Reconciliación de DNS de Active Directory y Kubernetes en implementaciones de clústeres de macrodatos
En este artículo se describen algunos de los desafíos y las soluciones para admitir la integración de Active Directory al implementar Clústeres de macrodatos.
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
Información general
Cuando no se implementa el clúster de macrodatos con la integración de Active Directory, se confía en el servicio CoreDNS de Kubernetes para las resoluciones DNS internas. Kubernetes usa un dominio interno como <namespace>.svc.cluster.local. Crea registros A (búsqueda directa) y PTR (búsqueda inversa) en el servidor DNS con nombres en este dominio.
Pero, cuando se habilita el modo de Active Directory, un nuevo dominio entra en escena con su propio conjunto de servidores DNS. Durante la resolución de nombres interna, esto puede dar lugar a confusión sobre qué conjunto de servidores DNS se va a usar para las búsquedas directas e inversas.
Desafíos
- Cuando se implementan pods de Kubernetes nuevos, deben agregarse las entradas de DNS en ambos conjuntos de servidores DNS. Kubernetes se encarga de la grabación de las entradas en su CoreDNS, pero el flujo de trabajo de implementación del clúster de macrodatos es el responsable de agregar las entradas necesarias en los servidores DNS del controlador de dominio de Active Directory. Del mismo modo, cuando se elimina un clúster de macrodatos, el flujo de trabajo debe asegurarse de que estas entradas se quitan.
- Los servidores DNS de Active Directory son externos al clúster de Kubernetes. Pero el clúster de macrodatos tiene su propio espacio de direcciones IP dentro de Kubernetes y no puede crear registros para este espacio IP en un servidor DNS ubicado externamente, ya que este espacio IP no es visible fuera de los límites del clúster.
- Cuando se producen eventos de conmutación por error en el clúster de Kubernetes, también se deben actualizar los registros de los servidores DNS de AD.
- Además de los nombres del pod, los nombres del servicio de Kubernetes también deben ser direccionables a través de las búsquedas de nombres de dominio de AD. Esto crea un desafío adicional en el DNS de Active Directory porque un nombre de servicio puede estar asignado a varias direcciones IP del pod.
- La propagación de actualizaciones de registros y los retrasos de replicación en los servidores DNS de Active Directory de la organización pueden ser significativos e ir más allá del control de los flujos de trabajo de administración del clúster de macrodatos. Esto puede afectar a la funcionalidad del clúster de macrodatos inmediatamente después de la implementación y la conmutación por error. Por el contrario, CoreDNS de Kubernetes es más rápido y eficaz debido a su localidad.
Solución
Para solucionar los problemas mencionados anteriormente, la solución implementada en el clúster de macrodatos implica un nuevo servicio CoreDNS interno que se administra dentro del espacio de nombres del clúster de macrodatos. Este es el único servicio DNS al que accederán los pods del espacio de nombres del clúster de macrodatos para las resoluciones de nombres. El nuevo servicio CoreDNS oculta la complejidad de los dominios múltiples.
Por ejemplo, en el diagrama siguiente, los pods usan el servidor de CoreDNS del clúster de macrodatos para la resolución de nombres. Los pods no interactúan directamente con el servidor de CoreDNS de Kubernetes o el servidor DNS de AD.
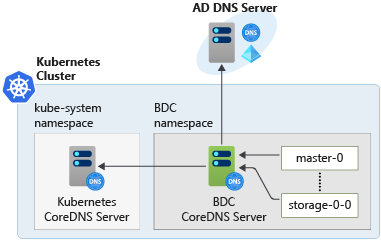
Estos son algunos de los detalles de implementación que aclaran cómo funciona este diseño en el clúster de macrodatos:
Administración centralizada de varios dominios
La complejidad de lo que sucede en las búsquedas de nombres permanece oculta detrás del servicio DNS interno de manera centralizada. Esto evita que la carga de la administración de varios dominios recaiga en pods individuales y simplifica el diseño.
Sin registros para pods internos en servidores DNS externos
Como resultado de este principio de diseño, el clúster de macrodatos no tendrá que crear y administrar registros A y PTR para pods en el espacio de IP de Kubernetes en servidores DNS externos.
Sin duplicación de registros
Registros DNS internos en varios lugares. El único almacenamiento de estos registros es CoreDNS de Kubernetes. El CoreDNS interno de BDC realizará una reescritura computacional y un reenvío de las consultas de DNS a CoreDNS de Kubernetes.
Reescritura computacional
Dado que el clúster de macrodatos no almacena ningún registro, no es responsable de traducir las consultas de búsqueda directa entrantes con nombres que tienen el dominio de AD a nombres con el dominio de Kubernetes y reenviar esta consulta a CoreDNS de Kubernetes.
Por ejemplo, una consulta entrante para compute-0-0.contoso.local se volvería a escribir como compute-0-0.compute-0-svc.contoso.svc.cluster.local y esta solicitud se reenviaría a CoreDNS de Kubernetes.
En el caso de las búsquedas inversas, la solicitud se reenvía con direcciones IP internas cuando se envían a CoreDNS de Kubernetes, y la respuesta se vuelve a escribir desde allí al nombre de dominio de AD antes de responder al cliente.
Simplicidad en las configuraciones del pod
Dado que solo se hace referencia al CoreDNS del clúster de macrodatos interno en /etc/resolv.conf de todos los pods del clúster de macrodatos, se simplifica la vista de red de los pods. En su lugar, la complejidad se ocultará en el CoreDNS interno.
Dirección IP estática y confiable para el servicio DNS
El servicio CoreDNS que implementa el clúster de macrodatos tendrá una dirección IP interna estática registrada a la que se puede acceder desde todos los pods. Esto garantizará que no será necesario actualizar los valores de /etc/resolv.conf.
Kubernetes retiene la administración del equilibrio de carga del servicio
Cuando se producen búsquedas para servicios en lugar de pods individuales, seguirán yendo a CoreDNS de Kubernetes, por lo que el clúster de macrodatos no es el responsable de implementar el equilibrio de carga especialmente para el dominio de AD.
Por ejemplo, si se trata de una solicitud de búsqueda directa para compute-0-svc.contoso.local, se volverá a escribir como compute-0-svc.contoso.svc.cluster.local. Esta solicitud se reenviará a CoreDNS de Kubernetes y el equilibrio de carga se producirá allí. Una respuesta será una dirección IP para una de las distintas instancias del grupo de proceso (réplicas de pod).
Escalabilidad
Dado que el clúster de macrodatos no almacena ningún registro, el CoreDNS del clúster de macrodatos interno se puede escalar sin la retención de estado y la replicación de registros en varias réplicas. Si los registros DNS se van a almacenar en el clúster de macrodatos, la replicación del estado en todos los pods también tendrá que encargarse de él.
Las entradas de servicio visibles externamente permanecen en el DNS de AD
En el caso de los puntos de conexión de servicio que deben ser accesibles para los clientes fuera del clúster de Kubernetes, se crearán entradas DNS en el servidor DNS de AD a medida que se implementa el clúster de macrodatos. El usuario escribirá los nombres DNS desde los que se va a registrar a través de los perfiles de configuración de implementación.
Desaprovisionamiento automático
Una vez eliminado el clúster de macrodatos, no hay ningún trabajo dinámico adicional para eliminar las entradas de DNS cuando se está desaprovisionando el clúster. Las únicas entradas del DNS de Active Directory remoto que se deben limpiar son las de los servicios externos y son estáticas en número. Las entradas de DNS internas se quitarán automáticamente con el clúster.
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de