual a la de destino. Pero las agregaciones automáticas se deben restablecer en la fase de destino, ya que la configuración no se transfiere de la fase actual a la de destino. También puede implementar contenido mediante programación, con las API REST de canalizaciones de implementación. Para obtener más información sobre este proceso, vea Automatización de la canalización de implementación mediante API y DevOps.
Soluciones de ALM personalizadas
Si usa una solución de ALM personalizada basada en puntos de conexión XMLA, tenga en cuenta que es posible que la solución pueda copiar tablas de agregaciones generadas por el sistema y creadas por el usuario como parte de los metadatos del modelo. Pero tendrá que habilitar manualmente las agregaciones automáticas después de cada paso de implementación en la fase de destino. Power BI conservará la configuración si sobrescribe un modelo existente.
Nota:
Si carga o vuelve a publicar un modelo como parte de un archivo de Power BI Desktop (.pbix), las tablas de agregación creadas por el sistema se pierden cuando Power BI reemplaza el modelo existente por todos sus metadatos y datos en el área de trabajo de destino.
Modificar un modelo
Después de modificar un modelo con agregaciones automáticas habilitadas mediante puntos de conexión XMLA, como al agregar o quitar tablas, Power BI conserva las agregaciones existentes que pueden ser necesarias o pertinentes, y quita las que ya no lo sean. El rendimiento de las consultas podría verse afectado hasta que se desencadene la siguiente fase de entrenamiento.
Elementos de metadatos
Los modelos con agregaciones automáticas habilitadas contienen tablas de agregaciones únicas generadas por el sistema. Las tablas de agregaciones no son visibles para los usuarios en las herramientas de creación de informes. Son visibles desde el punto de conexión XMLA mediante el uso de herramientas con Bibliotecas cliente de Analysis Services, versión 19.22.5 y posteriores. Al trabajar con modelos con agregaciones automáticas habilitadas, asegúrese de actualizar las herramientas de modelado y administración de datos a la versión más reciente de las bibliotecas cliente. Para SQL Server Management Studio (SSMS), actualice a la versión 18.9.2 o posterior. Las versiones anteriores de SSMS no pueden enumerar tablas ni generar scripts a partir de estos modelos.
Las tablas de agregaciones automáticas se identifican mediante una propiedad de tabla SystemManaged, que es nueva en el Modelo de objetos tabulares (TOM) en las bibliotecas cliente de Analysis Services, versión 19.22.5 y posteriores. El fragmento de código siguiente muestra la propiedad SystemManaged establecida en true para las tablas de agregaciones automáticas y en false para las tablas normales.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
La ejecución de este fragmento de código genera tablas de agregaciones automáticas incluidas actualmente en el modelo en una consola.
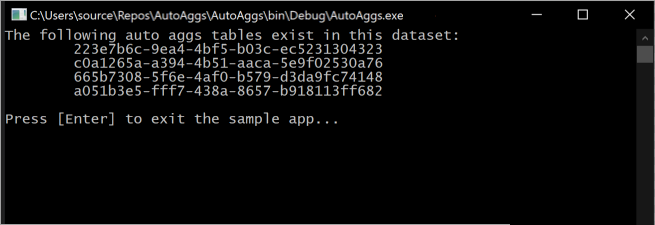
Tenga en cuenta que las tablas de agregaciones cambian constantemente a medida que las operaciones de entrenamiento determinan las agregaciones óptimas que se deben incluir en la caché de agregaciones en memoria.
Importante
Power BI administra completamente los objetos de tabla generados por el sistema de agregaciones automáticas. No elimine ni modifique personalmente estas tablas. Si lo hace, puede provocar la degradación del rendimiento.
Power BI mantiene la configuración del modelo fuera del modelo. La presencia de una tabla de agregaciones administradas por el sistema en un modelo no significa necesariamente que el modelo esté habilitado para el entrenamiento de las agregaciones automáticas. Dicho de otro modo, si crea un script a partir de una definición de modelo completa para un modelo con las agregaciones automáticas habilitadas y crea una copia del modelo (con otro nombre, área de trabajo o capacidad), el nuevo modelo no está habilitado para el entrenamiento de las agregaciones automáticas. Todavía tendrá que habilitar el entrenamiento de las agregaciones automáticas para el nuevo modelo en la configuración del modelo.
Consideraciones y limitaciones
Tenga en cuenta lo siguiente al usar agregaciones automáticas:
- Las agregaciones no admiten parámetros de consulta M dinámicos.
- Las consultas SQL generadas durante la fase de entrenamiento inicial pueden generar una carga significativa para el almacenamiento de datos. Si el entrenamiento sigue acabando incompleto y comprueba en el almacenamiento de datos que las consultas agotan el tiempo de espera, considere la posibilidad de escalar verticalmente el almacenamiento de datos de forma temporal para satisfacer la demanda de entrenamiento.
- Es posible que las agregaciones almacenadas en la caché de agregaciones en memoria no se calculen sobre los datos más recientes del origen de datos. A diferencia de DirectQuery puro, y más como las tablas de importación normales, hay una latencia entre las actualizaciones en el origen de datos y los datos de agregaciones almacenados en la caché de agregaciones en memoria. Aunque siempre habrá cierto grado de latencia, se puede mitigar mediante una programación de actualizaciones eficaz.
- Para optimizar aún más el rendimiento, establezca todas las tablas de dimensiones en Modo dual y deje las tablas de hechos en el modo DirectQuery.
- Las agregaciones automáticas no están disponibles con Power BI Pro, Azure Analysis Services ni SQL Server Analysis Services.
- Power BI no admite la descarga de modelos con agregaciones automáticas habilitadas. Si ha cargado o publicado un archivo de Power BI Desktop (.pbix) en Power BI y, después, ha habilitado las agregaciones automáticas, ya no podrá descargar el archivo PBIX. Asegúrese de mantener una copia del archivo PBIX en el entorno local.
- No se admiten agregaciones automáticas con tablas externas en Azure Synapse Analytics. Puede enumerar las tablas externas en Synapse mediante la consulta SQL siguiente:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables. - Las agregaciones automáticas solo están disponibles para modelos que usan metadatos mejorados. Si quiere habilitar las agregaciones automáticas para un modelo anterior, actualícelo primero a metadatos mejorados. Para obtener más información, vea Uso de metadatos de modelo mejorados.
- No habilite las agregaciones automáticas si el origen de datos de DirectQuery está configurado para el inicio de sesión único y usa vistas de datos dinámicas o controles de seguridad para limitar los datos a los que un usuario tiene permiso de acceso. Las agregaciones automáticas no son conscientes de estos controles de nivel de origen de datos, lo que hace imposible asegurarse de que se proporcionan datos correctos para cada usuario. El entrenamiento registra una advertencia en el historial de actualizaciones indicando que detectó un origen de datos configurado para el inicio de sesión único y omitió las tablas que usan ese origen de datos. Si es posible, deshabilite el inicio de sesión único para esos orígenes de datos con el fin de aprovechar al máximo el rendimiento de las consultas optimizadas que las agregaciones automáticas pueden proporcionar.
- No habilite las agregaciones automáticas si el modelo solo contiene tablas híbridas para evitar una sobrecarga de procesamiento innecesaria. Una tabla híbrida usa particiones de importación y una partición de DirectQuery. Un escenario habitual es la actualización incremental con datos en tiempo real donde una partición de DirectQuery captura las transacciones del origen de datos que tuvieron lugar después de la última actualización de los datos. Sin embargo, Power BI importa las agregaciones durante la actualización. Las agregaciones automáticas no pueden incluir las transacciones que se produjeron después de la última actualización de los datos. El entrenamiento registra entonces una advertencia en el historial de actualización indicando que detectó y omitió tablas híbridas.
- Las columnas calculadas no se tienen en cuenta para las agregaciones automáticas. Si usa una columna calculada en el modo DirectQuery, como mediante la función DAX
COMBINEVALUESpara crear una relación basada en varias columnas de dos tablas de DirectQuery, las consultas de informe correspondientes no llegarán a la caché de agregaciones en memoria. - Las agregaciones automáticas solo están disponibles en el servicio Power BI. Power BI Desktop no crea tablas de agregaciones generadas por el sistema.
- Si modifica los metadatos de un modelo con agregaciones automáticas habilitadas, el rendimiento de las consultas podría disminuir hasta que se desencadene el siguiente proceso de entrenamiento. Como procedimiento recomendado, debe quitar las agregaciones automáticas, realizar los cambios y, después, repetir el entrenamiento.
- No modifique ni elimine las tablas de agregaciones generadas por el sistema a menos que tenga deshabilitadas las agregaciones automáticas y vaya a limpiar el modelo. El sistema asume la responsabilidad de administrar estos objetos.
Comunidad
Power BI tiene una comunidad dinámica donde MVP, profesionales de BI y colegas comparten sus experiencias en grupos de debate, vídeos, blogs, entre otros. Cuando esté aprendiendo sobre las agregaciones automáticas, asegúrese de consultar estos recursos adicionales:
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de