Cómo el sistema de administración de recursos compara etiquetas de idioma
En el tema anterior (Cómo compara y elige recursos el sistema de administración de recursos) se examina la coincidencia de calificadores en general. Este tema se centra con mayor detalle en la coincidencia de etiquetas de idioma.
Introducción
Los recursos con calificadores de etiquetas de idioma se comparan y se puntúan en función de la lista de idiomas del tiempo de ejecución de la aplicación. Para ver las definiciones de las distintas listas de idiomas, consulte Comprender los idiomas de perfil de usuario y los idiomas del manifiesto de la aplicación. La coincidencia con el primer idioma de la lista se produce antes de que se logre la coincidencia con el segundo, incluso para otras variantes regionales. Por ejemplo, se elige un recurso para en-GB en un recurso fr-CA si el idioma en tiempo de ejecución de la aplicación es en-US. Solo si no hay ningún recurso para una forma del inglés (en) es que se elige un recurso para fr-CA (tenga en cuenta que, en ese caso, el idioma predeterminado de la aplicación no se pudo establecer en ninguna forma de inglés).
El mecanismo de puntuación utiliza datos que se incluyen en el registro de subetiquetas BCP-47 y otros orígenes de datos. Permite un gradiente de puntuación con diferentes cualidades de coincidencia y, cuando hay varios candidatos disponibles, selecciona el candidato con la mejor puntuación de coincidencia.
Por lo tanto, puede etiquetar el contenido del idioma en términos genéricos, pero todavía puede especificar contenido específico cuando sea necesario. Por ejemplo, la aplicación puede tener muchas cadenas en inglés que son comunes para los Estados Unidos, Gran Bretaña y otras regiones. El etiquetado de estas cadenas como "en" (inglés) ahorra espacio y sobrecarga de localización. Cuando es necesario hacer distinciones, como en una cadena que contenga la palabra "color/colour", las versiones de Estados Unidos y de Reino Unido se pueden etiquetar por separado mediante las subetiquetas de idioma y región, como "en-US" y "en-GB", respectivamente.
Etiquetas Language
Los idiomas se identifican mediante etiquetas de idioma BCP-47 normalizadas y bien formadas. Los componentes de la subetiqueta se definen en el registro de subetiquetas BCP-47. La estructura normal de una etiqueta de idioma BCP-47 consta de uno o varios de los siguientes elementos de subetiqueta.
- Subetiqueta de idioma (obligatorio).
- Subetiqueta de script (que se puede deducir mediante el valor predeterminado especificado en el registro de subetiquetas).
- Subetiqueta de región (opcional).
- Subetiqueta de variante (opcional).
Es posible que haya elementos de subetiqueta adicionales, pero tendrán un efecto insignificante en la coincidencia de idioma. No hay rangos de idioma definidos mediante el carácter comodín (""), por ejemplo, "en-".
Coincidencia de dos idiomas
Cada vez que Windows compara dos idiomas, normalmente se realiza dentro del contexto de un proceso mayor. Puede estar en el contexto de evaluar varios idiomas, como cuando Windows genera la lista de idiomas de la aplicación (consulte Comprender los idiomas del perfil de usuario y los idiomas del manifiesto de la aplicación). Windows hace esto haciendo coincidir varios idiomas de las preferencias del usuario con los idiomas especificados en el manifiesto de la aplicación. La comparación también puede estar en el contexto de la evaluación del idioma junto con otros calificadores para un recurso determinado. Un ejemplo es cuando Windows resuelve un recurso de archivo determinado en un contexto de recurso determinado; con la ubicación principal del usuario o la escala o DPI actuales del dispositivo como otros factores (además del idioma) que se factorizarán en la selección de recursos.
Cuando se comparan dos etiquetas de idioma, a la comparación se le asigna una puntuación basada en la proximidad de la coincidencia.
| Coincidir con | Score | Ejemplo |
|---|---|---|
| Coincidencia exacta | Highest (el más alto) | en-AU : en-AU |
| Coincidencia de variante (idioma, script, región, variante) | en-AU-variant1 : en-AU-variant1-t-ja | |
| Coincidencia de región (idioma, script, región) | en-AU : en-AU-variant1 | |
| Coincidencia parcial (idioma, script) | ||
| - Coincidencia de región de macros | en-AU : en-053 | |
| - Coincidencia de región neutra | en-AU : en | |
| - Coincidencia de afinidad ortográfica (compatibilidad limitada) | en-AU : en-GB | |
| - Coincidencia de región preferida | en-AU : en-US | |
| - Cualquier coincidencia de región | en-AU : en-CA | |
| Idioma no determinado (cualquier coincidencia de idioma) | en-AU : und | |
| Sin coincidencia (error de coincidencia de script o falta de coincidencia de etiquetas de idioma principal) | Mínima | en-AU : fr-FR |
Coincidencia exacta
Las etiquetas son exactamente iguales (todos los elementos de subetiqueta coinciden). Se puede promover una comparación de este tipo de coincidencia a partir de una coincidencia de variante o región. Por ejemplo, en-US coincide con en-US.
Coincidencia de variante
Las etiquetas coinciden con el idioma, el script, la región y las subetiquetas de variante, pero difieren en algún otro aspecto.
Coincidencia de región
Las etiquetas coinciden con las subetiquetas de idioma, script y región, pero difieren en algún otro aspecto. Por ejemplo, de-DE-1996 coincide con de-DE y en-US-x-Pirate coincide con en-US.
Coincidencias parciales
Las etiquetas coinciden con las subetiquetas de lenguaje y script, pero difieren en la región o en alguna otra subetiqueta. Por ejemplo, en-US coincide con en o en-US coincide con en-*.
Coincidencia de región de macros
Las etiquetas coinciden con las subetiquetas de idioma y script; ambas etiquetas tienen subetiquetas de región, una de las cuales denota una región de macros que abarca la otra región. Las subetiquetas de la región de macros son siempre numéricas y se derivan de los códigos de país y área de la División de Estadísticas de las Naciones Unidas M.49. Para obtener más información sobre cómo abarcar relaciones, consulte Composición de regiones geográficas de macros (continentales), subregiones geográficas y otras agrupaciones económicas seleccionadas.
Nota Los códigos de las Naciones Unidas para "agrupaciones económicas" o "otras agrupaciones" no se admiten en BCP-47.
Nota Una etiqueta con la subetiqueta de región macro "001" se considera equivalente a una etiqueta neutra de región. Por ejemplo, "es-001" y "es" se tratan como sinónimos.
Coincidencia de región neutra
Las etiquetas coinciden con las subetiquetas de idioma y script, y solo una etiqueta tiene una etiqueta de región. Se prefiere una coincidencia principal sobre otras coincidencias parciales.
Coincidencia de afinidad ortográfica
Las etiquetas coinciden con las subetiquetas de idioma y script, y las subetiquetas de región tienen afinidad ortográfica. La afinidad se basa en los datos mantenidos en Windows que definen regiones definidas específicas del idioma, por ejemplo, "en-IE" y "en-GB".
Coincidencia de región preferida
Las etiquetas coinciden con las subetiquetas de idioma y script, y una de las subetiquetas de región es la subetiqueta de región predeterminada para el idioma. Por ejemplo, "fr-FR" es la región predeterminada para la subetiqueta "fr". Por lo tanto, fr-FR es una mejor coincidencia para fr-BE que fr-CA. Esto se basa en los datos mantenidos en Windows que definen una región predeterminada para cada idioma en el que se localiza Windows.
Coincidencia del mismo nivel
Las etiquetas coinciden con las subetiquetas de idioma y script, y ambas tienen subetiquetas de región, pero no se define ninguna otra relación entre ellas. En caso de que haya varias coincidencias del mismo nivel, el último nivel relacionado enumerado será el ganador, en ausencia de una coincidencia mayor.
Idioma no determinado
Un recurso se puede etiquetar como "und" para indicar que coincide con cualquier idioma. Esta etiqueta también se puede usar con una etiqueta de script para filtrar coincidencias basadas en el script. Por ejemplo, "und-Latn" coincidirá con cualquier etiqueta de idioma que use el alfabeto latino. Consulte a continuación para más información.
Error de coincidencia de scripts
Cuando las etiquetas coinciden solo en la etiqueta de idioma principal, pero no en el script, se considera que el par no coincide y se puntúa por debajo del nivel de una coincidencia válida.
Ninguna coincidencia
Las subetiquetas de idioma principal que no coinciden se puntúan por debajo del nivel de una coincidencia válida. Por ejemplo, zh-Hant no coincide con zh-Hans.
Ejemplos
Un idioma de usuario "zh-Hans-CN" (chino simplificado (China)) coincide con los siguientes recursos en el orden de prioridad mostrado. Una X indica que no hay ninguna coincidencia.
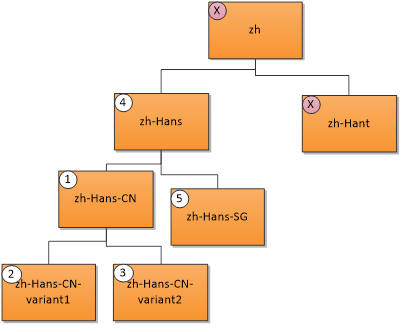
- Coincidencia exacta; 2. Y 3. Coincidencia de región; 4. Coincidencia principal; 5. Coincidencia del mismo nivel.
Cuando una subetiqueta de idioma tiene un valor Suppress-Script definido en el registro de subetiqueta BCP-47, se produce la coincidencia correspondiente, tomando el valor del código de script suprimido. Por ejemplo, en-Latn-US coincide con en-US. En este ejemplo siguiente, el idioma del usuario es "en-AU" (inglés (Australia)).
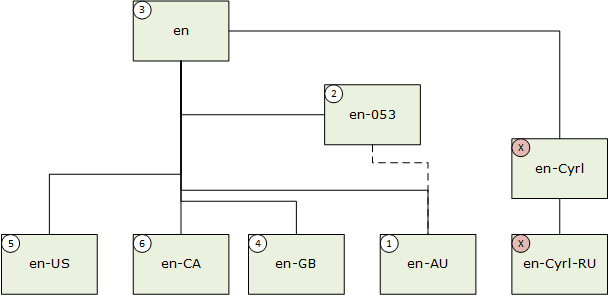
- Coincidencia exacta; 2. Coincidencia de región de macros; 3. Coincidencia de región neutra; 4. Coincidencia de afinidad ortográfica; 5. Coincidencia de región preferida; 6. Coincidencia del mismo nivel.
Coincidencia de un idioma con una lista de idiomas
En ocasiones, la coincidencia se produce como parte de un proceso mayor de coincidencia de un único idioma con una lista de idiomas. Por ejemplo, puede haber una coincidencia de un recurso basado en idioma único en la lista de idiomas de una aplicación. La puntuación de la coincidencia se pondera según la posición del primer idioma coincidente de la lista. Cuanto menor sea el idioma de la lista, menor será la puntuación.
Cuando la lista de idiomas contiene dos o más variantes regionales que tienen las mismas subetiquetas de idioma y script, las comparaciones de la primera etiqueta de idioma solo se puntúan para coincidencias exactas, variantes y regiones. La puntuación de coincidencias parciales se pospone a la última variante regional. Esto permite a los usuarios controlar correctamente el comportamiento coincidente de su lista de idiomas. El comportamiento coincidente puede incluir permitir que se prefiera una coincidencia exacta para un elemento secundario de la lista sobre una coincidencia parcial para el primer elemento de la lista, si hay un tercer elemento que coincida con el idioma y el script del primero. Este es un ejemplo.
- Lista de idiomas (en orden): "pt-PT" (portugués (Portugal)), "en-US" (inglés (Estados Unidos)), "pt-BR" (portugués (Brasil)).
- Recursos: "en-US", "pt-BR".
- Recurso con la puntuación más alta: "en-US".
- Descripción: la comparación comienza con "pt-PT", pero no encuentra una coincidencia exacta. Debido a la presencia de "pt-BR" en la lista de idiomas del usuario, la coincidencia parcial se pospone a la comparación con "pt-BR". La siguiente comparación de idioma es "en-US", que tiene una coincidencia exacta. Por lo tanto, el recurso ganador es "en-US".
O BIEN
- Lista de idiomas (en orden): "es-MX" (Español (México)), "es-HO" (Español (Honduras)).
- Recursos: "en-ES", "es-HO".
- Recurso con la puntuación más alta: "es-HO".
Idioma no determinado ("und")
La etiqueta de idioma "und" se puede usar para especificar un recurso que coincida con cualquier idioma en ausencia de una mejor coincidencia. Se puede considerar similar al intervalo de idioma BCP-47 "" o "-<script>". Este es un ejemplo.
- Lista de idiomas: "en-US", "zh-Hans-CN".
- Recursos: "zh-Hans-CN", "und".
- Recurso con la puntuación más alta: "und".
- Descripción: la comparación comienza por "en-US", pero no encuentra una coincidencia basada en "en" (parcial o mejor). Dado que hay un recurso etiquetado con "und", el algoritmo coincidente lo usa.
La etiqueta "und" permite que varios idiomas compartan un único recurso y permitan que los idiomas individuales se traten como excepciones. Por ejemplo.
- Lista de idiomas: "zh-Hans-CN", "en-US".
- Recursos: "zh-Hans-CN", "und".
- Recurso con la puntuación más alta: "zh-Hans-CN".
- Descripción: la comparación busca una coincidencia exacta para el primer elemento y, por lo tanto, no comprueba si el recurso está etiquetado como "und".
Puede usar "und" con una etiqueta de script para filtrar los recursos por script. Por ejemplo.
- Lista de idiomas: "ru".
- Recursos: "und-Latn", "und-Cyrl", "und-Arab".
- Recurso con la puntuación más alta: "und-Cyrl".
- Descripción: la comparación no encuentra una coincidencia para "ru" (parcial o mejor), por lo que coincide con la etiqueta de idioma "und". El valor suppress-script "Cyrl" asociado a la etiqueta de idioma "ru" coincide con el recurso "und-Cyrl".
Afinidad regional ortográfica
Cuando coinciden dos etiquetas de idioma con diferencias de subetiquetas de región, es posible que determinados pares de regiones tengan una afinidad mayor entre sí que con otras. Los únicos grupos definidos admitidos son para inglés ("en"). Las subetiquetas de región "PH" (Filipinas) y "LR" (Liberia) tienen afinidad ortográfica con la subetiqueta de región "US". Todas las demás subetiquetas de región se definen con la subtag de región "GB" (Reino Unido). Por lo tanto, cuando los recursos "en-US" y "en-GB" están disponibles, una lista de idiomas de "en-HK" (Inglés (RAE de Hong Kong)) obtendrá una puntuación más alta con recursos "en-GB" que con recursos "en-US".
Manejo de idiomas con muchas variantes regionales
Algunos idiomas tienen grandes comunidades de hablantes en diferentes regiones que usan diferentes variedades de ese idioma: idiomas como inglés, francés y español, entre los que se admiten con más frecuencia en aplicaciones multilingües. Las diferencias regionales pueden incluir diferencias en la ortografía (por ejemplo, "color" frente a "colour"), o diferencias de dialecto como el vocabulario (por ejemplo, "truck" frente a "lorry").
Estos lenguajes con variantes regionales significativas presentan ciertos desafíos al crear una aplicación lista para el mundo: "¿Cuántas variantes regionales diferentes se deben admitir?" "¿Cuáles?" "¿Cuál es la manera más rentable de administrar estos recursos de variante regional para mi aplicación?". Responder a todas estas preguntas está fuera del ámbito de este tema. Sin embargo, los mecanismos de coincidencia de idioma de Windows proporcionan funcionalidades que pueden ayudarle a controlar las variantes regionales.
A menudo, las aplicaciones solo admiten una única variedad de idioma determinado. Supongamos que una aplicación tiene recursos solo para una variedad de inglés que se espera que usen los hablantes de inglés independientemente de la región de la que proceden. En este caso, la etiqueta "en" sin ninguna subetiqueta de región reflejaría esa expectativa. Pero las aplicaciones podrían haber usado históricamente una etiqueta como "en-US" que incluye una subetiqueta de región. En este caso, esto también funcionará: la aplicación usa solo una variedad de inglés y Windows controla la coincidencia de un recurso etiquetado para una variante regional con una preferencia de idioma de usuario para una variante regional diferente de una manera adecuada.
Sin embargo, si se van a admitir dos o más variedades regionales, una diferencia como "en" frente a "en-US" puede tener un impacto significativo en la experiencia del usuario y es importante tener en cuenta qué subetiquetas de región utilizar.
Supongamos que desea proporcionar localización de francés independiente para francés como se usa en Canadá frente a francés europeo. Para francés canadiense, se puede usar "fr-CA". En el caso de los hablantes de Europa, la localización usará francés (Francia), por lo que se puede usar "fr-FR" para ello. Pero qué ocurre si un usuario determinado es de Bélgica, con una preferencia de idioma de "fr-BE"; ¿qué conseguirán? La región "BE" es diferente de "FR" y "CA", lo que sugiere una coincidencia de "cualquier región" para ambas. Sin embargo, Francia es la región preferida para francés, por lo que el "fr-FR" se considerará la mejor coincidencia en este caso.
Supongamos que primero ha localizado la aplicación para una sola variedad de francés, con cadenas en francés (Francia), pero que las ha calificado genéricamente como "fr" y, a continuación, quiere agregar compatibilidad con francés canadiense. Probablemente solo es necesario volver a traducir ciertos recursos para francés canadiense. Puede seguir usando todos los recursos originales que los mantienen calificados como "fr" y simplemente agregar el pequeño conjunto de recursos nuevos mediante "fr-CA". Si la preferencia de idioma del usuario es "fr-CA", el recurso "fr-CA" tendrá una puntuación de coincidencia mayor que el recurso "fr". Pero si la preferencia de idioma del usuario es para cualquier otra variedad de francés, el recurso independiente de la región "fr" será una mejor coincidencia que el activo "fr-CA".
Como otro ejemplo, supongamos que desea proporcionar localización de español independiente para hablantes de España en contraste con hablantes de América Latina. Supongamos además que las traducciones de América Latina se proporcionaron de un proveedor en México. ¿Debe usar "es-ES" (España) y "es-MX" (México) para dos conjuntos de recursos? Si lo hiciera, esto podría crear problemas para los hablantes de otras regiones de América Latina, como Argentina o Colombia, ya que obtendría los recursos de "es-ES". En este caso, hay una alternativa mejor: puede usar una subetiqueta de región macro, "es-419" para reflejar que pretende que los activos se usen para los hablantes de cualquier parte de América Latina o el Caribe.
Las etiquetas de lenguaje neutral de la región y las subetiquetas de región de macros pueden ser muy eficaces si desea admitir varias variedades regionales. Para minimizar el número de recursos independientes que necesita, puede calificar un activo determinado de una manera que refleje la cobertura más amplia para la que es aplicable. A continuación, complementa un recurso ampliamente aplicable con una variante más específica según sea necesario. Un recurso con un calificador de idioma independiente de la región se usará para los usuarios de cualquier variedad regional a menos que haya otro recurso con un calificador más específico de la región que se aplique a ese usuario. Por ejemplo, un recurso "en" coincidirá con un usuario en inglés australiano, pero un recurso con "en-053" (inglés como se usa en Australia o Nueva Zelanda) será una mejor coincidencia para ese usuario, mientras que un recurso con "en-AU" será la mejor coincidencia posible.
El inglés necesita una consideración especial. Si una aplicación agrega localización para dos variedades en inglés, es probable que sean para inglés de EE. UU. y para Reino Unido, o inglés "internacional". Como se indicó anteriormente, algunas regiones fuera de EE. UU. siguen convenciones ortográficas estadounidenses y la coincidencia de idiomas de Windows tiene en cuenta esa coincidencia. En este escenario, no se recomienda usar la etiqueta neutra de región "en" para una de las variantes; en su lugar, use "en-GB" y "en-US". (Sin embargo, si un recurso determinado no requiere variantes independientes, se puede usar "en"). Si "en-GB" o "en-US" se sustituye por "en", esto interferirá con la afinidad regional ortográfica proporcionada por Windows. Si se agrega una tercera localización en inglés, use una subetiqueta específica o de región de macros para las variantes adicionales según sea necesario (por ejemplo, "en-CA", "en-AU" o "en-053"), pero siga usando "en-GB" y "en-US".
Temas relacionados
- Cómo el sistema de administración de recursos compara y elige recursos
- BCP-47
- Comprender los idiomas del perfil del usuario y los idiomas de manifiesto de la aplicación
- Composición de regiones geográficas de macros (continentales), subregiones geográficas y otras agrupaciones económicas seleccionadas
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de