Escenario: Implementar Espacios de almacenamiento directo con VMM
Importante
Esta versión de Virtual Machine Manager (VMM) ha llegado al final del soporte técnico. Se recomienda actualizar a VMM 2022.
En este artículo se proporciona información general sobre la implementación de Espacios de almacenamiento directo (S2D) en el tejido de Virtual Machine Manager (VMM) de System Center.
S2D se introdujo en Windows Server 2016. Virtualiza el almacenamiento mediante la agrupación de unidades de almacenamiento físico en grupos de almacenamiento virtual. Con S2D puede:
- Administrar varios orígenes de almacenamiento físico como una entidad virtual única.
- Obtener almacenamiento virtual económico, con o sin dispositivos de almacenamiento físico externos.
- Reunir diferentes tipos de almacenamiento en un único grupo de almacenamiento virtual.
- Aprovisione fácilmente el almacenamiento y aumente los grupos de almacenamiento virtualizados a petición mediante la adición de nuevas unidades a ellos.
¿Cómo funciona?
S2D crea grupos de almacenamiento virtual a partir del almacenamiento físico asociado a nodos específicos de un clúster de Windows Server. El almacenamiento puede ser interno en el nodo o disco conectado directamente a un único nodo. Entre las unidades de almacenamiento compatibles se incluyen NVMe, SSD conectado a través de SATA o SAS, y unidades de disco duro. Más información.
- Cuando se habilita S2D en un clúster, S2D detecta automáticamente las unidades de almacenamiento aptas y las agrega a un grupo de almacenamiento.
- S2D crea una caché del lado servidor integrada para maximizar el rendimiento. S2D usa automáticamente las unidades más rápidas para el almacenamiento en caché. Las unidades restantes se usan para la capacidad. Más información sobre la caché.
- Los volúmenes se crean a partir de un grupo de almacenamiento. Cuando se crea un volumen, se crea el disco virtual (espacio de almacenamiento), se crean particiones en él y se formatea, se agrega al clúster y se convierte en un volumen compartido de clúster (CSV).
- Configure distintos niveles de tolerancia a errores para un volumen para especificar cómo se distribuyen los discos virtuales entre los discos físicos del grupo mediante SMB 3.0. Puede configurar un volumen sin resistencia ni con resistencia de reflejo o paridad. Más información.
Implementación convergida y no convergida
Un clúster de S2D puede implementarse de dos formas:
- Implementación hiperconvergida: el proceso de Hyper-V y S2D se ejecutan en el mismo clúster sin separación entre ellos.
- Implementación desagregada: el entorno se divide en proceso y almacenamiento. Los recursos del proceso se ejecutan en un clúster de Hyper-V. El almacenamiento se ejecuta en otro clúster.
En VMM, puede implementar S2D en una topología hiperconvergida o desagregada.
Implementación hiperconvergida
Los clústeres hiperconvergidos tienen las siguientes características:
- Hyper-V (proceso) y S2D (almacenamiento) se ejecutan en el mismo clúster.
- Los archivos de la máquina virtual se almacenan en CSV locales.
- No se usan recursos compartidos de archivos ni SMB.
- El clúster de proceso de Hyper-V y su almacenamiento se escalan juntos.
- Una vez que los volúmenes CSV de S2D están disponibles, debe aprovisionarlos de la misma manera que cualquier otra implementación de Hyper-V.
- En la ilustración siguiente se muestra la pila de implementación hiperconvergida.
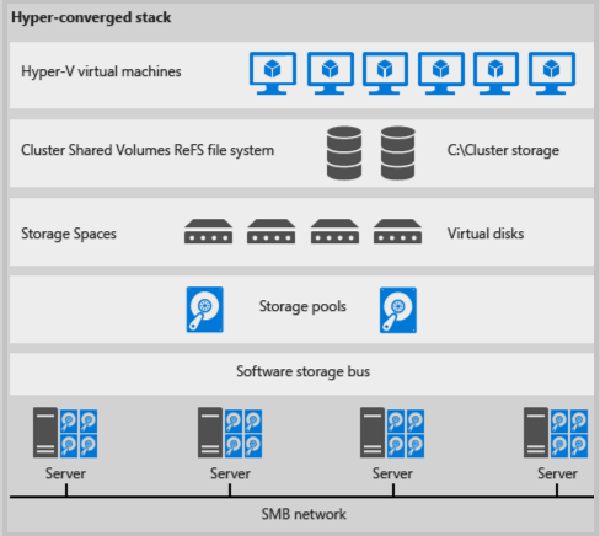
Ilustración 1: Implementación hiperconvergida
Implementación desagregada
Un clúster desagregado tiene las siguientes características:
- El clúster de proceso de Hyper-V es diferente del clúster de almacenamiento.
- Se crean recursos compartidos de archivos en los CSV del clúster de S2D. Las máquinas virtuales de Hyper-V están configuradas para almacenar sus archivos en el SOFS y se accede a ellas mediante SMB 3.0.
- Puede escalar los clústeres de Hyper-V y SOFS por separado para llevar a cabo una administración precisa. Por ejemplo, los nodos de proceso pueden aproximarse a la capacidad total en lo que respecta al número de máquinas virtuales, pero los nodos de almacenamiento podrían tener un exceso de capacidad de disco y de IOPS, por lo que solo debe agregar nodos de proceso adicionales.
Pasos siguientes
- Implemente Espacios de almacenamiento directo en el tejido de VMM.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de