Implementación del nodo de nombre de HDFS y de los servicios de Spark compartidos en una configuración de alta disponibilidad
Se aplica a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
Además de implementar la instancia maestra de SQL Server en una configuración de alta disponibilidad usando grupos de disponibilidad, se pueden implementar otros servicios críticos en el clúster de macrodatos para garantizar un mayor nivel de confiabilidad. Puede configurar HDFS name node y los servicios de Spark compartidos agrupados en sparkhead con una réplica adicional. En este caso, Zookeeper también se implementa en el clúster de macrodatos en el servidor como coordinador de clústeres y almacén de metadatos de los siguientes servicios:
- Nodo de nombre de HDFS
- Livy Resource Manager y Yarn Resource Manager
El historial de Spark, el historial de trabajos y el servicio de metadatos de Hive son servicios sin estado. Zookeeper no interviene para garantizar el estado de servicio de estos componentes.
La implementación de varias réplicas relativas a estos servicios da como resultado una escalabilidad y confiabilidad mejores, así como un equilibrio de carga de las cargas de trabajo entre las réplicas disponibles.
Nota:
Los siguientes servicios se implementan como contenedores en el pod sparkhead:
- Livy
- Yarn Resource Manager
- Historial de Spark
- Historial de trabajos
- Servicio de metadatos de Hive
En la siguiente imagen se muestra una implementación de HA de Spark en un clúster de macrodatos de SQL Server:
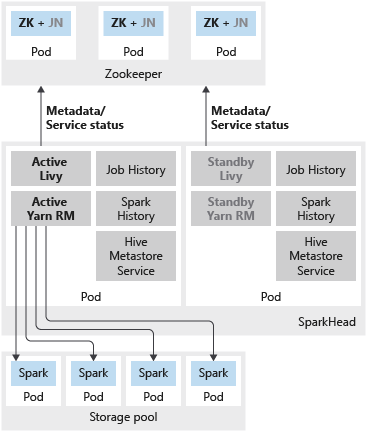
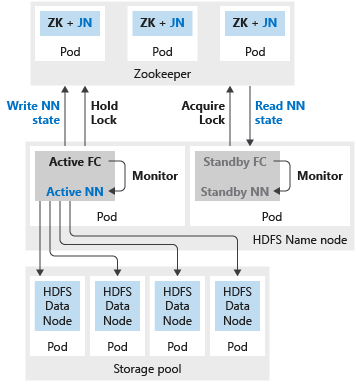
En la siguiente imagen se muestra una implementación de HA de HDFS en un clúster de macrodatos de SQL Server:
Implementar
Si el nodo de nombre o el encabezado de Spark están configurados con dos réplicas, también debe configurar el recurso de Zookeeper con tres réplicas. En una configuración de alta disponibilidad del nodo de nombre de HDFS, dos pod hospedan las dos réplicas. Los pods son nmnode-0 y nmnode-1. Esta configuración es activa-pasiva: solo uno de los nodos de nombre está activo, mientras que el otro está en espera y se activa como resultado de un evento de conmutación por error.
Puede usar los perfiles de configuración integrados aks-dev-test-ha o kubeadm-prod para empezar a personalizar la implementación del clúster de macrodatos. Estos perfiles incluyen la configuración necesaria relativa a los recursos que permiten configurar alta disponibilidad extra. Por ejemplo, aquí se muestra una sección del archivo de configuración bdc.json que es pertinente para implementar el nodo de nombre de HDFS, Zookeeper y recursos de Spark compartidos (sparkhead) con alta disponibilidad.
{
...
"nmnode-0": {
"spec": {
"replicas": 2
}
},
"sparkhead": {
"spec": {
"replicas": 2
}
},
"zookeeper": {
"spec": {
"replicas": 3
}
},
...
}
Como procedimiento recomendado, en una implementación de producción también hay que establecer la replicación de bloque de HDFS en 3. Esta configuración ya está especificada en los perfiles aks-dev-test-ha y kubeadm-prod. Vea la sección siguiente del archivo de configuración bdc.json:
{
...
"hdfs": {
"resources": [
"nmnode-0",
"zookeeper",
"storage-0",
"sparkhead"
],
"settings": {
"hdfs-site.dfs.replication": "3"
}
},
...
}
Limitaciones conocidas
Estos son los problemas conocidos y las limitaciones concernientes a la configuración de alta disponibilidad de los servicios de Hadoop en clústeres de macrodatos de SQL Server:
- Todas las configuraciones se deben especificar en el momento de la implementación de clústeres de macrodatos. En la versión SQL Server 2019 CU1, la configuración de alta disponibilidad no se puede habilitar después de la implementación.
Pasos siguientes
- Para más información sobre cómo usar archivos de configuración en implementaciones de clústeres de macrodatos, vea Cómo implementar Clústeres de macrodatos de SQL Server en Kubernetes.
- Para más información sobre las opciones de alta disponibilidad de instancias maestras de SQL Server en clústeres de macrodatos, vea Implementación de una instancia maestra de SQL Server con alta disponibilidad.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de