Información general sobre Service Manager cubos OLAP para análisis avanzado
Importante
Esta versión de Service Manager ha llegado al final del soporte técnico. Se recomienda actualizar a Service Manager 2022.
En Service Manager, los datos que están presentes en el almacenamiento de datos se pueden consolidar desde varios orígenes. Se presenta a través de Service Manager mediante cubos de datos predefinidos y personalizados de Microsoft Online Analytical Processing (OLAP). En resumen, los análisis avanzados de Service Manager constan de publicación, visualización y manipulación de datos de cubo, normalmente en Microsoft Excel o Microsoft SharePoint. Excel se utiliza principalmente por sí mismo para ver y manipular los datos. SharePoint se utiliza principalmente como medio para publicar y compartir datos del cubo.
Service Manager incluye un almacenamiento de datos para todo System Center. Por lo tanto, los datos de Operations Manager, Configuration Manager y Service Manager se pueden consolidar en el almacenamiento de datos, donde puede usar fácilmente varias vistas de datos para obtener cualquier información que desee. También es una interfaz, donde los datos de las fuentes propias personalizadas se pueden incluir en el mismo almacenamiento de datos, como las aplicaciones SAP u otra aplicación de recursos humanos de terceros. Esta consolidación crea un modelo común de datos y permite realizar análisis enriquecidos que ayudan a crear un almacenamiento de datos en toda la organización de tecnologías de la información (TI) para satisfacer las necesidades de inteligencia e informes de toda la empresa.
Una vez que los datos están en un modelo común, puede manipular la información y tener definiciones comunes y una taxonomía común para toda la empresa. Puede hacerlo mediante la implementación de cubos de datos OLAP, desde donde se tiene acceso a la información a través de herramientas estándar, como Excel y SharePoint. Esto posibilita que los usuarios empleen las habilidades que ya conocen. La definición de la lógica empresarial se controla de manera centralizada. Por ejemplo, puede definir indicadores clave de rendimiento, tales como los umbrales de tiempo de resolución de incidentes, donde los valores de dichos umbrales son verde, amarillo o rojo. Puede controlar estas opciones de forma centralizada y permitir a los usuarios que utilicen los datos de forma sencilla, a la vez que tienen una definición común en sus informes Excel o paneles SharePoint.
Acerca de Service Manager cubos OLAP
Los cubos de procesamiento analítico en línea (OLAP) son una característica de Service Manager que usan la infraestructura de almacenamiento de datos existente para proporcionar funcionalidades de inteligencia empresarial de autoservicio a los usuarios finales.
Un cubo OLAP es una estructura de datos que supera las limitaciones de las bases de datos relacionales y proporciona un análisis rápido de datos. Los cubos pueden mostrar y sumar grandes cantidades de datos, a la vez que proporcionan a los usuarios acceso mediante búsqueda a los puntos de datos. De este modo, los datos se pueden agrupar, segmentar y segmentar según sea necesario para controlar la mayor variedad de preguntas relevantes para el área de interés de un usuario.
Los proveedores de software o los desarrolladores de tecnología de la información (TI) con un conocimiento práctico de los cubos OLAP pueden crear módulos de administración para definir sus propios cubos OLAP extensibles y personalizables que se basan en la infraestructura de almacenamiento de datos. Estos cubos se almacenan en SQL Server Analysis Services (SSAS). Las herramientas de inteligencia empresarial con características de autoservicio, como Excel y SQL Server Reporting Services (SSRS), pueden acceder a estos cubos en SSAS y se pueden utilizar para analizar los datos desde múltiples perspectivas.
Las bases de datos que una empresa utiliza para almacenar sus transacciones y registros se denominan bases de datos de procesamiento de transacciones en línea (OLTP). Normalmente, estas bases de datos tienen registros que se introducen uno a uno y que contienen una gran cantidad de información, que los estrategas pueden utilizar para tomar decisiones fundamentadas sobre sus negocios. Sin embargo, las bases de datos que se usan para almacenar los datos no se diseñaron para su análisis. Por lo tanto, obtener respuestas de estas bases de datos es costoso en términos de tiempo y esfuerzo. Las bases de datos OLAP son bases de datos especializadas, diseñadas para ayudar a extraer esta información de inteligencia empresarial de los datos.
Los cubos OLAP se pueden considerar como la última pieza del rompecabezas para una solución de almacenamiento de datos. Un cubo OLAP, también conocido como cubo multidimensional o hipercubo, es una estructura de datos en SQL Server Analysis Services (SSAS) que se genera mediante bases de datos OLAP para permitir el análisis casi instantáneo de datos. La topología de este sistema se muestra en la siguiente ilustración.
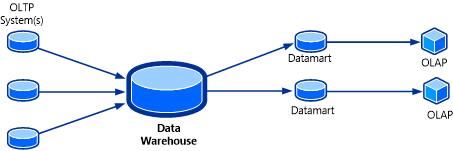
La característica útil de un cubo OLAP es que los datos del cubo pueden estar contenidos en un formulario agregado. Para el usuario, el cubo parece tener las respuestas de antemano debido a la variedad de valores que ya están precalculados. Sin tener que consultar la base de datos OLAP de origen, el cubo puede devolver respuestas para una amplia gama de preguntas casi al instante.
El objetivo principal de Service Manager cubos OLAP es proporcionar a los proveedores de software o a los desarrolladores de tecnología de la información (TI) la capacidad de realizar análisis casi instantáneos de los datos tanto con fines históricos de análisis como de tendencias. Service Manager lo hace:
- Permite definir cubos OLAP en módulos de administración que se crearán automáticamente en SSAS cuando se implemente el módulo de administración.
- Se ocupa automáticamente del mantenimiento del cubo, sin intervención del usuario, y realiza tareas tales como el procesamiento, la creación de particiones, las traducciones y la localización, así como los cambios del esquema.
- Permite a los usuarios utilizar herramientas de inteligencia empresarial con características de autoservicio, tales como Excel, para analizar los datos desde varias perspectivas.
- Guarda informes generados de Excel para futuras referencias.
Para ver cómo se representan los cubos de almacenamiento de datos en la consola de Service Manager, vaya al área de trabajo Data Warehouse y seleccione Cubos.
Service Manager cubos OLAP
La ilustración siguiente muestra una imagen desde SQL Server Business Intelligence Development Studio (BIDS) que representa las partes principales que son necesarias para los cubos de procesamiento analítico en línea (OLAP). Estas partes son el origen de datos, las vista de origen de los datos, los cubos y las dimensiones. En las secciones siguientes se describen las partes del cubo OLAP y las acciones que los usuarios pueden realizar con ellos.
Origen de datos
Un origen de datos es el origen de todos los datos contenidos dentro de un cubo OLAP. Un cubo OLAP se conecta a un origen de datos para leer y procesar los datos sin procesar para llevar a cabo cálculos y agregaciones para sus medidas asociadas. El origen de datos de todos los cubos OLAP de Service Manager es el data marts, que incluye los data marts para Operations Manager y Configuration Manager. La información de autenticación sobre el origen de datos se debe almacenar en SQL Server Analysis Services (SSAS) para establecer el nivel correcto de permisos.
Vista del origen de datos
La vista del origen de datos (DSV) es una colección de vistas que representan las tablas de dimensiones, hechos y desagregación del origen de datos, como los Service Manager data marts. La DSV contiene todas las relaciones entre tablas, tales como las claves principales y externas. En otras palabras, la DSV especifica cómo se asignará la base de datos de SSAS al esquema relacional, y proporciona una capa de abstracción sobre la base de datos relacional. Con esta capa de abstracción se pueden definir relaciones entre las tablas de hechos y dimensiones, incluso si no existen relaciones dentro de la base de datos relacional de origen. En la DSV también se pueden definir los cálculos con nombre, las medidas personalizadas y los nuevos atributos que podrían no existir de forma nativa en el esquema dimensional del almacenamiento de datos. Por ejemplo, un cálculo con nombre que define un valor booleano para Incidents Resolved calcula el valor como true si el estado de un incidente se resuelve o se cierra. Con el cálculo con nombre, Service Manager puede definir una medida para mostrar información útil, como el porcentaje de incidentes resueltos, el número total de incidentes resueltos y el número total de incidentes que no se resuelven.
Otro ejemplo rápido de un cálculo con nombre es ReleasesImplementedOnSchedule. Este cálculo con nombre proporciona una comprobación rápida del estado de mantenimiento en el número de registros de versión donde la fecha de finalización real es inferior o igual a la fecha de finalización programada.
Cubos OLAP
Un cubo OLAP es una estructura de datos que supera las limitaciones de las bases de datos relacionales y proporciona un análisis rápido de datos. Los cubos OLAP pueden mostrar y sumar grandes cantidades de datos, a la vez que proporcionan a los usuarios acceso que se pueden buscar a cualquier punto de datos para que los datos se puedan agrupar, segmentar y desglosar según sea necesario para controlar la mayor variedad de preguntas relevantes para el área de interés de un usuario.
Dimensions
Una dimensión de SSAS hace referencia a una dimensión del Service Manager almacenamiento de datos. En Service Manager, una dimensión es aproximadamente equivalente a una clase de módulo de administración. Cada clase de módulo de administración tiene una lista de propiedades, mientras que cada dimensión contiene una lista de atributos, con cada atributo asignado a una propiedad en una clase. Las dimensiones permiten el filtrado, la agrupación y el etiquetado de datos. Por ejemplo, puede filtrar los equipos por el sistema operativo instalado y agrupar a los usuarios en categorías por sexo o edad. A continuación, los datos se pueden presentar en un formato en el que los datos se clasifican de forma natural en estas jerarquías y categorías para permitir un análisis más detallado. Las dimensiones también pueden tener jerarquías naturales para permitir a los usuarios "explorar en profundidad" a niveles de detalle más detallados. Por ejemplo, la dimensión Fecha tiene una jerarquía de la que se pueden obtener más detalles por Año, a continuación Trimestre, a continuación, Mes, a continuación, Semana y a continuación Día.
La ilustración siguiente muestra un cubo OLAP que contiene las dimensiones Fecha, Región y Producto.
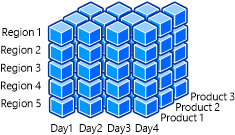
Por ejemplo, los miembros del equipo de Microsoft pueden querer un resumen rápido y sencillo de las ventas de la consola de juegos de Xbox One en la versión aplicable. Pueden desglosarlo más para obtener cifras de ventas de un período de tiempo más específico. Es posible que los analistas de negocios quieran examinar cómo las ventas de las consolas Xbox One se vieron afectadas por el lanzamiento del nuevo diseño de la consola y el Kinect para Xbox One. Esto les ayuda a determinar las tendencias de ventas que se están produciendo y qué revisiones potenciales de estrategia de negocio son necesarias. Al filtrar en la dimensión de fecha, esta información se puede distribuir y consumir rápidamente. Esta reorganización de los datos solo está habilitada porque las dimensiones se han diseñado con atributos y datos que el cliente puede filtrar y agrupar fácilmente.
En Service Manager, todos los cubos OLAP comparten un conjunto común de dimensiones. Todas las dimensiones utilizan el data mart principal del almacenamiento de datos como su origen, incluso en escenarios de varios data mart. En escenarios de varios data mart, es posible que esto pueda conducir a errores de claves de dimensión durante el procesamiento del cubo.
Grupo de medida
Un grupo de medida es el mismo concepto que un hecho en la terminología de almacenamiento de datos. Del mismo modo que los hechos contienen medidas numéricas en un almacenamiento de datos, un grupo de medida contiene medidas para un cubo OLAP. Todas las medidas de un cubo OLAP que se derivan de una sola tabla de hechos en una vista de origen de datos también se pueden considerar un grupo de medida. Sin embargo, en algunos casos, puede haber varias tablas de hechos de las que derivan las medidas de un cubo OLAP. Las medidas del mismo nivel de detalle se unen en un grupo de medida. Los grupos de medida definen qué datos se cargarán en el sistema, cómo se cargarán los datos y cómo se enlazarán los datos al cubo multidimensional.
Cada grupo de medida también contiene una lista de particiones, que contiene los datos reales en secciones independientes y no superpuestas. Los grupos de medida también contienen diseño de agregación, que define los conjuntos de datos previamente resumidos que se calculan para que cada grupo de medida mejore el rendimiento de las consultas de usuario.
Medidas
Las medidas son los valores numéricos que los usuarios desean segmentar, dados, agregar y analizar; son una de las razones fundamentales por las que desea crear cubos OLAP mediante la infraestructura de almacenamiento de datos. Mediante el uso de SSAS, puede crear cubos OLAP que aplicarán reglas de negocio y cálculos para aplicar formato a las medidas y mostrarlas en un formato personalizable. Gran parte del tiempo empleado en el desarrollo de un cubo OLAP sirve para la determinación y la definición de las medidas que se mostrarán y de cómo se deben calcular.
Las medidas son valores que normalmente se asignan a columnas numéricas en una tabla de hechos del almacenamiento de datos, pero también se pueden crear en atributos de dimensión y de dimensión degenerada. Estas medidas son los valores más importantes de un cubo OLAP que se analizan y el interés principal de los usuarios finales que exploran el cubo OLAP. Un ejemplo de una medida que existe en el almacenamiento de datos es ActivityTotalTimeMeasure. ActivityTotalTimeMeasure es una medida de ActivityStatusDurationFact que representa el tiempo en que cada actividad se encuentra en un estado concreto. El nivel de detalle de una medida está formado por todas las dimensiones a las que se hace referencia. Por ejemplo, el nivel de detalle del hecho de relación ComputerHostsOperatingSystem consta de las dimensiones del equipo y del sistema operativo.
Las funciones de agregación se calculan en medidas para habilitar el análisis más profundo de los datos. La función de agregación más común es Suma. Una consulta común de cubo OLAP, por ejemplo, resume el tiempo total para todas las actividades In Progress. Otras funciones comunes de agregación son Mín, Máx y Cuenta.
Una vez procesados los datos sin procesar en un cubo OLAP, los usuarios pueden realizar cálculos y consultas más complejos mediante expresiones multidimensionales (MDX) para definir sus expresiones de medida o miembros calculados propios. MDX es el estándar de la industria para consultar y obtener acceso a datos almacenados en sistemas OLAP. SQL Server no se diseñó para trabajar con el modelo de datos que admiten las bases de datos multidimensionales.
Rastrear desagrupando datos
Cuando un usuario profundiza en los datos en un cubo OLAP para obtener detalles, está analizando los datos a otro nivel de resumen. El nivel de detalle de los datos cambia en función de la obtención de detalle aplicada por el usuario para examinar los datos a distintos niveles en la jerarquía. A medida que los usuarios exploran en profundidad, pasan de información de resumen a datos con un enfoque más estrecho. Los siguientes son ejemplos de obtención de detalles:
- Obtención de detalles de la información demográfica sobre la población de EE.UU. y, a continuación, del Estado de Washington y, a continuación, del área metropolitana de Seattle y, a continuación, de la ciudad de Redmond y, finalmente, de la población de Microsoft.
- Profundizar en las cifras de ventas de las consolas Xbox One para el año natural de 2015, luego el cuarto trimestre del año, luego el mes de diciembre, luego la semana antes de navidad y, finalmente, nochebuena.
Obtención de detalles
Cuando los usuarios profundizan en los datos, quieren ver todas las transacciones individuales que han contribuido a los datos agregados del cubo OLAP. En otras palabras, el usuario puede recuperar los datos con un nivel de detalle menor para un valor de medida determinado. Por ejemplo, cuando se le proporcionan los datos de ventas de un mes determinado y una categoría de producto, puede explorar en profundidad esos datos para ver una lista de cada fila de tabla que se encuentra dentro de esa celda de datos.
Es habitual confundir los términos explorar en profundidad y profundizar entre sí. La principal diferencia entre ellos es que una exploración en profundidad funciona en una jerarquía predefinida de datos( por ejemplo, EE. UU., en Washington y, a continuación, en Seattle, dentro del cubo OLAP. Una perforación va directamente al nivel más pequeño de detalle de datos y recupera un conjunto de filas del origen de datos que se ha agregado en una sola celda.
Indicador clave de rendimiento
Las organizaciones pueden utilizar indicadores clave de rendimiento (KPI) para evaluar el estado de su empresa y su rendimiento mediante la medición de su progreso hacia sus objetivos. Los KPI son métricas empresariales que se pueden definir para supervisar el progreso hacia ciertos objetivos y metas predefinidos. Un KPI tiene un valor de destino y un valor real, que representa un objetivo cuantitativo que es fundamental para el éxito de la organización. Los KPI se muestran en grupos en un cuadro de mandos para mostrar el estado general de la empresa en una instantánea rápida.
Un ejemplo de KPI es completar todas las solicitudes de cambio en un plazo de 48 horas. Un KPI se puede utilizar para medir el porcentaje de solicitudes de cambio que se resuelven en ese intervalo de tiempo. Puede crear paneles para representar visualmente los KPI. Por ejemplo, es posible que desee definir un valor de destino de KPI para la realización de todas las solicitudes de cambio en un plazo de 48 horas al 75 por ciento.
Particiones
Una partición es una estructura de datos que contiene algunos o todos los datos en un grupo de medida. Cada grupo de medida se divide en particiones. Una partición define un subconjunto de datos de hechos que se cargan en el grupo de medida. SSAS Standard Edition solo permite una partición por grupo de medida, mientras que SSAS Enterprise Edition permite un grupo de medida con varias particiones. Las particiones son una característica transparente para el usuario final, pero tienen un impacto importante tanto en el rendimiento como en la escalabilidad de los cubos OLAP. Todas las particiones de un grupo de medida siempre se encuentran en la misma base de datos física.
Las particiones permiten a un administrador administrar mejor un cubo OLAP y mejorar el rendimiento de un cubo OLAP. Por ejemplo, puede quitar o volver a procesar los datos de una partición de un grupo de medida sin que ello afecte al resto del grupo de medida. Cuando se cargan datos nuevos en una tabla de hechos, solo resultan afectadas las particiones que deben contener dichos datos.
La creación de particiones mejora el procesamiento y el rendimiento de las consultas en los cubos OLAP. SSAS puede procesar varias particiones en paralelo, lo que conduce a un uso mucho más eficiente de los recursos de la CPU y de la memoria en el servidor. Mientras ejecuta una consulta, SSAS también captura, procesa y agrega datos de varias particiones, solo se examinan las particiones que contienen los datos que son relevantes para una consulta, lo que reduce la cantidad total de entrada y salida.
Un ejemplo de estrategia de creación de particiones es colocar los datos de hechos de cada mes en una partición mensual. Al final de cada mes, todos los datos nuevos entran en una partición nueva, lo que conduce a una distribución natural de los datos con valores no superpuestos.
Agregaciones
Las agregaciones de un cubo OLAP son conjuntos de datos con resúmenes previos. Son análogos a una instrucción SELECT de SQL con una cláusula GROUP BY. SSAS puede usar estas agrupaciones cuando responde a las consultas para reducir la cantidad de cálculos necesarios, con lo que las respuestas llegan rápidamente al usuario. Las agregaciones integradas del cubo OLAP reducen la cantidad de agregación que SSAS tiene que realizar en el momento de la consulta. La creación de las agregaciones correctas puede mejorar significativamente el rendimiento de las consultas. A menudo este proceso está en constante evolución durante toda la duración del cubo OLAP, ya que sus consultas y so cambian.
Normalmente se crea un conjunto básico de agregaciones que serán útiles para la mayoría de las consultas del cubo OLAP. Las agregaciones se crean para cada partición de un cubo OLAP dentro de un grupo de medida. Cuando se crea una agregación, se incluyen algunos atributos de las dimensiones en el conjunto de datos con resumen previo. Los usuarios pueden realizar consultas rápidamente basándose en estas agrupaciones cuando examinan el cubo OLAP. Las agregaciones deben diseñarse con cuidado, ya que el número de posibles agregaciones es tan grande que la creación de todas ellas necesitaría una cantidad de tiempo y un espacio de almacenamiento no adecuados.
Service Manager usa las dos opciones siguientes al compilar y diseñar agregaciones en Service Manager cubos OLAP:
- Ganancia de rendimiento
- Optimización basada en el uso
La opción Ganancia de rendimiento define el porcentaje de agregaciones que se ha creado. Por ejemplo, si en esta opción se selecciona en el valor predeterminado y recomendado del 30 por ciento significa que las agregaciones se generarán para dar el cubo OLAP una ganancia de rendimiento del 30 por ciento. Sin embargo, esto no significa que se compilará el 30 % de las agregaciones posibles.
La optimización basada en el uso permite que SSAS registre las solicitudes de datos para que cuando se ejecute una consulta, la información se introduce en el proceso de diseño de agregación. A continuación, SSAS revisa los datos y recomienda las agregaciones que se deben generar para dar la máxima ganancia de rendimiento.
creación de particiones de cubo de Service Manager
Cada grupo de medida de un cubo se divide en particiones, donde una partición define una parte de los datos de hechos que se carga en un grupo de medida. SQL Server Analysis Services (SSAS) en SQL Server Standard Edition solo permite una partición por grupo de medida, mientras que se permiten varias particiones en el Enterprise Edition. Las particiones son completamente transparentes para el usuario final, pero tienen un impacto importante en el rendimiento y la escalabilidad. Por ejemplo, las particiones se pueden procesar por separado y en paralelo. Pueden tener diseños de agregaciones diferentes. Puede volver a procesar una partición sin afectar al resto de las particiones de un grupo de medida. Además, SSAS solo escanea automáticamente las particiones que contienen los datos necesarios para una consulta, lo que puede mejorar considerablemente el rendimiento de las consultas.
La partición de cubos se realiza en cada ejecución del trabajo de mantenimiento del almacenamiento de datos, que se tiene lugar cada hora de forma predeterminada. El módulo del proceso específico que se ejecuta se denomina ManageCubePartitions. Siempre se ejecuta después del paso CreateMartPartitions. Estos datos de dependencia se almacenan en la tabla infra.moduletriggercondition.
La biblioteca principal de vínculos dinámicos (DLL), que controla la creación de particiones, está en la utilidad DLL del almacenamiento, Microsoft.EnterpriseManagement.Warehouse.Utility, en la clase PartitionUtil. En concreto, hay un método ManagePartitions() en la clase que controla todo el mantenimiento de particiones. Ambas, la DLL de mantenimiento del almacenamiento de datos, Microsoft.EnterpriseManagement.Warehouse.Maintenance, y la DLL de procesamiento analítico en línea (OLAP) del almacenamiento de datos, Microsoft.EnterpriseManagement.Warehouse.Olap, solicitan a Microsoft.EnterpriseManagement.Warehouse.Utility que procese las particiones durante el mantenimiento y la implementación del cubo. Por esta razón, para evitar la duplicación de la lógica o del código, el procesamiento real de la partición se realiza en la utilidad DLL del almacenamiento común.
El mantenimiento de las particiones de un cubo realiza las siguientes tareas:
- Crear particiones
- Eliminar particiones
- Actualizar límites de la partición
Para ello, se lee la tabla etl.TablePartition de Lenguaje de consulta estructurado (SQL), con el fin de determinar todas las particiones de hecho que se han creado para un grupo de medida. Se producirán las acciones siguientes:
- Iniciar el procesamiento del cubo para cada grupo de medida del cubo
- Obtener todas las particiones de la tabla etl.TablePartition para el grupo de medida
- Eliminar todas las particiones que existen en el grupo de medida, pero que faltan en la tabla etl.TablePartition
- Agregar las particiones nuevas que se han creado y que sólo existen en la tabla etl.TablePartition
- Actualizar cualquier partición que pueda haber cambiado haciendo coincidir cada partición con RangeStartDate y RangeEndDate en la tabla etl.TablePartition
Recuerde lo siguiente sobre el procesamiento de cubos:
- Solo los grupos de medida destinados a hechos contienen varias particiones en SQL Server Standard Edition. De forma predeterminada, todos los grupos de medida y dimensiones contienen sólo una partición. Por lo tanto, la partición no tiene ninguna condición de límite.
- Los límites de la partición se definen mediante un enlace de consulta que se basa en los datekeys que coinciden con los datekeys de la partición de hecho correspondiente en la tabla etl.TablePartition.
Service Manager implementación del cubo OLAP
La implementación de cubos de procesamiento analítico en línea (OLAP) usa la infraestructura de implementación de Service Manager para crear cubos OLAP en la base de datos SQL Server Analysis Services (SSAS).
En resumen, un elemento que se puede implementar devuelve un implementador con una colección de recursos que se serializan y que se utilizan para crear el cubo OLAP en la base de datos de SSAS. Para los cubos OLAP, el nombre del objeto que se puede implementar es CubeDeployable, para el elemento SystemCenterCube, y CubeExtensionDeployable, para el elemento CubeExtension. El implementador de ambos elementos es CubeDeployer.
La tabla dbo.Selector, en la base de datos DWStagingAndConfig, contiene una entrada para los elementos SystemCenterCube y CubeExtension del módulo de administración. El motor de implementación utiliza este metadato si es necesario realizar un procesamiento adicional para un elemento del módulo de administración al importar dicho módulo al almacenamiento de datos mediante el trabajo MPSync.
Las implementaciones utilizan la interfaz de programación de aplicaciones (API) de Analysis Management Objects (AMO) para crear y modificar todos los componentes del cubo en la base de datos de SSAS. En concreto, se usa AMO en modo desconectado porque el elemento CubeDeployable no tendrá una conexión a la base de datos SSAS. Al trabajar con AMO en un modo sin conexión, es posible crear un árbol completo de objetos AMO sin tener que conectarse al servidor. Service Manager serializa la jerarquía de objetos como recursos de secuencia y los asocia al objeto deployer que se pasa de nuevo a la infraestructura de implementación. A continuación, el objeto del implementador se deserializa, establece una conexión con la base de datos de SSAD y crea los objetos mediante el envío de las solicitudes correspondientes al servidor.
Sólo los objetos principales se pueden serializar. En AMO, los principales objetos se consideran clases que representan un objeto completo como una entidad completa y no como parte de otro objeto. Por ejemplo, los objetos principales incluyen Server, Cube y Dimension, que son todas entidades independientes. Sin embargo, DimensionAttribute no es un objeto principal porque solo se puede crear como parte de un objeto principal primario de Dimension. Por lo tanto, DimensionAttribute es un objeto secundario. El diseño del cubo OLAP se centra en la creación de todos los objetos principales que son necesarios para los cubos, junto con los objetos dependientes de menor importancia. Estos objetos principales son los objetos que se serializarán y, finalmente, se deserializarán antes de crear los objetos en la base de datos de SSAS.
Los recursos que ajustan los objetos principales se deben crear en un orden específico para que la implementación se realice correctamente y satisfaga los requisitos de dependencia de los elementos del cubo OLAP. Las dos listas siguientes ilustran la secuencia de implementación de los elementos SystemCenterCube y CubeExtension, respectivamente:
- Elementos DataSourceView
- elementos de dimensión
- elemento de dimensión de fecha
- elemento de cubo
- Elementos DataSourceView
- elemento de cubo
procesamiento de cubos OLAP de Service Manager
Cuando se ha implementado un cubo de procesamiento analítico en línea (OLAP) y se han creado todas sus particiones, está listo para procesarse para que sea visible. El procesamiento del cubo es el último paso después de las ejecuciones de extracción, transformación y carga (ETL). Estos pasos se producen de la forma siguiente:
- Extraer: extraer datos del sistema de origen
- Transformar: aplicar funciones para ajustar los datos a un esquema dimensional estándar
- Cargar: cargar los datos en el data mart para el consumo
- Proceso: cargar los datos del data mart en el cubo OLAP para la exploración
El procesamiento de un cubo OLAP se produce una vez que se han calculado todas sus agregaciones y se ha cargado con estos datos y agregaciones. Se leen las tablas de hechos y dimensiones, y los datos se calculan y se cargan en el cubo. A la hora de diseñar un cubo OLAP, es necesario reflexionar detenidamente sobre su procesamiento, debido al efecto potencialmente significativo de dicho procesamiento en un entorno de producción donde podrían existir millones de registros. Un proceso completo de todas las particiones de este entorno puede tardar entre días e incluso semanas, lo que podría representar la infraestructura y los cubos Service Manager inutilizables para los usuarios finales. Una recomendación es deshabilitar la programación de procesamiento de los cubos que no se usan para reducir la sobrecarga en el sistema.
El procesamiento de los cubos OLAP consta de dos tareas independientes:
- Procesamiento de dimensiones
- Procesamiento de particiones
Cada cubo OLAP tiene un trabajo de procesamiento correspondiente en la consola de Service Manager y se ejecuta según una programación configurable por el usuario. En las siguientes secciones se describe cada tipo de tarea de procesamiento.
Procesamiento de dimensiones
Siempre que se agrega una nueva dimensión a la base de datos del servidor SQL Server Analysis Server (SSAS), se debe ejecutar un proceso completo en la dimensión para que tenga un estado completamente procesado. Sin embargo, después de procesar una dimensión, no hay ninguna garantía de que se procesará de nuevo cuando se procese otro cubo que tenga como destino la misma dimensión. Al no volver a procesar automáticamente la dimensión, se impide que Service Manager vuelva a procesar todas las dimensiones de cada cubo. Esto es especialmente cierto si la dimensión se ha procesado recientemente, ya que es poco probable que existan nuevos datos que aún no se hayan procesado. Para optimizar la eficiencia del procesamiento, hay una clase singleton, que se define en el módulo de administración Microsoft.SystemCenter.Datawarehouse.OLAP.Base, denominado Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval. El siguiente es un ejemplo de esta clase:
<!-- This singleton class defines the minimum interval of time in minutes that must elapse before a shared dimension is reprocessed. -->
<ClassType ID="Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval" Accessibility="Public" Abstract="false" Base="AdminItem!System.AdminItem" Singleton="true">
<Property ID="IntervalInMinutes" Type="int" Required="true" DefaultValue="60"/>
</ClassType>
Esta clase singleton contiene una propiedad, IntervalInMinutes, que describe la frecuencia de procesamiento de una dimensión. De forma predeterminada, esta propiedad se establece en 60 minutos. Por ejemplo, si se procesó una dimensión a las 3:05 p.m. y otro cubo que tiene como destino la misma dimensión se procesa a las 3:45 p.m., la dimensión no se vuelve a procesar. Un inconveniente de este enfoque es el aumento de las posibilidades de errores de clave de dimensión. Un mecanismo de reintento controla los errores clave de la dimensión para poder reprocesar tanto la dimensión como la partición del cubo. Para obtener más información sobre los errores de procesamiento, consulte la sección "Problemas comunes con la depuración y la solución de problemas".
Una vez que la dimensión se ha procesado completamente, se ejecuta un procesamiento incremental con ProcessUpdate . La otra ocasión en que se ejecuta ProcessFull es cuando se producen cambios en el esquema de una dimensión, ya que la devuelven a un estado sin procesar. Recuerde que si ProcessFull se realiza en una dimensión, todos los cubos afectados y sus particiones existirán en un estado no procesado y tendrán que procesarse completamente en su siguiente ejecución programada.
Procesamiento de particiones
El procesamiento de particiones debe tenerse en cuenta cuidadosamente porque el reprocesamiento de una partición grande es lento y consume muchos recursos de CPU en el servidor que hospeda SSAS. Generalmente, el procesamiento de particiones tarda más que el procesamiento de dimensiones. A diferencia del procesamiento de dimensiones, el procesamiento de particiones no tiene efectos secundarios en otros objetos. Los dos únicos tipos de procesamiento que se realizan en System Center: Service Manager cubos OLAP son ProcessFull y ProcessAdd.
De forma similar a las dimensiones, la creación de nuevas particiones en un cubo OLAP requiere una tarea ProcessFull para que la partición esté en un estado en que se pueda consultar. Dado que una tarea ProcessFull es una operación costosa, solo se debe realizar cuando sea necesario; por ejemplo, al crear una partición o al actualizar una fila. En escenarios en los que se han agregado filas y no se han actualizado filas, Service Manager puede realizar una tarea ProcessAdd. Para ello, Service Manager usa marcas de agua y otros metadatos. En concreto, se consultan las tablas etl.cubepartition y etl.tablepartition para determinar el tipo de procesamiento que se va a llevar a cabo.
En el diagrama siguiente se muestra cómo Service Manager determina qué tipo de procesamiento se va a realizar en función de los datos de marca de agua.
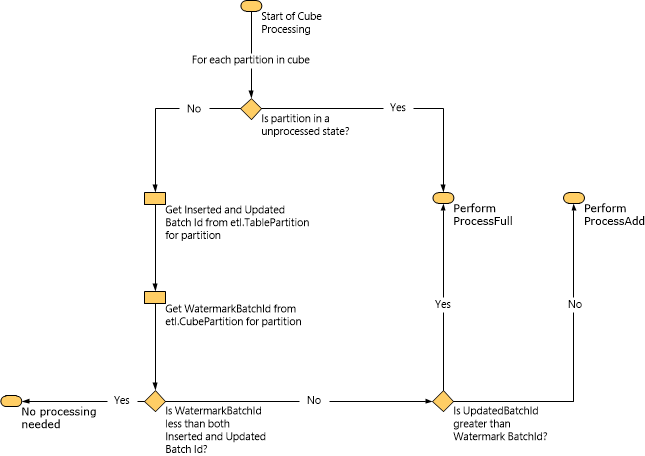
Cuando se realiza una tarea ProcessAdd, Service Manager limita el ámbito de la consulta mediante marcas de agua. Por ejemplo, si el valor de InsertedBatchId es 100 y el valor de WatermarkBatchId es 50, la consulta carga únicamente los datos del data mart en el que el valor de InsertedBatchId sea superior a 50 e inferior a 100.
Por último, es importante tener en cuenta que Service Manager no admite el procesamiento manual de cubos OLAP mediante SSAS o Business Intelligence Development Studio. El procesamiento de cubos fuera de los métodos que se proporcionan en System Center: Service Manager, incluida la consola de Service Manager y los cmdlets de Service Manager, no actualizará las tablas de marcas de agua. Por lo tanto, es posible que se produzcan problemas de integridad de datos. Si ha vuelto a procesar manualmente el cubo manualmente, una posible solución consiste en desprocesar el cubo OLAP manualmente de la misma manera. A continuación, la próxima vez que Service Manager procese el cubo, realizará automáticamente una tarea ProcessFull porque las particiones estarán en un estado no procesado. De esta forma, las marcas de agua y los metadatos se actualizarán correctamente y así se solucionará cualquier posible problema de integridad de datos.
Mantenimiento de Service Manager cubos OLAP
La información de las secciones siguientes describe los procedimientos recomendados de mantenimiento para los cubos de procesamiento analítico en línea (OLAP).
Reprocesar periódicamente dimensiones de Analysis Services
De acuerdo con los procedimientos recomendados de SQL Server Analysis Services (SSAS), las dimensiones SSAS se deben procesar completamente de forma periódica. Al procesar por completo las dimensiones se vuelven a generar índices y se optimiza el almacenamiento de datos multidimensionales, lo que mejora el rendimiento de las consultas y del cubo, que puede reducirse con el trascurso del tiempo. El proceso es similar a la desfragmentación periódica de un disco duro en un equipo.
Sin embargo, un inconveniente de procesar por completo una dimensión SSAS es que todos los cubos OLAP afectados pasan a un estado sin procesar y también se deben procesar por completo para devolverlos al estado en el que se pueden consultar. Service Manager no procesa explícitamente las dimensiones de SSAS. Por lo tanto, debe decidir cuándo realizar esta tarea de mantenimiento.
Consideraciones sobre memoria
Si ejecuta todas las operaciones de extracción, transformación y carga (ETL) del almacenamiento de datos, así como las funciones del cubo OLAP en un servidor, reflexione detenidamente sobre los requisitos del sistema operativo, el almacenamiento de datos y SSAS para asegurarse de que el servidor pueda realizar todas las operaciones de procesamiento intensivo de datos que se pueden ejecutar simultáneamente. Esto es especialmente importante, porque el procesamiento de cubos OLAP es una operación que usa mucha memoria.
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de