Solución de problemas de colas de envío de registros en un grupo de disponibilidad de Always On
En este artículo se proporcionan soluciones a problemas relacionados con la cola de envío de registros.
¿Qué es la cola de envío de registros?
Los cambios realizados en una base de datos de grupo de disponibilidad en la réplica principal (como INSERT, UPDATEy DELETE) se escriben en el registro de transacciones y se envían a las réplicas secundarias del grupo de disponibilidad. La cola de envío de registros define el número de registros en los archivos de registro de la base de datos principal que no se han enviado a las réplicas secundarias.
Síntomas y efecto de la cola de envío de registros
La cola de envío de registros almacena todos los datos vulnerables
Si la réplica principal se pierde en un desastre repentino y conmuta por error a la réplica secundaria donde estos cambios aún no han llegado, esos cambios no aparecerán en la nueva copia de réplica principal de la base de datos. Esto excluye los cambios que se almacenan cuando se ejecutan copias de seguridad completas de registros y bases de datos.
El aumento de la cola de envío de registros provoca un crecimiento creciente del archivo de registro de transacciones
Para una base de datos definida en un grupo de disponibilidad, Microsoft SQL Server debe conservar en la réplica principal todas las transacciones del registro de transacciones que aún no se han entregado a las réplicas secundarias. La cola de envío de registros representa la cantidad de cambios registrados en la réplica principal que no se pueden truncar durante los eventos normales de truncamiento de registros (por ejemplo, durante una copia de seguridad del registro de base de datos). Una cola de envío de registros grande y creciente puede agotar espacio libre en la unidad que hospeda el archivo de registro de base de datos o puede superar el tamaño máximo configurado del archivo de registro de transacciones. Para obtener más información, consulte Error 9002 cuando el registro de transacciones es grande.
Varias características de diagnóstico notifican la puesta en cola de envío de registros de grupo de disponibilidad
El panel de Always On del SQL Server Management Studio informes sobre la cola de envío de registros. Es posible que informe de que el grupo de disponibilidad no es correcto.
Cómo comprobar si hay colas de envío de registros
La cola de envío de registros es una medida por base de datos. Puede comprobar este valor mediante el panel de Always On de la réplica principal o mediante el sys.dm_hadr_database_replica_states Vistas de administración dinámica (DMV) en la réplica principal o secundaria. Monitor de rendimiento contadores se usan para comprobar si hay colas de envío de registros en la réplica secundaria.
En las siguientes secciones se proporcionan métodos para supervisar activamente la cola de envío de registros de base de datos del grupo de disponibilidad.
Sys.dm_hadr_database_replica_state de consultas
La sys.dm_hadr_database_replica_states DMV informa de una fila para cada base de datos de grupo de disponibilidad. Una columna de ese informe es log_send_queue_size. Este valor es el tamaño de la cola de envío de registros en kilobytes (KB). Puede configurar una consulta como la siguiente para supervisar cualquier tendencia en el tamaño de la cola de envío de registros. La consulta se ejecuta en la réplica principal. Usa el is_local=0 predicado para notificar los datos de la réplica secundaria, donde log_send_queue_size y log_send_rate son pertinentes.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.log_send_queue_size, drs.log_send_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Este es el aspecto de la salida.

Revisión de la cola de envío de registros en Always On panel
Para revisar la cola de envío de registros, siga estos pasos:
Abra el panel de Always On en SQL Server Management Studio (SSMS) haciendo clic con el botón derecho en un grupo de disponibilidad de SSMS Explorador de objetos.
Seleccione Mostrar panel.
Las bases de datos del grupo de disponibilidad se enumeran por última vez y hay algunos datos notificados en las bases de datos. Aunque el tamaño de cola de envío de registros (KB) y la velocidad de envío de registros (KB/s) no aparecen de forma predeterminada, puede agregarlos a esta vista, como se muestra en la captura de pantalla del paso siguiente.
Para agregar estas columnas, haga clic con el botón derecho en el encabezado de columna de base de datos del grupo de disponibilidad y seleccione en la lista de columnas disponibles.
Para agregar tamaño de cola de envío de registros, haga clic con el botón derecho en el encabezado que se muestra como resaltado en rojo en la captura de pantalla siguiente.
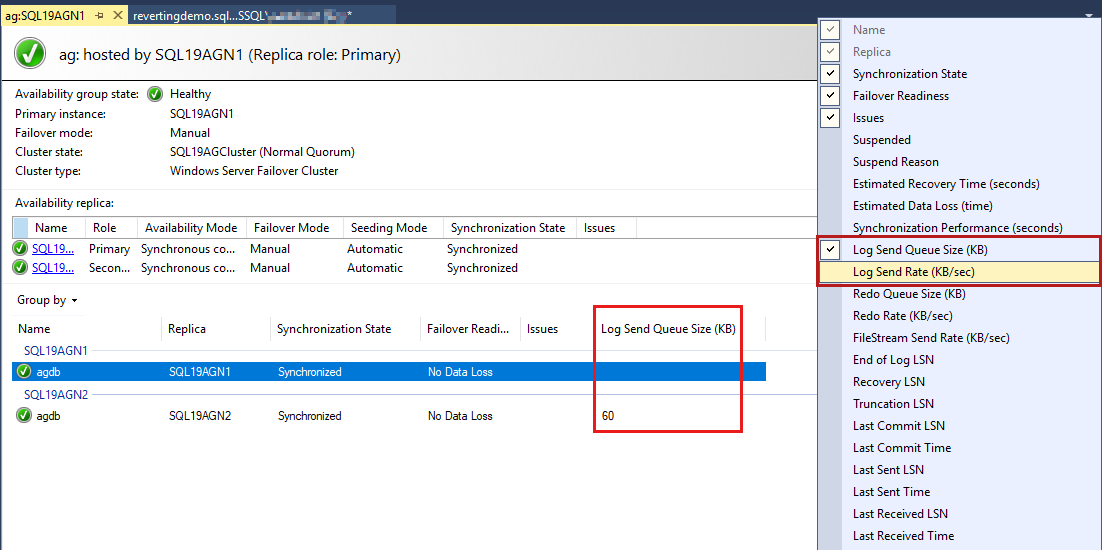
De forma predeterminada, el panel de Always On actualiza automáticamente estos datos cada 60 segundos.
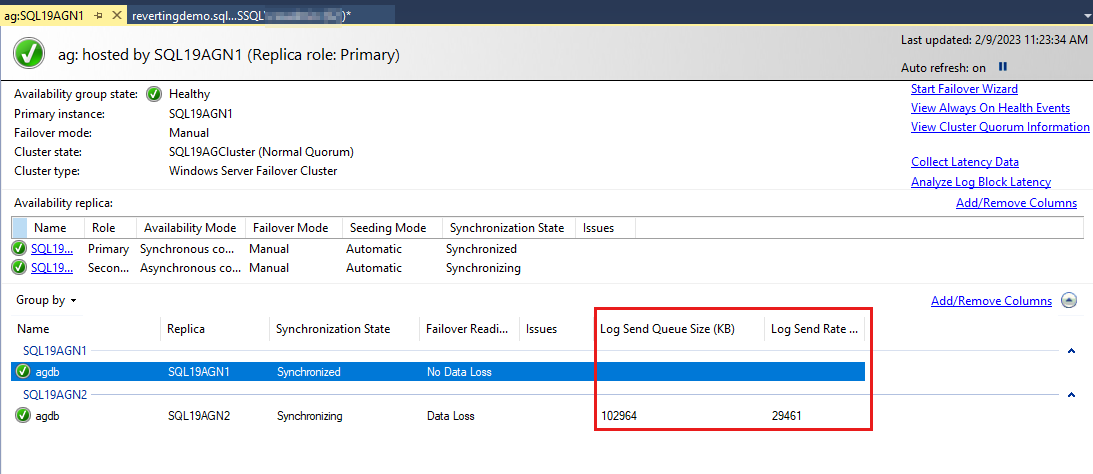


Revise la cola de envío de registros en Monitor de rendimiento
La cola de envío de registros es específica de cada base de datos de réplica secundaria. Por lo tanto, para revisar la cola de envío de registros de una base de datos de grupo de disponibilidad, siga estos pasos:
Abra Monitor de rendimiento en la réplica secundaria.
Seleccione el botón Agregar (contador).
En Contadores disponibles, seleccione los contadores SQLServer:Réplica de base de datos y Cola de envío de registros .
En el cuadro de lista Instancia , seleccione la base de datos del grupo de disponibilidad que desea comprobar para la cola de envío de registros.
Seleccione Agregar y Aceptar.
Este es el aspecto que podría tener el aumento de la cola de envío de registros.


Interpretación de los valores de envío de colas de registros
En esta sección se explica cómo interpretar los valores del tamaño de la cola de envío de registros.
¿Cuándo es incorrecta la cola de envío de registros? ¿Cuánta cola de envío de registros debe tolerarse?
Puede suponer que si la cola de envío de registros notifica un valor de 0, esto significa que no se está realizando ninguna cola de envío de registros en el momento de ese informe. Sin embargo, cuando el entorno de producción está ocupado, debe esperar observar que la cola de envío de registros notifica con frecuencia un valor distinto de cero incluso en un entorno AlwaysOn correcto. Durante la producción típica, debe esperar observar que este valor fluctúa entre 0 y un valor distinto de cero.
Si observa un aumento de la cola de envíos de registros con el tiempo, se garantiza una investigación adicional. Esta actividad adicional indica que algo ha cambiado. Si observa un crecimiento repentino en la cola de envío de registros, las siguientes medidas son útiles para solucionar problemas:
- Velocidad de envío de registros (KB/s) (panel AlwaysOn)
- sys.dm_hadr_database_replica_states (DMV)
- Réplica de base de datos::Transacciones reflejadas/s (Monitor de rendimiento)
Obtención de las tasas de línea base para la tasa de envío de registros y las transacciones reflejadas por segundo
Durante el rendimiento de AlwaysOn correcto, supervise la tasa de envío de registros y los valores reflejados de transacciones por segundo para las bases de datos de grupos de disponibilidad ocupados. ¿Qué aspecto tienen durante las horas de trabajo normalmente ocupadas? ¿Qué aspecto tienen durante los períodos de mantenimiento, cuando las transacciones grandes impulsan un mayor rendimiento de las transacciones en el sistema? Puede comparar estos valores al observar el crecimiento de la cola de envío de registros para ayudar a determinar lo que ha cambiado. La carga de trabajo puede ser mayor de lo habitual. Si la tasa de envío de registros es menor de lo habitual, es posible que sea necesaria una investigación adicional para determinar por qué.
Los volúmenes de carga de trabajo son importantes
Cuando tiene cargas de trabajo grandes (como una UPDATE instrucción en 1 millón de filas, una recompilación de índices en una tabla de 1 terabyte o incluso un lote ETL que inserta millones de filas), debería esperar ver algún crecimiento de la cola de envío de registros, ya sea inmediatamente o con el tiempo. Esto se espera cuando se realiza un gran número de cambios repentinamente en la base de datos del grupo de disponibilidad.
Diagnóstico de colas de envío de registros
Después de identificar la cola de envío de registros para una base de datos de grupo de disponibilidad específica, debe comprobar varias causas principales diferentes del problema, como se describe en las secciones siguientes.
Importante
Para obtener una salida de tipo de espera significativa, compruebe si hay un aumento en la cola de envío de registros mediante uno de los métodos que se describen en las secciones anteriores al supervisar las condiciones siguientes.
El sistema está demasiado ocupado
Compruebe si la carga de trabajo de la réplica principal sobrecarga las CPU del sistema. Si ve un aumento en la cola de envío de registros, consulte la sys.dm_os_schedulers DMV y supervise high runnable_tasks_count. Este recuento indica las tareas pendientes que se ejecutaron en ese momento.
SELECT scheduler_address, scheduler_id, cpu_id, status, current_tasks_count, runnable_tasks_count, current_workers_count, active_workers_count
FROM sys.dm_os_schedulers
En la tabla siguiente se muestra un ejemplo de resultados. Un aumento en el runnable_tasks_count valor indica que un gran número de tareas están esperando el tiempo de CPU.
| scheduler_address | scheduler_id | cpu_id | status | current_tasks_count | runnable_tasks_count | current_workers_count | active_workers_count |
|---|---|---|---|---|---|---|---|
| 0x000002778D 200040 | 0 | 0 | VISIBLE SIN CONEXIÓN | 1 | 0 | 2 | 1 |
| 0x000002778D 220040 | 1 | 1 | VISIBLE ONLINE | 108 | 12 | 115 | 107 |
| 0x000002778D 240040 | 2 | 2 | VISIBLE ONLINE | 113 | 2 | 123 | 113 |
| 0x000002778D 260040 | 3 | 3 | VISIBLE ONLINE | 105 | 11 | 116 | 105 |
| 0x000002778D 480040 | 4 | 4 | VISIBLE ONLINE | 108 | 15 | 117 | 108 |
| 0x000002778D 4A0040 | 5 | 5 | VISIBLE ONLINE | 100 | 25 | 110 | 99 |
| 0x000002778D 4C0040 | 6 | 6 | VISIBLE ONLINE | 105 | 23 | 113 | 105 |
| 0x000002778D 4E0040 | 7 | 7 | VISIBLE | 109 | 25 | 116 | 109 |
| 0x000002778D 700040 | 8 | 8 | VISIBLE ONLINE | 98 | 10 | 112 | 98 |
| 0x000002778D 720040 | 9 | 9 | VISIBLE ONLINE | 114 | 1 | 130 | 114 |
| 0x000002778D 740040 | 10 | 10 | VISIBLE ONLINE | 110 | 25 | 120 | 110 |
| 0x000002778D 760040 | 11 | 11 | VISIBLE ONLINE | 83 | 8 | 93 | 83 |
| 0x000002778D A00040 | 12 | 12 | VISIBLE ONLINE | 104 | 4 | 117 | 104 |
| 0x000002778D A20040 | 13 | 13 | VISIBLE ONLINE | 108 | 32 | 118 | 108 |
| 0x000002778D A40040 | 14 | 14 | VISIBLE ONLINE | 102 | 12 | 113 | 102 |
| 0x000002778D A60040 | 15 | 15 | VISIBLE ONLINE | 104 | 16 | 116 | 103 |
Solución: si detecta alta runnable_task_count, reduzca la carga de trabajo en el sistema o aumente el número de CPU disponibles para el sistema.
Latencia de red
Esta condición es especialmente común si la réplica secundaria es físicamente remota desde la réplica principal. Los grupos de disponibilidad de varios sitios permiten a los clientes implementar copias de datos empresariales en varios sitios para la recuperación ante desastres y los informes. Esto hace que los cambios casi en tiempo real estén disponibles para las copias de los datos de producción en ubicaciones remotas.
Si una réplica secundaria está hospedada lejos de la réplica principal, la cola de envío de registros puede deberse a la latencia de red y a la imposibilidad de enviar cambios a la réplica secundaria remota tan rápido como se producen en la base de datos de réplica principal.
Importante
SQL Server usa una única conexión para sincronizar los cambios de la principal con las réplicas secundarias. Por lo tanto, si una réplica secundaria es remota, el ancho de la canalización no afectará a la cantidad de datos SQL Server puede enviar. En su lugar, esta cantidad depende más de la latencia de red en la canalización (velocidad de conexión).
Prueba de latencia de red
Comprobar si la configuración del control de flujo contribuye a la latencia de red
Los grupos de disponibilidad de Microsoft SQL Server usan puertas de control de flujo para evitar el consumo excesivo de recursos de red, memoria y otros recursos en todas las réplicas de disponibilidad. Estas puertas de control de flujo no afectan al estado de mantenimiento de sincronización de las réplicas de disponibilidad. Sin embargo, pueden afectar al rendimiento general de las bases de datos de disponibilidad, incluido RPO.
Las versiones posteriores de SQL Server cambiar los umbrales en los que se escribe el control de flujo. Esto puede ayudar a aliviar el efecto que tiene el control de flujo en síntomas como la cola de envío de registros. Para obtener más información sobre el control de flujo y el historial de cambios en los umbrales de control de flujo, consulte Puertas de control de flujo.
Puede supervisar el control de flujo mediante Monitor de rendimiento para capturar datos en la réplica principal. Para supervisar el control de flujo de base de datos, agregue contadores SQLServer:Réplica de base de datos y seleccione los contadores Retraso del control de flujo de base de datos y Controles de flujo de base de datos /s . En el cuadro de diálogo Instancia , seleccione la base de datos del grupo de disponibilidad que desea comprobar para el control de flujo de base de datos. Para detectar y supervisar el control de flujo de réplica de disponibilidad, agregue contadores SQLServer:Availability Replica y seleccione los contadores Flow Control Time (ms/s) y Flow Control/s .
Compruebe si la congestión del reinicio de Windows contribuye a la latencia de red.
Los problemas de rendimiento de red que provocan la cola de envío de registros se pueden desencadenar si la configuración de TCP de reinicio de Windows congestión se establece en True. Esta era la configuración predeterminada en Windows Server 2016. Asegúrese de que El reinicio de la ventana de congestión está establecido en False en los servidores Windows que hospedan réplicas de grupo de disponibilidad en las que se observa la cola de envío de registros.
PS C:\WINDOWS\system32> Get-NetTCPSetting | Select SettingName, CwndRestart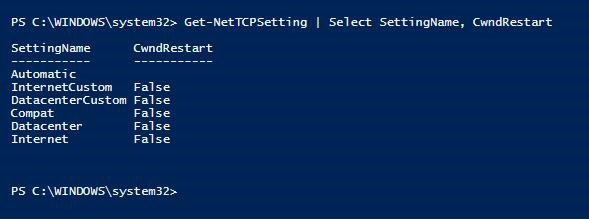
Para obtener más información sobre cómo establecer la propiedad Tcp Congestion Windows Restart en False, vea Set-NetTCPSetting (NetTCPIP).
Consulte también Supervisión del rendimiento de Always On grupos de disponibilidad para obtener información sobre el proceso de sincronización. En este artículo también se muestra cómo calcular algunas de las métricas clave y se proporcionan vínculos a algunos de los escenarios comunes de solución de problemas de rendimiento.
Uso de ping para obtener un ejemplo de latencia
En una línea de comandos en node1 (réplica principal), ping node2 (réplica secundaria):
C:\Users\customer>ping node2 Pinging node2.customer.corp.company.com [<ip address>] with 32 bytes of data: Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=97ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=119ms Ping statistics for 2<ip address>: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 94ms, Maximum = 119ms, Average = 101msPrueba del rendimiento de red de principal a secundario mediante una herramienta independiente
Use una herramienta como NTttcp para detectar de forma independiente el rendimiento de red entre las réplicas principal y secundaria mediante una única conexión. La latencia de red es una causa común de la cola de envío de registros. En los pasos siguientes se muestra cómo usar una herramienta independiente, como NTttcp, para medir el rendimiento de la red.
Importante
SQL Server envía los cambios de la réplica principal a la réplica secundaria mediante una única conexión. En la sección siguiente, configuramos y ejecutamos NTttcp para usar una única conexión (de la misma manera que SQL Server) para comparar el rendimiento con precisión.
Puede descargar NTttcp desde Github: microsoft/ntttcp.
Para ejecutar NTttcp, siga estos pasos:
Descargue y copie la herramienta en los servidores basados en SQL Server principal y secundario.
En el servidor de réplica secundario, abra una ventana del símbolo del sistema con privilegios elevados, cambie el directorio a la carpeta de herramientas NTttcp y, a continuación, ejecute el siguiente comando:
ntttcp.exe -r -m 1,0,<secondaryipaddress>-a 16 -t 60Nota:
En este comando,
<secondaryipaddress>es un marcador de posición para la dirección IP real del servidor de réplica secundario.En el servidor de réplica principal, abra una ventana del símbolo del sistema con privilegios elevados, cambie el directorio a la carpeta de herramientas NTttcp y, a continuación, ejecute el siguiente comando especificando de nuevo la dirección IP real del servidor de réplica secundario:
ntttcp.exe -s -m 1,0,<secondaryipaddress>-a 16 -t 60En las capturas de pantalla siguientes se muestra NTttcp en ejecución en las réplicas secundarias y principales. Debido a la latencia de red, la herramienta solo puede enviar 739 KB/s de datos. Eso es lo que puede esperar que SQL Server pueda enviar.
NTttcp en réplica secundaria
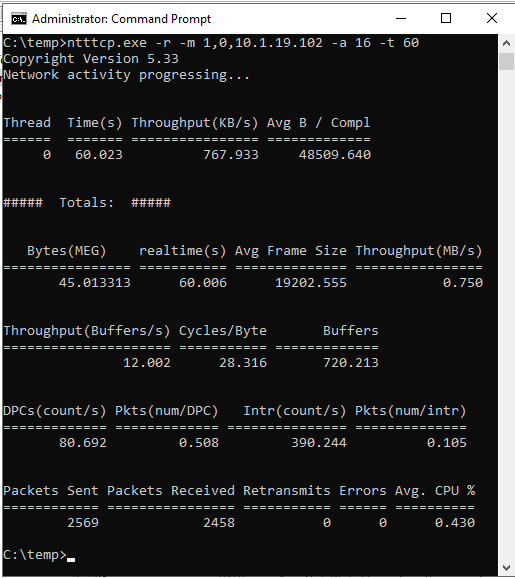
NTttcp en la réplica principal
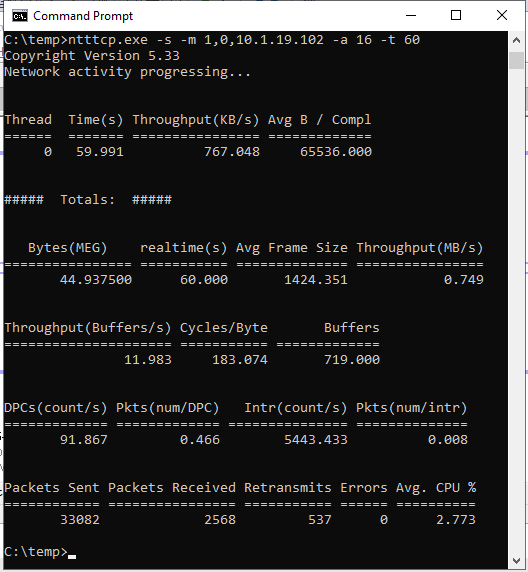
Revisar los contadores de Monitor de rendimiento
Compruebe qué informes de NTttcp. Una transacción de gran tamaño se ejecuta en SQL Server en la réplica principal. Después de iniciar Monitor de rendimiento en la réplica principal, agregue el contador Network Interface::Bytes Sent/s. Este contador confirma que la réplica principal puede enviar aproximadamente 777 KB/s de datos. Esto es similar al valor de 739 KB/s notificado por la prueba de NTttcp.

También es útil comparar el valor SQL Server::D atabases::Log Bytes Flushed/s en la réplica principal con SQL Server::D atabase Replica::Log Bytes Received/s para la misma base de datos en la réplica secundaria. En promedio, observamos aproximadamente 20 MB/s de cambios que se crean en la base de datos "agdb". Sin embargo, la réplica secundaria recibe, de media, solo 5,4 MB de cambios. Esto hará que el envío de registros se ponga en cola en la réplica principal de los cambios pendientes en el registro de transacciones de base de datos que aún no se han enviado a la réplica secundaria.
Bytes de registro de réplica principal vaciados por segundo para la base de datos "agdb"

Bytes de registro de réplica secundaria recibidos/s para la base de datos agdb

Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de