DBCC SHOW_STATISTICS (Transact-SQL)
Se aplica a:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() Punto de conexión de análisis SQL en Microsoft Fabric
Punto de conexión de análisis SQL en Microsoft Fabric![]() Almacenamiento en Microsoft Fabric
Almacenamiento en Microsoft Fabric
Muestra las estadísticas de optimización de consulta actuales de una tabla o vista indizada. El optimizador de consultas usa las estadísticas para estimar la cardinalidad o el número de filas del resultado de la consulta, lo que permite que el optimizador de consultas cree un plan de consultas de alta calidad. Por ejemplo, el optimizador de consultas podría utilizar las estimaciones de cardinalidad para elegir el operador index seek en lugar del operador index scan en el plan de consulta, lo que mejoraría el rendimiento de las consultas al evitar el examen de índices con una gran cantidad de recursos.
El optimizador de consultas almacena las estadísticas de una tabla o vista indizada en un objeto de estadísticas. En una tabla, el objeto de estadísticas se crea en un índice o en una lista de columnas de la tabla. El objeto de estadísticas incluye un encabezado con metadatos sobre las estadísticas, un histograma con la distribución de valores de la primera columna de clave del objeto de estadísticas y un vector de la densidad para medir la correlación entre las columnas. El Motor de base de datos puede calcular las estimaciones de cardinalidad con cualquiera de los datos del objeto de estadísticas. Para obtener más información, vea Estadísticas y Estimación de cardinalidad (SQL Server).
DBCC SHOW_STATISTICS muestra el encabezado, el histograma y el vector de densidad en función de los datos almacenados en el objeto de estadísticas. La sintaxis le permite especificar una tabla o vista indizada junto con un nombre del índice de destino, un nombre de las estadísticas o un nombre de columna.
Actualizaciones importantes en versiones anteriores de SQL Server:
A partir de SQL Server 2012 (11.x) Service Pack 1, la vista de administración dinámica sys.dm_db_stats_properties está disponible para recuperar mediante programación la información de encabezado incluida en el objeto de estadísticas para las estadísticas no incrementales.
A partir de SQL Server 2014 (12.x) Service Pack 2 y SQL Server 2012 (11.x) Service Pack 1, la vista de administración dinámica sys.dm_db_incremental_stats_properties está disponible para recuperar mediante programación la información de encabezado incluida en el objeto de estadísticas para las estadísticas incrementales.
A partir de SQL Server 2016 (13.x) Service Pack 1 CU 2, la vista de administración dinámica sys.dm_db_stats_histogram está disponible para recuperar mediante programación la información del histograma incluida en el objeto de estadísticas.
-
El grupo de SQL sin servidor no admite esta sintaxis en Azure Synapse Analytics.
Para más información sobre las estadísticas de Microsoft Fabric, consulte Estadísticas.
![]() Convenciones de sintaxis de Transact-SQL
Convenciones de sintaxis de Transact-SQL
Sintaxis
Sintaxis de SQL Server y Azure SQL Database:
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , ...n ] ]
< option > ::=
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
[ ; ]
Sintaxis de Azure Synapse Analytics, Analytics Platform System (PDW) y Microsoft Fabric:
DBCC SHOW_STATISTICS ( table_name , target )
[ WITH { STAT_HEADER | DENSITY_VECTOR | HISTOGRAM } [ , ...n ] ]
[ ; ]
Nota:
Para ver la sintaxis de Transact-SQL para SQL Server 2014 (12.x) y versiones anteriores, consulta la Documentación de versiones anteriores.
Argumentos
table_or_indexed_view_name
Nombre de la tabla o de la vista indizada cuya información de estadísticas se va a presentar.
table_name
Nombre de la tabla que contiene las estadísticas que mostrar. La tabla no puede ser una tabla externa.
Destino
Nombre del índice, estadística o columna cuya información de estadísticas se va a presentar. target se incluye entre paréntesis, entre comillas simples, entre comillas dobles o sin comillas.
- Si target es el nombre de un índice o estadística existentes en una tabla o vista indizada, se devuelve la información de estadísticas acerca de este destino.
- Si target es el nombre de una columna existente y dicha columna contiene un objeto de estadística creado automáticamente, se devuelve información sobre dicha estadística.
Si una estadística creada automáticamente no existe para el destino de una columna, se devuelve el mensaje de error 2767.
En Azure Synapse Analytics and Analytics Platform System (PDW), el destino no puede ser un nombre de columna.
En el almacenamiento de Microsoft Fabric, el destino puede ser el nombre de las estadísticas de histograma de una sola columna o una columna. Si se usa un nombre de columna para el destino, este comando devuelve información de distribución solo sobre la estadística de histograma generada automáticamente. Para ver la información sobre una estadística de histograma creada manualmente, especifique el nombre de las estadísticas como destino.
NO_INFOMSGS
Suprime todos los mensajes informativos con niveles de gravedad entre 0 y 10.
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM [ , n ]
La especificación de una o varias de estas opciones limita los conjuntos de resultados devueltos por la instrucción a la opción u opciones especificadas. Si no se especifican opciones, se devuelve información de todas las estadísticas.
STATS_STREAM solo se identifica con fines informativos. No compatible. La compatibilidad con versiones posteriores no está garantizada.
Conjunto de resultados
En la tabla siguiente se describen las columnas devueltas en el conjunto de resultados si se especifica STAT_HEADER.
| Nombre de la columna | Descripción |
|---|---|
| Nombre | Nombre del objeto de estadísticas. |
| Actualizado | Fecha y hora de la última actualización de las estadísticas. La función STATS_DATE constituye otro modo de recuperar esta información. Para más información, vea la sección Comentarios en esta página. |
| Filas | Número total de filas que tenía la tabla o vista indizada la última vez que se actualizaron las estadísticas. Si las estadísticas se filtran o corresponden a un índice filtrado, el número de filas puede ser inferior al número de filas de la tabla. Para más información, consulte Estadísticas. |
| Rows Sampled | Número total de filas muestreadas para cálculos de estadísticas. Si Rows Sampled < Rows, el histograma y los resultados de la densidad que se muestren serán estimaciones extraídas de las filas muestreadas. |
| Pasos | Número de pasos del histograma. Cada paso abarca un intervalo de valores de columna seguido de un valor de columna límite superior. Los pasos del histograma se definen en la primera columna de clave de las estadísticas. El número máximo de pasos es 200. |
| Densidad | Se calcula como 1 / valores distintos en todos los valores de la primera columna de clave del objeto de estadísticas, excepto en los valores límite del histograma. El optimizador de consultas no usa este valor de densidad y solo se muestra por motivos de compatibilidad con versiones anteriores a SQL Server 2008 (10.0.x). |
| Promedio de longitud de clave | Número promedio de bytes por cada uno de los valores de las columnas de clave del objeto de estadísticas. |
| String Index | Sí indica que el objeto de estadísticas contiene estadísticas de resumen de las cadenas para mejorar los cálculos de cardinalidad de los predicados de consulta que utilizan el operador LIKE; por ejemplo, WHERE ProductName LIKE '%Bike'. Las estadísticas de resumen de cadenas se almacenan de forma independiente del histograma y se crean en la primera columna de clave del objeto de estadísticas cuando es de tipo char, varchar, nchar, nvarchar, varchar(max), nvarchar(max), text o ntext. |
| Expresión de filtro | Predicado del subconjunto de filas de la tabla incluido en el objeto de estadísticas. NULL = estadísticas sin filtrar. Para más información sobre los predicados filtrados, vea Crear índices filtrados. Para más información sobre las estadísticas filtradas, vea Estadísticas. |
| Filas sin filtrar | Número total de filas de la tabla antes de aplicar la expresión de filtro. Si Expresión de filtro es NULL, Unfiltered Rows es igual a Rows. |
| Persisted Sample Percent | Porcentaje de ejemplo persistente empleado en las actualizaciones de estadísticas en las que no se especifica explícitamente un porcentaje de muestreo. Si el valor es cero, significa que no hay establecido ningún porcentaje de ejemplo persistente para esta estadística. Se aplica a: SQL Server 2016 (13.x) Service Pack 1 CU 4 |
En la tabla siguiente se describen las columnas devueltas en el conjunto de resultados si se especifica DENSITY_VECTOR.
| Nombre de la columna | Descripción |
|---|---|
| Toda la densidad | La densidad es 1 / valores distintos. Los resultados muestran la densidad de cada prefijo de columnas del objeto de estadísticas (una fila por cada densidad). Un valor distinto es una lista Distinct de los valores de columna de cada fila y prefijo de columna. Por ejemplo, si el objeto de estadísticas contiene las columnas de clave (A, B, C), los resultados indican la densidad de las listas de valores distintos de cada uno de estos prefijos de columna: (A), (A,B) y (A, B, C). Si se usa el prefijo (A, B, C), cada una de estas listas es una lista de valores distintos: (3, 5, 6), (4, 4, 6), (4, 5, 6), (4, 5, 7). Si se usa el prefijo (A, B) los valores de la misma columna tendrán estas listas de valores distintos: (3, 5), (4, 4) y (4, 5) |
| Promedio de longitud | Promedio de longitud, en bytes, para almacenar una lista de los valores de columna del prefijo de columna. Por ejemplo, si cada valor de la lista (3, 5, 6) necesita 4 bytes, la longitud es 12 bytes. |
| Columnas | Nombres de las columnas en el prefijo para las que se muestran Toda la densidad y Promedio de longitud. |
En la tabla siguiente se describen las columnas devueltas en el conjunto de resultados si se especifica la opción HISTOGRAM.
| Nombre de la columna | Descripción |
|---|---|
| RANGE_HI_KEY | Valor de columna límite superior de un paso del histograma. El valor de columna también se denomina valor de clave. |
| RANGE_ROWS | Número calculado de filas cuyo valor de columna está comprendido en un paso del histograma, sin incluir el límite superior. |
| EQ_ROWS | Número calculado de filas cuyo valor de columna es igual al límite superior del paso del histograma. |
| DISTINCT_RANGE_ROWS | Número calculado de filas que tienen un valor de columna distinto en un paso del histograma, sin incluir el límite superior. |
| AVG_RANGE_ROWS | Promedio de filas con valores de columna duplicados en un paso del histograma, sin incluir el límite superior. Cuando DISTINCT_RANGE_ROWS es mayor que 0, AVG_RANGE_ROWS se calcula dividiendo RANGE_ROWS por DISTINCT_RANGE_ROWS. Cuando DISTINCT_RANGE_ROWS es 0, AVG_RANGE_ROWS devuelve 1 para el paso del histograma. |
Comentarios
La fecha de actualización de estadísticas se almacena en el objeto BLOB de estadísticas junto con el histograma y el vector de densidad, pero no en los metadatos. Cuando no se lee ningún dato con el que generar datos de estadísticas, el BLOB de estadísticas no se crea, la fecha no está disponible y la columna updated es NULL. Esto sucede en las estadísticas filtradas, en las que el predicado no devuelve ninguna fila, o en las tablas nuevas vacías.
Histograma
Un histograma mide la frecuencia de aparición de cada valor distinto en un conjunto de datos. El optimizador de consultas calcula un histograma de los valores de la primera columna de clave del objeto de estadísticas; para ello, selecciona los valores de la columna tomando una muestra estadística de las filas o realizando un análisis completo de todas las filas de la tabla o vista. Si el histograma se crea a partir de muestras de un conjunto de filas, los totales almacenados para el número de filas y el número de valores distintos son las estimaciones y no es necesario que sean números enteros.
Para crear el histograma, el optimizador de consultas ordena los valores de columna, calcula el número de valores que coinciden con cada valor de columna distinto y, a continuación, agrupa los valores de columna en un máximo de 200 pasos de histograma contiguos. Cada paso incluye un intervalo de valores de columna seguido de un valor de columna de límite superior. El intervalo incluye todos los valores de columna posibles comprendidos entre los valores límite (sin incluir los propios valores límite). El valor de columna ordenado más pequeño es el valor del límite superior del primer paso del histograma.
En el diagrama siguiente se muestra un histograma con seis pasos. El área a la izquierda del primer valor límite superior es el primer paso.

En cada paso del histograma:
- La línea gruesa representa el valor de límite superior (RANGE_HI_KEY) y el número de veces que tiene lugar (EQ_ROWS).
- El área de color sólido situada a la izquierda RANGE_HI_KEY representa el intervalo de valores de columna y el número medio de veces que tiene lugar cada valor de columna (AVG_RANGE_ROWS). El valor de AVG_RANGE_ROWS en el primer paso del histograma siempre es 0.
- Las líneas de puntos representan los valores de las muestras utilizados para estimar el número total de valores distintos que hay en el intervalo (DISTINCT_RANGE_ROWS) y el número total de valores que hay en el intervalo (RANGE_ROWS). El optimizador de consultas utiliza RANGE_ROWS y DISTINCT_RANGE_ROWS para calcular AVG_RANGE_ROWS y no almacena los valores de las muestras.
El optimizador de consultas define los pasos del histograma en función de su importancia estadística. Utiliza un algoritmo de diferencias máximas para minimizar el número de pasos del histograma a la vez que minimiza las diferencias entre los valores límite. El número máximo de pasos es 200. El número de pasos del histograma puede ser menor que el número de valores distintos, incluso para las columnas con menos de 200 puntos de límite. Por ejemplo, una columna con 100 valores distintos puede tener un histograma con menos de 100 puntos de límite.
Vector de densidad
El optimizador de consultas utiliza las densidades para mejorar las estimaciones de cardinalidad de las consultas que devuelven varias columnas de la misma tabla o vista indizada. El vector de densidad contiene una densidad para cada prefijo de columnas del objeto de estadísticas. Por ejemplo, si un objeto de estadísticas tiene las columnas de clave CustomerId, ItemId y Price, la densidad se calcula en cada uno de los siguientes prefijos de columna.
| Prefijo de columna | Densidad calculada en |
|---|---|
(CustomerId) |
Filas con valores que se corresponden con CustomerId |
(CustomerId, ItemId) |
Filas con valores que se corresponden con CustomerId y ItemId |
(CustomerId, ItemId, Price) |
Filas con valores que se corresponden con CustomerId, ItemId y Price |
Limitaciones
DBCC SHOW_STATISTICS no proporciona estadísticas de índices espaciales ni índices de almacén de columnas optimizados para memoria.
Permisos para SQL Server y SQL Database
Para ver el objeto de estadísticas, el usuario debe tener el permiso SELECT en la tabla.
Los siguientes requisitos existen para que los permisos SELECT sean suficientes para ejecutar el comando:
- Los usuarios deben tener permisos en todas las columnas del objeto de estadísticas
- Los usuarios deben tener permiso en todas las columnas de una condición de filtro (si existe alguna)
- La tabla no puede tener una directiva de seguridad de nivel de fila.
- Si alguna de las columnas de un objeto de estadísticas se enmascara con reglas de Enmascaramiento dinámico de datos, además del permiso
SELECT, el usuario debe tener el permisoUNMASKo ser miembro del rol db_ddladmin.
En versiones anteriores a SQL Server 2012 (11.x) Service Pack 1, el usuario debe ser propietario de la tabla o miembro del rol fijo de servidor sysadmin, o bien de los roles fijos de base de datos db_owner o db_ddladmin.
Nota:
Para volver a cambiar el comportamiento al anterior a SQL Server 2012 (11.x) Service Pack 1, use la marca de seguimiento 9485.
Permisos para Azure Synapse Analytics y Analytics Platform System (PDW)
DBCC SHOW_STATISTICS requiere el permiso SELECT en la tabla o la pertenencia al rol fijo de servidor sysadmin, el rol fijo de base de datos db_owner o el rol fijo de base de datos db_ddladmin.
Limitaciones y restricciones de Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
DBCC SHOW_STATISTICS muestra las estadísticas almacenadas en la base de datos Shell en el nivel del nodo de control. No muestra las estadísticas que SQL Server crea automáticamente en los nodos de ejecución.
DBCC SHOW_STATISTICS no se admite en tablas externas.
En Microsoft Fabric, DBCC SHOW_STATISTICS solo muestra los resultados de las estadísticas de histograma, no las estadísticas ACE-*.
Ejemplos: SQL Server y Azure SQL Database
A. Devolución de la información de todas las estadísticas
En el siguiente ejemplo se muestra toda la información de estadísticas del índice AK_Address_rowguid de la tabla Person.Address de la base de datos AdventureWorks2022.
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
GO
B. Especificación de la opción HISTOGRAM
Esto limita la información de estadísticas mostrada en relación con el índice Customer_LastName a únicamente los datos de HISTOGRAM.
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName) WITH HISTOGRAM;
GO
Ejemplos: Azure Synapse Analytics y Sistema de la plataforma de análisis (PDW)
C. Mostrar el contenido de un objeto de estadísticas
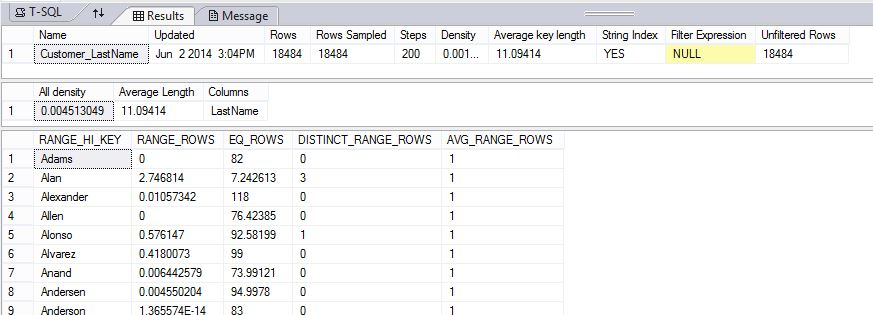
En el siguiente ejemplo se crea un objeto de estadística y, a continuación, se muestra el contenido de la estadística Customer_LastName en la tabla DimCustomer de la base de datos de ejemplo AdventureWorksPDW2022.
-- Uses AdventureWorksPDW
--First, create a statistics object
CREATE STATISTICS Customer_LastName
ON AdventureWorksPDW2012.dbo.DimCustomer (LastName);
GO
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName);
GO
Los resultados muestran el encabezado, el vector de densidad y parte del histograma.
Consulte también
- Estadísticas
- Estadísticas en Microsoft Fabric
- sys.dm_db_stats_properties (Transact-SQL)
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_db_incremental_stats_properties (Transact-SQL)
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de