Solución de problemas de Espacios de almacenamiento directo
Se aplica a: Azure Stack HCI, versiones 22H2 y 21H2, Windows Server 2022, Windows Server 2019 y Windows Server 2016
Use la información de este artículo para solucionar problemas de implementación de Espacios de almacenamiento directo.
En general, comience con estos pasos:
- Confirme que la marca y el modelo de SSD esté certificada para Windows Server 2016 y Windows Server 2019 mediante Windows Server Catalog. Confirme con el proveedor que las unidades sean compatibles con Espacios de almacenamiento directo.
- Inspeccione el almacenamiento de las unidades defectuosas. Use el software de administración de almacenamiento para comprobar el estado de las unidades. Si alguna de las unidades es defectuosa, contacte con su proveedor.
- Actualice el firmware del almacenamiento y de la unidad si fuera necesario. Asegúrese de que las actualizaciones de Windows más recientes estén instaladas en todos los nodos. Es posible obtener las actualizaciones más recientes de Windows Server 2016 desde el historial de actualizaciones de Windows 10 y Windows Server 2016. Obtenga las actualizaciones más recientes de Windows Server 2019 desde el historial de actualizaciones de Windows 10 y Windows Server 2019.
- Actualice el firmware y los controladores del adaptador de red.
- Ejecute la validación del clúster y revise la sección Espacio de almacenamiento directo. Asegúrese de que las unidades que usa para la memoria caché se notifiquen correctamente y no tengan errores.
Si sigue teniendo problemas, revise la información de solución de problemas de cada uno de los problemas específicos de este artículo.
Recursos de disco virtual en estado Sin redundancia
Los nodos de un sistema de Espacios de almacenamiento directo se reinician inesperadamente debido a un bloqueo o un error de alimentación. Por tanto, es posible que uno o varios de los discos virtuales no se conecten y aparezca la descripción Información de redundancia insuficiente.
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Size | PSComputerName |
|---|---|---|---|---|---|---|
| Disk4 | Reflejo | Aceptar | Healthy | True | 10 TB | Node-01.conto... |
| Disk3 | Reflejo | Aceptar | Healthy | True | 10 TB | Node-01.contoso. |
| Disk2 | Reflejo | Sin redundancia | Unhealthy (Incorrecto) | True | 10 TB | Node-01.contoso. |
| Disco1 | Reflejo | {Sin redundancia, InService} | Unhealthy (Incorrecto) | True | 10 TB | Node-01.contoso. |
Además, después de intentar conectar el disco virtual, la siguiente información se registra en el registro del clúster, DiskRecoveryAction.
[Verbose] 00002904.00001040::YYYY/MM/DD-12:03:44.891 INFO [RES] Physical Disk <DiskName>: OnlineThread: SuGetSpace returned 0.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 WARN [RES] Physical Disk < DiskName>: Underlying virtual disk is in 'no redundancy' state; its volume(s) may fail to mount.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 ERR [RES] Physical Disk <DiskName>: Failing online due to virtual disk in 'no redundancy' state. If you would like to attempt to online the disk anyway, first set this resource's private property 'DiskRecoveryAction' to 1. We will try to bring the disk online for recovery, but even if successful, its volume(s) or CSV may be unavailable.
El estado operativo Sin redundancia puede ocurrir si se produce un error en un disco o si el sistema no pudiera acceder a los datos del disco virtual. Este problema puede ocurrir si un nodo se reinicia durante el mantenimiento en los nodos.
Siga estos pasos para solucionar este problema:
Quite los discos virtuales afectados del CSV. Al hacerlo, los colocará en el grupo de almacenamiento disponible en el clúster y comenzará a mostrarse como ResourceType de
Physical Disk.Remove-ClusterSharedVolume -Name "CSV Name"En el nodo que posee el grupo Almacenamiento disponible, ejecute el siguiente comando en cada disco que tenga el estado Sin redundancia. Para identificar en qué nodo está activado el grupo Almacenamiento disponible, puede ejecutar este comando:
Get-ClusterGroupEstablezca la acción de recuperación de disco e inicie el disco o los discos.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 1 Start-ClusterResource -Name "Physical Disk Resource Name"Se debe iniciar automáticamente una reparación. Espere a que finalice la reparación. Podría pasar a un estado suspendido e iniciarse de nuevo. Para supervisar el progreso:
- Ejecute
Get-StorageJobpara supervisar el estado de la reparación y ver en qué momento se ha completado. - Ejecute
Get-VirtualDisky compruebe que el espacio devuelva un valor HealthStatus de Correcto.
- Ejecute
Al finalizar la reparación y estar los discos virtuales en estado Correcto, vuelva a cambiar los parámetros del disco virtual.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 0Desconecte los discos y vuelva a conectarlos para que el
DiskRecoveryActionsurta efecto:Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"Vuelva a agregar los discos virtuales afectados al CSV.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"
DiskRecoveryAction es un modificador de invalidación que permite adjuntar el volumen Espacio en modo de lectura y escritura sin comprobaciones. La propiedad le permite diagnosticar por qué un volumen no está en línea. Es similar al modo de mantenimiento, pero puede invocarlo en un recurso en estado erróneo. También le permitirá acceder a los datos para que pueda copiarlos. Este acceso es útil en situaciones sin redundancia. La propiedad DiskRecoveryAction se agregó el 22 de febrero de 2018, en la actualización KB 4077525.
Estado desasociado en un clúster
Al ejecutar el cmdlet Get-VirtualDisk, el OperationalStatus de uno o varios discos virtuales de Espacios de almacenamiento directo se desasociará. Sin embargo, el HealthStatus que informa el cmdlet Get-PhysicalDisk indica que todos los discos físicos están en estado Correcto.
En este ejemplo se muestra la salida del cmdlet Get-VirtualDisk.
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Size | PSComputerName |
|---|---|---|---|---|---|---|
| Disk4 | Reflejo | Aceptar | Healthy | True | 10 TB | Node-01.contoso. |
| Disk3 | Reflejo | Aceptar | Healthy | True | 10 TB | Node-01.contoso. |
| Disk2 | Reflejo | Separada | Unknown | True | 10 TB | Node-01.contoso. |
| Disco1 | Reflejo | Separada | Unknown | True | 10 TB | Node-01.contoso. |
Además, es posible que los siguientes eventos se registren en los nodos:
Log Name: Microsoft-Windows-StorageSpaces-Driver/Operational
Source: Microsoft-Windows-StorageSpaces-Driver
Event ID: 311
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: Virtual disk {GUID} requires a data integrity scan.
Data on the disk is out-of-sync and a data integrity scan is required.
To start the scan, run this command:
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask
Once you have resolved that condition, you can online the disk by using these commands in PowerShell:
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsReadOnly $false
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsOffline $false
------------------------------------------------------------
Log Name: System
Source: Microsoft-Windows-ReFS
Event ID: 134
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: The file system was unable to write metadata to the media backing volume <VolumeId>. A write failed with status "A device which does not exist was specified." ReFS will take the volume offline. It might be mounted again automatically.
------------------------------------------------------------
Log Name: Microsoft-Windows-ReFS/Operational
Source: Microsoft-Windows-ReFS
Event ID: 5
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: ReFS failed to mount the volume.
Context: 0xffffbb89f53f4180
Error: A device which does not exist was specified.
Volume GUID:{00000000-0000-0000-0000-000000000000}
DeviceName:
Volume Name:
El Detached Operational Status se producirá si el seguimiento de regiones sucias (DRT) estuviera lleno. Espacios de almacenamiento usa el seguimiento de regiones sucias (DRT) para espacios reflejados para asegurarse de que, cuando se produzca un error de alimentación, se registren las actualizaciones en curso de los metadatos. Las actualizaciones registradas garantizan que el espacio de almacenamiento pueda rehacer o deshacer operaciones. Devuelven el espacio de almacenamiento a un estado flexible y coherente después de las restauraciones de energía y el sistema vuelve a subir. Si el registro de DRT está lleno, el disco virtual no se puede conectar hasta que los metadatos de DRT se sincronicen y vacíen. Este proceso requiere la ejecución de un examen completo que puede tardar varias horas en finalizar.
Siga estos pasos para solucionar este problema:
Quite los discos virtuales afectados del CSV.
Remove-ClusterSharedVolume -Name "CSV Name"Ejecute estos comandos en todos los discos que no se conecten.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 7 Start-ClusterResource -Name "Physical Disk Resource Name"Ejecute el siguiente comando en cada nodo en el que el volumen desasociado esté conectado.
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTaskInicie esta tarea en todos los nodos en los que el volumen desasociado esté en línea. Se debe iniciar automáticamente una reparación. Espere a que finalice la reparación. Podría pasar a un estado suspendido e iniciarse de nuevo. Para supervisar el progreso:
- Ejecute
Get-StorageJobpara supervisar el estado de la reparación y ver en qué momento se ha completado. - Ejecute
Get-VirtualDisky compruebe que Espacio devuelva un valor HealthStatus de Correcto.El examen de integridad de datos para la recuperación de bloqueos es una tarea que no se muestra como un trabajo de almacenamiento y no hay ningún indicador de progreso. Si la tarea se muestra como en ejecución, significa que se está ejecutando. Cuando se complete, se mostrará como completada.
Además, puede ver el estado de una tarea de programación en ejecución mediante este cmdlet:
Get-ScheduledTask | ? State -eq running
- Ejecute
Una vez completado el examen de integridad de datos para la recuperación de bloqueos, se finalizará la reparación y los discos virtuales estarán en buen estado. Vuelva a cambiar los parámetros del disco virtual.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 0Desconecte los discos y vuelva a conectarlos para que el
DiskRecoveryActionsurta efecto:Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"Vuelva a agregar los discos virtuales afectados al CSV.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"Use
DiskRunChkdsk value 7para adjuntar el volumen Espacio y establecer la partición en modo de solo lectura. Esta acción permite a los espacios autodescubrirse y autosanarse al desencadenar una reparación. La reparación se ejecutará automáticamente tras el montaje. También le permitirá acceder a los datos para copiarlos. Para algunas condiciones de error, como un registro de DRT completo, debe ejecutar la tarea programada de examen de integridad de datos para la recuperación de bloqueos.
Use la tarea Análisis de integridad de datos para la recuperación de bloqueos para sincronizar y borrar registros completos de seguimiento de regiones desfasadas (DRT). Esta tarea puede tardar varias horas en completarse. El examen de integridad de datos para la recuperación de bloqueos es una tarea que no se muestra como un trabajo de almacenamiento y no hay ningún indicador de progreso. Si la tarea se muestra como en ejecución, significa que se está ejecutando. Cuando se complete, se mostrará como completada. Si cancela la tarea o reinicia un nodo mientras se ejecuta esta tarea, la tarea tendrá que volver a empezar desde el principio.
Para obtener más información, consulte Solución de problemas de Espacios de almacenamiento directo en estados operativos y de mantenimiento.
Evento 5120 con STATUS_IO_TIMEOUT c00000b5
Importante
Windows Server 2016: para reducir la posibilidad de experimentar estos síntomas al aplicar la actualización con la corrección, se recomienda usar el procedimiento de modo de mantenimiento de almacenamiento para instalar la actualización acumulativa del 18 de octubre de 2018 para Windows Server 2016 o una versión posterior cuando los nodos hayan instalado una actualización acumulativa de Windows Server 2016 publicada desde el 8 de mayo de 2018 al 9 de octubre de 2018.
Es posible que obtenga el evento 5120 con STATUS_IO_TIMEOUT c00000b5 después de reiniciar un nodo en Windows Server 2016 con la actualización acumulativa publicada desde el 8 de mayo de 2018 KB 4103723 hasta el 9 de octubre de 2018 KB 4462917 instalada.
Al reiniciar el nodo, el evento 5120 se registra en el registro de eventos del sistema e incluye uno de estos códigos de error:
Event Source: Microsoft-Windows-FailoverClustering
Event ID: 5120
Description: Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_IO_TIMEOUT(c00000b5)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_CONNECTION_DISCONNECTED(c000020c)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Cuando se registra un evento 5120, un volcado en vivo se genera para recopilar información de depuración que puede causar otros síntomas o afectar al rendimiento. Cuando se genera el volcado en vivo, se produce una breve pausa. La pausa permite que una instantánea de memoria escriba el archivo de volcado. Los sistemas con una gran cantidad de memoria y bajo estrés podrían provocar que los nodos se quiten de la pertenencia al clúster y provoquen que se registre el siguiente evento 1135.
Event source: Microsoft-Windows-FailoverClustering
Event ID: 1135
Description: Cluster node 'NODENAME'was removed from the active failover cluster membership. The Cluster service on this node might have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Un cambio introducido el 8 de mayo de 2018 en Windows Server 2016 era una actualización acumulativa para agregar controladores resistentes de SMB para las sesiones de red SMB dentro del clúster de Espacios de almacenamiento directo. Esta actualización se hizo para mejorar la resistencia a los errores de red transitorios y mejorar la forma en que RoCE controla la congestión de la red. Estas mejoras también aumentaron accidentalmente los tiempos de espera cuando las conexiones del SMB intentan volver a conectarse y esperan a que se agote el tiempo de espera cuando se reinicia un nodo. Estos problemas pueden afectar a un sistema que tenga estrés. Durante los periodos de inactividad no planeados, también se han observado pausas en la E/S de hasta 60 segundos mientras el sistema espera a que se agote el tiempo de espera de las conexiones. Para solucionar este problema, instale la actualización acumulativa del 18 de octubre de 2018 para Windows Server 2016, o cualquier versión posterior.
Nota
Esta actualización alinea los tiempos de espera de CSV con los tiempos de espera de conexión SMB para corregir este problema. No implementa los cambios para deshabilitar la generación de volcados en vivo que se mencionan en la sección Solución alternativa.
Flujo del proceso de apagado
Ejecute el cmdlet Get-VirtualDisk y compruebe que el HealthStatus es Correcto.
Para purgar el nodo, ejecute este cmdlet:
Suspend-ClusterNode -DrainColoque los discos en ese nodo en modo de mantenimiento de almacenamiento mediante la ejecución de este cmdlet:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Enable-StorageMaintenanceModeEjecute el cmdlet
Get-PhysicalDisky asegúrese de que el valor deOperationalStatussea esté en el modoIn Maintenance.Ejecute el cmdlet
Restart-Computerpara reiniciar el nodo.Una vez reiniciado el nodo, quite los discos de ese nodo del modo de mantenimiento de almacenamiento mediante la ejecución de este cmdlet:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Disable-StorageMaintenanceModePara reanudar el nodo, ejecute este cmdlet:
Resume-ClusterNodePara comprobar el estado de los trabajos de resincronización, ejecute este cmdlet:
Get-StorageJob
Deshabilitación de volcados dinámicos
Para mitigar los efectos de la generación de volcados en vivo en sistemas con una gran cantidad de memoria y bajo estrés, puede deshabilitar la generación de volcados en vivo. Se proporcionan estas tres opciones:
Precaución
Este procedimiento puede impedir la recopilación de información de diagnóstico que el soporte técnico de Microsoft podría necesitar para investigar este problema. Es posible que un agente del soporte técnico le pida que vuelva a habilitar la generación de volcados dinámicos en función de escenarios de solución de problemas específicos.
Deshabilitar todos los volcados
Para deshabilitar completamente todos los volcados, incluyendo los volcados dinámicos en todo el sistema, siga estos pasos. Use este procedimiento para este escenario:
- Cree la siguiente clave del registro: HKLM\System\CurrentControlSet\Control\CrashControl\ForceDumpsDisabled
- En la nueva clave ForceDumpsDisabled, cree una propiedad REG_DWORD como GuardedHost y, a continuación, establezca su valor en 0x10000000.
- Aplique la nueva clave del registro a cada nodo de clúster.
Nota
Debe reiniciar el equipo para que el cambio de nregistry surta efecto.
Una vez establecida esta clave del registro, se producirá un error en la creación del volcado dinámico y se generará un error STATUS_NOT_SUPPORTED.
Permitir solo un LiveDump
De forma predeterminada, Informe de errores de Windows no permite más de una instancia de LiveDump por tipo de informe cada siete días y solo una instancia de LiveDump por equipo cada cinco días. Puede cambiarlo; para ello, establezca las siguientes claves del registro para que solo permita liveDump en el equipo para siempre.
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v SystemThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v ComponentThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
Nota
Debe reiniciar el equipo para que el cambio surta efecto.
Deshabilitar la generación de clústeres
Para deshabilitar la generación de clústeres de volcados dinámicos (por ejemplo, cuando se registre un evento 5120), ejecute este cmdlet:
(Get-Cluster).DumpPolicy = ((Get-Cluster).DumpPolicy -Band 0xFFFFFFFFFFFFFFFE)
Este cmdlet tiene un efecto inmediato en todos los nodos del clúster sin reiniciar el equipo.
Rendimiento de E/S lento
Si percibe que el rendimiento de E/S es lento, compruebe si la caché está habilitada en la configuración de Espacios de almacenamiento directo.
Hay dos formas de comprobarlo:
Use el registro del clúster. Abra el registro del clúster con un editor de texto de su elección y busque "[=== Discos SBL ===]". Verá una lista del disco en el nodo en el que se generó el registro.
Ejemplo de discos habilitados para caché: observe que el estado es
CacheDiskStateInitializedAndBoundy hay un GUID presente aquí.[=== SBL Disks ===] {26e2e40f-a243-1196-49e3-8522f987df76},3,false,true,1,48,{1ff348f1-d10d-7a1a-d781-4734f4440481},CacheDiskStateInitializedAndBound,1,8087,54,false,false,HGST,HUH721010AL4200,7PG3N2ER,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Caché no habilitada: aquí se puede ver que no hay ningún GUID presente y que el estado es
CacheDiskStateNonHybrid.[=== SBL Disks ===] {426f7f04-e975-fc9d-28fd-72a32f811b7d},12,false,true,1,24,{00000000-0000-0000-0000-000000000000},CacheDiskStateNonHybrid,0,0,0,false,false,HGST,HUH721010AL4200,7PGXXG6C,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Caché no habilitada: cuando todos los discos son del mismo tipo, el caso no está habilitado de forma predeterminada. Aquí puede ver que no hay ningún GUID presente y el estado es
CacheDiskStateIneligibleDataPartition.{d543f90c-798b-d2fe-7f0a-cb226c77eeed},10,false,false,1,20,{00000000-0000-0000-0000-000000000000},CacheDiskStateIneligibleDataPartition,0,0,0,false,false,NVMe,INTEL SSDPE7KX02,PHLF7330004V2P0LGN,0170,{79b4d631-976f-4c94-a783-df950389fd38},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Mediante Get-PhysicalDisk.xml del SDDCDiagnosticInfo.
- Abra el archivo XML mediante "$d = Import-Clixml GetPhysicalDisk.XML".
- Ejecute
ipmo storage. - Ejecute
$d. Tenga en cuenta que Uso es Selección automática, no Diario.
Debería ver una salida similar a esta:
FriendlyName SerialNumber MediaType CanPool OperationalStatus HealthStatus Uso Size NVMe INTEL SSDPE7KX02 PHLF733000372P0LGN SSD False Aceptar Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7504008J2P0LGN SSD False Aceptar Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7504005F2P0LGN SSD False Aceptar Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7504002A2P0LGN SSD False Aceptar Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7504004T2P0LGN SSD False Aceptar Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7504002E2P0LGN SSD False Aceptar Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7330002Z2P0LGN SSD False Aceptar Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF733000272P0LGN SSD False Aceptar Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7330001J2P0LGN SSD False Aceptar Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF733000302P0LGN SSD False Aceptar Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7330004D2P0LGN SSD False Aceptar Healthy Auto-Select 1.82 TB
Cómo destruir un clúster existente para poder volver a usar los mismos discos
En un clúster de Espacios de almacenamiento directo, deshabilite Espacios de almacenamiento directo y use el proceso de limpieza descrito en Limpiar unidades. El grupo de almacenamiento de clúster sigue estando en estado Sin conexión y el servicio de mantenimiento se quita del clúster.
El siguiente paso es quitar el grupo de almacenamiento fantasma:
Get-ClusterResource -Name "Cluster Pool 1" | Remove-ClusterResource
Ahora, si ejecuta Get-PhysicalDisk en cualquiera de los nodos, verá todos los discos que estaban en el grupo. Por ejemplo, en un laboratorio con un clúster de cuatro nodos con cuatro discos SAS, cada uno presenta 100 GB a cada nodo. En ese caso, después de deshabilitar espacio de almacenamiento directo, el cual que quita el SBL (capa de bus de almacenamiento) pero mantiene el filtro, si ejecuta Get-PhysicalDisk, debe notificar 4 discos excepto el disco del sistema operativo local. En su lugar, informó 16. Este comportamiento es el mismo para todos los nodos del clúster. Al ejecutar un comando Get-Disk, verá los discos conectados localmente numerados como 0, 1, 2, etc., como se muestra en esta salida de ejemplo:
| Número | Nombre descriptivo | Número de serie | HealthStatus | OperationalStatus | Tamaño total | Estilo de partición |
|---|---|---|---|---|---|---|
| 0 | Msft Virtual | Correcto | En línea | 127 GB | GPT | |
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | ||
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | ||
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | ||
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | ||
| 1 | Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | |
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | ||
| 2 | Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | |
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | ||
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | ||
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | ||
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | ||
| 4 | Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | |
| 3 | Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | |
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | ||
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW | ||
| Msft Virtual | Correcto | Sin conexión | 100 GB | RAW |
Mensaje de error sobre el "tipo de medio no compatible" al crear un clúster de Espacios de almacenamiento directo mediante Enable-ClusterS2D
Es posible que vea errores similares al ejecutar el cmdlet Enable-ClusterS2D:
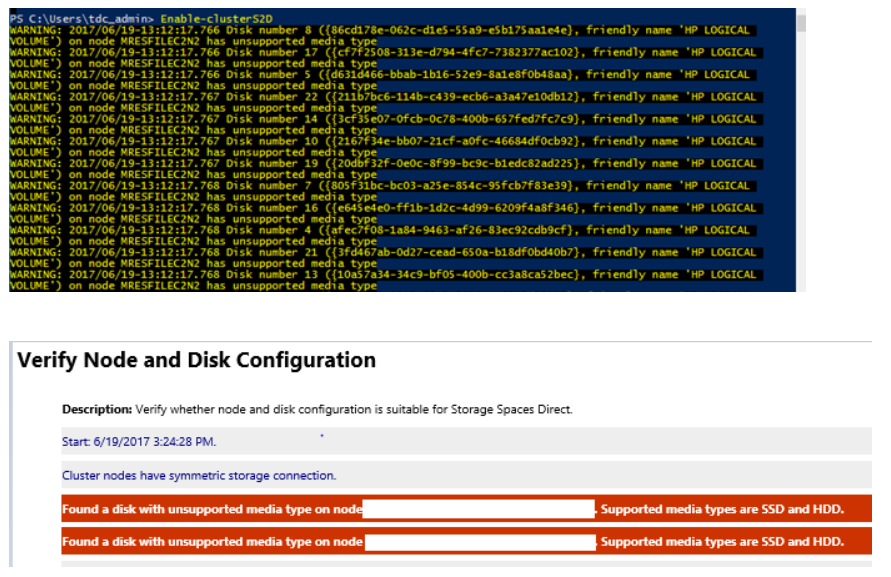
Para corregir este problema, asegúrese de que el adaptador de HBA está configurado en modo HBA. No se debe configurar ningún HBA en modo RAID.
Enable-ClusterStorageSpacesDirect se bloquea en "Esperando hasta que se muestren discos SBL" o al 27 %
Se ve la siguiente información en el informe de validación:
El disco <identifier> conectado al nodo <nodename> devolvió una asociación de puertos SCSI y no se encontró el dispositivo contenedor correspondiente. El hardware no es compatible con Espacios de almacenamiento directo (S2D). Póngase en contacto con el proveedor de hardware para comprobar la compatibilidad con SCSI Enclosure Services (SES).
El problema es con la tarjeta de ampliación HPE SAS que se encuentra entre los discos y la tarjeta HBA. El ampliador SAS crea un identificador duplicado entre la primera unidad conectada al ampliador y al propio ampliador. Esta incidencia se ha resuelto en el firmware 4.02 del ampliador HPE Smart Array Controllers SAS.
La serie INTEL SSD DC P4600 tiene un NGUID no único
Es posible que vea un problema en el que un dispositivo de la serie SSD DC P4600 de Intel parece estar informando de NGUID similar de 16 bytes para varios espacios de nombres, como 0100000001000000E4D25C000014E214 o 0100000001000000E4D25C0000EEE214, en el siguiente ejemplo.
| UniqueId | DeviceID | MediaType | Tipo de bus | SerialNumber | Tamaño | CanPool | FriendlyName | OperationalStatus |
|---|---|---|---|---|---|---|---|---|
| 5000CCA251D12E30 | 0 | HDD | SAS | 7PKR197G | 10000831348736 | False | HGST | HUH721010AL4200 |
| eui.0100000001000000E4D25C000014E214 | 4 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C000014E214 | 5 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C0000EEE214 | 6 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C0000EEE214 | 7 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
Para corregir este problema, actualice el firmware de las unidades Intel a la versión más reciente. se sabe que la versión de firmware QDV101B1 de mayo de 2018 resuelve este problema.
La versión de mayo de 2018 de la herramienta Intel SSD Data Center incluye una actualización de firmware, QDV101B1, para la serie INTEL SSD DC P4600.
HealthStatus para el disco físico y OperationalStatus
En un clúster de Espacios de almacenamiento directo de Windows Server 2016, es posible que vea el valor de HealthStatus de uno o varios discos físicos como Correcto, mientras que OperationalStatus es quitando del grupo, Aceptar.
El estado Quitar del grupo es una intención establecida cuando se llama a Remove-PhysicalDisk, pero se almacena en Estado para mantener el estado y permitir la recuperación si se produjese un error en la operación de eliminación. Puede cambiar manualmente OperationalStatus a Correcto con uno de estos métodos:
- Quite el disco físico del grupo y agréguelo de nuevo.
- Import-Module Clear-PhysicalDiskHealthData.ps1.
- Ejecute el script Clear-PhysicalDiskHealthData.ps1 para borrar la intención. Este script está disponible para su descarga como archivo .txt. Debe guardarlo como archivo ps1 antes de poder ejecutarlo.
Estos son algunos ejemplos que muestran cómo ejecutar el script:
Use el parámetro
SerialNumberpara especificar el disco que necesita establecer en Correcto. Puede obtener el número de serie deWMI MSFT_PhysicalDiskoGet-PhysicalDisk. En este ejemplo se usan ceros para el número de serie.Clear-PhysicalDiskHealthData -Intent -Policy -SerialNumber 000000000000000 -Verbose -ForceUse el parámetro
UniqueIdpara especificar el disco, de nuevo desdeWMI MSFT_PhysicalDiskoGet-PhysicalDisk.Clear-PhysicalDiskHealthData -Intent -Policy -UniqueId 00000000000000000 -Verbose -Force
La copia de archivos es lenta
Es posible que vea que la copia de archivos tarda más de lo esperado cuando se usa el Explorador de archivos para copiar un VHD grande en el disco virtual.
No se recomienda usar el Explorador de archivos, Robocopy o Xcopy para copiar un VHD grande en el disco virtual. Da como resultado un rendimiento más lento del esperado. El proceso de copia no pasa por la pila de Espacios de almacenamiento directo, que se encuentra más abajo en la pila de almacenamiento y, en su lugar, actúa como un proceso de copia local.
Si desea probar el rendimiento de Espacios de almacenamiento directo, se recomienda usar VMFleet y Diskspd para cargar y probar el estrés de los servidores para obtener una línea base y establecer las expectativas del rendimiento de Espacios de almacenamiento directo.
Eventos que se esperan ver en el resto de los nodos durante el reinicio de un nodo
Estos eventos se pueden omitir sin problema alguno:
Event ID 205: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Event ID 203: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Si ejecuta máquinas virtuales de Azure, puede omitir este evento: id. de evento 32: el controlador detectó que el dispositivo \Device\Harddisk5\DR5 tiene habilitada su caché de escritura. Podrían producirse datos dañados.
Rendimiento lento o errores de "Comunicación perdida", "Error de E/S", "Desasociado" o "Sin redundancia" en implementaciones que usan dispositivos NVMe Intel P3x00
Hemos identificado un problema crítico que afecta a algunos usuarios de Espacios de almacenamiento directo que usan hardware basado en la familia Intel P3x00 de dispositivos NVM Express (NVMe) con versiones de firmware anteriores a la "Versión de mantenimiento 8".
Nota
Los OEM individuales podrían tener dispositivos basados en la familia Intel P3x00 de dispositivos NVMe con cadenas de versión de firmware únicas. Póngase en contacto con el OEM para obtener más información sobre la versión más reciente del firmware.
Si usa hardware en una implementación basada en la familia Intel P3x00 de dispositivos NVMe, se recomienda aplicar inmediatamente el firmware disponible más reciente (al menos la versión de mantenimiento 8).