Tamaño de tabla y fila de las tablas con optimización para memoria
Se aplica a:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Antes de SQL Server 2016 (13.x), el tamaño de los datos de una fila de una tabla optimizada para memoria no podía superar los 8060 bytes. Pero a partir de SQL Server 2016 (13.x) y en Azure SQL Database es posible crear una tabla optimizada para memoria con varias columnas de gran tamaño [por ejemplo, varias columnas varbinary(8000)] y columnas LOB [es decir, varbinary(max), varchar(max) y nvarchar(max)] y realizar operaciones en ellas con módulos Transact-SQL (T-SQL) compilados de forma nativa y tipos de tabla.
Las columnas que no quepan en el límite de tamaño de fila de 8060 bytes se colocan de forma no consecutiva, en una tabla interna aparte. Cada columna no consecutiva tiene una tabla interna correspondiente que, a su vez, tiene un único índice no agrupado. Para obtener detalles sobre estas tablas internas usadas para columnas no consecutivas, vea sys.memory_optimized_tables_internal_attributes.
Hay determinados escenarios donde resulta útil calcular el tamaño de la fila y la tabla:
¿Cuánta memoria usa una tabla?
La cantidad de memoria utilizada por la tabla no se puede calcular con precisión. Muchos factores afectan a la cantidad de memoria utilizada. Factores como la asignación de memoria basada en páginas, localidad, almacenamiento en caché y relleno. Además, varias versiones de fila que tengan transacciones activas asociadas o que estén esperando para la recolección de elementos no utilizados.
El tamaño mínimo necesario para los datos y los índices de la tabla viene proporcionado por el cálculo de
<table size>, descrito a continuación en este artículo.El cálculo del uso de memoria es, en el mejor caso, una aproximación y es preferible incluir el planeamiento de la capacidad en los planes de implementación.
El tamaño de los datos de una fila y si cabe en la limitación de tamaño de fila de 8060 bytes. Para responder a estas preguntas, use el cálculo de
<row body size>, descrito más adelante en este artículo.
Una tabla optimizada para memoria consta de una colección de filas e índices que contienen punteros a las filas. La ilustración siguiente muestra una tabla con índices y filas, que a su vez tienen encabezados de fila y cuerpos:
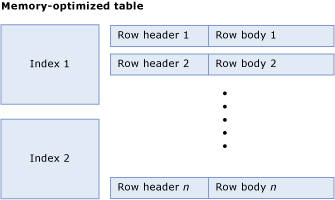
Cálculo del tamaño de una tabla
El tamaño en memoria de una tabla, en bytes, se calcula de la forma siguiente:
<table size> = <size of index 1> + ... + <size of index n> + (<row size> * <row count>)
El tamaño de un índice hash se fija en el momento de creación de la tabla y depende del número real de cubos. El valor bucket_count especificado con la especificación de índice se redondea a la potencia más cercana de 2 para obtener el número real de cubos. Por ejemplo, si el bucket_count especificado es 100 000, el número real de cubos para el índice es 131 072.
<hash index size> = 8 * <actual bucket count>
El tamaño de un índice no agrupado está en el orden de <row count> * <index key size>.
El tamaño de fila se calcula agregando el encabezado y el cuerpo:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indexes>
Cálculo del tamaño del cuerpo de la fila
Las filas de una tabla optimizada para memoria tienen los siguientes componentes:
El encabezado de fila contiene la marca de tiempo necesaria para implementar las versiones de fila. El encabezado de fila también contiene el puntero de índice para implementar el encadenamiento de filas en cubos de hash (descritos anteriormente).
El cuerpo de la fila contiene los datos de columna reales, lo que incluye cierta información auxiliar como la matriz NULL para las columnas que aceptan valores NULL y la matriz de desplazamiento para los tipos de datos de longitud variable.
La ilustración siguiente muestra la estructura de la fila de una tabla que tenga dos índices:

Las marcas de tiempo de inicio y fin indican el periodo en el que una determinada versión de fila es válida. Las transacciones que se inician en este intervalo pueden ver esta versión de fila. Para obtener más detalles, vea Transacciones con tablas optimizadas para memoria.
Los punteros de índice señalan a la siguiente fila de la cadena que pertenece al cubo de hash. La ilustración siguiente muestra la estructura de una tabla con dos columnas (name, city) y dos índices, uno en el nombre de columna y en otro en la ciudad de la columna.
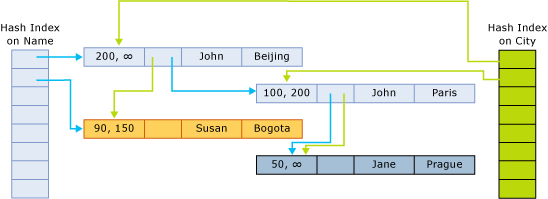
En esta ilustración, se aplica un algoritmo hash a los nombres John y Jane para el primer cubo. Se aplica el algoritmo hash a Susan para el segundo cubo. Se aplica el algoritmo hash a las ciudades Beijing y Bogota para el primer cubo. Se aplica el algoritmo hash a Paris y Prague para el segundo cubo.
Por tanto, las cadenas para el índice hash en el nombre son las siguientes:
- Primer cubo:
(John, Beijing);(John, Paris);(Jane, Prague) - Segundo cubo:
(Susan, Bogota)
Las cadenas para el índice de la ciudad son las siguientes:
- Primer cubo:
(John, Beijing),(Susan, Bogota) - Segundo cubo:
(John, Paris),(Jane, Prague)
Una marca de tiempo de extremo ∞ (infinito) indica que esta es la versión no válida de la fila. La fila no se ha actualizado ni se ha eliminado desde que esta versión de fila se escribió.
Para un tiempo mayor que 200, la tabla contiene las filas siguientes:
| Nombre | Ciudad |
|---|---|
| John | Beijing |
| Julia | Praga |
Sin embargo, cualquier transacción activa con el tiempo de inicio 100 verá la versión siguiente de la tabla:
| Nombre | Ciudad |
|---|---|
| John | París |
| Julia | Praga |
| Susan | Bogotá |
El recálculo de <row body size> se describe en la siguiente tabla.
Hay dos cálculos diferentes para el tamaño del cuerpo de la fila: el tamaño calculado y el tamaño real:
El tamaño calculado, indicado mediante el tamaño del cuerpo calculado de la fila, se utiliza para determinar si la limitación de tamaño de fila de 8.060 bytes se supera.
El tamaño real, que se denomina tamaño del texto real de la fila, es el tamaño de almacenamiento real del cuerpo de la fila en memoria y en los archivos de puntos de comprobación.
Tanto tamaño del cuerpo calculado de la fila y tamaño del texto real de la fila se calculan de la misma forma. La única diferencia es el cálculo de tamaño de las columnas (n)varchar(i) y varbinary(i), como se refleja en la parte inferior de la tabla siguiente. El tamaño del cuerpo calculado de la fila utiliza el tamaño i declarado como tamaño de columna, mientras que el tamaño del cuerpo real de la fila utiliza el tamaño real de los datos.
En la tabla siguiente se describe el cálculo del tamaño del cuerpo de fila, dado como <actual row body size> = SUM(<size of shallow types>) + 2 + 2 * <number of deep type columns>.
| Sección | Size | Comentarios |
|---|---|---|
| Columnas de tipo superficial | SUM(<size of shallow types>). El tamaño en bytes de los tipos individuales es el siguiente:bit: 1tinyint: 1smallint: 2int: 4real: 4smalldatetime: 4smallmoney: 4bigint: 8datetime: 8datetime2: 8float: 8money: 8numeric (precisión <= 18): 8time: 8numeric(precisión > 18): 16uniqueidentifier: 16 |
|
| Relleno superficial de la columna | Los valores posibles son:1, si hay columnas de tipo profundo y el tamaño total de datos de las columnas superficiales es un número impar.de lo contrario, 0 |
Los tipos profundos son (var)binary y (n)(var)char. |
| Matriz de desplazamiento para las columnas de tipo profundo | Los valores posibles son:0 si no hay columnas de tipo profundode lo contrario, 2 + 2 * <number of deep type columns> |
Los tipos profundos son (var)binary y (n)(var)char. |
| Matriz NULL | <number of nullable columns> / 8 se redondea a bytes completos. |
La matriz tiene 1 bit por cada columna que admite valores NULL. Se redondea a bytes completos. |
| Relleno de matriz NULL | Los valores posibles son:1, si hay columnas de tipo profundo y el tamaño de la matriz NULL es un número de bytes impar.de lo contrario, 0 |
Los tipos profundos son (var)binary y (n)(var)char. |
| Relleno | Si no hay columnas de tipo profundo: 0Si hay columnas de tipo profundo, se agregan los bytes de relleno 0-7, según la alineación mayor requerida por una columna superficial. Cada columna superficial requiere una alineación igual a su tamaño según se documentó anteriormente, salvo en que las columnas GUID necesitan la alineación de 1 byte (no 16) y las columnas numéricas necesitan siempre la alineación de 8 bytes (nunca 16). Se usa el requisito de alineación más grande entre todas las columnas poco profundas. Se agregan los bytes 0 a 7 de relleno de forma que el tamaño total (sin las columnas de tipo profundo) sea un múltiplo de la alineación requerida. |
Los tipos profundos son (var)binary y (n)(var)char. |
| Columnas de tipo profundo de longitud fija | SUM(<size of fixed length deep type columns>)El tamaño de cada columna es el siguiente: i para char(i) y binary(i).2 * i para nchar(i) |
Las columnas de tipo profundo de longitud fija son de tipo char(i), nchar(i) o binary(i). |
| Columnas de tipo profundo de longitud variable tamaño calculado | SUM(<computed size of variable length deep type columns>)El tamaño calculado de cada columna es el siguiente: i para varchar(i) y varbinary(i)2 * i para nvarchar(i) |
Esta fila solo se aplica al tamaño del texto calculado de la fila. Las columnas de tipo profundo de longitud variable son de tipo varchar(i), nvarchar(i) o varbinary(i). El tamaño calculado se determina mediante la longitud máxima ( i) de la columna. |
| Columnas de tipo profundo de longitud variable tamaño real | SUM(<actual size of variable length deep type columns>)El tamaño real de cada columna es el siguiente: n, donde n es el número de caracteres almacenados en la columna, para varchar(i).2 * n, donde n es el número de caracteres almacenados en la columna, para nvarchar(i).n, donde n es el número de bytes almacenados en la columna, para varbinary(i). |
Esta fila solo se aplica al tamaño del texto real de la fila. El tamaño real se determina con los datos almacenados en las columnas de la fila. |
Ejemplo: Cálculo del tamaño de fila y tabla
Para los índices hash, el número de cubos real se redondea a la potencia más cercana de 2. Por ejemplo, si el valor bucket_count especificado es 100 000, el número real de cubos para el índice es 131 072.
Considere una tabla Orders con la definición siguiente:
CREATE TABLE dbo.Orders (
OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED,
CustomerID INT NOT NULL INDEX IX_CustomerID HASH WITH (BUCKET_COUNT = 10000),
OrderDate DATETIME NOT NULL,
OrderDescription NVARCHAR(1000)
)
WITH (MEMORY_OPTIMIZED = ON);
GO
Esta tabla tiene un índice hash y un índice no clúster (la clave principal). También tiene tres columnas de longitud fija y una columna de longitud variable, y una de las columnas admite valores NULL (OrderDescription). Imaginemos que la tabla Orders tiene 8379 filas y la longitud promedio de los valores de la columna OrderDescription es de 78 caracteres.
Para determinar el tamaño de la tabla, primero determine el tamaño de los índices. El bucket_count para ambos índices se especifica como 10000. Se redondea a la potencia más cercana de 2: 16384. Por consiguiente, el tamaño total de los índices de la tabla Orders es:
8 * 16384 = 131072 bytes
Lo que permanece en el tamaño de los datos de la tabla, que es:
<row size> * <row count> = <row size> * 8379
(La tabla de ejemplo tiene 8379 filas.) Ahora, tenemos:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indices> = 24 + 8 * 1 = 32 bytes
A continuación, vamos a calcular <actual row body size>:
Columnas de tipo superficial:
SUM(<size of shallow types>) = 4 <int> + 4 <int> + 8 <datetime> = 16El relleno superficial de la columna es 0, ya que el tamaño total de la columna es uniforme.
Matriz de desplazamiento para las columnas de tipo profundo:
2 + 2 * <number of deep type columns> = 2 + 2 * 1 = 4NULLmatriz = 1Relleno
NULLde matriz = 1, ya que el tamaño de la matrizNULLes impar y hay una columna de tipo profundo.Relleno
- 8 es el requisito mayor de alineación
- El tamaño es hasta ahora 16 + 0 + 4 + 1 + 1 = 22
- El múltiplo más cercano de 8 es 24
- El relleno total es 24 - 22 = 2 bytes
No hay columnas de tipo profundo de longitud fija (columnas de tipo profundo de longitud fija: 0).
El tamaño real de la columna de tipo profundo es 2 * 78 = 156. La columna de tipo profundo único
OrderDescriptiontiene el tiponvarchar.
<actual row body size> = 24 + 156 = 180 bytes
Para completar el cálculo:
<row size> = 32 + 180 = 212 bytes
<table size> = 8 * 16384 + 212 * 8379 = 131072 + 1776348 = 1907420
El tamaño total de la tabla en memoria es de aproximadamente 2 megabytes. Esto no tiene en cuenta la sobrecarga potencial provocada por la asignación de memoria y las versiones de fila necesarias para las transacciones que tienen acceso a esta tabla.
La memoria real asignada a esta tabla y usada por ella y sus índices se pueden obtener con la consulta siguiente:
SELECT * FROM sys.dm_db_xtp_table_memory_stats
WHERE object_id = object_id('dbo.Orders');
Limitaciones de las columnas no consecutivas
A continuación se muestran varias limitaciones y advertencias relacionadas con el uso de columnas no consecutivas en una tabla optimizada para memoria:
- Si hay un índice de almacén de columnas en una tabla optimizada para memoria, todas las columnas deben ajustarse de forma consecutiva.
- Todas las columnas de clave de índice se deben almacenar de forma consecutiva. Si una columna de clave de índice no se ajusta de forma consecutiva, se produce un error al agregar el índice.
- Advertencias sobre la modificación de una tabla optimizada para memoria con columnas no consecutivas.
- En el caso de los LOB, la limitación de tamaño es igual a la de las tablas basadas en disco (límite de 2 GB sobre los valores de LOB).
- Para obtener un rendimiento óptimo, se recomienda que la mayoría de las columnas se ajusten a 8060 bytes.
- Los datos fuera de fila pueden provocar un uso excesivo de memoria o disco.
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de