Configurar y consumir un flujo de datos
Con los flujos de datos, puede unificar los datos de varios orígenes y preparar los datos unificados para el modelado. Cada vez que crea un flujo de datos, se le solicita que actualice los datos para el flujo de datos. Es necesario actualizar un flujo de datos para que se pueda consumir en un conjunto de datos en Power BI Desktop, o bien para que se pueda hacer referencia a él como una tabla vinculada o calculada.
Nota:
Los flujos de datos en el servicio Power BI podrían no estar disponibles para todos los clientes DoD del gobierno de Estados Unidos. Para obtener más información sobre qué características están disponibles y cuáles no, consulte Disponibilidad de características de Power BI para los clientes de la Administración Pública de Estados Unidos.
Configuración de un flujo de datos
Para configurar la actualización de un flujo de datos, seleccione el menú Más opciones (los puntos suspensivos) y elija Configuración.
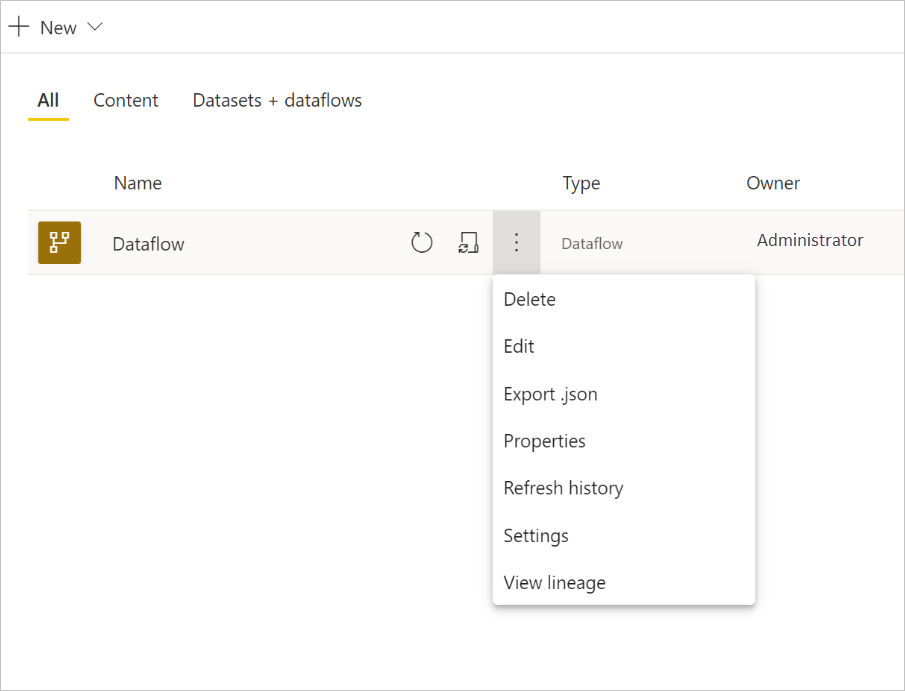
Las opciones de Configuración ofrecen diversas alternativas para el flujo de datos, como se describe en las secciones siguientes.

Tomar posesión: si usted no es el propietario del flujo de datos, muchas de estas opciones estarán deshabilitadas. Para tomar posesión del flujo de datos, seleccione Tomar control para encargarse de controlarlo. Se le pedirá que proporcione credenciales para asegurarse de que cuenta con el nivel de acceso necesario.
Conexión de puerta de enlace: en esta sección, puede elegir si el flujo de datos usa una puerta de enlace y seleccionar qué puerta de enlace se usa. Si has especificado la puerta de enlace como parte del flujo de datos de edición, al tomar posesión, es posible que tengas que actualizar las credenciales mediante la opción editar flujo de datos.
Credenciales del origen de datos: en esta sección, se eligen las credenciales que se usan y se puede cambiar la forma de autenticarse en el origen de datos.
Etiqueta de confidencialidad: aquí puede definir la confidencialidad de los datos del flujo de datos. Para obtener más información sobre las etiquetas de confidencialidad, vea Aplicación de etiquetas de confidencialidad en Power BI.
Actualización programada: aquí puede definir a qué horas del día se actualiza el flujo de datos seleccionado. Un flujo de datos se puede actualizar con la misma frecuencia que un modelo semántico.
Configuración mejorada del motor de proceso: aquí puede definir si el flujo de datos se almacena en el motor de proceso. El motor de proceso permite que los flujos de datos posteriores, que hacen referencia a este flujo de datos, realicen fusiones, combinaciones y otras transformaciones más rápido. También permite el uso de DirectQuery en el flujo de datos. Al seleccionar Activar, se garantiza que el flujo de datos se admita siempre en el modo DirectQuery, de modo que todas las referencias se benefician del motor. Al seleccionar Optimizado, el motor solo se usa si hay una referencia a este flujo de datos. Al seleccionar Desactivar, se deshabilita el motor de proceso y la función DirectQuery para este flujo de datos.
Aprobación: puede definir si el flujo de datos está certificado o promovido.
Nota
Los usuarios con una licencia Pro o Premium por usuario (PPU) pueden crear un flujo de datos en un área de trabajo Premium.
Precaución
Si se elimina un área de trabajo que contiene flujos de datos, también se eliminan todos los flujos de datos de esa área de trabajo. Incluso si es posible la recuperación del área de trabajo, no puede recuperar flujos de datos eliminados, ya sea directamente o a través del soporte técnico de Microsoft.
Actualización de un flujo de datos
Los flujos de datos actúan como bloques de creación que se colocan unos sobre otros. Supongamos que tiene un flujo de datos denominado Datos sin procesar y una tabla vinculada denominada Datos transformados que contiene una tabla vinculada a Datos sin procesar. Cuando se desencadena la actualización programada para el flujo llamado Datos sin procesar, se desencadenan todos los flujos de datos que hacen referencia a este una vez finalizada. Esta funcionalidad crea un efecto en cadena de actualizaciones, lo que le evita tener que programar flujos de datos manualmente. Hay algunos matices que deben tenerse en cuenta cuando se trabaja con actualizaciones de tablas vinculadas:
Una actualización desencadenará una tabla vinculada solo si existe en la misma área de trabajo.
Si se actualiza una tabla de origen o se cancela la actualización de la tabla de origen, no se podrá editar una tabla vinculada. Si alguno de los flujos de datos de una cadena de referencia no puede actualizarse, todos los flujos de datos se revertirán a los datos antiguos (las actualizaciones de flujos de datos son transaccionales dentro de un área de trabajo).
Únicamente se actualizan las tablas a las que se hace referencia cuando se desencadenan como consecuencia de la finalización de una actualización de origen. Para programar todas las tablas, debe establecer también una actualización programada en la tabla vinculada. Evite establecer una programación de la actualización en los flujos de datos vinculados para evitar una actualización doble.
Cancelar actualización Flujos de datos admiten la capacidad de cancelar una actualización, a diferencia de los modelos semánticos. Si una actualización se ejecuta durante mucho tiempo, puede seleccionar Más opciones (puntos suspensivos junto al flujo de datos) y, luego, elegir Cancelar actualización.
Actualización incremental (solo Premium): los flujos de datos también se pueden establecer para que se actualicen de manera incremental. Para ello, seleccione el flujo de datos que quiere configurar para la actualización incremental y, después, haga clic en el icono Actualización incremental.

Al establecer la actualización incremental, se agregan parámetros al flujo de datos para especificar el intervalo de fechas. Para obtener información detallada sobre cómo configurar la actualización incremental, consulte Uso de actualización incremental con flujos de datos.
Hay algunas circunstancias en las que no se debe establecer la actualización incremental:
Las tablas vinculadas no deben usar la actualización incremental si hacen referencia a un flujo de datos. Los flujos de datos no admiten el plegado de consultas (incluso si la tabla está habilitada para DirectQuery).
Los modelos semánticos que hacen referencia a flujos de datos no deben usar la actualización incremental. Las actualizaciones de los flujos de datos suelen optimizar el rendimiento, por lo que las actualizaciones incrementales no deberían ser necesarias. Si las actualizaciones tardan demasiado, considere la posibilidad de usar el motor de proceso o el modo DirectQuery.
Consumo de un flujo de datos
Un flujo de datos se puede consumir de las tres maneras siguientes:
Crear una tabla vinculada desde el flujo de datos para permitir que otro autor de flujo de datos use los datos.
Cree un modelo semántico desde el flujo de datos para permitir que un usuario emplee los datos para crear informes.
Crear una conexión desde herramientas externas que pueden leer el formato CDM (Common Data Model).
Consumo desde Power BI Desktop: para consumir un flujo de datos, abra Power BI Desktop y seleccione flujos de datos en el cuadro de diálogo Obtener datos.
Nota:
El conector de flujos de datos usa un conjunto de credenciales diferentes a las del usuario que ha iniciado sesión actualmente. Esto es así por diseño, para admitir usuarios de varios inquilinos.
Seleccione el flujo de datos y las tablas a las que quiere conectarse.
Nota
Puede conectarse a cualquier flujo de datos o tabla, independientemente del área de trabajo en la que resida y de si se definió en un área de trabajo Premium o no Premium.
Si DirectQuery está disponible, se le pedirá que elija si quiere conectarse a las tablas mediante DirectQuery o Importar.
En el modo DirectQuery, puede interrogar rápidamente modelos semánticos a gran escala de forma local. Sin embargo, no se pueden realizar más transformaciones.
El uso de Import incluye los datos en Power BI y requiere que el modelo semántico se actualice independientemente del flujo de datos.
Contenido relacionado
En los artículos siguientes encontrará más información sobre los flujos de datos y Power BI:
- Introducción a los flujos de datos y la preparación de datos de autoservicio
- Creación de un flujo de datos
- Configuración del almacenamiento de flujo de datos para usar Azure Data Lake Gen 2
- Características prémium de flujos de datos
- IA con flujos de datos
- Consideraciones y limitaciones de flujos de datos
- Procedimientos recomendados para flujos de datos
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de